详解ORB-SLAM2中的特征均匀提取策略
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
之前发表过《ORB特征均匀提取策略对性能的提升有多大?》,本文是对该策略的详细解释。作者是杨小东,已经授权转载,未经授权禁止二次转载
原文:
ORB-SLAM的一大创新点在于系统的所有模块都使用了同一种特征:ORB,这样构造的系统更加简单、稳健。
本文首先介绍了原版的ORB特征,之后又介绍了ORB-SLAM对ORB特征的改进。
相较与SIFT、SURF,ORB在CPU下就可以获得实时性能,并且具有尺度(一定的)、旋转不变性,而且提高了BRIEF描述子的抗噪能力。
ORB的速度是SIFT的100倍,SURF的10倍。
ORB: Oriented FAST and Rotated BRIEF
一定的尺度不变性:
利用图像金子塔实现,由于金字塔层数有限,因此只能在一定范围保证尺度的不变性。
旋转不变性:
首先利用灰度质心法计算出特征的方向,然后计算旋转后的BRIEF描述子。
抗噪能力:
计算BRIEF的时候不是使用一个点的灰度,而是使用了点周围5×5区域的灰度。
应该也有一定的光照不变性:
因为FAST提取的时候是比较灰度,rBRIEF的计算也是比较灰度。
速度快:
使用了FAST角点,BRIEF描述子,二者均很快。
速度是SIFT的100倍,SURF的10倍。
0. 提取流程概览
构造金字塔
提取FAST角点
利用灰度质心法,计算旋转角度 θ
计算旋转后的BRIEF描述子
下面展开介绍这四步。
1. 构造金字塔
金字塔大家应该都比较熟悉,不再啰嗦了,自己脑补喽。
2. 提取FAST角点
2.1 如何分配每一层提取的特征点数量。
金字塔层数越高,图像的面积越小,所能提取到的特征数量就越小。基于这个原理,我们可以按照面积将特征点均摊到金字塔每层的图像上。我们假设第0层图像的宽为 W,长为 L,缩放因子为 s(这里的 0 < s < 1)。那么整个金字塔总的面积为

那么,单位面积的特征点数量为

那么,第0层应分配的特征点数量为

接着那么,推出了第α层应分配的特征点数量为

实际上,OpenCV里的代码不是按照面积算的,而是按照边长来算的。也就是上面公式中的
2.2 什么是FAST角点,如何提取?
FAST角点,通过对比中心与周围点(半径为3的圆上的点)灰度的差别,即可确定是否为关键点,速度贼快。
具体的步骤为:
1) 像素 p,其灰度为 Ip ;
2) 设置一个阈值 T,比如 Ip的20%。
3) 以 p为圆心,选择半径为3的圆上的16个像素点。
4)如果圆上面有连续的 N个点的亮度大于阈值 Lp+T 或者小于 Lp-T,则判定此点为FAST角点。通常 N的取值有FAST-9,FAST-11, FAST-12最常见。对于FAST-12有高效的检测方法,首先检测12点、3点、6点和9点钟的像素(1,5,9,13),如果至少有3个是成功的,才有可能是角点,再去进一步的检测,否则就直接pass。
按照上述步骤对图像上每个像素处理一遍,可以获取大量的FAST角点。那,FAST角点容易出现扎堆现象,要用非极大值抑制再处理一遍(Non-maximal suppression)。TODO: NMS具体实施。非极大值抑制的方法使用的分数计算很简单,计算一个中心点与周围16个点灰度差绝对值的和最为分数:

为了选择响应最大的 Na个角点,还需要计算一个Harris响应。最后,在每层中选择响应最大的 Na个特征点。TODO:Harris角点的计算。
3. Oriented FAST,旋转角度计算
ORB计算角度也比较简单,首先一个圆形区域的灰度质心,连接质心和圆心形成一个向量,这个向量的角度就是角点的角度。圆的半径取为15,因为整个patch一般取的是31×31的。
注意,现在我们已经把坐标系的圆心设在了关键点上,那么灰度质心为

角度就是

至此,不仅仅提取了FAST角点,还找出了角点的角度。这个角度可以用来指导描述子的提取,保证每次都在相同的方向上计算描述子,实现角度不变性。
这就是Oriented FAST。
4. 计算Rotation-Aware BRIEF, rBRIEF
4.1 BRIEF描述子
BRIEF是一个二进制的描述子,计算和匹配的速度都很快。
BEIFE的计算步骤如下
首先,以关键点为中心,选择一个31×31的块
然后,在这个块内按照一定的方法选择N对点,N一般取256
对于点对, 通过比较这两个点的灰度大小确定一个二值结果,0或者1.
![]()
这样把256个点对的结果排起来,就形成了BRIEF描述子。
![]()
 , 通过比较这两个点的灰度大小确定一个二值结果,0或者1.
, 通过比较这两个点的灰度大小确定一个二值结果,0或者1.


