华为提出PyramidTNT:用金字塔结构改进Transformer!涨点明显!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

Transformer在计算机视觉任务方面取得了很大的进展。Transformer-in-Transformer (TNT)体系结构利用内部Transformer和外部Transformer来提取局部和全局表示。在这项工作中,通过引入2种先进的设计来提出新的TNT Baseline:
Pyramid Architecture
Convolutional Stem
新的“PyramidTNT”通过建立层次表示,显著地改进了原来的TNT。PyramidTNT相较于之前最先进的Vision Transformer具有更好的性能,如Swin-Transformer。
1简介
Vision Transformer为计算机视觉提供了一种新的解决思路。从ViT开始,提出了一系列改进Vision Transformer体系结构的工作。
-
PVT介绍了Vision Transformer的金字塔网络体系结构
-
T2T-ViT-14 递归地将相邻的Token聚合为一个Token,以提取局部结构,减少Token的数量
-
TNT 利用 inner Transformer和outer Transformer来建模 word-level 和 sentence-level 的视觉表示
-
Swin-Transformer提出了一种分层Transformer,其表示由Shifted windows来进行计算
随着近年来的研究进展,Vision Transformer的性能已经可以优于卷积神经网络(CNN)。而本文的这项工作是建立了基于TNT框架的改进的 Vision Transformer Baseline。这里主要引入了两个主要的架构修改:
-
Pyramid Architecture:逐渐降低分辨率,提取多尺度表示
-
Convolutional Stem:修补Stem和稳定训练
这里作者还使用了几个其他技巧来进一步提高效率。新的Transformer被命名为PyramidTNT。
对图像分类和目标检测的实验证明了金字塔检测的优越性。具体来说,PyramidTNT-S在只有3.3B FLOPs的情况下获得了82.0%的ImageNet分类准确率,明显优于原来的TNT-S和Swin-T。
对于COCO检测,PyramidTNT-S比现有的Transformer和MLP检测模型以更少的计算成本实现42.0的mAP。
2本文方法
2.1 Convolutional Stem
给定一个输入图像 ,TNT模型首先将图像分割成多个patch,并进一步将每个patch视为一个sub-patch序列。然后应用线性层将sub-patch投射到visual word vector(又称token)。这些视觉word被拼接在一起并转换成一个visual sentence vector。
肖奥等人发现在ViT中使用多个卷积作为Stem可以提高优化稳定性,也能提高性能。在此基础上,本文构造了一个金字塔的卷积Stem。利用3×3卷积的堆栈产生visual word vector ,其中C是visual word vector的维度。同样也可以得到visual sentence vector ,其中D是visual sentence vector 的维度。word-level 和 sentence-level位置编码分别添加到visual words和sentences上,和原始的TNT一样。
class Stem(nn.Module):
"""
Image to Visual Word Embedding
"""
def __init__(self, img_size=224, in_chans=3, outer_dim=768, inner_dim=24):
super().__init__()
img_size = to_2tuple(img_size)
self.img_size = img_size
self.inner_dim = inner_dim
self.num_patches = img_size[0] // 8 * img_size[1] // 8
self.num_words = 16
self.common_conv = nn.Sequential(
nn.Conv2d(in_chans, inner_dim*2, 3, stride=2, padding=1),
nn.BatchNorm2d(inner_dim*2),
nn.ReLU(inplace=True),
)
# 利用 inner Transformer来建模 word-level
self.inner_convs = nn.Sequential(
nn.Conv2d(inner_dim*2, inner_dim, 3, stride=1, padding=1),
nn.BatchNorm2d(inner_dim),
nn.ReLU(inplace=False),
)
# 利用outer Transformer来建模 sentence-level 的视觉表示
self.outer_convs = nn.Sequential(
nn.Conv2d(inner_dim*2, inner_dim*4, 3, stride=2, padding=1),
nn.BatchNorm2d(inner_dim*4),
