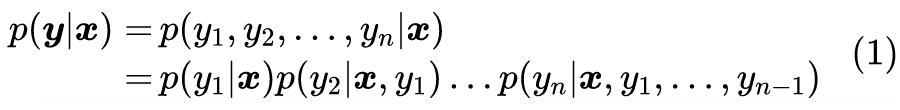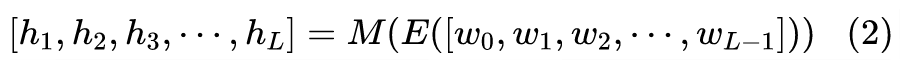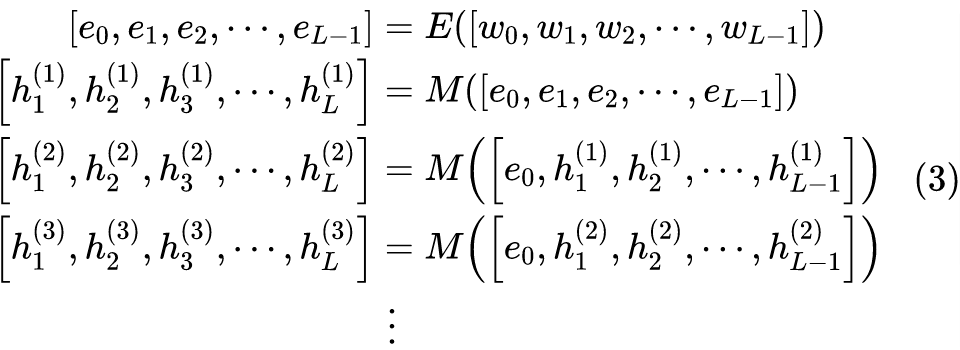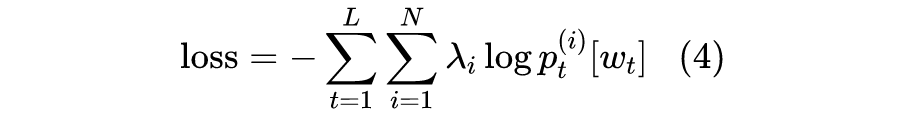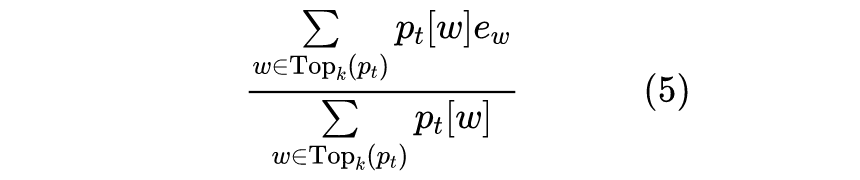©PaperWeekly 原创 · 作者|苏剑林
单位|追一科技
研究方向|NLP、神经网络
Teacher Forcing 是 Seq2Seq 模型的经典训练方式,而 Exposure Bias则是 Teacher Forcing 的经典缺陷,这对于搞文本生成的同学来说应该是耳熟能详的事实了。笔者之前也曾写过文章 Seq2Seq中Exposure Bias现象的浅析与对策 ,初步地分析过 Exposure Bias 问题。
本文则介绍 Google 新提出的一种名为“TeaForN ”的缓解 Exposure Bias 现象的方案,来自论文 TeaForN: Teacher-Forcing with N-grams
论文标题:
TeaForN: Teacher-Forcing with N-grams
论文链接:
https://arxiv.org/abs/2010.03494
(注:为了尽量跟旧文章保持一致,本文的记号与原论文的记号有所不同,请大家以理解符号含义为主,不要强记符号形式。)
Teacher Forcing
然后,当我们训练第 t 步的模型
时,我们假设
都是已知的,然后让模型只预测
,这就是 Teacher Forcing。
但在预测阶段,真实的
