梯度下降优化之旅:神经网络常用优化算法概览
编者按:DataScience+作者Anish Singh Walia概览了常用的神经网络优化算法。
你是否曾经思考过该为自己的神经网络模型使用什么样的优化算法?我们应该使用梯度下降还是随机梯度下降还是Adam?
什么是优化算法?
优化算法帮助我们最小化(或最大化)一个目标函数(误差函数的另一个名字)E(x),该函数不过是一个取决于模型的内部可学习参数的数学函数,内部可学习参数用来根据一组输入(X)计算预测目标值(Y)。例如,神经网络的权重(W)和偏置(b)被我们称为神经网络的内部可学习参数,这些参数用于计算输出值,并在优化方案的方向上学习和更新,即在网络训练过程中最小化损失。
模型的内部参数在训练网络产生精确结果的效果和效率方面起着极为重要的作用,它们影响我们模型的学习过程和模型的输出。这正是我们使用多种优化策略和算法来更新、计算这些模型参数的恰当的最优值的原因。
优化算法的类型
优化算法可分为两大类:
一阶优化算法(First Order Optimization Algorithms)
这些算法基于损失函数在参数上的梯度值,最小化或最大化损失函数E(x)。使用最广泛的一阶优化算法是梯度下降。一阶导数告诉我们在某一特定点上函数是下降还是上升。基本上,一阶导数提供正切于误差平面上一点的一条直线。
什么是函数的梯度?
梯度不过是一个向量,该向量是导数(dy/dx)的多元推广。导数(dy/dx)则是y相对于x的即时变化率。主要的区别在于,梯度用于计算多元函数的导数,通过偏导数计算。另一个主要的区别是,函数的梯度生成向量场。
梯度由雅可比矩阵表示——一个包含一阶偏导数(梯度)的矩阵。
简单来说,导数定义在单元函数上,而梯度定义在多元函数上。我们就不讨论更多关于微积分和物理的内容了。
二阶优化算法(Second Order Optimization Algorithms)
二阶方法使用二阶导数最小化或最大化损失函数。二阶方法使用海森矩阵——一个包含二阶偏导数的矩阵。由于计算二阶导数开销较大,二阶方法不如一阶方法常用。二阶导数告诉我们一阶导数是上升还是下降,这提示了函数的曲率。二阶导数提供了一个拟合误差平面曲率的二次平面。
尽管二阶导数计算起来开销较大,但二阶优化算法的优势在于它没有忽略误差平面的曲率。另外,就每一步的表现而言,二阶优化算法要比一阶优化算法更好。
了解更多关于二阶优化算法的内容:https://web.stanford.edu/class/msande311/lecture13.pdf
应该使用哪类优化算法?
目前而言,一阶优化技术更容易计算,花费时间更少,在大型数据集上收敛得相当快。
仅当二阶导数已知时,二阶技术更快,否则这类方法总是更慢,并且计算的开销更大(无论是时间还是内存)。
不过,有时牛顿二阶优化算法能超过一阶梯度下降,因为二阶技术不会陷入鞍点附近的缓慢收敛路径,而梯度下降有时会陷进去,无法收敛。
知道哪类算法收敛更快的最好办法是自己亲自尝试。
梯度下降
梯度下降是训练和优化智能系统的基础和最重要技术。
