强化学习中的调参经验与编程技巧(on policy篇)

©PaperWeekly 原创 · 作者|张恒瑞
单位|北京交通大学
研究方向|强化学习
在强化学习的训练过程中,常常会遇见以下问题:
在某一环境中可以 work 的超参数拿去训练别的环境却训练不出来
训练时熵在增大
训练动作达到边界
本文通过调试几个环境的案例来探究强化学习的调参方法。

pendulum
使用 Actor 网络与环境交互一定步数,记录下(state, action, reward, v, done)
根据记录下来的值计算优势值 adv(更新 actor 网络使用)和 v_target(更新 critic 网络使用)
计算 loss 更新 actor 网络和 critic 网络
在 John Schulman's 程序中,对 V 估值采用这种方式:
V(s_t+1) = {0 if s_t is terminal
{v_s_{t+1} if s_t not terminal and t != T (last step)
{v_s if s_t not terminal and t == T
根据每一 step 的 reward 按照 gamma return 的方式计算 v_target
根据每一 step 的 adv 和 v 估值累加作为 v_target
1.1 初始
我们先使用简单的 PPO 来训练一下环境,参数选择如下:
-
actor,critic 网络初始化为正交初始化 -
steps=2048; -
batch=64; -
lr=3e-4 且经过训练迭代数逐渐减小;
lam = lambda f: 1 - f / train_steps