都是未知的,此时它们是递归地预测出来的,可能会存在传递误差等情况。因此 Teacher Forcing 的问题就是训练和预测存在不一致性,这让我们很难从训练过程掌握预测的效果。
没什么远见
怎么更具体理解这个不一致性所带来的问题呢?我们可以将它理解“没什么远见”。在解码器中,输入
和前 t-1 个输出 token 共同编码得到向量
,在 Teacher Forcing 中,这个
只是用来预测
,跟
没有直接联系,换句话说,它的“见识”也就局限在 t 这一步了。
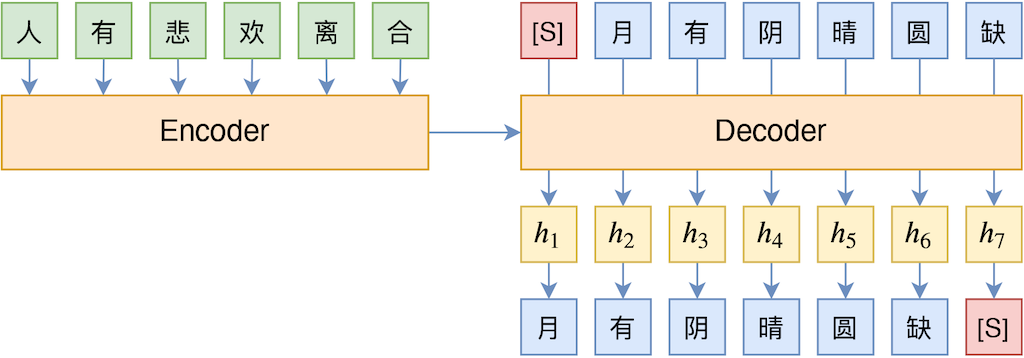
比如上图中的 h_3 向量,Teacher Forcing 只让它用来预测“阴 ”,事实上“阴 ”的预测结果也会影响“晴 ”、“圆 ”、“缺 ”的预测,也就是说
也应该与“晴 ”、“圆 ”、“缺 ”有所关联,而 Teacher Forcing 没有显式地建立这种关联。所以模型在解码的时候每一步很可能只输出局部最高概率的 token,这就容易出现高频安全回复或者重复解码现象。
Student Forcing
为了提高模型的“前瞻能力”,最彻底的方法当然是训练阶段也按照解码的方式来进行,即
也像解码阶段一样递归地预测出来,不依赖于真实标签,我们不妨称这种方式为 Student Forcing 。但是,Student Forcing 的训练方式来带来两个严重的问题:
第一,牺牲并行 。对于 Teacher Forcing 来说,如果 Decoder 使用的是 CNN 或 Transformer 这样的结构,那么训练阶段是所有 token 都可以并行训练的(预测阶段还是串行),但如果 Student Forcing 的话则一直都是串行。
