©作者 | 曹虎、李京烨等
来源 | 社媒派SMP
本研究设计了一种简单有效的标签系统将重叠和嵌套事件抽取转换成了词对关系分类的任务,触发词、论元以及其间的关系可以并行地同时被预测出来,达到非常快的抽取速度,在 3 个重叠或嵌套的事件抽取数据集上的实验结果达到了 SOTA。
![]()
OneEE: A One-Stage Framework for Fast Overlapping and Nested Event Extraction
收录会议:
论文链接:
https://arxiv.org/pdf/2209.02693.pdf
代码链接:
https://github.com/Cao-Hu/OneEE
![]()
动机介绍
1.1 重叠和嵌套事件抽取
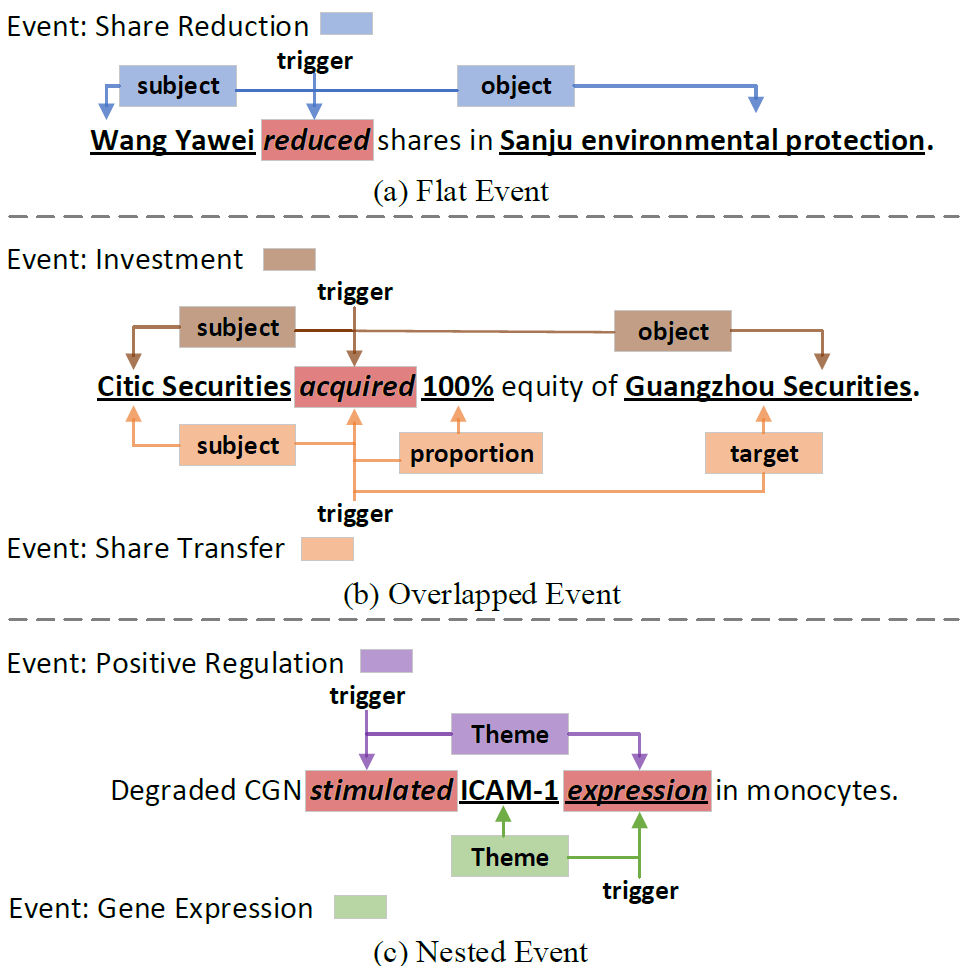
事件抽取(Event Extraction,EE)是自然语言处理领域的一项非常基本的任务,在社区长久以来一直得到广泛的研究。EE 的目标是从文本中抽取事件触发词和相关的论元。传统的事件抽取关注于普通的事件,认为触发词和论元之间没有重叠,忽视了复杂的事件模式,即重叠事件和嵌套事件:
▲ 图1:普通事件(a),重叠事件(b),嵌套事件(c)
以图 1 为例,(b) 中 Investment 事件和 Share Transfer 事件共享了”acquired”这一重叠触发词,以及”Citic Securities”,”Guangzhou Securities”是重叠的论元。(c) 中 Gene Expression 事件是 Positive Regulation 的 Theme 论元。
1.2 重叠和嵌套事件抽取方法
