step-by-step: 夕小瑶版神经网络调参指南(上)

虽然现在仅仅靠调参已经在深度学习领域不是香饽饽了,但是如果连参数都不会调,那可能连肉汤都喝不到的。毕竟你有再好的idea,也需要有一个漂亮的实验结果去支撑的对不对,参数调不好,千里马也容易被当成骡子。
说到调参,也不得不吐槽现在行业里论文复现难的问题。小夕曾经非常好奇AAAI2018某送审文章的性能,于是完全按照论文里的设定去做了复现,发现跟与论文中的结果足足差了4个百分点!更神奇的是我发现按照该论文的设定,模型远不足以拟合数据集 ╮( ̄▽ ̄"")╭ 最后实在get不到论文里的trick了,小夕就放开了自己调!结果最后调的比该论文里的结果还高了0.5个点,着实比较尴尬。
我们不能说某些顶会论文数据有问题,但是可以确信的是显式或隐式的超参数很可能大大的影响实验结果,这个超参数或许来自数据预处理,或许来自优化算法,或许来自模型本身,甚至有时候是来自输出层的推理阶段。
调参前的准备
好啦,回到正题上。在调参之前,小夕强烈建议在代码里完成下面几件事:
可视化训练过程中每个step(batch)的loss。如果是分类任务,可以顺便可视化出每个batch的准确率(不均衡数据可视化F1-score)。
将训练日志在打印到屏幕上的同时也写入到本地磁盘。如果能实时同步写入那更好了(在python中可以用logging模块可以轻松实现。一个handler输出到屏幕,再设置一个handler输出到磁盘即可)。
借助tensorflow里的FLAGS模块或者python-fire工具将你的训练脚本封装成命令行工具。
代码中完成tensorboard等训练过程可视化环境的配置,最少要可视化出训练loss曲线。
如果使用tensorflow,记得设置GPU内存动态增长(除非你只有一个GPU并且你确信一个训练任务会消耗GPU的一大半显存)
另外,初始调参阶段记得关闭L2、Dropout等用来调高模型泛化能力的超参数呐,它们很可能极大的影响loss曲线,干扰你的重要超参数的选取。然后根据自己的任务的量级,预估一个合理的batch size(一般来说64是个不错的初始点。数据集不均衡的话建议使用更大一点的值,数据集不大模型又不是太小的情况下建议使用更小一些的值)。如果对网络参数的随机初始化策略缺乏经验知识(知识来源于相关任务的论文实验细节或开源项目等),可以使用He方法[1](使用ReLU激活时)或Xavier方法[2]来进行网络参数初始化。