第二,极难收敛 。Student Forcing 通常需要用 Gumbel Softmax 或强化学习来回传梯度,它们的训练都面临着严重的不稳定性,一般都要用 Teacher Forcing 预训练后才能用 Student Forcing,但即便如此也不算特别稳定。
形象地理解,Student Forcing 相当于老师完全让学生独立探究一个复杂的问题,不做手把手教学,只对学生的结果好坏做个最终评价。这样一旦学生能探索成功,那可能说明学生的能力很强了,但问题就是缺乏老师的“循循善诱”,学生“碰壁”的几率更加大。
往前多看几步
有没有介乎 Teacher Forcing 与 Student Forcing 之间的方法呢?有,本文所介绍的 TeaForN 就算是其中一种,它的思想是常规的 Teacher Forcing 相当于在训练的时候只往前看 1 步,而 Student Forcing 相当于在训练的时候往前看了 L 步(L 是目标句子长度)。
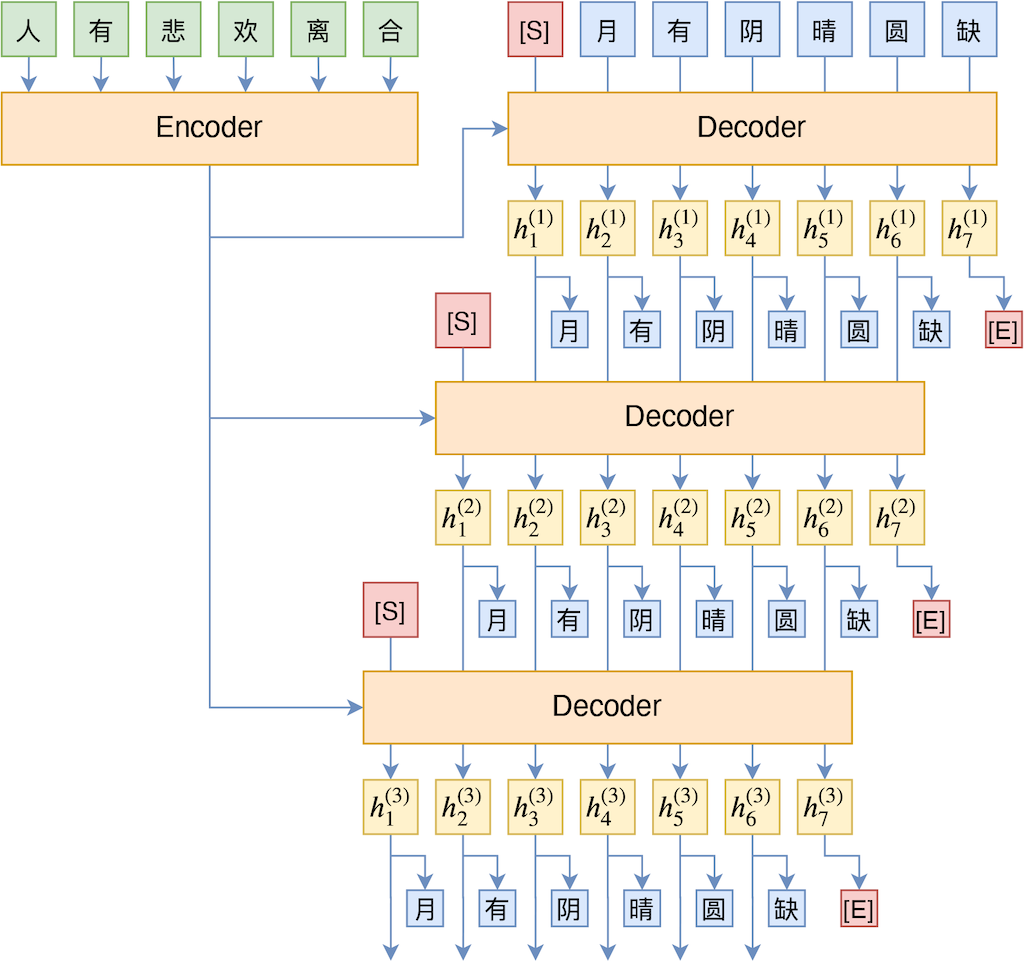
如果我们只是往前多看几步(相当于看到了 N-gram),那么理论上就能提高“远见”,并且不至于严重牺牲模型的并行性。其示意图如下:
直观来看,就是把输出结果再往前迭代多遍,这样一来前 t-1 个 token 要预测的就不仅仅是第 t 个 token 了,还有第
个。比如在上图中,最后我们用
来预测了“缺 ”字,而我们可以看到
只依赖于“月 ”、“有 ”、“阴 ”三个字,所以我们也可以理解为
这个向量同时要预测“晴 ”、“圆 ”、“缺 ”三个字,因此也就提高了“远见”。
用数学语言来描述,我们可以将 Decoder 分为 Embedding 层 E 和剩余部分 M 两个部分,Embedding 层负责将输入句子