self.opti_scheduler = torch.optim.lr_scheduler.LambdaLR(self.opti, lr_lambda=lam)
-
采用 return 方式计算v_target; -
adv 计算采用 gae -
loss 计算添加熵,系数(self.c_en)为 0.01
loss = aloss - loss_entropy*self.c_en + v_loss*self.c_vf
-
max_grad_norm=0.5 -
torch.nn.utils.clip_grad_norm_(self.critic.parameters(), self.max_grad_norm)
torch.nn.utils.clip_grad_norm_(self.actor.parameters(), self.max_grad_norm)
这些都是比较常规的 PPO 参数设置,进行 1000 迭代后(2048*1000 step)reward 变化如下:
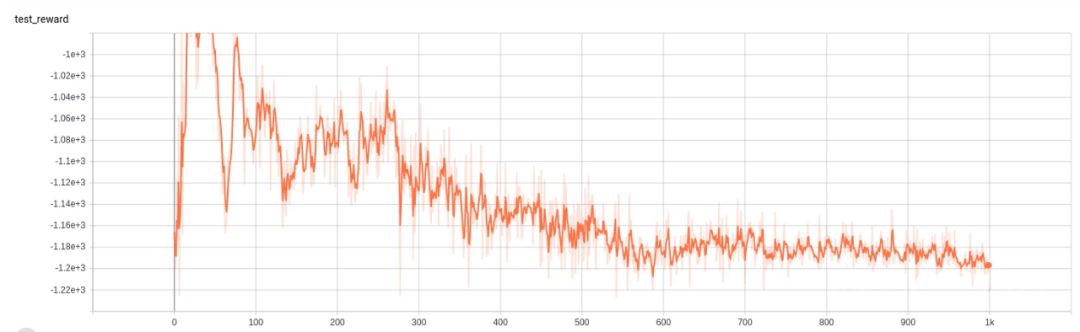
算法并没有很好的学习,reward 在 100 iter 以内还有上升趋势,100iter 时突然下降,之后就再也起不来。
我们来看一下学习过程中各个诊断量变化情况。

vloss 一开始值很大,接着骤降,之后一直处于比较高的水平。
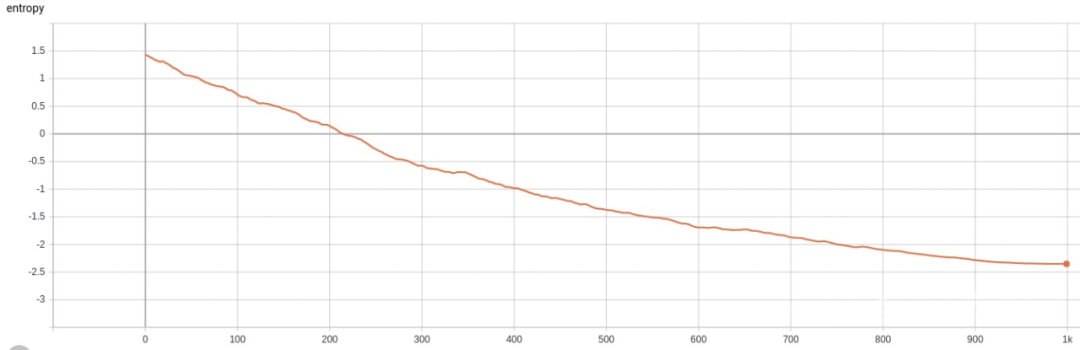
entropy 的变化幅度过快,最终值小于 0。这里简单提一下在连续密度分布中,熵值可能小于 0,拿高斯分布举例,如果其 sigma 过小,均值点处的密度概率可以远大于 1,熵值也为负数。综合来看,熵值出现小于 0 一般为 Actor 网络更新时sigma参数过小,可能是 actor 更新过快的原因。
