教程 | 如何解决LSTM循环神经网络中的超长序列问题
选自MachineLearningMastery
作者:Jason Brownlee
机器之心编译
参与:李泽南
在 LSTM 循环神经网络面临长序列输入时,我们应该怎样应对?Jason Brownlee 给了我们 6 种解决方案。
长短期记忆(LSTM)循环神经网络可以学习和记忆长段序列的输入。如果你的问题对于每个输入都有一个输出(如时间序列预测和文本翻译任务),那么 LSTM 可以运行得很好。但 LSTM 在面临超长输入序列——单个或少量输出的情形时就会遇到困难了。这种问题通常被称为序列标记,或序列分类。
其中的一些例子包括:
包含数千个单词的文本内容情绪分类(自然语言处理)。
分类数千个时间步长的脑电图数据(医疗领域)。
分类数千个 DNA 碱基对的编码/非编码基因序列(基因信息学)。
当使用循环神经网络(如 LSTM)时,这些所谓的序列分类任务需要特殊处理。在这篇文章中,你将发现 6 种处理长序列的方法。
1. 原封不动
原封不动地训练/输入,这或许会导致训练时间大大增长。另外,尝试在很长的序列里进行反向传播可能会导致梯度消失,反过来会削弱模型的可靠性。在大型 LSTM 模型中,步长通常会被限制在 250-500 之间。
2. 截断序列
处理非常长的序列时,最直观的方式就是截断它们。这可以通过在开始或结束输入序列时选择性地删除一些时间步来完成。这种方式通过失去部分数据的代价来让序列缩短到可以控制的长度,而风险也显而易见:部分对于准确预测有利的数据可能会在这个过程中丢失。
3. 总结序列
在某些领域中,我们可以尝试总结输入序列的内容。例如,在输入序列为文字的时候,我们可以删除所有低于指定字频的文字。我们也可以仅保留整个训练数据集中超过某个指定值的文字。总结可以使得系统专注于相关性最高的问题,同时缩短了输入序列的长度。
4. 随机取样
相对更不系统的总结序列方式就是随机取样了。我们可以在序列中随机选择时间步长并删除它们,从而将序列缩短至指定长度。我们也可以指定总长的选择随机连续子序列,从而兼顾重叠或非重叠内容。
在缺乏系统缩短序列长度的方式时,这种方法可以奏效。这种方法也可以用于数据扩充,创造很多可能不同的输入序列。当可用的数据有限时,这种方法可以提升模型的鲁棒性。
5. 时间截断的反向传播