映射为向量序列
(其中
是固定的解码起始标记,也就是上图的 [S],有些文章记为
),然后交给模型 M 处理,得到向量序列
,即:
接着通过
得到第 t 步的 token 概率分布,最后用
作为损失函数训练,这便是常规的 Teacher Forcing。
可以想象,负责映射到 token 分布的输出向量序列
某种程度上跟 Embedding 序列
是相似的,如果我们补充一个
进去,然后将
也送入到模型 M 中再处理一次,是否可以呢?也就是:
训练完成后,我们只用 E 和 M 做常规的解码操作(比如 Beam Search),也就是只用
而不需要
了。这个流程就是本文的主角 TeaForN 了。
效果、思考与讨论
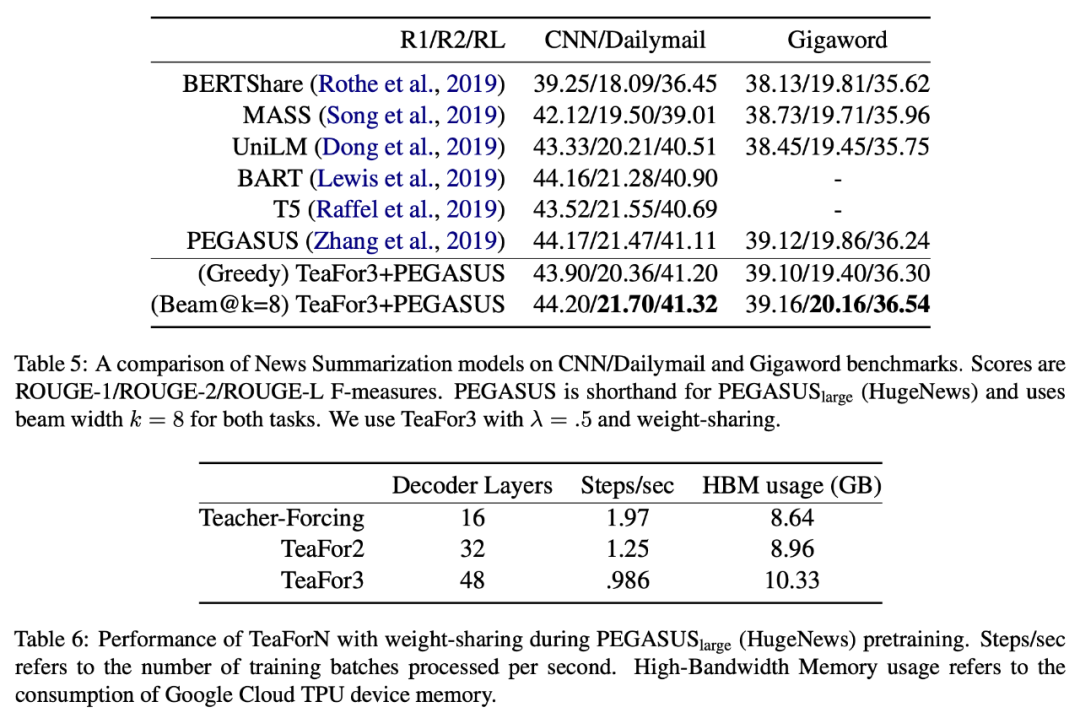
至于实验效果,自然是有提升的,从原论文的实验表格来看,在 beam_size 比较大时提升比较明显。其实也不难理解,按道理来说,这样处理后再不济应该也不会下降,因此算是一种“稳赚不赔”的策略了。
原论文讨论了几个值得商榷的点,我们这里也来看下。
首先,模型每一步迭代所用的 M 该不该共享权重?直觉来想共享是更好的,如果不共享权重,那么往前看 N 步,那么参数量就差不多是原来的 N 倍了,感觉是不大好。当然最好还是靠实验实验,原论文确实做了这个比较,证实了我们的直觉。
▲ TeaForN在机器翻译上的效果,其中包含了是否贡献权重的比较
其次,可能最主要的疑问是:在迭代过程中将
当作
用是否真的靠谱?当然,实验结果已经表明了是可行的,这就是最有说服力的论据了。但由于
到
是通过内积来构建的,所以
跟
未必相似,如果能让它们更接近些,效果会不会更好?原论文考虑了如下的方式:
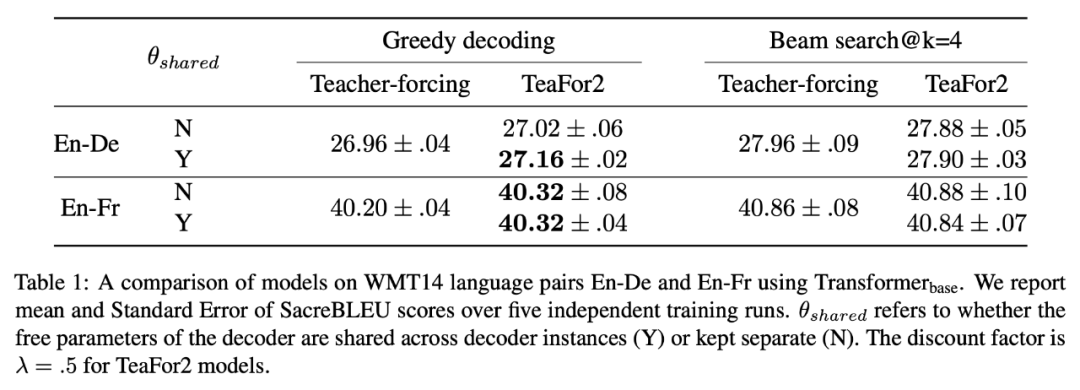
也就是说,每一步算出
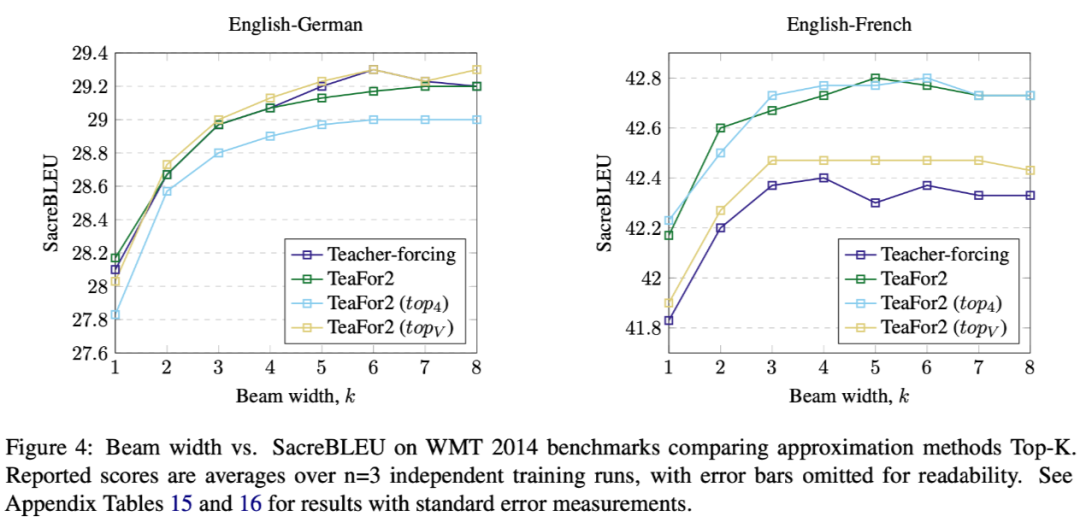
后,取概率最大的 k 个 token,将它们的 Embedding 向量加权平均来作为下一步迭代的输入。原论文实验了 k=4 和 k=|V|(词表大小),结果如下图。总的来说 Topk 的效果不大稳定,好的情况也跟直接用
差不多,因此就没必要尝试别的了。
▲ 用Topk对Embedding加权平均的方式代替h的效果
当然,我觉得要是论文再比较一下通过 Gumbel Softmax 来模拟采样效果就更加完美了。
来自文末的总结
本文分享了 Google 新提出来一种称为 TeaForN 的训练方式,它介乎 Teacher Forcing 和 Student Forcing 之间,能缓解模型的 Exposure Bias 问题,并且不用严重牺牲模型训练的并行性,是一种值得尝试的策略。
除此之外,它实际上还提供了一种解决此类问题的新思想(通过迭代保持并行和前瞻),其中颇有值得回味的地方。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学习心得 或技术干货 。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品 ,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱: hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」 ,小助手将把你带入 PaperWeekly 的交流群里。