哦,梯度下降——找到最小值,控制方差,接着更新模型的参数,最终带领我们走向收敛
θ=θ−η⋅∇J(θ)是参数更新的公式,其中η为学习率,∇J(θ)为损失函数J(θ)在参数θ上的梯度。
梯度下降是优化神经网络的最流行算法,主要用于更新神经网络模型的权重,也就是以某个方向更新、调整模型参数,以便最小化损失函数。
我们都知道训练神经网络基于一种称为反向传播的著名技术。在神经网络的训练中,我们首先进行前向传播,计算输入信号和相应权重的点积,接着应用激活函数,激活函数在将输入信号转换为输出信号的过程中引入了非线性,这对模型而言非常重要,使得模型几乎能够学习任意函数映射。在此之后,我们反向传播网络的误差,基于梯度下降更新权重值,也就是说,我们计算误差函数(E)在权重(W)也就是参数上的梯度,然后以损失函数的梯度的相反方向更新参数(这里是权重)。
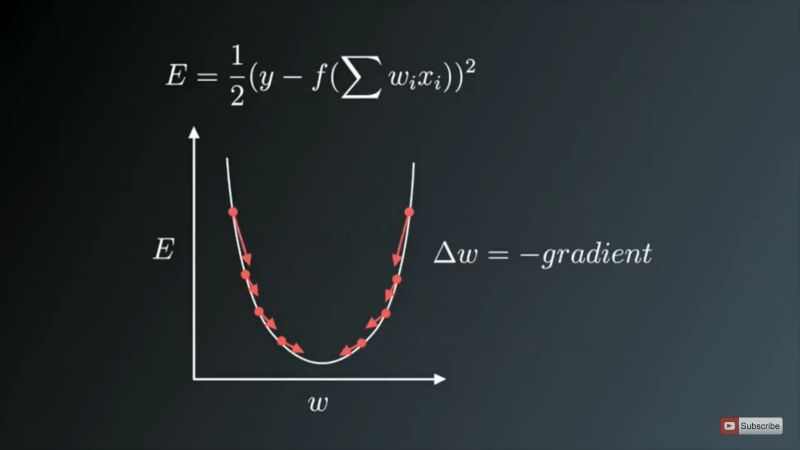
权重在梯度的反方向上更新
上图中,U型曲线是梯度(坡度)。如你所见,如果权重(W)值过小或过大,那么我们会有较大误差,所以我们想要更新和优化权重使其既不过小又不过大,所以我们沿着梯度的反方向下降,直到找到局部极小值。
梯度下降的变体
传统的梯度下降将为整个数据集计算梯度,但仅仅进行一次更新,因此它非常慢,而在大到内存放不下的数据集上更是困难重重。更新的大小由学习率η决定,同时保证能够在凸误差平面上收敛到全局最小值,在非凸误差平面上收敛到局部极小值。另外,标准的梯度下降在大型数据集上计算冗余的更新。
以上标准梯度下降的问题在随机梯度下降中得到了修正。
1. 随机梯度下降
随机梯度下降(SGD)则为每一个训练样本进行参数更新。通常它是一个快得多的技术。它每次进行一项更新。
θ=θ−η⋅∇J(θ;x(i);y(i))
由于这些频繁的更新,参数更新具有高方差,从而导致损失函数剧烈波动。这实际上是一件好事,因为它帮助我们发现新的可能更好的局部极小值,而标准随机梯度下降则如前所述,仅仅收敛至盆地(basin)的极小值。
然而,SGD的问题在于,由于频繁的更新和波动,它最终复杂化了收敛过程,因频繁的波动而会不断越过头。
不过,如果我们缓慢降低学习率η,SGD展现出和标准梯度下降一样的收敛模式。
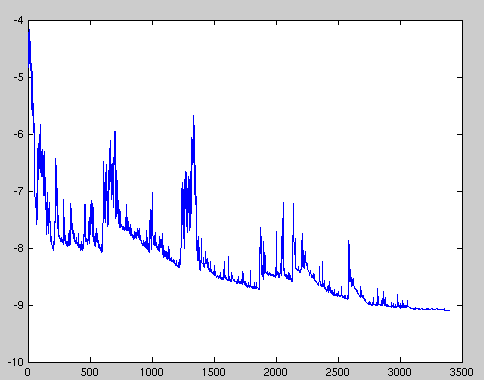
损失函数剧烈波动导致我们可能无法得到最小化损失值的参数
高方差参数更新和不稳定收敛在另一个称为小批量梯度下降(Mini-Batch Gradient Descent)的变体中得到了修正。
2. 小批量梯度下降
想要避免SGD和标准梯度下降的所有问题和短处,可以使用小批量梯度下降,它吸收了两种技术的长处,每次进行批量更新。
使用小批量梯度下降的优势在于:
降低了参数更新的方差,最终导向更好、更稳定的收敛。
可以利用当前最先进的深度学习库中常见的高度优化的矩阵操作,极为高效地计算小批量梯度。
常用的Mini-batch大小为50到256,不过可能因为应用和问题的不同而不同。
小批量梯度下降是今时今日训练神经网络的典型选择。
