资源 | 清华大学发布OpenNE:用于网络嵌入的开源工具包
选自THUNLP
机器之心编译
参与:刘晓坤、路雪
为了方便大家对网络表示学习(NE/NRL)开展相关的实验或研究,清华大学计算机科学与技术系的研究人员在 GitHub 上发布了 NE/NRL 训练和测试框架 OpenNE,其中统一了 NE 模型输入/输出/评测接口,并且修订和复现了目前比较经典的网络表征学习模型。该项目还在持续开发中,作者还提供了与未扩展模型的比较结果。
项目链接:https://github.com/thunlp/OpenNE
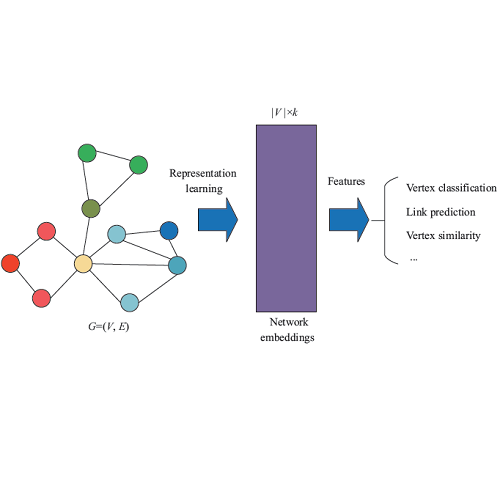
本项目是一个标准的 NE/NRL(Network Representation Learning,网络表征学习)训练和测试框架。在这个框架中,我们统一了不同 NE 模型输入和输出接口,并为每个模型提供可扩展选项。此外,我们还在这个框架中用 TensorFlow 实现了经典 NE 模型,使这些模型可以用 GPU 训练。
我们根据 DeepWalk 的设置开发了这个工具包, 实现和修改的模型包括 DeepWalk、LINE、node2vec、GraRep、TADW 和 GCN。我们还将根据已公布的 NRL 论文发表持续实现更多有代表性的 NE 模型。特别地,我们欢迎其他研究者在该框架中构建 NE 模型到这个工具包中,也会公布项目中的贡献内容。
配置需求
numpy==1.13.1
networkx==2.0
scipy==0.19.1
tensorflow==1.3.0
gensim==3.0.1
scikit-learn==0.19.0
使用
通用选项
如果想查看其它可用的 OpenNE 选项,请输入以下命令:
python src/main.py --help
input,一个网络的输入文件;
graph-format,输入图的格式,类邻接表或边表;
output,表征的输出文件;
representation-size,用于学习每个节点的隐维数,默认为 128;
method,NE 模型的学习方法,包括 deepwalk、line、node2vec、grarep、tadw 和 gcn;
directed,将图转换为定向的;
weighted,将图加权;
label-file,节点标签的文件;只在测试时使用;
clf-ratio,节点分类的训练数据的比例;默认值为 0.5;
epochs,LINE 和 GCN 的训练 epoch 数;默认值为 5;
样例
在 BlogCatalog 网络上运行「node2vec」,评估多标签节点分类任务上的学习表征,并在这个项目的主目录上运行以下命令:
python src/main.py --method node2vec --label-file data/blogCatalog/bc_labels.txt --input data/blogCatalog/bc_adjlist.txt --graph-format adjlist --output vec_all.txt --q 0.25 --p 0.25
在 Cora 网络上运行「gcn」,并在多标签节点分类任务上评估学习表征,在这个项目的主目录上运行以下命令:
python src/main.py --method gcn --label-file data/cora/cora_labels.txt --input data/cora/cora_edgelist.txt --graph-format edgelist --feature-file data/cora/cora.features --epochs 200 --output vec_all.txt --clf-ratio 0.1
特定选项
DeepWalk 和 node2vec:
number-walks,每个节点起始的随机行走数目;默认值为 10;
walk-length,每个节点起始的随机行走步长;默认值为 80;