阶段1:learning rate和num steps
这个阶段是最容易的,打开tensorboard,按照指数规律设置几组可能的学习率,小夕一般设置如下六组[1, 0.1, 0.01, 0.001, 0.0001, 0.00001]。
如果你的GPU比较多,你还可以在几个大概率学习率附近多插几个值,比如小夕一般喜欢再插上[0.03, 0.05, 0.003, 0.005, 0.007, 0.0005]这几个值(最起码在做文本分类任务时经常撞到不错的结果哦)。
当这些任务跑完时,就可以去tensorboard里挑选最优学习率啦。选择原则也很简单,选择那条下降的又快又深的曲线所对应的学习率即可,如下图,选择粉色那条曲线:
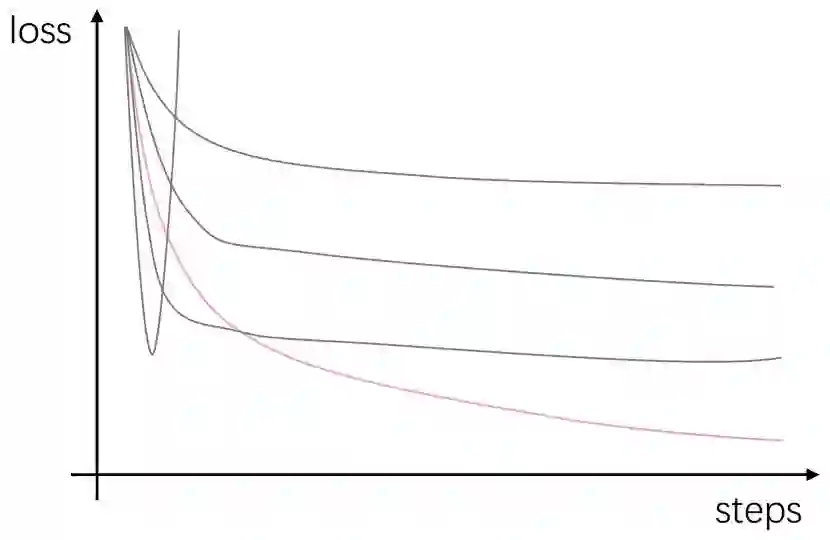
选择好学习率后,顺便再观察一下这条曲线,选择一个差不多已经收敛的step作为我们的训练总steps(如果数据集规模小的话也可以换算成epoch次数)。如图
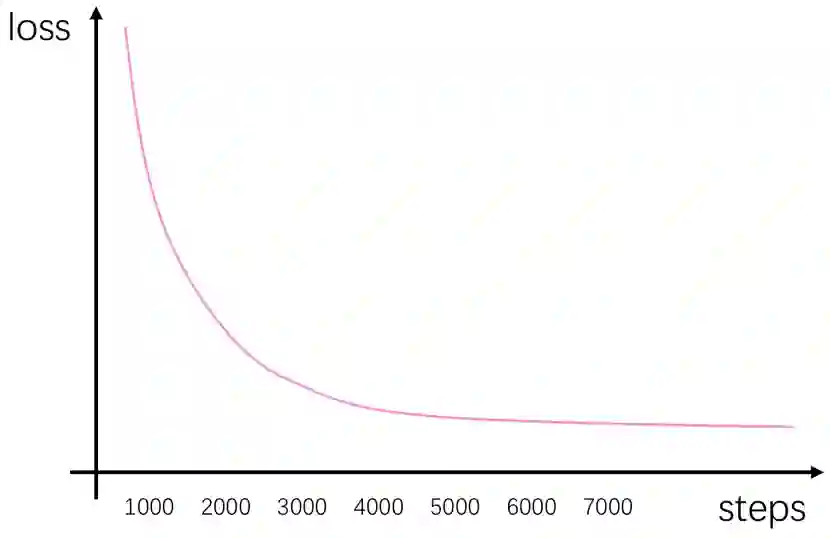
可以看到,我们的模型在迭代到4K步的时候就基本收敛了,保险起见我们可以选择6K来作为我们训练的总num_steps(毕竟后面改动的超参数可能使收敛延后嘛)。
细节:
如果GPU有限并且任务对显存的消耗没有太大,那么可以同时在一个GPU里挂上多组训练任务(这时每组任务的计算速度会有损耗,但是完成全部任务所消耗的总时间大大减少了)。小夕一般先随便设个学习率跑一下,确定一下每个任务大体消耗的显存,然后在shell脚本里将这若干个任务塞进GPU里并行跑(shell脚本里直接用&扔进后台即可)。当然,如果代码里用到了时间戳,可以给时间戳加个随机噪声或者在shell脚本里为任务之间加上一定的时间间隔,免得训练任务的时间戳发生碰撞。
买不起GPU版:
曾经有一段时间小夕只有一个可以用的GPU,然而任务规模又大到每次实验要占用一大半的GPU显存且要跑一天半,然而时间又特别紧,来不及像上面一样跑十几次实验去选个学习率。那怎么办呢?