P.S. 实际上,很多时候SGD指的就是小批量梯度下降。
梯度下降及其变体面临的挑战
选择合适的学习率可能很难。过小的学习率导致慢到让人怀疑人生的收敛,在寻找最小化损失的最优参数值时迈着婴儿般的小步,直接影响总训练时长,使其过于漫长。而过大的学习率可能阻碍收敛,导致损失函数在极小值周围波动,甚至走上发散的不归路。
此外,同样的学习率应用于所有参数更新。如果我们的数据是稀疏的,我们的特征有非常不同的频率,我们可能不想以同等程度更新所有特征,而是想在很少出现的特征上进行较大的更新。
最小化神经网络中常见的高度非凸误差函数的另一项关键挑战是避免陷入众多的次优局部极小值。事实上,困难不仅在于局部极小值,更在于鞍点,即一个维度的坡度上升,另一个维度的坡度下降的点。这些鞍点通常被误差相等的高原环绕,众所周知,这让SGD难以逃离,因为在所有维度上,梯度都接近零。
优化梯度下降
现在我们将讨论进一步优化梯度下降的多种算法。
动量
SGD的高方差振荡使其难以收敛,所以人们发明了一项称为动量(Momentum)的技术,通过在相关方向上导航并减缓非相关方向上的振荡加速SGD。换句话说,它在当前更新向量中增加了上一步的更新向量,乘以一个系数γ。
V(t)=γV(t−1)+η∇J(θ)
最终我们通过θ=θ−V(t)更新参数。
动量项γ通常设为0.9,或与之相似的值。
这里的动量源自经典物理学中的动量概念,当我们沿着一座小山坡向下扔球时,球在沿着山坡向下滚动的过程中收集动量,速度不断增加。
我们的参数更新过程发生了同样的事情:
它导向更快、更稳定的收敛。
它减少了振荡。
动量项γ在梯度指向同一方向的维度上扩大更新,而在梯度方向改变的维度上缩小更新。这减少了不必要的参数更新,导向更快、更稳定的收敛,减少了振荡。
Nesterov加速梯度
Yurii Nesterov发现了动量的一个问题:
盲目地随着坡度滚下山坡的球是不令人满意的。我们希望能有一个智能一点的球,对所处位置有一定的概念,知道在坡度变得向上前减速。
也就是说,当我们到达极小值,也就是曲线的最低点时,动量相当高,因为高动量的作用,优化算法并不知道在那一点减速,这可能导致优化算法完全错过极小值然后接着向上移动。
Yurii Nesterov在1983年发表了一篇论文,解决了动量的这个问题。我们现在将其提出的策略称为Nesterov加速梯度(Nestrov Accelerated Gradient,NAG)。
Nesterov提议,我们首先基于先前的动量进行一次大跳跃,接着计算梯度,然后据此作出修正,并根据修正更新参数。预更新可以防止优化算法走得太快错过极小值,使其对变动的反应更灵敏。
NAG是为动量项提供预知能力的一种方法。我们知道,我们在更新参数θ的时候会用到动量项γV(t−1)。因此,计算θ−γV(t−1)能提供参数下一位置的近似值。这样我们就可以通过计算参数未来位置的近似值上的梯度“预见未来”:
V(t)=γV(t−1)+η∇J( θ−γV(t−1) )
接着我们同样通过θ=θ−V(t)更新参数。
关于NAG的更多细节,可以参考cs231n课程。
