浅谈细粒度实体分类的前世今生 | AI Time PhD知识图谱专题
实体分类是知识图谱构建和补全的重要子任务,其中细粒度实体分类为实体提供了更加丰富的语义信息,有助于关系抽取、实体链接、问答系统等下游任务。
FGET 定义及问题
Fine-grained Entity Typing, 给定候选实体 (Mention)及其上下文 (Context),预测可能的类别集合 (Type)。
- 识别边界
NER从文本序列中识别实体的边界和类型,一般当作序列标注任务来处理
FGET任务实体边界通常已经给定,一般当作有层级的多标签分类任务来处理
- 类别层级
NER面向的类别数量较少,因为序列标注问题搜索空间比较大,限制了实体的类别数量
FGET面向几十个或者上百个类别,需要考虑类别之间的subClassOf关系
FGET任务的难点:
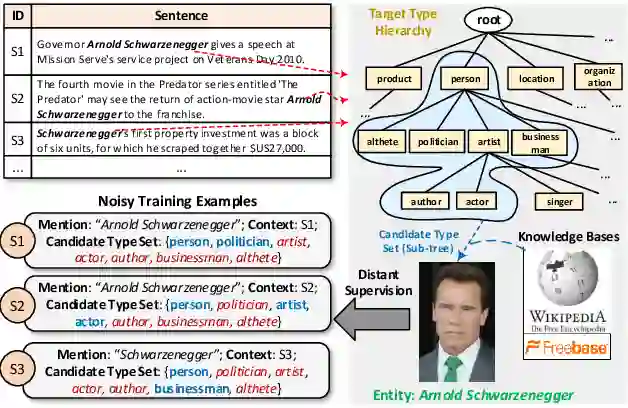
(1)远程监督带来的噪音
现有的数据集大多数使用distant supervision方法来构造,将实体mention链接到知识库中的某个实体,并把这个实体在知识库中全部的类别赋予这个mention,这种做法没有考虑mention的上下文,因此会引入噪音。包含上下文无关类别的噪音和过于具体的类别噪音。
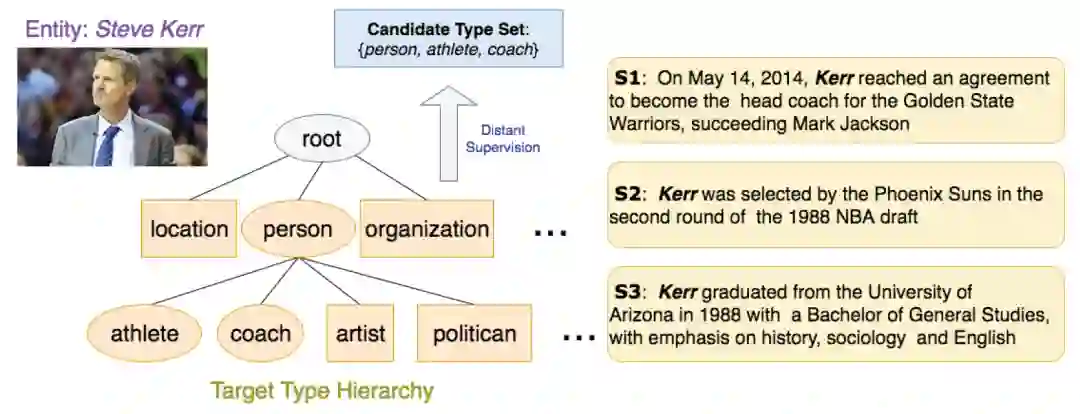
对于类别信息单一的实体,类别一般保持一致,这时远程监督方法可以接受。但是对于类别信息复杂的实体,尤其像人物这类实体,我们需要考虑远程监督带来的噪音问题。
(2)类别之间的层次关系
首先,如何得到一个分类树?有了这个分类树之后,我们应该如何建模这种subclassof关系,也是一个难点。
下表是目前常用的三个数据集:FIGER,OntoNotes和BBN。不同的论文训练集、验证集和测试集的划分会有一些差别,这里参考ACL-20最新的一个工作。类别的数量从几十到上百,类别之间通过subClassOf关系组织成2-3层的树形结构。