小夕get到一个trick,就是在代码里计算出来每次更新时的梯度更新向量的模与当前参数向量的模的比值。如果这个比值在
阶段2:batch size和momentum
带着第一阶段得到的超参数,我们来到了第二阶段。
如果我们使用的是Adam这种“考虑周全”的优化器的话,动量项momentum这类优化器的超参数就基本省了。然而,不仅是小夕的经验,业界广泛的经验就是Adam找到的最优点往往不如精调超参的SGD找到的超参数质量高。因此如果你想要追求更加极限的性能的话,momentum还是要会调的哦。
momentum一方面可以加速模型的收敛(减少迭代步数),另一方面还可以带领模型逃离差劲的局部最优点(没理解的快回去看看momentum SGD的公式)。而batch size参数似乎也能带来类似的作用——batch size越小,噪声越大,越容易逃离局部最优点,同时这时对梯度的估计不准确,导致需要更多的迭代步数。因此小夕一般将这两个参数一起调。
两个参数同时调的时候可以使用传统的网格搜索,也可以使用大牛们提倡的随机搜索[3]。小夕觉得嘛,GPU多又时间充裕的话就网格搜索,否则就随机搜索啦。反正两个超参数时使用网格搜索也不是让人那么无法接受。还不熟悉这两种策略的同学可以去Ng在coursera开的深度学习课上补补哦,“超参数调节”这几节课讲的很清晰而且貌似是公开的。
另外,如果使用网格搜索并且搜索范围小的话小夕一般直接在shell脚本里偷懒解决:
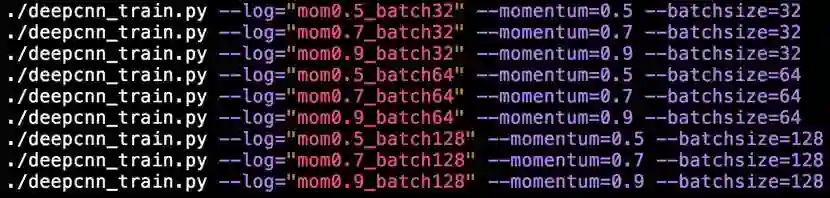
另外,由于这两个超参数可能涉及到模型的泛化能力,因此记得在监控loss曲线的同时也要监控开发集准确率哦。如果两组实验的loss曲线的形状都很好,这时就可以根据开发集准确率来做取舍了(一般不会出现loss曲线形状很差但是开发集准确率超好的情况)。
另外,还要记得!这一阶段结束后,可能最优的loss曲线会发生很大的变化,可能第一阶段我们确定的num_steps在这一阶段已经变得过分冗余了,那么我们在这一阶段结束后要记得把尾巴剪短一些哦(即减少num_steps,减少的依据跟以前一样)。当然如果batch size低了很多,有可能之前的num_steps不足以充分训练了,那么要记得增加步数啦。
阶段3:学习率衰减策略
相比较前面几个超参数,学习率衰减策略就比较神奇了。有时你会发现这个超参数好像没有什么用,有时却会发现它像开了挂一样让你看似已经收敛的网络更进一层,带来更低的训练loss和更高的开发集准确率。
这个其实也很容易理解啦,如果你的模型在收敛时走到了“高原地带”,这时其实你衰减学习率不会带来太大改观。而如果收敛时在“峡谷边缘”来回跳跃,这时你衰减学习率就可能一步跨下峡谷,发现新大陆!当然啦,这也只能是我们的YY,在手头任务中谁也不清楚这几百万几千万维度的空间里的地形。所以不妨使用一个简单有效的学习率衰减策略简单一调,有用就继续精调,没用就算啦。
经典的学习率衰减策略要同时考虑4个东西:衰减开始的时机、衰减量级(线性衰减or指数衰减)、衰减速率以及衰减的周期。
还记得我们上个阶段得到的开发集准确率曲线吗?没错!这条曲线的低谷附近就是开始衰减的好时机!