截止当前,重叠和嵌套事件抽取领域的主流方法大致有三类:
基于 Pipleline 的方法;
基于多轮 QA 的方法;
基于级联网络的方法。
这些方法都是 Multi-stage 的,用多个连续的阶段分别抽取事件触发词和论元。其中,基于级联网络的方法 CasEE 是之前的 SOTA,CasEE 依次预测事件类型、抽取触发词、抽取论元。这些 Multi-stage 的方法后面阶段的预测依赖于前面的预测结果,难以避免地带来了误差传播的问题。
本研究关注于构建一种高效的 EE 框架,能够在一个阶段同时解决重叠和嵌套的事件抽取。
1.3 本文的方法
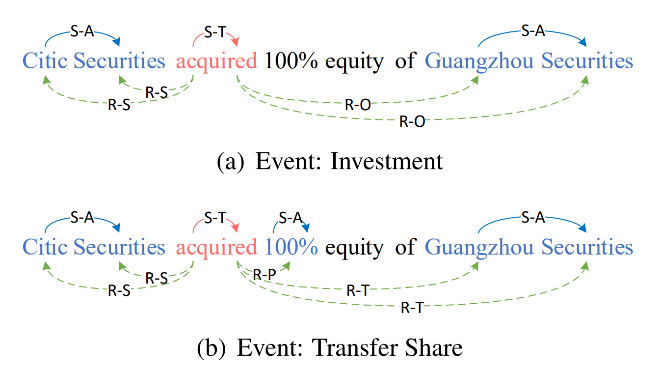
传统的事件抽取使用序列标注的方法无法解决重叠和嵌套的问题,现有的工作使用指针网络分别识别触发词或论元的头尾 token;我们在针对重叠和嵌套事件的共性进行深入挖掘后,发现可以通过 token-pair 之间的关系分类进行统一建模。触发词和论元可以通过 token-head 和 token-tail 之间联系,而论元的角色可以通过触发词和论元之间的关系建模,例如图 1(b)中触发词”acquired”和论元”Guangzhou Securities”表达了 object 关系。
根据上述观察,本文将 Overlapped and Nested EE 任务转化成一种词对的关系分类任务,通过这种标签体系能够在一个阶段内抽取出事件类型、触发词、论元以及论元的角色,在此基础提出了一种新的 EE 框架(A One-Stage Framework for Fast Overlapping and Nested Event Extraction),名为 OneEE。具体地,该框架的目标是将 EE 转变为识别出触发词和论元中所蕴含的两种类型的关系,即:1)Span 关系(S-T, S-A);2)Role 关系(R-*)。