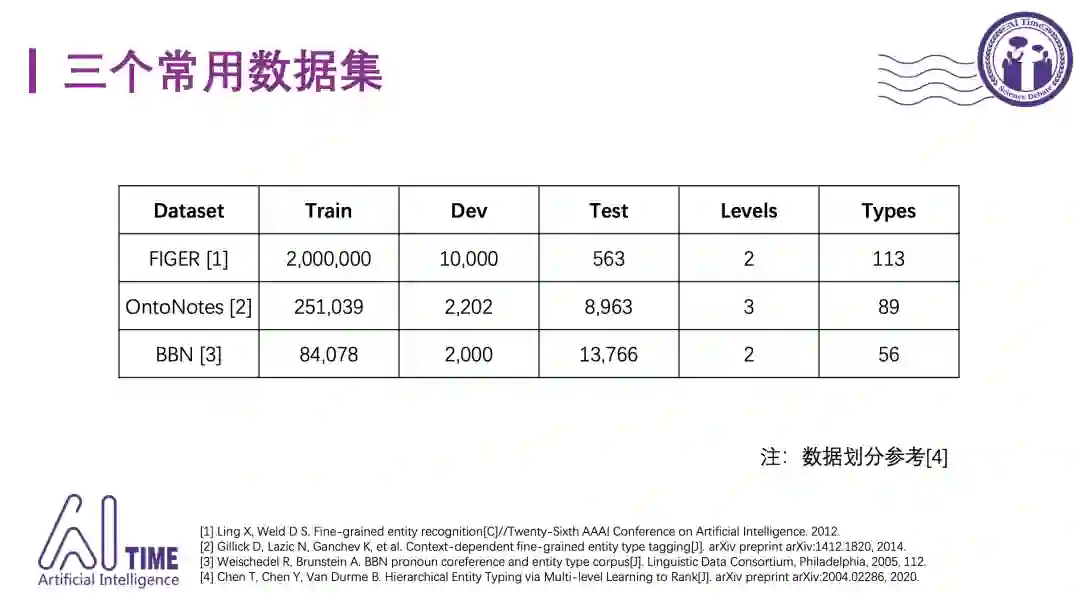
1)FIGER数据集
FIGER数据集中的类别是从Freebase中挑选出来的,把实体较少的类别进行了合并。FIGER数据集提出较早,存在一些问题,比如训练集较大,但测试集只有500多个样本,不是所有的实体类型都在测试集中出现过。因此在使用时,通常都会重新划分。
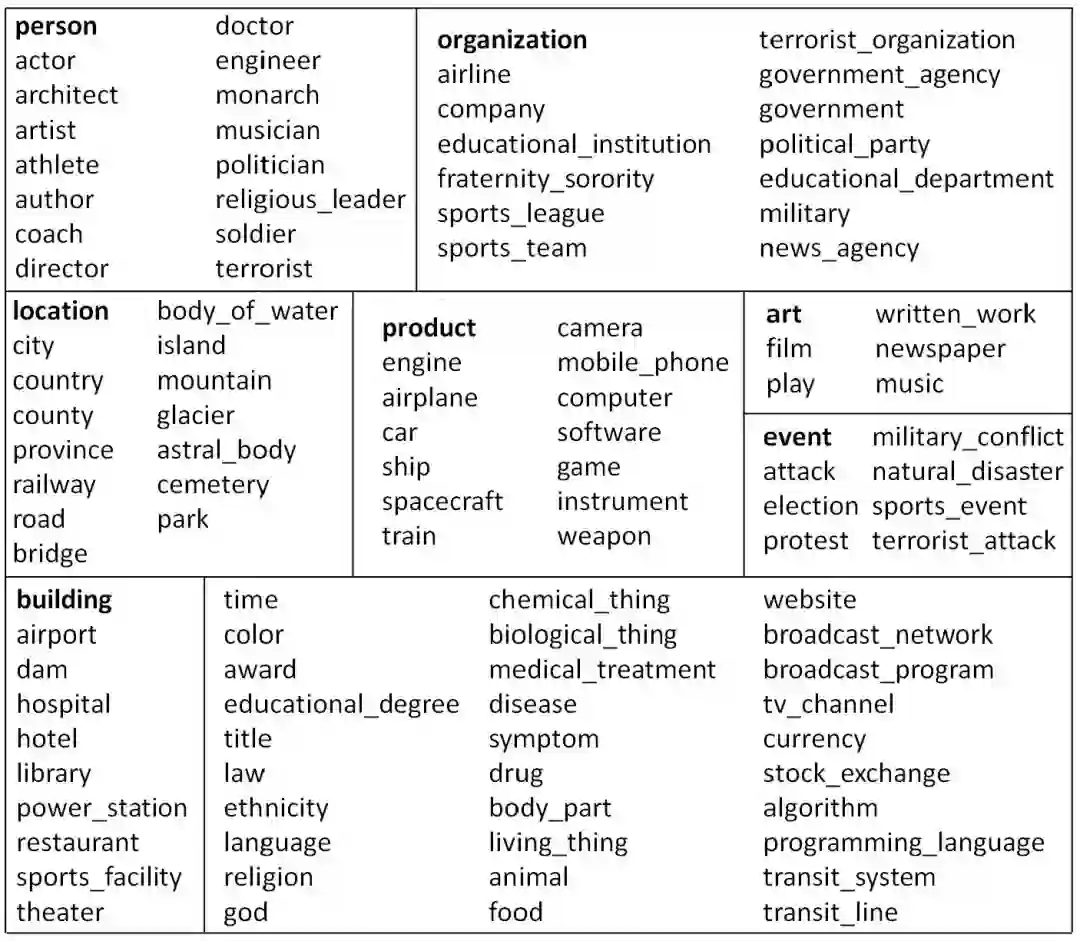
OntoNotes数据集参考了前面FIGER数据集的构造方法,同样从Freebase中筛选类别。类别之间的层次结构更加清晰。整个分类体系包含三层,比如person在第一层,artist在第二层,actor在第三层。并且最顶层的类别,和最常用的NER工具使用的类别集合可以对应起来。
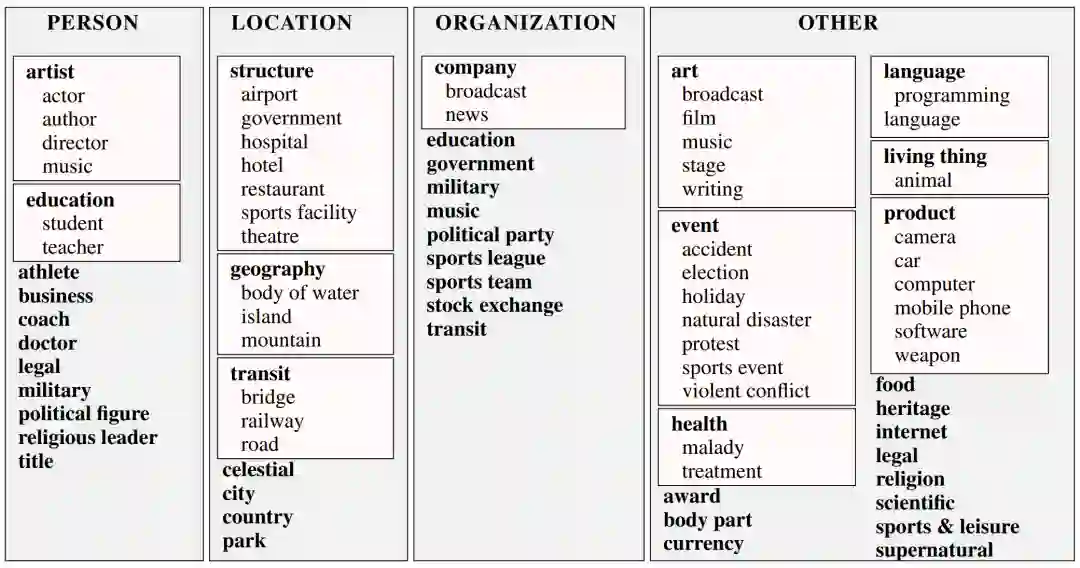
3)TypeNet数据集
之前介绍的数据集类别数量比较少,层次结构也比较简单。TypeNet包含超过1900个类别,构造的时候参考了WordNet的hierarchy结构。
同样从Freebase类别出发,首先过滤一些包含实体较少的类别,并且去除和Freebase API相关的类别,对于每个剩下的Freebase类别,通过字符串匹配的方式产生所有候选的WordNet Synset。人工标注者会从候选列表中判断这个Freebase类别和每个Synset之间的关系。如果没有匹配的,标注者会调用WordNet API直到找到一个合适的Synset。由于WordNet的Hierarchy层级结构比较深,因此TypeNet的平均深度要高于前面的三个数据集。

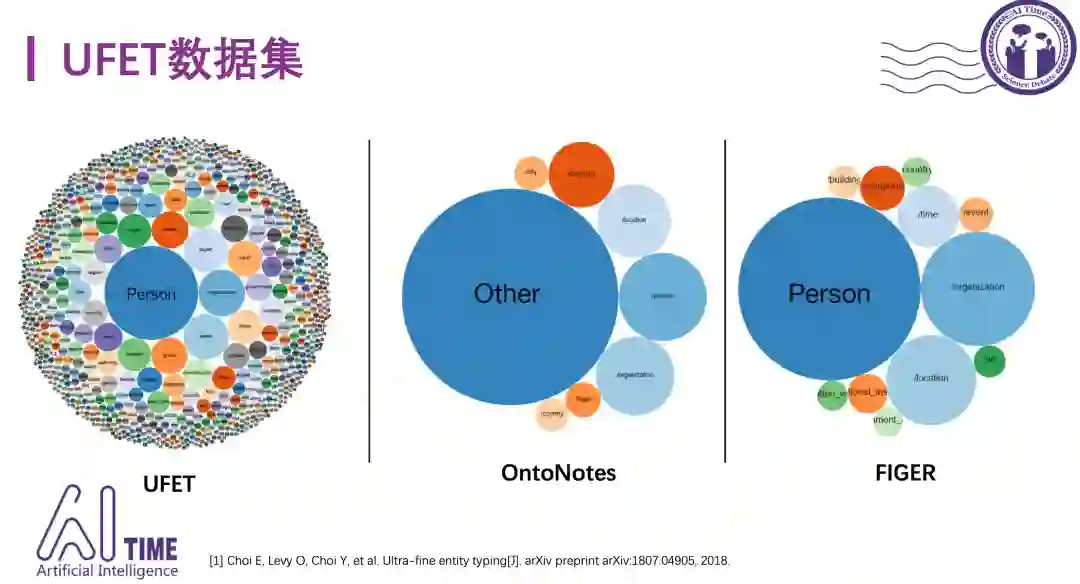
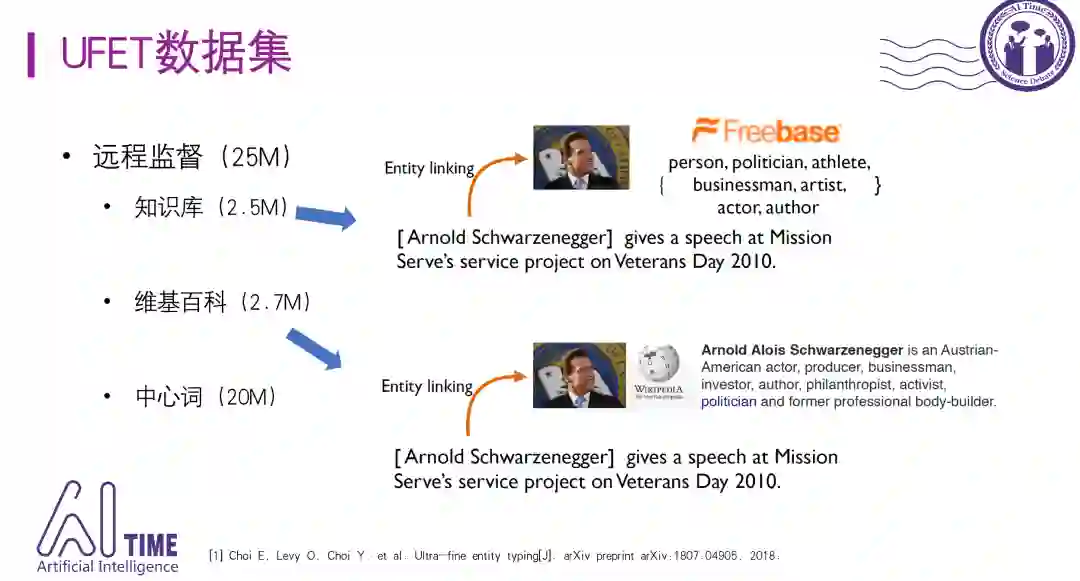
4)UFET数据集