workers,平行处理的数量;默认值为 8;
window-size,skip-gram 模型的 window-size;默认值为 10;
q,只用于 node2vec;默认值为 1.0;
p,只用于 node2vec;默认值为 1.0;
LINE:
negative-ratio,默认值为 5;
order,1 为 1 阶模型,2 为 2 阶模型;默认值为 3;
no-auto-stop,训练 LINE 时不使用早期停止法;训练 LINE 的时候,对每个 epoch 计算 micro-F1。如果当前的 micro-F1 小于上一个,训练过程将使用早期停止法;
GraRep:
kstep,使用 k-step 转移概率矩阵(确保 representation-size%k-step == 0);
TADW:
lamb,lamb 是 TADW 中控制正则化项的权重的参数;
GCN:
feature-file,节点特征的文件;
epochs,GCN 的训练 epoch 数;默认值为 5;
dropout,dropout 率;
weight-decay,嵌入矩阵的 L2 损失的权重;
hidden,第一个隐藏层的单元数量;
输入
支持的输入格式是边表(edgelist)或类邻接表(adjlist):
edgelist: node1 node2 <weight_float, optional>
adjlist: node n1 n2 n3 ... nk
默认图为非定向、未加权。这些选项可以通过设置合适的 flag 进行修改。
如果该模型需要额外的特征,支持的特征输入格式如下(feature_i 指浮点):
node feature_1 feature_2 ... feature_n
输出
带有 n 个节点的图的输入文件有 n+1 行。第一行的格式为:
num_of_nodes dim_of_representation
下面 n 行的格式为:
node_id dim1 dim2 ... dimd
其中,dim1, ... , dimd 是 OpenNE 学到的 d 维表示。
评估
如果你想评估学得的节点表征,你可以输入节点标签。它将使用一部分节点(默认:50%)来训练分类器,在剩余的数据集上计算 F1 得分。
支持的输入标签格式为:
node label1 label2 label3...
与其他实现进行对比
运行环境:CPU: Intel(R) Xeon(R) CPU E5-2620 v3 @ 2.40GHz
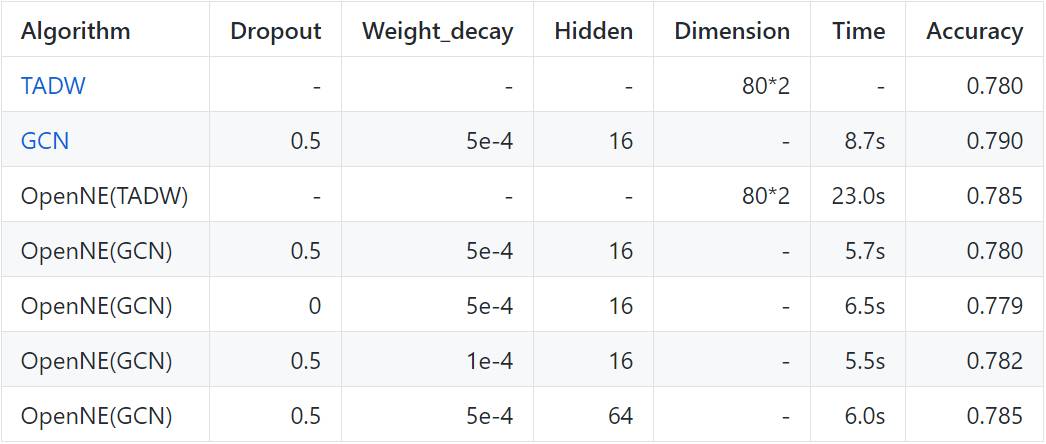
我们展示了在不同数据集上对不同方法的节点分类结果。我们将表征维度设置为 128,GraRep 中的 kstep=4,node2vec 中 p=1,q=1。
注意:GCN(半监督 NE 模型)和 TADW 需要额外的文本特征作为输入。因此,我们在 Cora 上评估这两个模型,Cora 的每个节点都有文本信息。我们使用 10% 的标注数据来训练 GCN。
BlogCatalog:10312 节点,333983 边缘,39 标签,非定向:
data/blogCatalog/bc_adjlist.txt
data/blogCatalog/bc_edgelist.txt
data/blogCatalog/bc_labels.txt
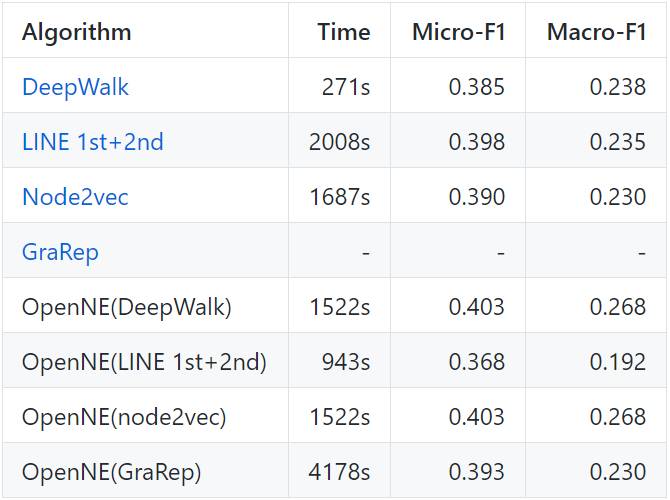
Wiki:2405 节点,17981 边缘,19 标签,定向:
data/wiki/Wiki_edgelist.txt
data/wiki/Wiki_category.txt
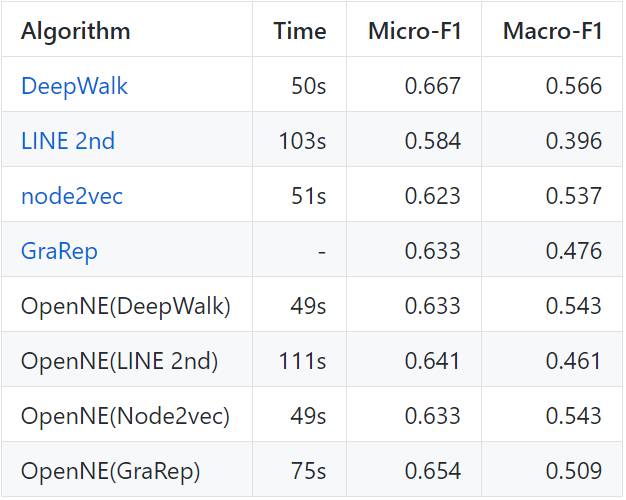
cora:2708 节点,5429 边缘,7 标签,定向:
data/cora/cora_edgelist.txt
data/cora/cora.features
data/cora/cora_labels.txt
引用
如果 OpenNE 对你的研究有用,请考虑引用以下论文:
@InProceedings{perozzi2014deepwalk,
Title = {Deepwalk: Online learning of social representations},
Author = {Perozzi, Bryan and Al-Rfou, Rami and Skiena, Steven},
Booktitle = {Proceedings of KDD},
Year = {2014},
Pages = {701--710}
}
@InProceedings{tang2015line,
Title = {Line: Large-scale information network embedding},
Author = {Tang, Jian and Qu, Meng and Wang, Mingzhe and Zhang, Ming and Yan, Jun and Mei, Qiaozhu},
Booktitle = {Proceedings of WWW},
Year = {2015},
Pages = {1067--1077}
}
@InProceedings{grover2016node2vec,
Title = {node2vec: Scalable feature learning for networks},
Author = {Grover, Aditya and Leskovec, Jure},
Booktitle = {Proceedings of KDD},
Year = {2016},
Pages = {855--864}
}
@article{kipf2016semi,
Title = {Semi-Supervised Classification with Graph Convolutional Networks},
Author = {Kipf, Thomas N and Welling, Max},
journal = {arXiv preprint arXiv:1609.02907},
Year = {2016}
}
@InProceedings{cao2015grarep,
Title = {Grarep: Learning graph representations with global structural information},
Author = {Cao, Shaosheng and Lu, Wei and Xu, Qiongkai},
Booktitle = {Proceedings of CIKM},
Year = {2015},
Pages = {891--900}
}
@InProceedings{yang2015network,
Title = {Network representation learning with rich text information},
Author = {Yang, Cheng and Liu, Zhiyuan and Zhao, Deli and Sun, Maosong and Chang, Edward},
Booktitle = {Proceedings of IJCAI},
Year = {2015}
}
@Article{tu2017network,
Title = {Network representation learning: an overview},
Author = {TU, Cunchao and YANG, Cheng and LIU, Zhiyuan and SUN, Maosong},
Journal = {SCIENTIA SINICA Informationis},
Volume = {47},
Number = {8},
Pages = {980--996},
Year = {2017}
}
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com