具体的词对关系分类示例如图 2 所示。其中 S-T 表示两个词是某个触发词的头部和尾部,S-A 表示两个词是某个论元的头部和尾部(如”Citic”->”Securities”,Argument),R-*表示该词作为触发词的事件中,另一个词扮演了角色类型为*的论元(如“acquired”->“Citic Securities”,Subject)。
![]()
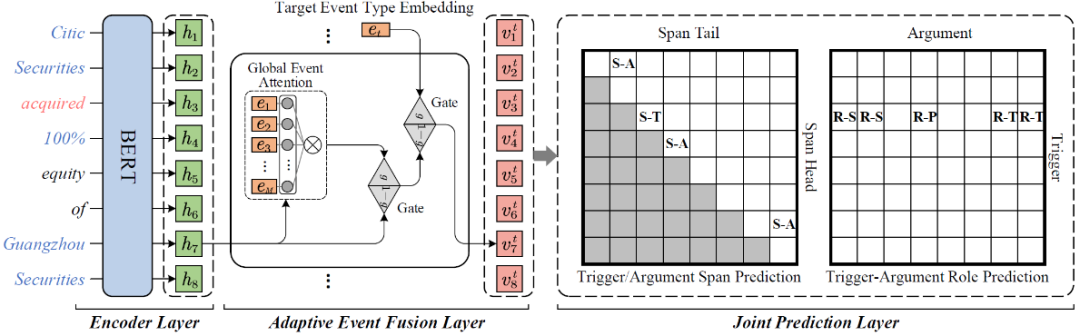
图 3 给出了 OneEE 整体的框架结构。其整体可分为三层:输入编码层,自适应事件融合曾以及最后的联合解码层。
其中解码层是本论文的核心。
![]()
▲ 图3:模型整体结构
2.1 编码层
给定一个输入句子,将每一个词转换成多个 word piece,并将他们输入预训练的 BERT 模块中。进过 BERT 计算后,使用最大池化操作将这些 word piece 表示重新聚合成词表示。
由于该框架的目标是预测目标事件类型的词对之间的关系,因此生成高质量的事件感知的表示十分重要。因此,为了融合编码器提供的事件信息和上下文信息,本论文设计了一个自适应事件融合层。其中注意力模块用于建模不同事件类型之间的交互并获得全局事件信息,两个门融合模块用于将全局事件信息和目标事件类型信息与上下文化的词表示融合。
2.3 解码层