ACL-2018提出的UFET数据集近两年得到了广泛的关注。这个数据集的特点是类别数量特别多,包含9个粗粒度类别,121个细粒度类别和超过10K的特别细粒度类别,mention的覆盖范围也不局限于命名实体,还包括代词和名词短语,图中黄色部分是前面工作没有覆盖到的,增加了He这种代词、AI researcher这种名词短语,这些在知识库中一般找不到对应的实体。Mention和type的覆盖面增大,给细粒度实体分类任务带来了更大的挑战。

在OntoNotes数据集中,52%的mention都被标记为Other,主要也是因为Other中类别数量比较多。FIGER数据集中Person,LOC和ORG的占比也比较高。而UFET数据集中各类别的分布相对均匀,更加符合实际情况。
UFET数据集中,有6K条数据是人工标注得到,每条数据有5个标注者,平均一个mention标注得到5.2个类别。

剩下的数据是远程监督得到的,方法有三种:使用知识库、维基百科和提取中心词。
首先使用知识库做远程监督,利用实体链接工具,将某个mention链接到Freebase这样的知识库中,将知识库中的实体类别赋予这个mention。
进一步使用维基百科做远程监督,还是利用实体链接工具,将mention链接到对应的维基词条,从文本中利用一些句法分析工具提取类别,这样得到的类别粒度更细。
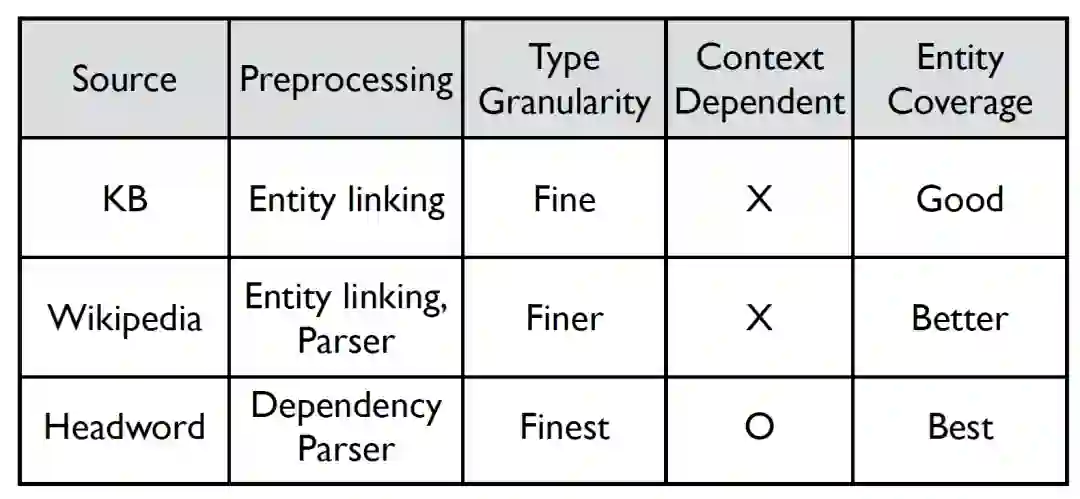
以上两种方法,都没有考虑mention所在的上下文,因此存在一定的噪音。使用中心词的方法可以得到最细粒度的类别,相对前两种方法而言是上下文相关的。
表格给出了三种远程监督方法的对比。
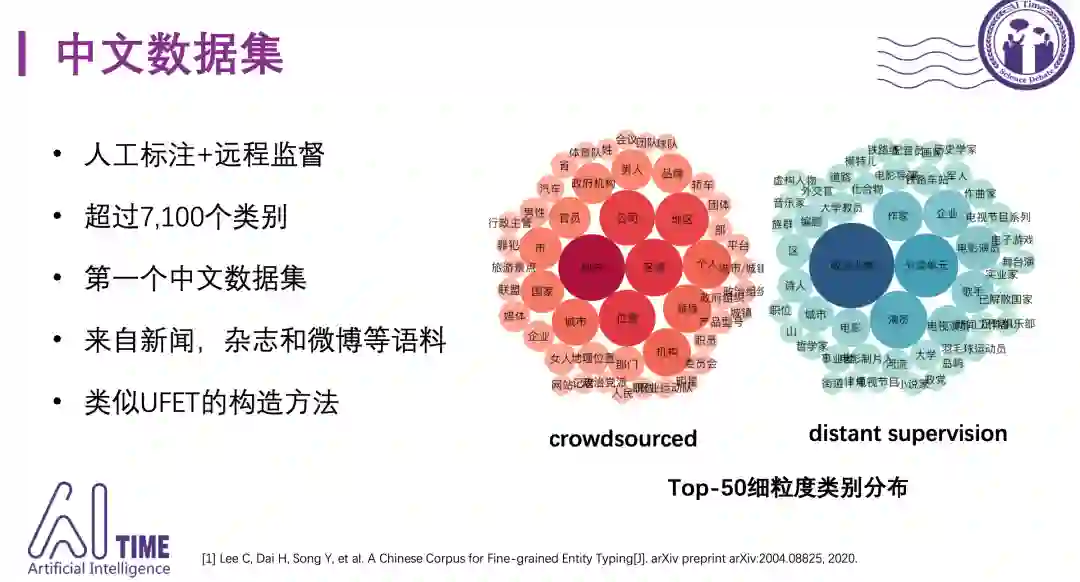
5)中文数据集
UFET数据集虽然规模大,但还是英文数据集。近期也有研究者做了中文数据集,包含7100多个类别,采用了和UFET数据集类似的构造方式,同时使用了人工标注加远程监督的方法,类别的分布也比较合理,红色的表示人工标注的类别分布,蓝色的表示distant supervision的类别分布,相信这个刚刚发表的中文数据集在今后会得到更多的关注。