1.2 clip V
为了让 critic 更新更合适,一般程序中采用 clipv 的技巧,防止更新前后 V 差距过大,对其进行惩罚,程序代码如下:
clip_v = oldv + torch.clamp(v - oldv, -self.epsilon, self.epsilon)
v_max = torch.max(((v - v_target) ** 2), ((clip_v - v_target) ** 2))
v_loss = v_max.mean()
同时程序中采用 gae 方式计算 v_target。
self.v_target = self.adv + self.v
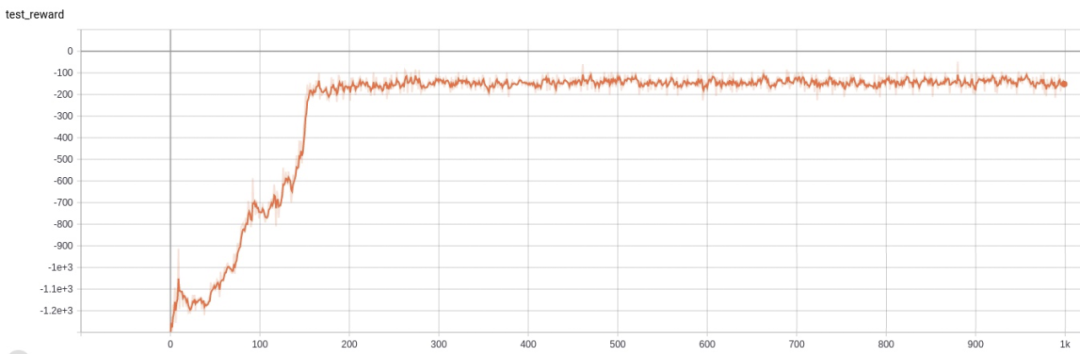
进行 1000 迭代后(2048*1000 step)reward 变化如下:

reward 最终能呈上升趋势最终达到一个不错的值,但美中不足在于中间出现两次波折。
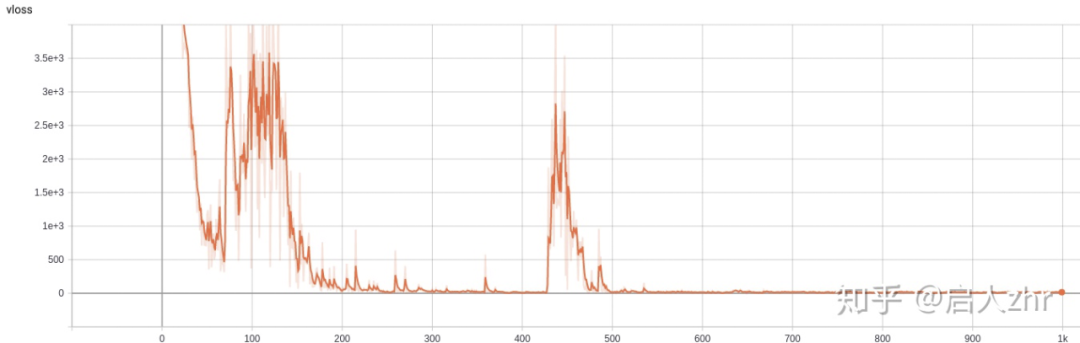
vloss 最终也能收敛到较小的值,但和 reward 类似在相同的地方出现了波折。

熵值的下降显得平稳多了。
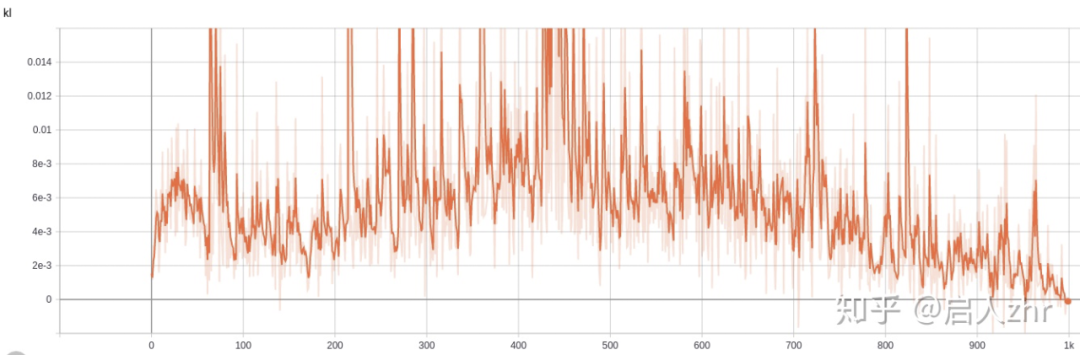
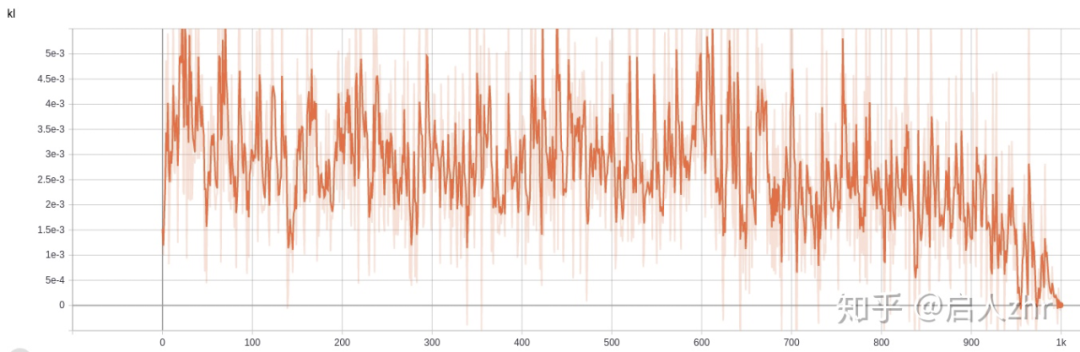
观察 kl 散度变化,发现类似的地方出现 kl 散度过大的现象。
ppo 在一次迭代中使用同一批数据进行策略更新,要求策略变化不能过大,不然重要性采样就不再适用,所以在 ppo 的策略更新中采用了裁剪的技巧,但事实上即使这个技巧也不能保证限制 kl 散度大小,论文 IMPLEMENTATION MATTERS IN DEEP POLICY GRADIENTS: A CASE STUDY ON PPO AND TRPO 也指出裁剪没有起到真正作用。
