论文浅尝 | 基于异质图交互模型进行篇章级事件抽取

笔记整理:娄东方,浙江大学 & 恒生电子股份有限公司博士后,研究方向为事件抽取
来源:ACL2021
链接:https://arxiv.org/abs/2105.14924
GitHub项目地址:https://github.com/RunxinXu/GIT
本文关注篇章事件抽取——建模篇章信息,从中发现事件,并抽取事件各角色对应属性。现有方法主要关注句子事件抽取(假设事件属性分布在同一句内/较小文本片段内),它们无法适用于事件属性分散在篇章中多个句子的情形。如下图所示,

篇章事件抽取问题的挑战包括事件属性分散(EO事件中,“Xiaoting Wu”出现在句子3和句子4中,“Nov 6, 2014”则出现在句子1和句子2中)和多事件(关联性事件“股票增持”和“股票减持”)。现有方法DCFEE、Doc2EDAG等一般独立地抽取事件,忽略它们之间内在关联性。
本文提出的Graph-based Interaction Model with a Tracker (GIT)方法基于异质图网络完成篇章内句子、实体提及之间的交互,并引入tracker跟踪预测事件记录以及role对应抽取记录。试验证明它能增强实现篇章理解和事件关联建模。
Motivation
针对篇章级事件抽取问题面临的两个挑战,作者分别设计相应模块予以解决。
1.同一事件属性分散在篇章不同句子,需要对篇章信息充分理解。考虑构建句子和实体提及的异质图,将实体之间、句子之间、实体与句子之间的信息建模起来,并应用GNN网络进行编码,增强实体提及和句子向量表示,篇章理解更细致;2.建模事件之间的依赖性。考虑将当前篇章中已抽取的事件记录用memory存储下来,在预测当前事件角色对应属性过程中将memory中的信息考虑进来,从而使得事件关联信息被捕捉到。
Model
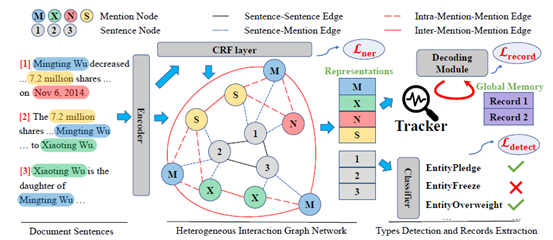
上图所示为本文提出GIT事件抽取框架。主要包括如下模块:
1.句子编码:将篇章的所有句子进行独立编码,模型为Transformer结构;
2.实体提及预测:基于句子编码结果(每个token表示) + CRF解码得到每个句子的实体提及预测结果;
3.构建异质图:
•节点:句子、候选实体提及(上一步的结果);
•边:句-句关系(全连接)、句内属性之间关系(句内属性全连接)、属性-句关系(属性与所在句相连)、跨句同名属性关系(篇章同名属性全连接)
4.GNN编码器:输出所有句子和实体提及对应的向量表示,它们已捕捉到全篇章信息;
5.事件类型发现:基于多头机制将所有句子信息整合起来,获取每个事件类型对应的向量表示,
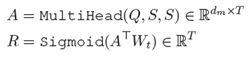
并采用多标签分类方式学习事件类型,对应损失函数为,
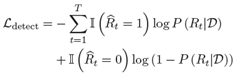
6.多事件属性抽取。如图所示,抽取步骤及原则如下,
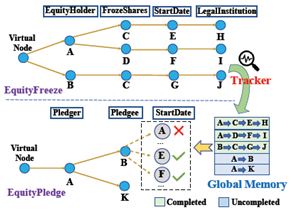
•按照给定事件类型逐个抽取事件(例如,先抽EquityFreeze类型,再抽EquityPledge类型),按照给定角色顺序逐个抽取属性(在EquityFreeze类型的事件中,角色抽取顺序为EquityHolder、FrozeShares、StartDate…)•构建tracker实时记录当前抽取情况,存入memory,并在当前角色的属性预测过程中将memory中的信息考虑进来。具体而言,当前角色属性抽取考虑的因素包括
•基于Transformer更新候选实体在当前角色下的向量表示,

基于更新之后的候选实体表示 E ̃ 进行二分类,确定每个实体是否能成为当前“事件+角色”对应的属性。属性抽取对应的损失函数为
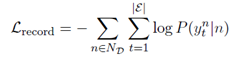
最终总损失包括:实体提及损失、事件类型发现损失和属性抽取损失之和。
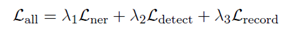
Experiment
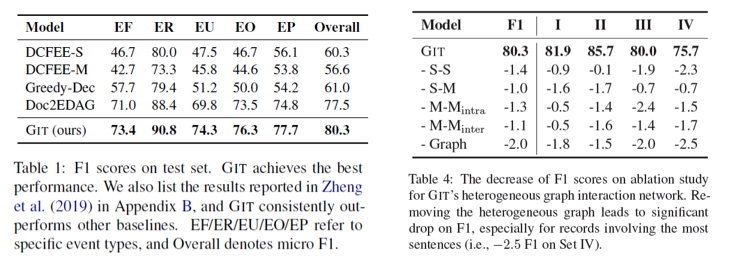
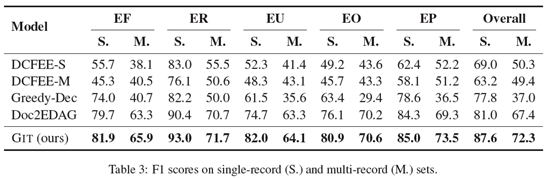
实验在中文金融事件抽取数据ChFinAnn上进行,结果表明GIT方法在该数据上达到SOTA;在单事件和多事件情况下表现都能显著提升,基于GNN的异质图编码对文档理解充分、基于tracker的事件关联建模能增强多事件表现等。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。