FGET 的方法
首先介绍基本的框架,为后面的大多数工作所沿用。后续的工作也主要是解决前面提到的两个挑战,即数据噪音问题和层次关系处理问题。我们会先梳理后续的工作如何降低distant supervision带来的噪音的影响,然后梳理后续工作如何处理类别之间的subclassof关系。
1)AttentiveNER模型
EACL-17提出的AttentiveNER是细粒度实体分类早期的工作,分别对实体mention和上下文context建模,得到mention的表示v_m和上下文的表示v_c。其中mention的表示直接取平均,上下文的表示采用双向LSTM+固定的attention机制,此外还引入了传统特征。将三种特征拼接到一起,送到MLP中进行类别预测。可以看到这种方法并没有考虑distant supervision带来的数据噪音问题。
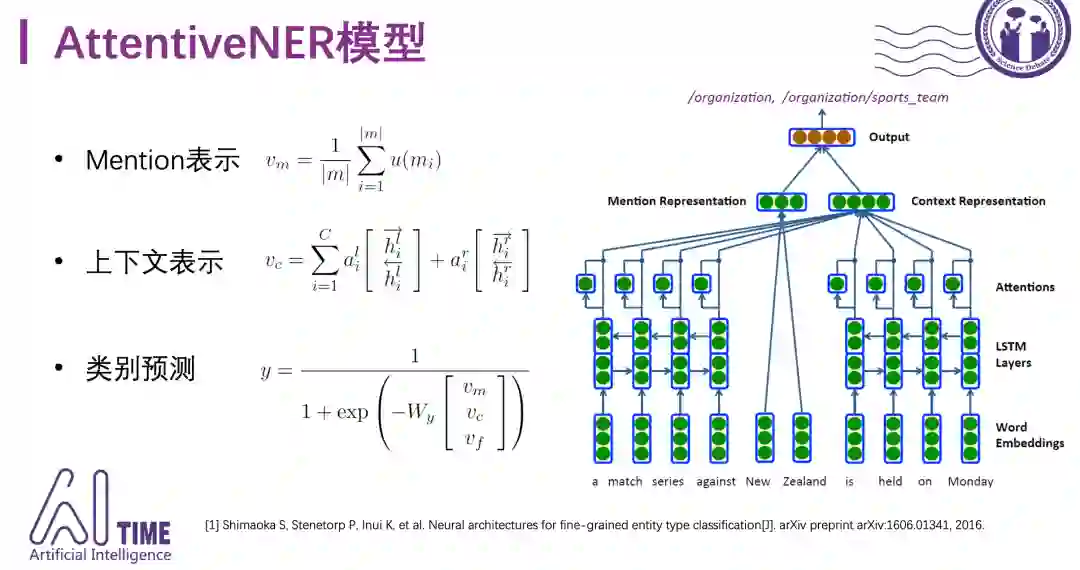
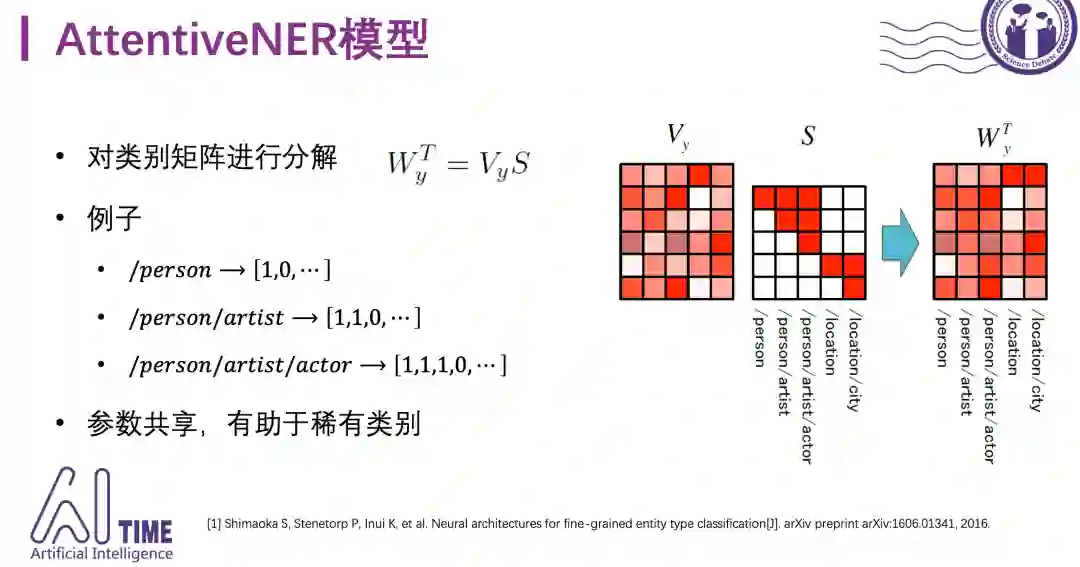
AttentiveNER采用了比较简单的方式来处理类别之间的层次关系。V_y表示要学习的参数矩阵,S是一个稀疏矩阵,按照层级进行编码,比如Person第一个位置为1,/person/artist前两个位置为1,这样有助于参数共享,同一层的类别可以共享父节点的表示,对于那些训练数据比较少的类别有帮助。
AttentiveNER采用双向LSTM和固定的attention机制以及类别之间的参数共享机制,后面的模型大多数沿用了这个框架。
2)KNET模型
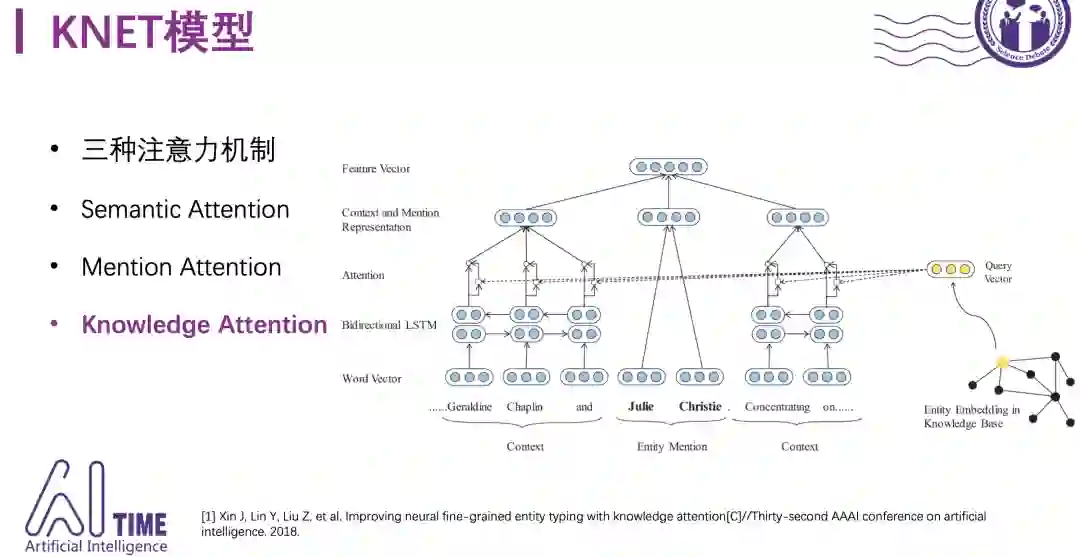
由于AttentiveNER采用了固定的attention机制,在实际应用中不够灵活。同样使用双向LSTM结构,AAAI-18的KNET模型提出使用三种注意力机制来改进:
semantic attention还是固定的attention机制;