1.3 kl early stop

1.4 normalization
x = self.pre_filter(x)
if update:
self.rs.push(x)
if self.demean:
x = x - self.rs.mean
if self.destd:
x = x / (self.rs.std + 1e-8)
if self.clip:
x = np.clip(x, -self.clip, self.clip)
x = self.pre_filter(x)
self.ret = self.ret*self.gamma + x
if update:
self.rs.push(self.ret)
x = x/(self.rs.std + 1e-8)
if self.clip:
x = np.clip(x, -self.clip, self.clip)
return x

mujoco
用我们以上学到的经验去调试 mujoco 中的 halfcheetah,hopper 和 walker2d。
这里主要调节每次 early_stop 的 max_kl,采样 3 个随机种子完成实验。
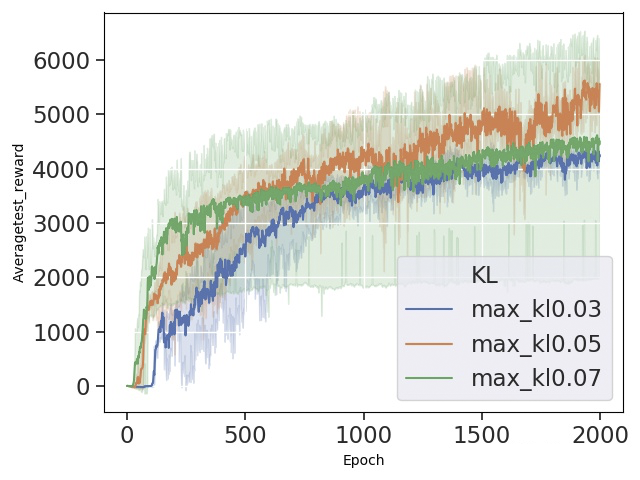
在 halfcheetah 环境中,目标 kl0.07 稳定性最差,可以看出在其他参数保持不变时,0.07 的限制依然导致每次策略更新时幅度过大,整体效果不够稳定。

在 hopper 环境中,依然是 kl0.07 的限制最不稳定。
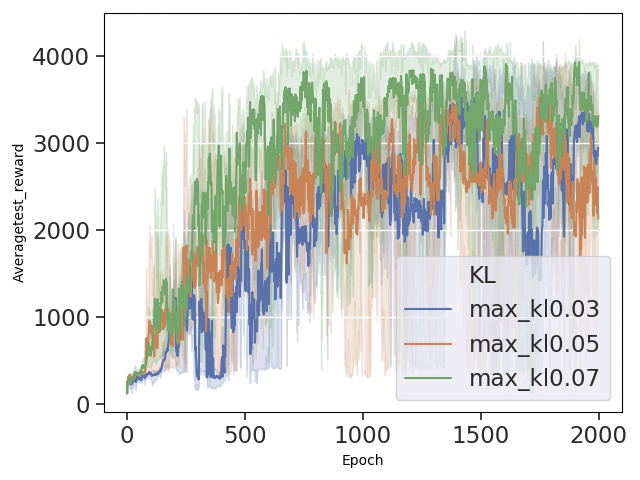