BRIEF的匹配采用汉明距离,非常快,简单说就是看一下不相同的位数有多少个。如下的两个描述子,不同的位数为4。实际上我们选择的点对数为256,那么距离范围就是0~256。

4.2 Steered BRIEF
BRIEF描述子是没有考虑旋转不变性的,Steered BRIEF根据Oriented FAST计算出的角度,把原始的256个点对的坐标旋转之后,再取灰度。从而实现了旋转不变性。

原始的256个点对坐标为 S,旋转后的为 Sθ。
4.3 Rotation-Aware BRIEF
上述过程虽然解决了旋转问题,但是也造成了描述子一些性能的下降。TODO: 具体什么呢?我也没看明白,留着以后看吧。
这个问题的解决是使用了学习的方法,利用了大量的数据,选择出了效果最好的256个点对位置。
以后每次提取特征点都使用这256个位置。
4.4 抗噪能力的提高
在计算BRIEF描述子的时候,ORB使用的不是每个点的灰度,而是周围5×5的patch的灰度。因此起到了低通滤过的效果,对噪声有更强的鲁棒性。
5. ORB-SLAM对ORB特征的改进
ORB-SLAM中并没有使用OpenCV的实现,因为OpenCV的版本提取的ORB特征过于集中,会出现扎堆的现象。这会降低SLAM的精度,对于闭环来说,也会降低一幅图像上的信息量。具体的对ORB-SLAM的影响可以参考我的另一篇文章
杨小东:[ORB-SLAM2] ORB特征提取策略对ORB-SLAM2性能的影响
ORB-SLAM中的实现提高了特征分布的均匀性。
最简单的一种方法是把图像划分成若干小格子,每个小格子里面保留质量最好的n个特征点。这种方法看似不错,实际上会有一些问题。当有些格子里面能够提取的数量不足n个的时候(无纹理区域),整幅图上提取的特征总量就达不到我们想要的数量。严重的情况下,SLAM就会跟丢喽
ORB-SLAM中的实现就解决了这么一个问题,当一个格子提取不到FAST点的时候,自动降低阈值。ORB-SLAM主要改进了FAST角点提取步骤。
对于金字塔的每一层。
划分格子,格子的大小为30×30pixels
单独对每个格子提取FAST角点,如果提取不到点,就降低FAST阈值。
这样保证纹理较弱的区域也能提取到一些FAST角点。
这一步可以提取大量的FAST点。
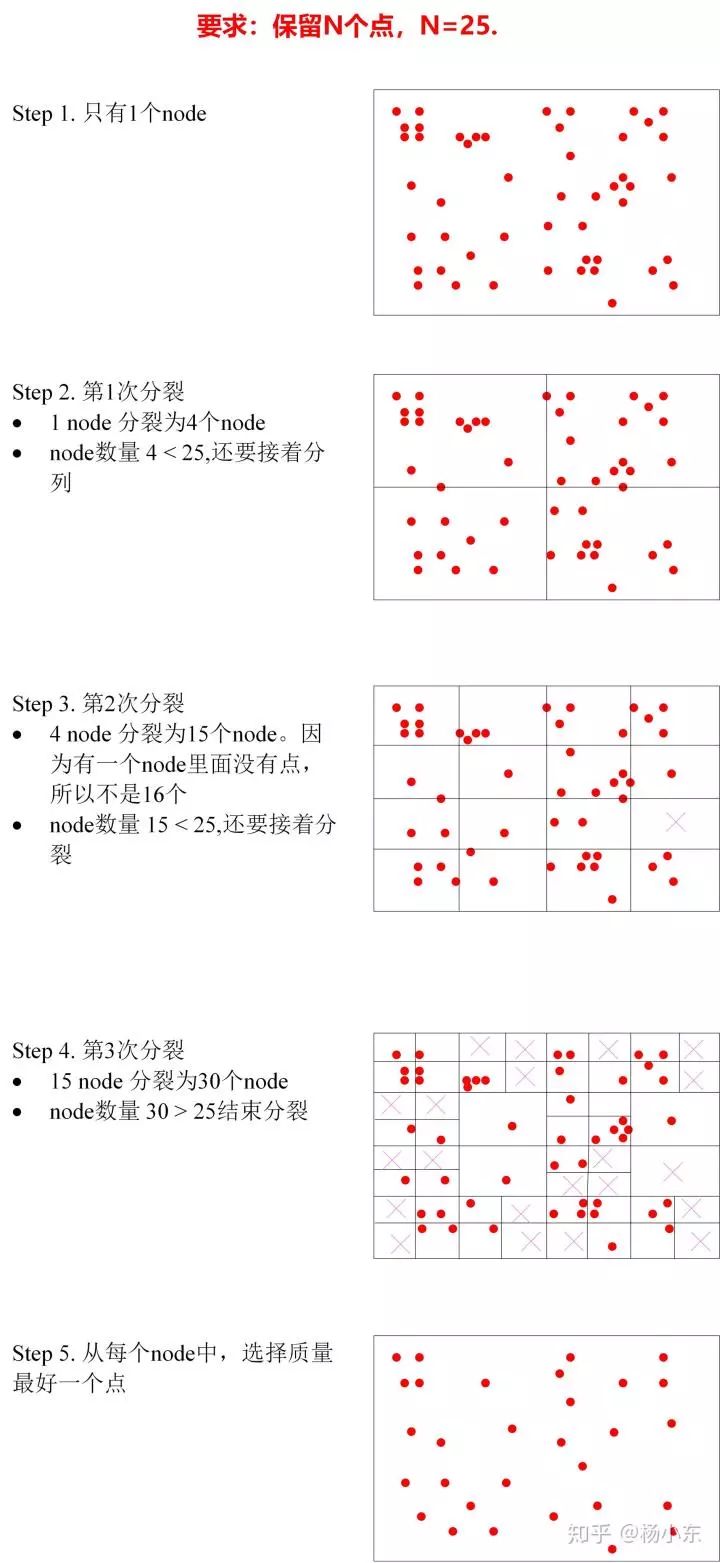