mention attention使用mention的表示替代固定的query vector;
knowledge attention使用知识图谱中实体的表示替代query vector,这是KNET模型的主要创新点。
实体的表示由TransE计算得到,因为要使用知识图谱中实体的表示,因此需要进行实体消歧,将mention链接到某个实体上。如果mention在知识图谱中找不到对应的实体,会根据文本信息构造得到实体表示。个人不太推荐在细粒度实体分类的任务中使用涉及到类似实体链接或者实体消歧的方法来提升模型效果,因为实体链接是更加终极的目标。
3)进一步改进
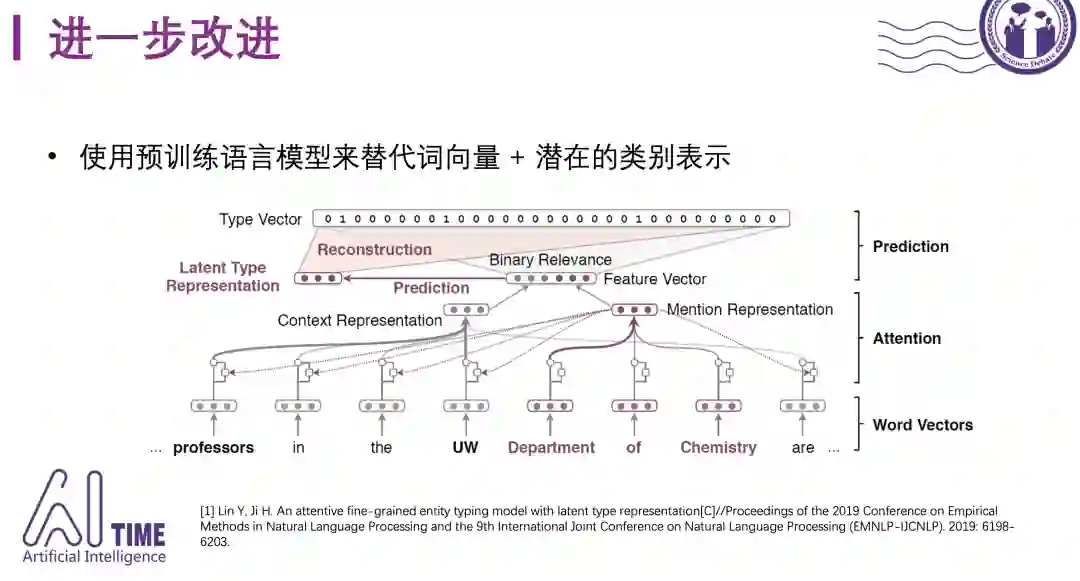
近两年来预训练模型发展迅速,也可以用到细粒度实体分类的任务中来。EMNLP-19提出的模型使用ELMo 和BERT 等更强的预训练语言模型进行mention 和context 的表示,模型顶部是一个混合分类器,它不独立预测每种类型,而是预测编码潜在类型特征的低维向量,并且该模型从这种潜在表示中重构稀疏高维的类型向量。这个工作使用了ELMo和BERT 等更强的预训练语言模型,结合潜在类型表示,效果进一步提升。
1)投票法
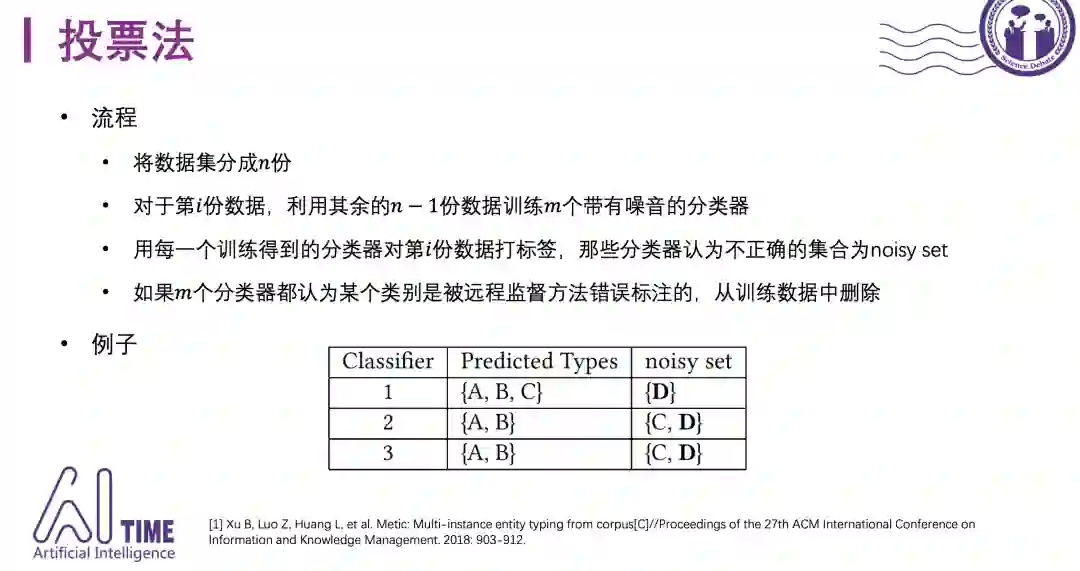
首先介绍一种最简单的数据降噪方法,称为投票法。如图所示,如果distant supervision的标注方法认为ABCD都是某个mention的类别,但是三个分类器都认为D是错误标注的类别,最终会将D删除。
2)AFET模型
处理数据噪音的比较有代表性工作是EMNLP-16提出的AFET模型。这个模型分为四个部分,首先提取mention的特征,然后将训练数据集划分成clean set和noisy set。Clean set中的实体类别信息比较单一,只对应一条类别路径,而noisy set中的实体对应多条类别路径,这种数据就是包含噪音的。将mention和type映射到同一个语义空间中,方便后面做计算,U和V是映射矩阵,目标就是要学习这两个映射矩阵U和V。在得到了这两个矩阵之后,就可以为测试集中的实体mention预测类别。

