技术 | 如何在Python下生成用于时间序列预测的LSTM状态
长短期记忆网络(LSTM)是一种强大的递归神经网络,能够学习长观察值序列。
LSTM的一大优势是它们能有效地预测时间序列,但是作这种用途时配置和使用起来却较为困难。
LSTM的一个关键特性是它们维持一个内部状态,该状态能在预测时提供协助。这就引出了这样一个问题:如何在进行预测之前在合适的 LSTM 模型中初始化状态种子。
在本教程中,你将学习如何设计、进行试验并解释从试验中得出的结果,探讨是用训练数据集给合适的 LSTM 模型初始化状态种子好还是不使用先前状态好。
在完成本教程的学习后,你将了解:
关于如何为合适的 LSTM 预测模型预置状态的开放式问题。
如何开发出强大的测试工具,用于评测 LSTM 模型解决单变量时间序列预测问题的能力。
如何判断在解决您的时间序列预测问题时,于预测前为LSTM状态种子初始化是否适当。
让我们开始吧。

Python中如何为LSTM 初始化状态进行时间序列预测
教程概览
该教程分为 5 部分;它们分别为:
LSTM状态种子初始化
洗发水销量数据集
LSTM 模型和测试工具
代码编写
试验结果
环境
本教程假设您已安装 Python SciPy 环境。您在学习本示例时可使用Python 2 或 3。
您必须使用TensorFlow或Theano后端安装Keras(2.0或更高版本)。
本教程还假设您已安装scikit-learn、Pandas、 NumPy和Matplotlib。
如果您在安装环境时需要帮助,请查看这篇文章:
如何使用Anaconda安装机器学习和深度学习所需的 Python 环境
http://machinelearningmastery.com/setup-python-environment-machine-learning-deep-learning-anaconda/
当在Keras中使用无状态LSTM时,您可精确控制何时清空模型内部状态。
这是通过使用model.reset_states()函数实现的。
当训练时有状态的LSTM时,清空训练epoch之间的模型状态很重要。这样的话,每个epoch在训练期间创建的状态才会与该epoch的观察值序列相匹配。
假定我们能够实现这种精确控制,还有这样一个问题:是否要以及如何在进行预测前预置LSTM的状态。
选择有:
在预测前重置状态。
在预测前使用训练数据集预置状态。
假定下,使用训练数据集预置模型状态更好,但是这需要用试验进行验证。
另外,状态初始化的方法还有很多种;例如:
完成一个训练epoch,包括权重更新。例如,在最后一个训练epoch结束后不重置状态。
完成训练数据的预测。
一般认为两种方法在某种程度上相当。预测训练数据的后者更好,因为这种方法不需要对网络权重进行任何修改,并且对于存入文件夹的不变网络而言它可以作为可重复步骤。
在本教程中,我们将考虑一下两种方法之间的差别:
使用无状态的合适 LSTM 预测测试数据集(例如在重置之后)。
在预测完训练数据集之后使用有状态的合适LSTM预测测试数据集。
下面,让我们看一下我们将在本试验中使用的标准时间序列数据集。
洗发水销量数据集
该数据集描述某洗发水在3年内的月度销量。
数据单位为销售量,共有36个观察值。原始数据集由Makridakis、Wheelwright和Hyndman(1998)提供。
您可通过此链接下载和进一步了解该数据集:
https://datamarket.com/data/set/22r0/sales-of-shampoo-over-a-three-year-period
下方示例代码加载并生成已加载数据集的视图。
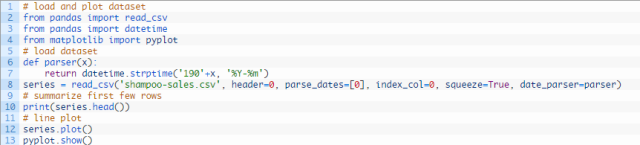
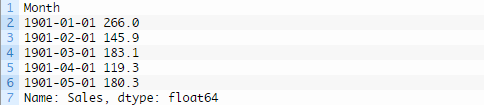
运行该示例,以Pandas序列的形式加载数据集,并打印出头5行。
然后就可生成显示明显增长趋势的序列线图。
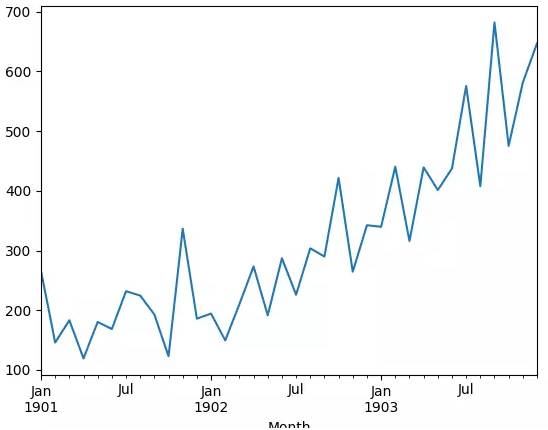
洗发水销量线图
接下来,我们将看一下本试验中使用的LSTM配置和测试工具。
3. LSTM模型和测试工具
数据划分
我们将把洗发水销量数据集分为两个集合:一个训练集和一个测试集。
前两年的销售数据将作为训练数据集,最后一年的数据将作为测试集。
我们将使用训练数据集创建模型,然后对测试数据集进行预测。
模型评测
我们将使用滚动预测的方式,也称为步进式模型验证。
以每次一个的形式运行测试数据集的每个时间步。使用模型对时间步作出预测,然后收集测试组生成的实际预期值,模型将利用这些预期值预测下一时间步。
这模拟了现实生活中的场景,新的洗发水销量观察值会在月底公布,然后被用于预测下月的销量。
训练数据集和测试数据集的结构将对此进行模拟。我们将一步生成所有的预测。
最后,收集所有测试数据集的预测,计算误差值总结该模型的预测能力。采用均方根误差(RMSE)的原因是这种计算方式能够降低粗大误差对结果的影响,所得分数的单位和预测数据的单位相同,即洗发水月度销量。
数据准备