除基于整个序列更新模型的方法之外,我们还可以在最后的数个时间步中估计梯度。这种方法被称为「时间截断的反向传播(TBPTT)」。它可以显著加速循环神经网络(如 LSTM)长序列学习的过程。
这将允许所有输入并执行的序列向前传递,但仅有最后数十或数百时间步会被估计梯度,并用于权重更新。一些最新的 LSTM 应用允许我们指定用于更新的时间步数,分离出一部分输入序列以供使用。例如:
Theano 中的「truncate_gradient」参数:http://deeplearning.net/software/theano/library/scan.html
6. 使用编码器-解码器架构
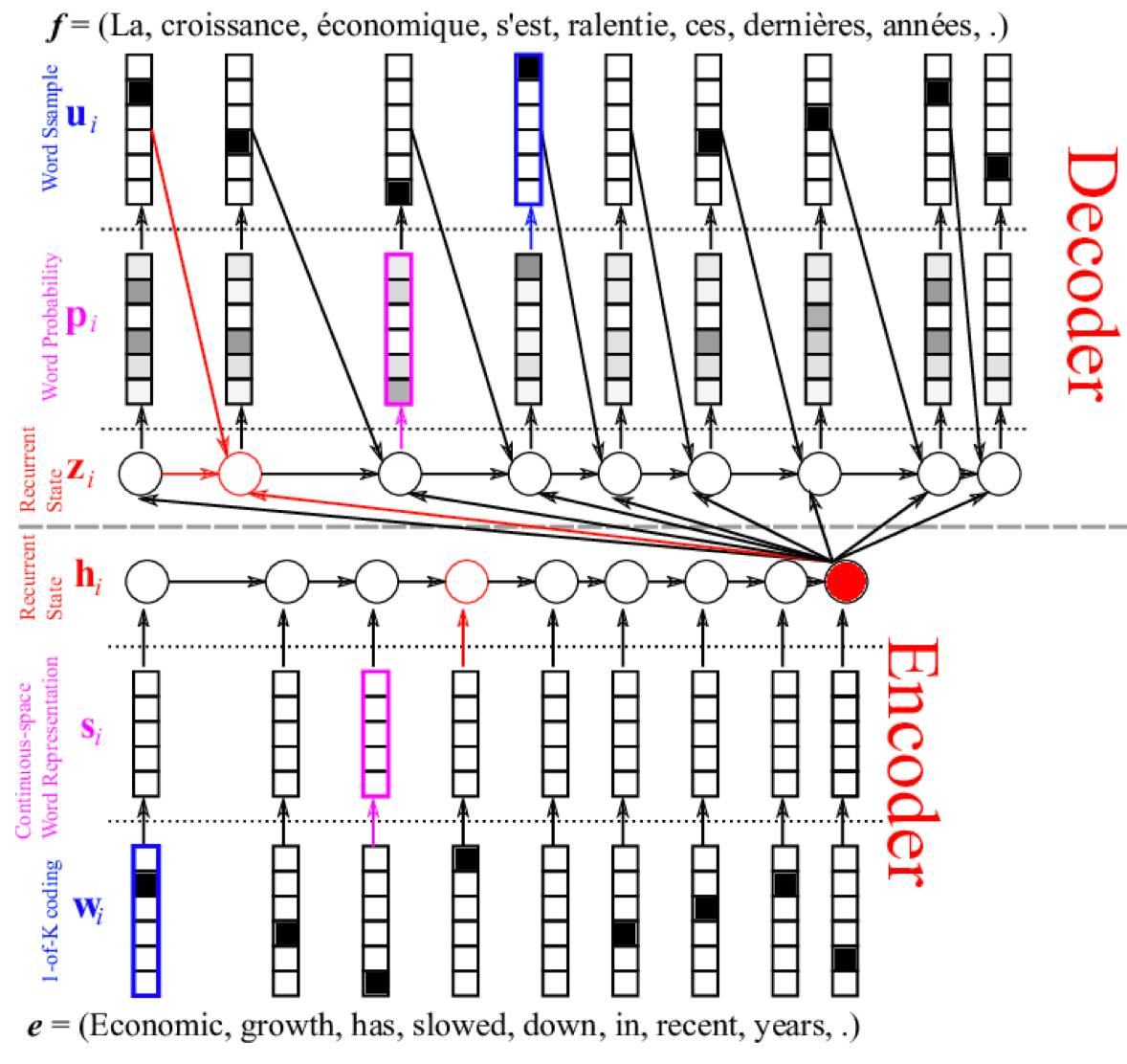
你可以使用自编码器来让长序列表示为新长度,然后解码网络将编码表示解释为所需输出。这可以是让无监督自编码器成为序列上的预处理传递者,或近期用于神经语言翻译的编码器-解码器 LSTM 网络。
当然,目前机器学习系统从超长序列中学习或许仍然非常困难,但通过复杂的架构和以上一种或几种方法的结合,我们是可以找到办法解决这些问题的。
其他疯狂的想法
这里还有一些未被充分验证过的想法可供参考。
将输入序列拆分为多个固定长度的子序列,并构建一种模型,将每个子序列作为单独的特征(例如并行输入序列)进行训练。
双向 LSTM,其中每个 LSTM 单元对的一部分处理输入序列的一半,在输出至层外时组合。这种方法可以将序列分为两块或多块处理。
我们还可以探索序列感知编码方法、投影法甚至哈希算法来将时间步的数量减少到指定长度。
扩展阅读
序列标记:https://en.wikipedia.org/wiki/Sequence_labeling
序列分类简述:http://dl.acm.org/citation.cfm?id=1882478

原文链接:http://machinelearningmastery.com/handle-long-sequences-long-short-term-memory-recurrent-neural-networks/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击阅读原文,查看机器之心官网↓↓↓