下图是distant supervision构造得到数据集的方式。
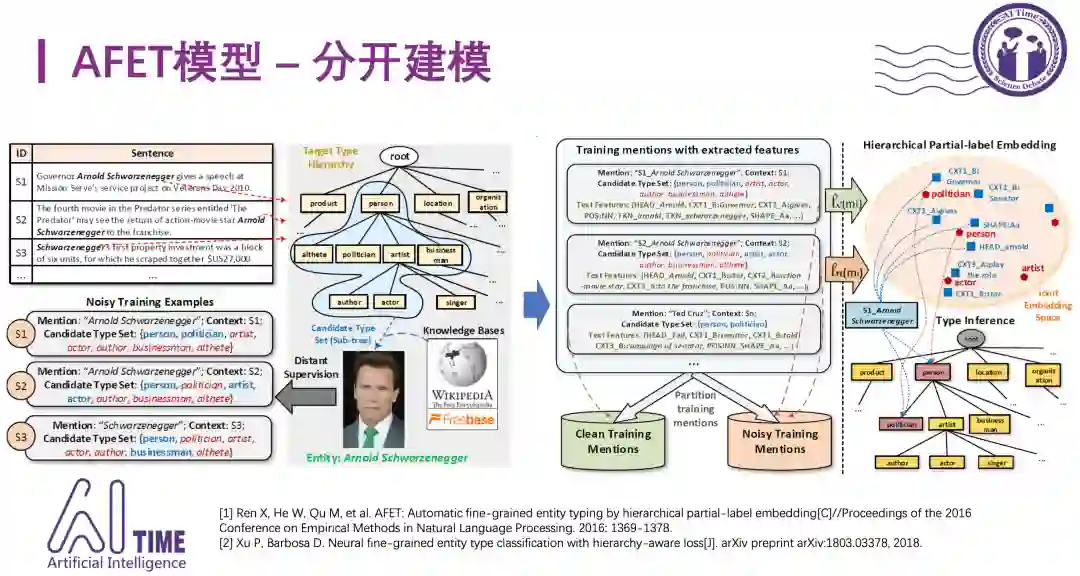
AFET模型比较早的将数据集划分成clean-set和noisy-set,针对不同的数据采用不同的处理方法,在当时取得了最好的效果。

因篇幅原因,略去报告中讲解的其他模型。
c)层次建模的方法
1)层次损失标准化
在分类的过程中,模型会倾向于预测那些比较general的类别,也就是high-level的类别,如果要预测某个比较具体的类别,需要在上下文context中找到比较强的指示信息。

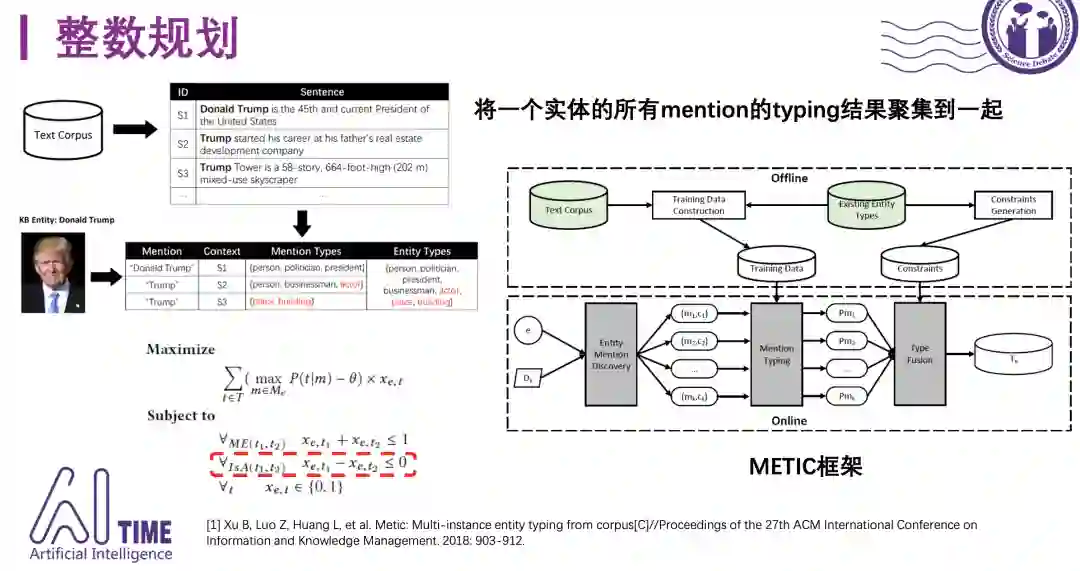
2)整数规划
CIKM-18提出的METIC模型面向另外一个问题:假设我们知道一个实体的所有mention,理论上使用一种融合的方法将每个mention在上下文中的类别聚集在一起,就可以将这个实体的类别信息收集全。
如图所示假如我们知道Trump有三个mention,,第一个mention的预测结果是政客,第二个mention的预测结果是商人和演员,第三个mention的预测结果是建筑,这是实体链接错误导致的结果,将三个mention的类别预测结果汇聚到一起,检查一下有没有冲突就可以得到trump在知识库这一级别上的类别集合,红色的表示没有通过冲突检查的类别,会被丢弃掉。
应用
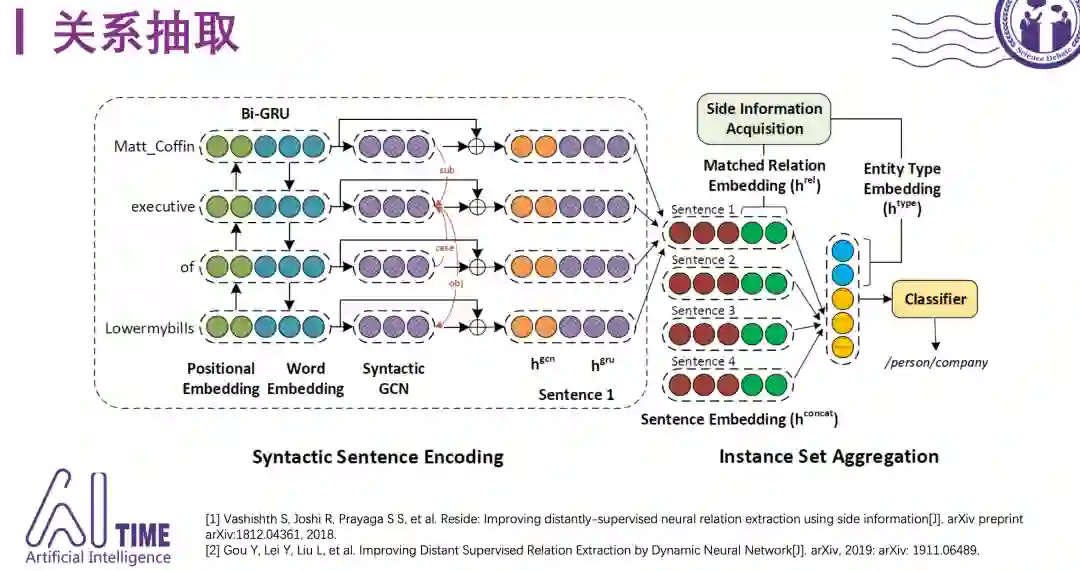
a)关系抽取
针对关系抽取任务,EMNLP-18提出的RESIDE模型使用了实体类别信息,提升了关系抽取任务的效果。这个模型将包含某个实体对的所有句子建模成一个bag,对每个句子计算得到句子向量,在得到了每个句子向量之后,利用关系的别名信息和Open-IE抽取得到的关系短语计算每个句子的权重,得到句子向量的加权平均表示,最终bag的embedding由刚才得到的句子加权平均后的向量表示和头尾实体的类别embedding拼接得到,输入softmax分类器中进行分类。在NYT数据集上的实验结果表明,实体的类别信息能够提升关系抽取任务的效果。