在自适应事件融合层之后,获得了事件感知的词表示,用于预测词对之间的 Span 关系和 Role 关系,对于每个词对 (w_i , w_j ),计算一个分数来衡量它们对于关系 s ∈ S 和 r ∈ R 的可能性。为了使预测层对于词与词之间的相对距离敏感,论文还引入了旋转式的相对位置编码,设计了距离感知的打分函数。损失函数部分本文使用了 Circle Loss 的变体,将交叉熵损失扩展到多标签分类问题,并缓解了类别不均衡的问题。
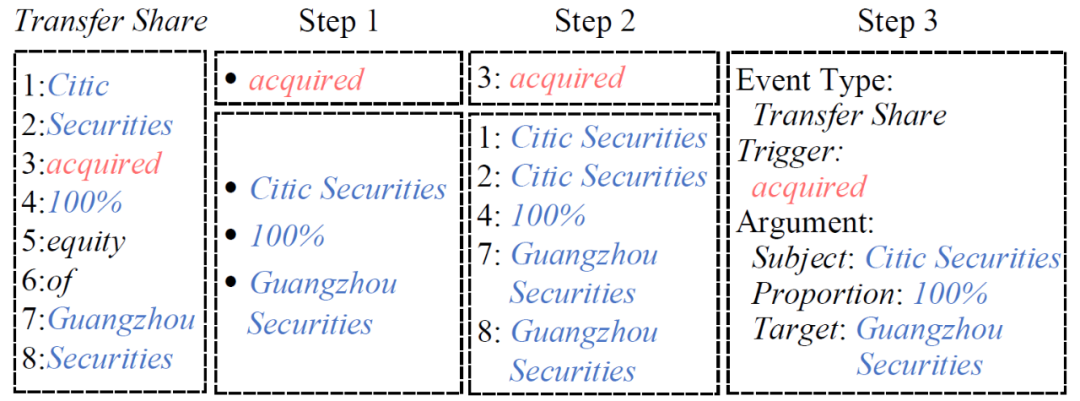
在解码阶段,该模型通过将事件类型 Embedding 并行地插入自适应事件融合层来抽取所有事件。如图 4 所示,一旦该模型在一个阶段预测了某种事件类型的所有标签,整个解码过程可以概括为四个步骤:首先,获得触发词或论元的开始和结束索引;其次,获得触发词和论元的 span;第三,根据 R-* 关系匹配触发词和论元;最后,将事件类型分配给该事件结构。
▲ 图4:解码示例
![]()
实验结果
本文在 3 个重叠和嵌套的事件抽取数据集上(包括英文和中文)进行了实验,分别是:
1. FewFC,一个中文金融事件抽取数据集,标注了 10 种事件类型和 18 种论元,有约 22% 的句子包含重叠事件;
2. Genia 11 和 Genia 13,两个英文医学领域数据集,有约 18% 的句子包含嵌套事件,Genia11 标注了 9 种事件类型和 10 种论元,而 Genia13 的数字是 13 和 7。
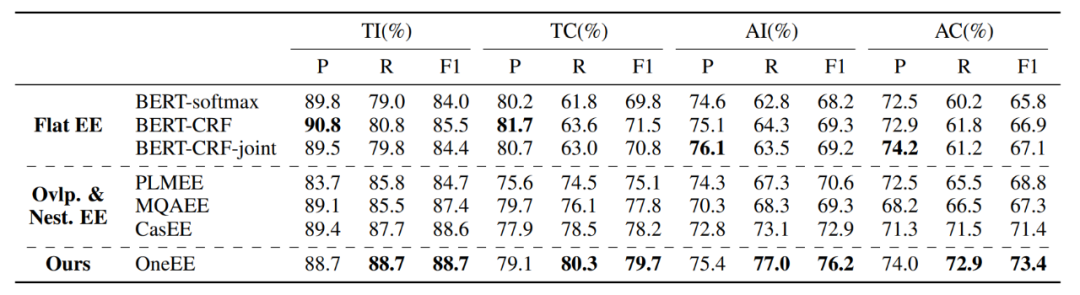
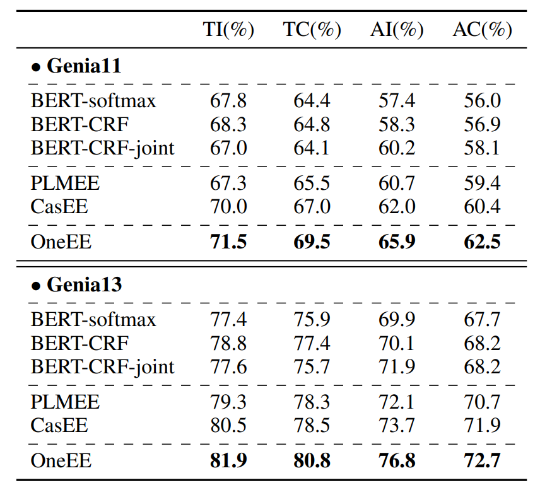