在将为数据集匹配LSTM模型前,我们必须对数据进行转化。
在匹配模型和进行预测之前须进行以下三种数据转化。
转化序列数据使其呈静态。具体来说,就是使用 lag=1差分移除数据中的增长趋势。
将时间序列问题转化为监督学习问题。具体来说,就是将数据组为输入和输出模式,上一时间步的观察值可作为输入用于预测当前时间步的观察值。
转化观察值使其处在特定区间。具体来说,就是将数据缩放带 -1至1的区间内,以满足LSTM模型默认的双曲正切激活函数。
LSTM模型
使用的 LSTM模型将能有效进行预测但是未经调整。
这意味着该模型将与数据匹配,并且能够作出有效预测,但不是匹配该数据集的最优模型。
该网络拓扑包含一个输出、一个4单位的隐藏层和一个1输出值的输出层。
该模型将匹配batch大小为4,epoch为3000的数据集。训练数据集在完成数据准备之后将减少至20个观察值。这样batch大小就可以均匀地分配给训练数据集和测试数据集(作为一项要求)。
试验运行
每种方案将进行30次试验。
这意味着每个方案将创建并评测30个模型。从每次试验收集的均方根误差(RMSE)给出结果分布,然后可使用描述统计学(如平均偏差和标准偏差)方法进行总结。
必须这样做的原因在于,与LSTM类似的神经网络会受其初始条件影响(例如它们的初始随机权重)。
这表示,每个方案的结果将使我们能够解释每个方案的平均性能以及它们的对比情况。
让我们研究一下这些结果。
为了使你能重复利用这个试验设置,关键的模块化行为被分为可读性好的函数和可测试性好的函数。
experiment()函数描述了各方案的参数。
完整的代码编写如下方所示:
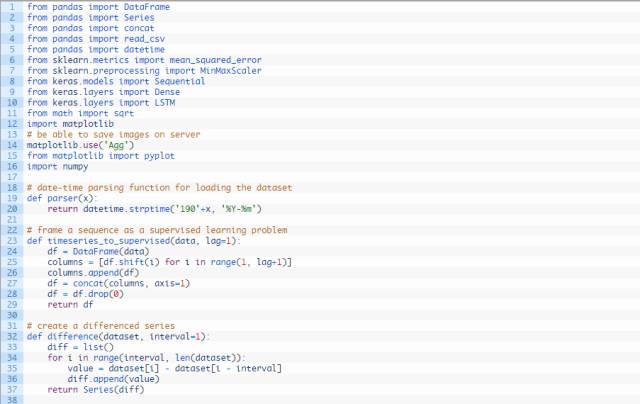
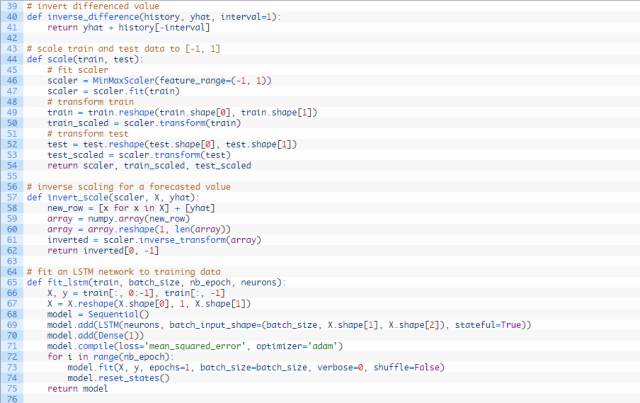
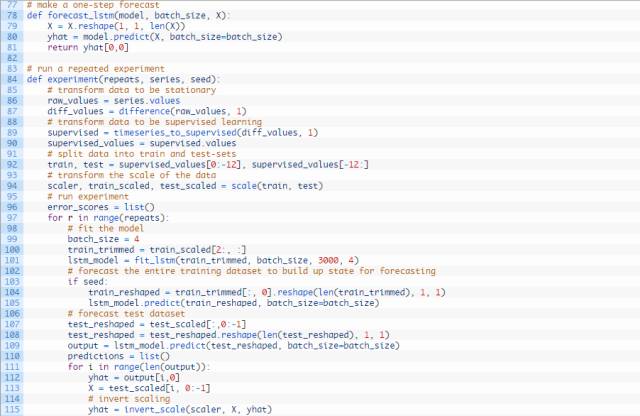
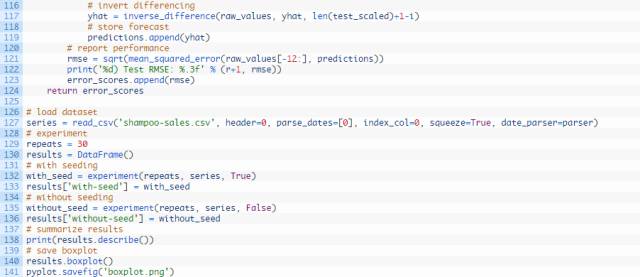
运行试验需要花费一些时间或者消耗CPU或GPU硬件。
打印每次试验的均方根误差以表现出进行状态。
在每次试验结束时,计算并打印每种方案的总结数据,包括均值偏差和标准偏差。
完整的输出结果如下所示:
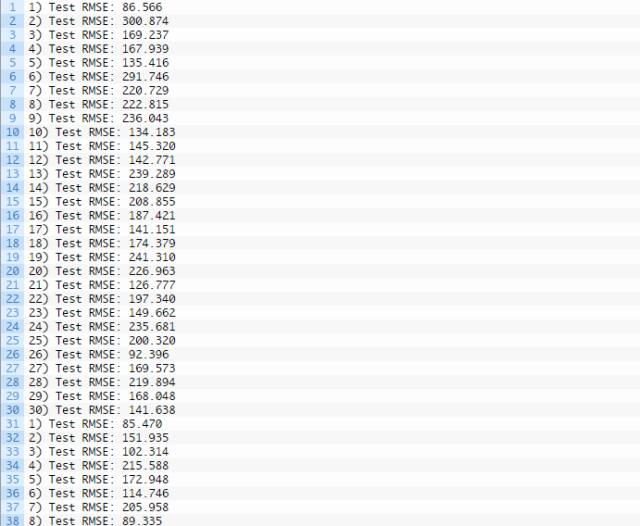
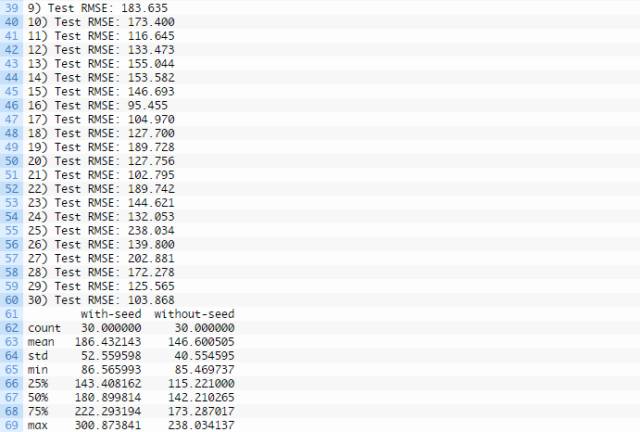
另外生成一个盒须图并保存至文件夹,如下所示:
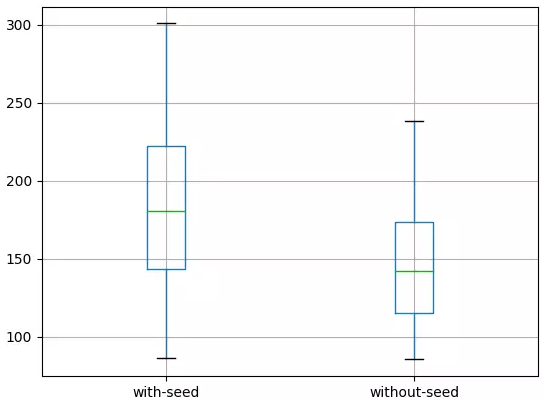
初始化和未初始化的LSTM的盒须图
结果很令人意外。
它们表明,在预测测试数据集之前未初始化LSTM状态种子的方案得出的结果更好。
将这种方案预测的平均误差(146.6005050)和另一种方案(初始化状态种子)预测的平均误差(186.432143)做对比即可得出上结论。通过盒须图可以看得更加清楚。
也许选择的模型配置使创建的模型过小而使得预测前初始化状态种子的优点无法在序列和内部状态上显示出来。也可能需要进行更大型的试验。
延伸
令人意外的结果为进一步试验创造了条件。
评测在每次训练epoch结束之后清空和不清空状态产生的影响。
评测一次性预测训练集和测试集对比每次预测一个时间步的影响。
评测在每个epoch结束后重置和不重置LSTM状态的影响。
你尝试过这些延伸试验吗?
总结
通过学习本教程,你学会了如何在解决单变量时间序列预测问题时用试验的方法确定初始化LSTM状态种子的最佳方法。
具体而言,你学习了:
关于在预测前初始化LSTM状态种子的问题和解决该问题的方法。
如何开发出强大的测试工具,评测LSTM模型解决时间序列问题的性能。
如何确定是否在预测前使用训练数据初始化LSTM模型状态种子。
本文作者 Jason Brownlee 博士是一位学术研究员、作家、专业开发者和机器学习从业人员。他致力于帮助开发者开始学习并掌握机器学习应用。
原文地址
https://machinelearningmastery.com/seed-state-lstms-time-series-forecasting-python/
AI科技大本营目前招聘资深AI采编。AI时代,和我们一起做最贴近AI的媒体!详细职位要求和简历投递方式请见☟☟☟(向下滑动详情)。
要求:
1.熟悉AI领域,对大公司、AI大牛的动态有极强敏感性,且有深度剖析的楞劲儿。
2.英语能力六级以上,看得懂文章,做得了编译,听得懂外文,做得了采访。
3.对AI相关的技术有一定的理解,能追踪最新的技术热点。
4.写稿、编译速度快,快速成稿能力非常重要。
5.语言能力强,行文流畅,写作风格不僵化不生硬。
6.相关媒体经验2年以上。
7.有过重磅深度稿件者优先。
8.对自己极高的要求,工作有极大热情,对成长有极强的动力。
9.时刻保持谦虚,能随时调整状态,跟团队目标紧密配合。
有意者,请将简历投至puge@ai100.ai,标题注明:姓名+手机号+AI采编。有疑问请加微信greta1314。

☞ 点击阅读原文,查看详细课程信息。