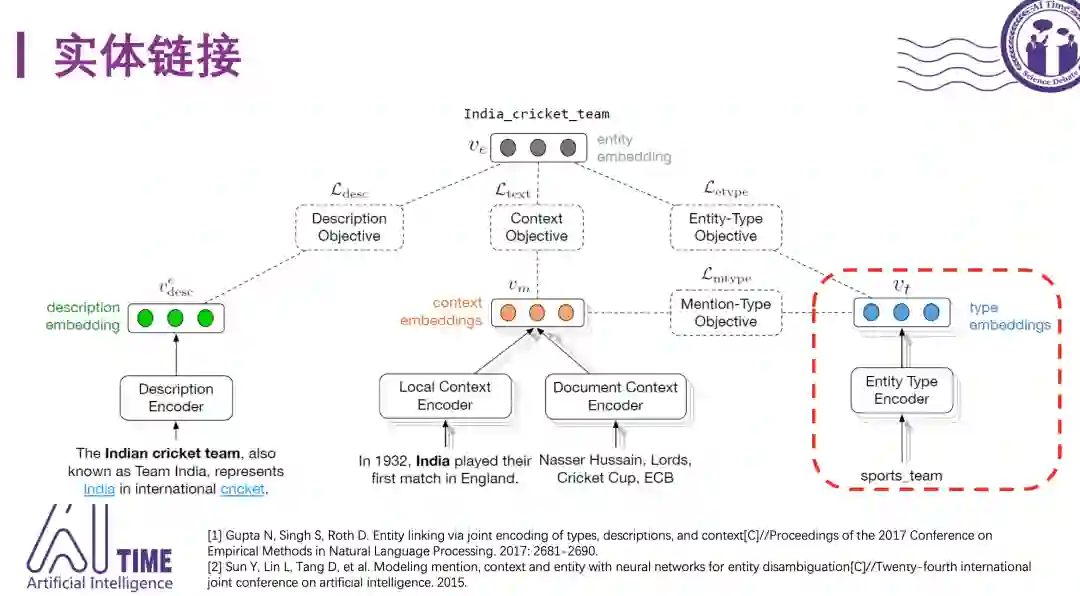
在实体链接任务中,实体的类别信息对特征表示有一定的帮助。
如图所示IJCAI-15提出的模型中,𝑣_𝑐是上下文文本的表示,其输入是局部上下文的词向量,使用CNN对词向量输入进行特征抽象,对于实体mention 𝑣_𝑚,简单地对名字中的所有词向量进行平均,对于候选实体𝑣_𝑒 则是基于候选实体mention中的词向量平均𝑣_𝑒𝑤 和候选实体类别中的词向量平均𝑣_𝑒𝑐。
类似的还有EMNLP-17提出的模型,充分利用了实体相关的文本信息(包括实体描述,实体mention在文档中的上下文) 和结构化信息(主要是实体类别) 来对实体进行表示,这些工作在特征表示方面考虑了实体的类别信息。
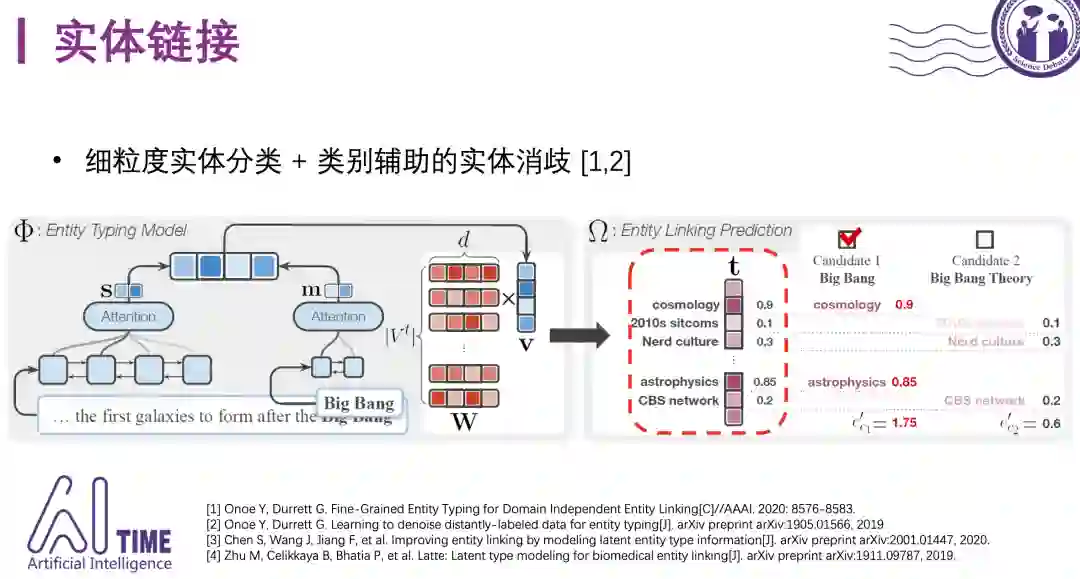
下面介绍实体类型信息对消歧的帮助。实体消歧的核心目标在于消除实体mention的歧义性,类别可以看作实体的一个属性,在实体消歧任务中,对于一个实体mention,我们已经获得了所有的候选实体集,理论上,只要类别数量足够多,类别粒度足够小,我们就可以通过类别的交集来从候选实体集中定位应该链接的实体。
如图所示,对于第二个文档,能够判断出”Jordan(Country)” 的类别与文本中的另一实体”Arab country” 的类别语义接近,从而选择“Jordan(Country)”作为实体mention ”Jordan” 的指代的目标实体。

AAAI-20提出了一种基于entity typing结果来预测实体链接结果的模型。这一工作只使用了实体类别进行消歧,足以证明类别信息不但能够为实体链接任务提供重要的消歧特征,相应的基于类别的消歧模型也拥有非常好的泛化能力。