在 walker2d 环境中,kl0.07 的效果却是最好的,这也说明在不同的任务环境中,超参数的选择也是不同的。
这些结果的表现来看也都达到或超过部分论文上 ppo 的效果了,如果想试试调节超参数的可以看看:
如果你还不太清楚如何用 seaborn 绘制强化学习训练图,可以参考这篇:
https://zhuanlan.zhihu.com/p/75477750

deepmind control suite
env = dmc2gym.make(
domain_name=args.domain_name,
task_name=args.task_name,
seed=args.seed,
visualize_reward=False,
from_pixels=(args.encoder_type == 'pixel'),
height=args.image_size,
width=args.image_size,
frame_skip=args.action_repeat
)
先使用 mujoco 训练时使用的超参数,reward 如下:
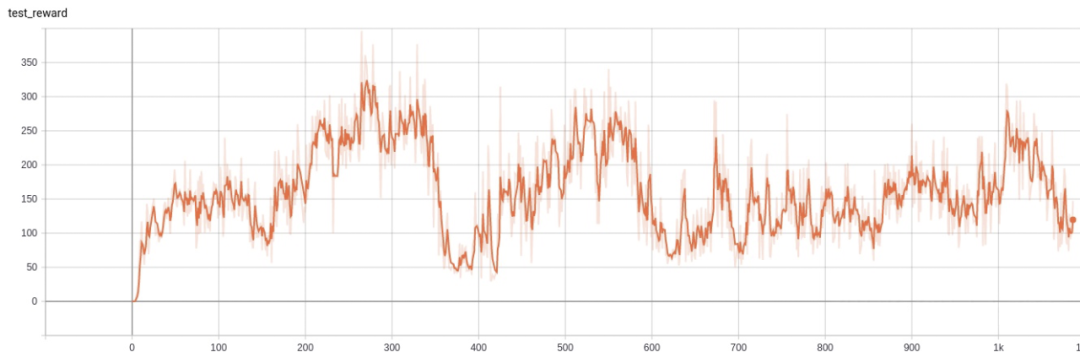
reward 结果极其不稳定,最终也没有达到比较好的结果。
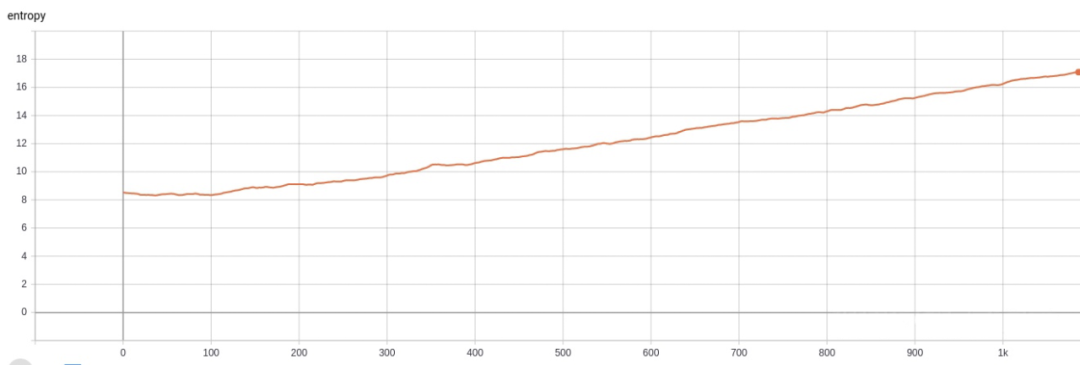
entropy在训练过程中由原来的8左右逐渐增大,这在以前的实验中都没有遇见。
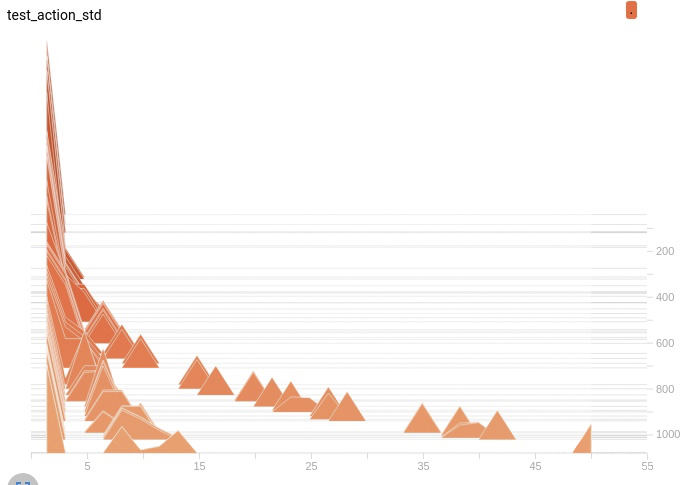
查看 Actor 网络动作 std 的变化情况,由一开始设置的 1 越变越大,也正是如此导致了 entropy 的不降反升。