基于四叉树,均匀的选取 Na 个FAST点。
上述步骤中,基于四叉树的方法有点复杂,下面分析一下。
如果图片的宽度比较宽,就先把分成左右w/h份。
一般的640×480的图像开始的时候只有一个node。
如果node里面的点数>1,把每个node分成四个node,如果node里面的特征点为空,就不要了,删掉。
新分的node的点数>1,就再分裂成4个node。
如此,一直分裂。
终止条件为:
node的总数量>Na, 或者无法再进行分裂。
然后从每个node里面选择一个质量最好的FAST点。
下面通过一张图说明这个问题
参考资料
[1] Rublee E, Rabaud V, Konolige K, et al. ORB: An efficient alternative to SIFT or SURF[C]// International Conference on Computer Vision. 2012.
[2] https://github.com/raulmur/ORB_SLAM2/blob/master/src/ORBextractor.cc
[3] Zhang Bin:传统计算机视觉中图像特征匹配方法的原理介绍(SIFT 和 ORB)
[4] 小林同学:【小林的OpenCV基础课 22】BRIEF/ORB/故事未结束
[5] 小林同学:【小林的OpenCV基础课 21】FAST算法/返璞归真
相关代码:
https://github.com/ydsf16
从零开始学习三维视觉核心技术SLAM,扫描查看介绍,3天内无条件退款

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、算法竞赛、图像检测分割、人脸人体、医学影像、自动驾驶、综合等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

推荐阅读
从零开始一起学习SLAM | 不推公式,如何真正理解对极约束?
从零开始一起学习SLAM | 理解图优化,一步步带你看懂g2o代码
从零开始一起学习SLAM | 用四元数插值来对齐IMU和图像帧
深度学习遇到SLAM | 如何评价基于深度学习的DeepVO,VINet,VidLoc?
最新AI干货,我在看