nn.ReLU(inplace=True),
nn.Conv2d(inner_dim*4, inner_dim*8, 3, stride=2, padding=1),
nn.BatchNorm2d(inner_dim*8),
nn.ReLU(inplace=True),
nn.Conv2d(inner_dim*8, outer_dim, 3, stride=1, padding=1),
nn.BatchNorm2d(outer_dim),
nn.ReLU(inplace=False),
)
self.unfold = nn.Unfold(kernel_size=4, padding=0, stride=4)
def forward(self, x):
B, C, H, W = x.shape
H_out, W_out = H // 8, W // 8
H_in, W_in = 4, 4
x = self.common_conv(x)
# inner_tokens建模word level表征
inner_tokens = self.inner_convs(x) # B, C, H, W
inner_tokens = self.unfold(inner_tokens).transpose(1, 2) # B, N, Ck2
inner_tokens = inner_tokens.reshape(B * H_out * W_out, self.inner_dim, H_in*W_in).transpose(1, 2) # B*N, C, 4*4
# outer_tokens建模 sentence level表征
outer_tokens = self.outer_convs(x) # B, C, H_out, W_out
outer_tokens = outer_tokens.permute(0, 2, 3, 1).reshape(B, H_out * W_out, -1)
return inner_tokens, outer_tokens, (H_out, W_out), (H_in, W_in)
2.2 Pyramid Architecture
原始的TNT网络在继ViT之后的每个块中保持相同数量的token。visual words和visual sentences的数量从下到上保持不变。
本文受PVT的启发,为TNT构建了4个不同数量的Token阶段,如图1(b)。所示在这4个阶段中,visual words的空间形状分别设置为H/2×W/2、H/4×W/4、H/8×W/8、H/16×W/16;visual sentences的空间形状分别设置为H/8×W/8、H/16×W/16、H/32×W/32、H/64×W/64。下采样操作是通过stride=2的卷积来实现的。每个阶段由几个TNT块组成,TNT块在word-level 和 sentence-level特征上操作。最后,利用全局平均池化操作,将输出的visual sentences融合成一个向量作为图像表示。

class SentenceAggregation(nn.Module):
"""
Sentence Aggregation
"""
def __init__(self, dim_in, dim_out, stride=2, act_layer=nn.GELU):
super().__init__()
self.stride = stride
self.norm = nn.LayerNorm(dim_in)
self.conv = nn.Sequential(
nn.Conv2d(dim_in, dim_out, kernel_size=2*stride-1, padding=stride-1, stride=stride),
)
def forward(self, x, H, W):
B, N, C = x.shape # B, N, C
x = self.norm(x)
x = x.transpose(1, 2).reshape(B, C, H, W)
x = self.conv(x)
H, W = math.ceil(H / self.stride), math.ceil(W / self.stride)
x = x.reshape(B, -1, H * W).transpose(1, 2)
return x, H, W
class WordAggregation(nn.Module):
"""
Word Aggregation
"""
def __init__(self, dim_in, dim_out, stride=2, act_layer=nn.GELU):
super().__init__()
self.stride = stride
self.dim_out = dim_out
self.norm = nn.LayerNorm(dim_in)
self.conv = nn.Sequential(
nn.Conv2d(dim_in, dim_out, kernel_size=2*stride-1, padding=stride-1, stride=stride),
)
def forward(self, x, H_out, W_out, H_in, W_in):
B_N, M, C = x.shape # B*N, M, C
x = self.norm(x)
x = x.reshape(-1, H_out, W_out, H_in, W_in, C)