现在,我们已经能够根据误差函数的斜率调整更新的幅度,并加速SGD过程,我们同样希望能根据不同参数的重要性调整更新的幅度。
Adagrad
Adagrad让学习率η可以基于参数调整,为不频繁的参数进行较大的更新,为频繁的参数进行较小的更新。因此,它很适合处理稀疏数据。
Adagrad在每一时步为每个参数θ使用不同的学习率,学习率的大小基于该参数的过往梯度。
之前,我们为所有参数θ一下子进行更新,因为每个参数θ(i)使用相同的学习率η。由于Adagrad在每个时步t为每个参数θ(i)使用不同的学习率,我们首先计算Adagrad在每个参数上的更新,接着将其向量化。设gi,t为参数θ(i)在时步t的损失函数的梯度,则Adagrad的公式为:
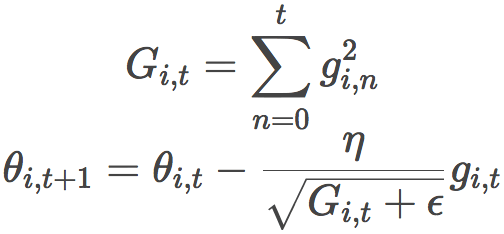
上式中,ϵ为平滑因子,避免除数为零。
从上式中,我们可以看到:
某方向上的Gi,t较小,则相应的学习率较大,也就是说,为不频繁出现的参数做较大的更新。
随着时间的推移,Gi,t越来越大,从而使学习率越来越小。因此,我们无需手动调整学习率。大多数Adagrad的实现中,η均使用默认值0.01. 这是Adagrad的一大优势。
由于Gi,t为平方和,每一项都是正值。因此,随着训练过程的进行,Gi,t会持续不断地增长。这意味着,学习率会持续不断地下降,模型收敛越来越慢,训练需要漫长的时间,甚至最终学习率小到模型完全停止学习。这是Adagrad的主要缺陷。
另一个算法AdaDelta修正了Adagrad的学习率衰减问题。
AdaDelta
AdaDelta试图解决Adagrad的学习率衰减问题。不像Adagrad累加所有过往平方梯度,Adadelta对累加的范围作了限制,只累计固定大小w的窗口内的过往梯度。 为了提升效率,Adadelta也没有存储w个平方梯度,而是过往平方梯度的均值。这样,时步t的动态均值就只取决于先前的均值和当前梯度。
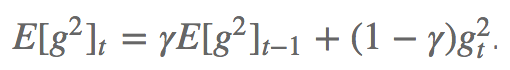
其中,γ的取值和动量方法类似,在0.9左右。
类似Adagrad,Adadelta的公式为:
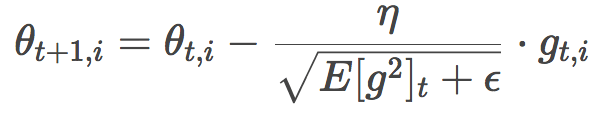
由于分母部分恰好符合梯度的均方误差的定义:
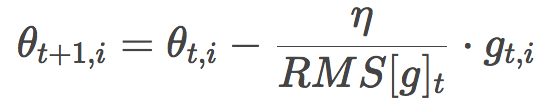
这其实也是RMSprop的公式。RMSprop是由Geoffrey Hinton提出的,未以论文形式发表,见其csc321课程。
Adadelta和RMSProp是在差不多同时相互独立地开发的,都是为了解决Adagrad的学习率衰减问题。
另外,标准的Adadelta算法中,和分母对称,分子的η也可以用RMS[Δθ]t-1替换:
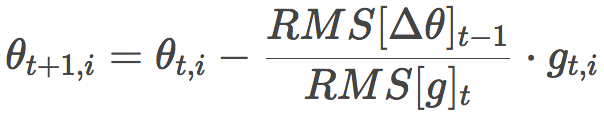
这就消去了η!也就是说,我们无需指定η的值了。
目前为止我们所做的改进
为每个参数计算不同的学习率。
同时计算动量。
防止学习率衰减。
还有什么可以改进的?