在 ppo 的 loss 中熵项的存在确实是希望动作随机保持探索,但最终 entropy 越来越大,也体现出 ppo 策略网络的不自信,我们考虑将 entropy 的系数变小。
试试系数为 0 的效果。
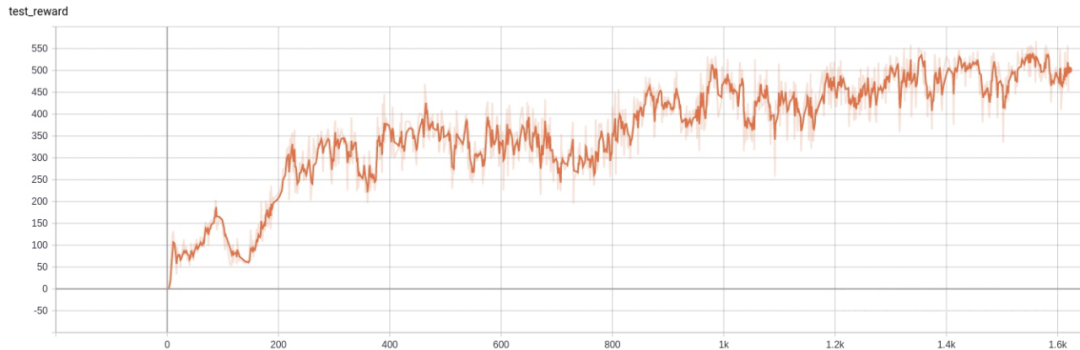
reward 有比较好的上升效果了。
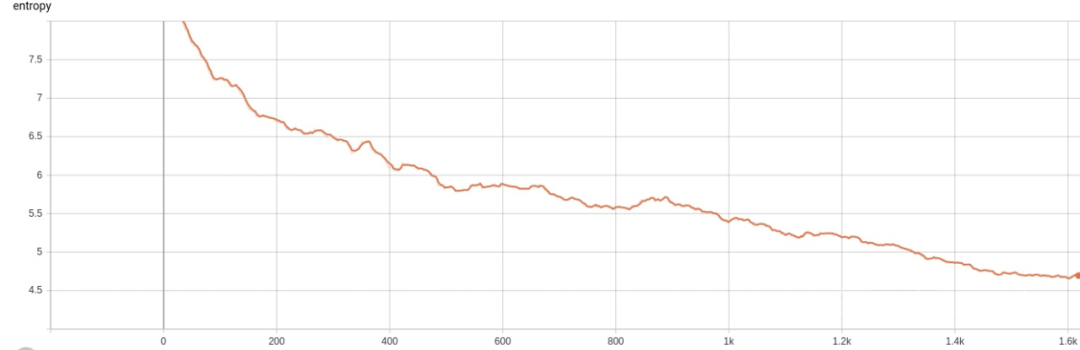
熵也能正常的下降了。
比较这两次的实际运行情况:
可以看出第一次后期翻车了,第二次还是能比较不错的跑下去。
大家也可以试试熵前面系数 0~0.01 之间其他值:
尝试总结一下,虽然 dmc 中的 cheetah-run 和 mujoco 的 halfcheetah 有类似的模型和动态转移,一开始的动作熵也在 8 左右,但 dmc 用同样的超参数熵就会上升,可能在于两者的 reward 不同,dmc 只有速度 reward,mujoco 还加上了控制 reward。
如果后面有时间的话还会补充上 dmc pixel 状态和 Atari 的调参过程,全部程序在:
欢迎点赞 star 和交流。

参考文献
[1] The 32 Implementation Details of Proximal Policy Optimization (PPO) Algorithm costa.sh/blog-the-32-im
[2] IMPLEMENTATION MATTERS IN DEEP POLICY GRADIENTS: A CASE STUDY ON PPO AND TRPO. ICLR2020
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