表 1-2 分别展示了上述任务和数据集上与基线模型对比的结果。实验结果表明,本文提出的基于词对关系分类的 One-Stage 方法,可以同时解决重叠和嵌套的事件抽取,并在 3 个数据集上的效果都优于之前的工作,并且推理速度也是最快的。
![]()
▲ 表1:FewFC, 重叠事件抽取
▲ 表2:Genia 11和Genia 13, 嵌套事件抽取
![]()
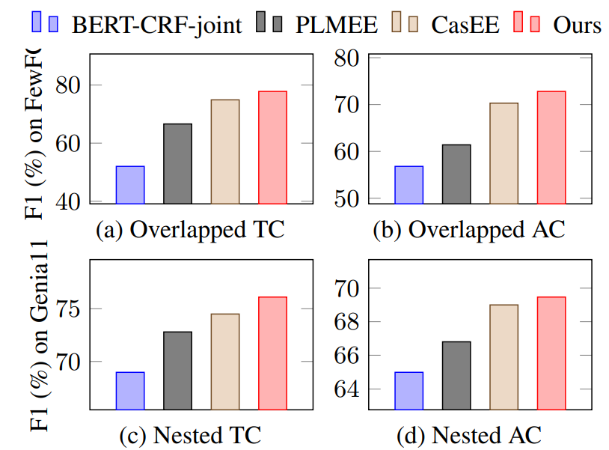
▲ 图5:重叠事件与嵌套事件抽取效果对比
![]()
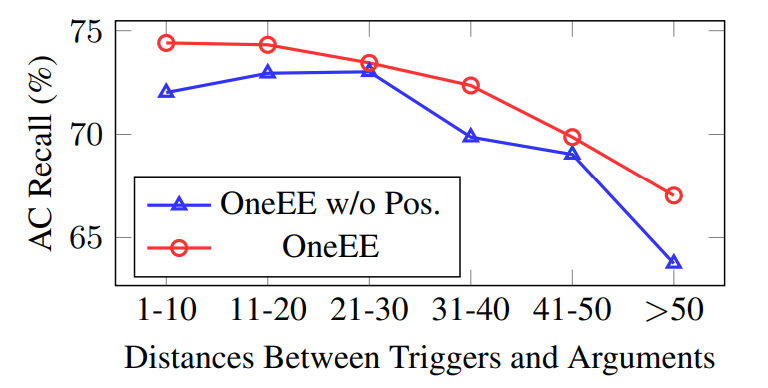
▲ 图6:触发词和论元不同距离论元角色抽取效果对比
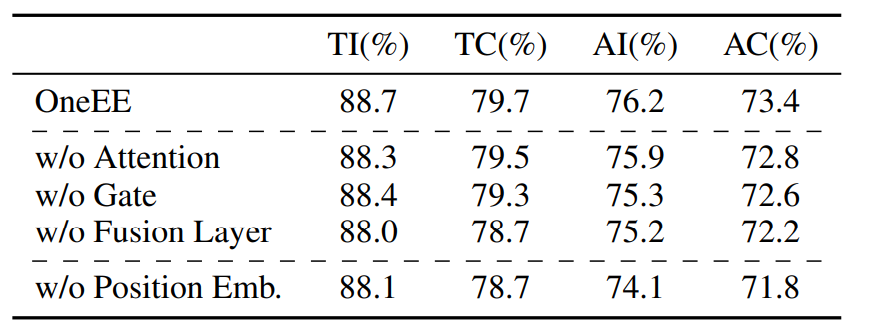
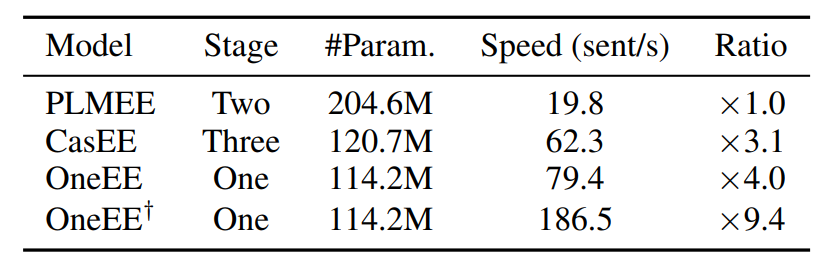
通过进一步的消融实验,我们探索了不同参数和部件对整体框架的影响。此外我们模型在相对较小的参数情况下,其训练和推理速度超过了多个非连续实体识别模型。
![]()
▲ 表6:消融实验
![]()
▲ 表7:模型参数与效率对比
![]()
在本文中,我们提出了一种基于词-词关系识别的新型单阶段框架,以同时解决重叠和嵌套的事件抽取。词对之间的关系被预定义为触发词或论元内的词-词关系以及跨越触发词-论元对。此外,我们提出了一个有效的模型,该模型由一个用于融合目标事件表示的自适应事件融合层和一个用于联合识别各种关系的距离感知的预测层组成。实验结果表明,我们提出的模型在三个数据集上实现了新的 SoTA 结果,并且比 SoTA 模型更快。
![]()
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
点击「关注」订阅我们的专栏吧
![]()