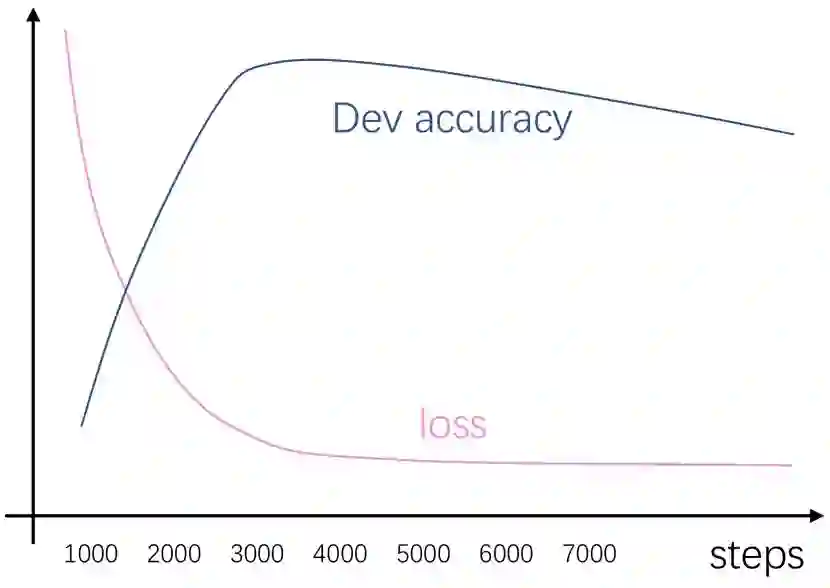
衰减时机很好确定,例如上面这种状态,最高开发集准确率在3000左右,那么我们不妨从2700左右开始衰减学习率。
衰减量级来说,貌似大家用指数衰减更多一点。不过呢,对于指数衰减来说,衰减因子调节起来较为敏感,一旦衰减因子太小,则model往往还没有训练够呢就衰减没了。因子设置太大的话迭代好久学习率还是下不去,导致开发集的性能提升不大。考虑这些的同时还要把握好衰减的间隔(也就是每多少个steps衰减一次),如果间隔过小,则开发集准确率的波峰附近相比无衰减时更平缓,如果间隔过大,容易发现除了第一次衰减,后面的衰减都不会带来什么收益。不过,最最起码的一个设计原则是,在到达原先的最高开发集准确率点的那个step时,最少衰减为初始学习率的一半才行(除非你的衰减间隔真的很短)。
是不是感觉超级麻烦哇,为了一个学习率衰减要去考虑和计算这么多东西,感觉好麻烦哦,所以小夕个人更喜欢用下面这种懒办法。
这种方法是从fasttext源码里学到的,实验了一下发现还蛮好用的就一直用了下来。首先,开始衰减的点不用算,直接从第一步起就开始线性衰减。然后假如总迭代步数为5K,学习率为0.01,那么我们就可以算一下每一步学习率的衰减量为

粗略算一下发现这时到达第3000步时的学习率为0.006,好像还蛮合理的诶。这样在最后一步时,学习率也恰好衰减到0。
在这个方案里,我们可以每个step都重新计算学习率,但是为了防止某些情况浮点下溢以及额外的计算开销(虽然可以忽略),往往还是设置一个衰减间隔,比如每100steps衰减一次。相比经典策略,这时的衰减间隔就不那么敏感啦,放心大胆的去设置。
使用这种懒办法基本没有引入任何难调的超参数,只要你在第二阶段的num_steps设置的合理,这一阶段的懒版学习率衰减就能往往取得不错的效果。
当然,如果在当前任务中发现这个懒办法也没带来多少收益,那这个任务可能真是地形相对平坦,对学习率衰减不太敏感,这时小夕一般不会考虑精调衰减策略。反之,如果发现这种懒办法都带来了明显的收益,那么仔细对比一下衰减策略下的开发集曲线和无衰减策略的开发集曲线,如果发现波峰后移的厉害,那可能衰减的太快了,尝试推后衰减时机。不过,既然有明显收益,那这时按照经典衰减策略再精调往往也不亏啦。
剩下的超参数要怎么调呢?坐等小夕的下一篇文章咯( ̄∇ ̄)

[1] Xavier Glorot and Yoshua Bengio. 2010. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, volume 9 of Proceedings of Machine Learning Research, pages 249–256, Chia Laguna Resort, Sardinia, Italy. PMLR.
[2] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. CoRR, abs/1502.01852.
[3] Bergstra J, Bengio Y. Random search for hyper-parameter optimization[J]. Journal of Machine Learning Research, 2012, 13(Feb): 281-305.