# padding to fit (1333, 800) in detection.
pad_input = (H_out % 2 == 1) or (W_out % 2 == 1)
if pad_input:
x = F.pad(x.permute(0, 3, 4, 5, 1, 2), (0, W_out % 2, 0, H_out % 2))
x = x.permute(0, 4, 5, 1, 2, 3)
# patch merge
x1 = x[:, 0::2, 0::2, :, :, :] # B, H/2, W/2, H_in, W_in, C
x2 = x[:, 1::2, 0::2, :, :, :]
x3 = x[:, 0::2, 1::2, :, :, :]
x4 = x[:, 1::2, 1::2, :, :, :]
x = torch.cat([torch.cat([x1, x2], 3), torch.cat([x3, x4], 3)], 4) # B, H/2, W/2, 2*H_in, 2*W_in, C
x = x.reshape(-1, 2*H_in, 2*W_in, C).permute(0, 3, 1, 2) # B_N/4, C, 2*H_in, 2*W_in
x = self.conv(x) # B_N/4, C, H_in, W_in
x = x.reshape(-1, self.dim_out, M).transpose(1, 2)
return x
class Stage(nn.Module):
"""
PyramidTNT stage
"""
def __init__(self, num_blocks, outer_dim, inner_dim, outer_head, inner_head, num_patches, num_words, mlp_ratio=4.,
qkv_bias=False, qk_scale=None, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU,
norm_layer=nn.LayerNorm, se=0, sr_ratio=1):
super().__init__()
blocks = []
drop_path = drop_path if isinstance(drop_path, list) else [drop_path] * num_blocks
for j in range(num_blocks):
if j == 0:
_inner_dim = inner_dim
elif j == 1 and num_blocks > 6:
_inner_dim = inner_dim
else:
_inner_dim = -1
blocks.append(Block(
outer_dim, _inner_dim, outer_head=outer_head, inner_head=inner_head,
num_words=num_words, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop,
attn_drop=attn_drop, drop_path=drop_path[j], act_layer=act_layer, norm_layer=norm_layer,
se=se, sr_ratio=sr_ratio))
self.blocks = nn.ModuleList(blocks)
self.relative_pos = nn.Parameter(torch.randn(1, outer_head, num_patches, num_patches // sr_ratio // sr_ratio))
def forward(self, inner_tokens, outer_tokens, H_out, W_out, H_in, W_in):
for blk in self.blocks:
inner_tokens, outer_tokens = blk(inner_tokens, outer_tokens, H_out, W_out, H_in, W_in, self.relative_pos)
return inner_tokens, outer_tokens
class PyramidTNT(nn.Module):
"""
PyramidTNT
"""
def __init__(self, configs=None, img_size=224, in_chans=3, num_classes=1000, mlp_ratio=4., qkv_bias=False,
qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm, se=0):
super().__init__()
self.num_classes = num_classes
depths = configs['depths']
outer_dims = configs['outer_dims']
inner_dims = configs['inner_dims']
outer_heads = configs['outer_heads']
inner_heads = configs['inner_heads']
sr_ratios = [4, 2, 1, 1]
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
self.num_features = outer_dims[-1] # num_features for consistency with other models
self.patch_embed = Stem(
img_size=img_size, in_chans=in_chans, outer_dim=outer_dims[0], inner_dim=inner_dims[0])
num_patches = self.patch_embed.num_patches
num_words = self.patch_embed.num_words