1)数据集相关
小语种数据集。现有的工作主要集中在英文数据集上,包括常用的FIGER、OntoNotes和UFET数据集,近期才有中文数据集被提出来,还有很多小语种缺乏高质量的数据集。
现有数据集的分类体系还需要进一步研究。可以考虑借鉴taxonomy induction的方法构造一个类别数目和层级结构都比较合理的分类体系。
协同的方式。现有的数据集往往是针对单个实体mention进行类别预测,如果一个句子中包含多个实体mention,用一种协同的方式来进行类别预测可能更加合理。
2)Zero-shot问题
zero-shot的entity typing工作也非常有研究价值,因为在实际应用中确实可能会遇到没见过的type,NACCL 19提出使用维基百科中type的文本描述信息来处理new type问题,后续有研究者提出了memory增强的方法来处理zero-shot问题。
3)跨语言细粒度实体分类
统一的分类体系。目前的研究主要集中在英文数据集上,维基百科包含丰富的锚文本链接和跨语言链接,假如我们使用同样的分类体系,理论上是可以利用维基百科构造其他语言的数据集的。
用rich-resource语言去帮助low-resource语言。针对其他语言标注数据少、或者根本没有标注数据的情况,跨语言的细粒度实体分类任务就产生了,可以使用迁移学习模型和已有的跨语言词向量表示,共同训练一个跨语言的分类模型,把在英文数据上学到的东西迁移到其他语言上,实现知识共享,这方面我们可以参考很多迁移学习和domain adaptation的工作。
4)结合具体的任务
最后还是要和具体任务结合在一起,比如前面提到的关系抽取和实体链接工作,因为typing一般不是最终的目的,只提供辅助的结果,为下游应用服务,因此把细粒度实体分类应用到其他下游任务上,才能最大地发挥其价值。
整理:鸽鸽
审稿:金海龙
(直播回放:https://www.bilibili.com/video/BV18z4y1X7dx)