self.outer_pos = nn.Parameter(torch.zeros(1, num_patches, outer_dims[0]))
self.inner_pos = nn.Parameter(torch.zeros(1, num_words, inner_dims[0]))
self.pos_drop = nn.Dropout(p=drop_rate)
depth = 0
self.word_merges = nn.ModuleList([])
self.sentence_merges = nn.ModuleList([])
self.stages = nn.ModuleList([])
# 搭建PyramidTNT所需要的4个Stage
for i in range(4):
if i > 0:
self.word_merges.append(WordAggregation(inner_dims[i-1], inner_dims[i], stride=2))
self.sentence_merges.append(SentenceAggregation(outer_dims[i-1], outer_dims[i], stride=2))
self.stages.append(Stage(depths[i], outer_dim=outer_dims[i], inner_dim=inner_dims[i],
outer_head=outer_heads[i], inner_head=inner_heads[i],
num_patches=num_patches // (2 ** i) // (2 ** i), num_words=num_words, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[depth:depth+depths[i]], norm_layer=norm_layer, se=se, sr_ratio=sr_ratios[i])
)
depth += depths[i]
self.norm = norm_layer(outer_dims[-1])
# Classifier head
self.head = nn.Linear(outer_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
inner_tokens, outer_tokens, (H_out, W_out), (H_in, W_in) = self.patch_embed(x)
inner_tokens = inner_tokens + self.inner_pos # B*N, 8*8, C
outer_tokens = outer_tokens + self.pos_drop(self.outer_pos) # B, N, D
for i in range(4):
if i > 0:
inner_tokens = self.word_merges[i-1](inner_tokens, H_out, W_out, H_in, W_in)
outer_tokens, H_out, W_out = self.sentence_merges[i-1](outer_tokens, H_out, W_out)
inner_tokens, outer_tokens = self.stages[i](inner_tokens, outer_tokens, H_out, W_out, H_in, W_in)
outer_tokens = self.norm(outer_tokens)
return outer_tokens.mean(dim=1)
def forward(self, x):
# 特征提取层,可以作为Backbone用到下游任务
x = self.forward_features(x)
# 分类层
x = self.head(x)
return x
2.3 其他的Tricks
除了修改网络体系结构外,还采用了几种Vision Transformer的高级技巧。
-
在自注意力模块上添加相对位置编码,以更好地表示Token之间的相对位置。
-
前两个阶段利用Linear spatial reduction attention(LSRA)来降低长序列自注意力的计算复杂度。
3实验
3.1 分类
表3显示了ImageNet-1K分类结果。与原来的TNT相比,PyramidTNT实现了更好的图像分类精度。例如,与TNT-S相比,使用少1.9B的TNT-S的Top-1精度高0.5%。这里还将PyramidTNT与其他具有代表性的CNN、MLP和基于Transformer的模型进行了比较。从结果中可以看到PyramidTNT是最先进的Vision Transformer。

3.2 目标检测
表4报告了“1x”训练计划下的目标检测和实例分割的结果。PyramidTNT-S在One-Stage和Two-Stage检测器上都显著优于其他Backbone,且计算成本相似。例如,基于PyramidTNT-S的RetinaNet达到了42.0 AP和57.7AP-L,分别高出使用Swin-Transformer的模型0.5AP和2.2APL。
这些结果表明,PyramidTNT体系结构可以更好地捕获大型物体的全局信息。金字塔的简单的上采样策略和较小的空间形状使AP-S从一个大规模的推广。
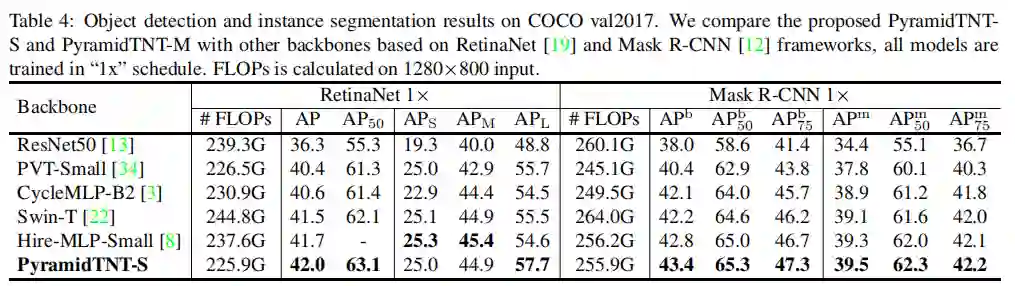
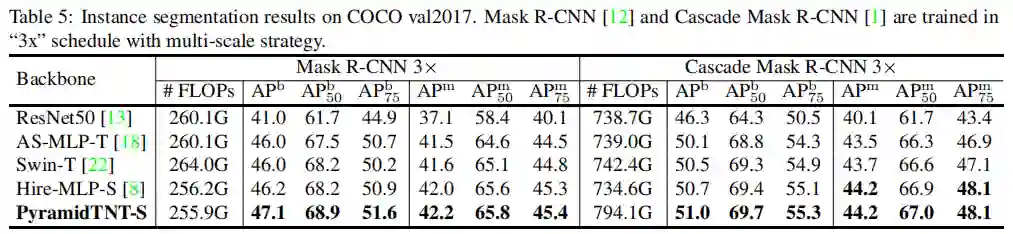
3.3 实例分割
PyramidTNT-S在Mask R-CNN和Cascade Mask R-CNN上的AP-m可以获得更好的AP-b和AP-m,显示出更好的特征表示能力。例如,在ParamidTNN约束上,MaskR-CNN-S超过Hire-MLPS 的0.9AP-b。
上面论文和代码下载
后台回复:PTNT,即可下载上述论文和代码
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看