既然我们已经为每个参数分别计算学习率,为什么不为每个参数分别计算动量变动呢?基于这一想法,人们提出了Adam优化算法。
Adam
Adam表示自适应动量估计(Adaptive Moment Estimation)。
开门见山,让我们直接查看Adam的公式:
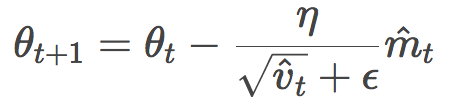
有没有一种似曾相识的感觉?你的感觉没错,这很像RMSProp或者Adadelta的公式:
所以,问题来了,这vt和mt到底是什么玩意?莫急,我们马上给出两者的定义。
先来瞧瞧vt:
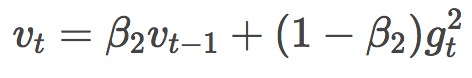
哟!这不就是Adadelta或者RMSProp里面的过往平方梯度均值嘛!只不过换了几个字母,把γ换成了β2,把E[g2]换成了v。
再来看看mt的定义:
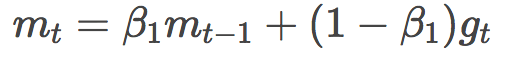
咦?这个好像和动量的定义有点像呀?
V(t)=γV(t−1)+η∇J(θ)
γ换成了β1,∇J(θ)和gt都是梯度。当然还有一个系数不一样,只是有点像,不是一回事。
从这个角度来说,Adam算法有点博采众家之长的意思。事实上,RMSProp或者Adadelta可以看成是Adam算法不带动量的特殊情形。
当然,其实我们上面有一个地方漏了没说。细心的读者可能已经发现,实际上Adam的公式里vt和mt是戴帽的,这顶帽子意义何在?
这是因为,作者发现,由于vt和mt刚开始初始化为全零向量,会导致这两个量的估计向零倾斜,特别是在刚开始的几个时步里,以及衰减率很小的情况下(即β取值接近1)。因此需要额外加上校正步骤:
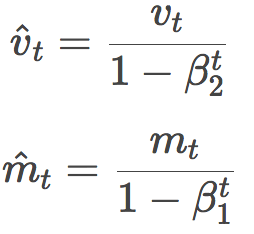
Adam作者建议,β1取0.9,β2取0.999,ϵ取10-8。
在实践中,Adam的表现非常出色,收敛迅速,也修正了之前一些优化算法的问题,比如学习率衰减、收敛缓慢、损失函数振荡。通常而言,Adam是自适应学习率算法的较优选择。
AMSGrad
在ICLR 2018上,Google的Reddi等提交了一篇关于Adam收敛性的论文,指出了Adam算法收敛性证明中的一个错误。并构造了一个简单的凸优化问题作为反例,证明Adam在其上无法收敛。另外,Reddi等提出了Adam算法的一个变体,AMSGRad,其主要改动为:
基于算法的简单性考量,去除了Adam的偏置纠正步骤。
仅当当前vt大于vt-1时,才应用vt。也就是说,应用两种中较大的那个。这有助于避免收敛至次优解时,某些提供较大、有用梯度的罕见mini-batch的作用可能被过往平方梯度均值大为削弱,导致难以收敛的问题。
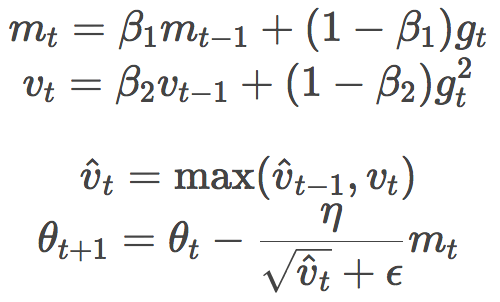
Reddi等在小型网络(MNIST上的单层MLP、CIFAR-10上的小型卷积网络)上展示了AMSGrad在训练损失和测试损失方面相对Adam的优势。然而,有人在较大模型上进行了试验,发现两者并无显著差异(顺便,Adam和AMSGrad的偏置纠正是否开启,影响也不大)。
可视化优化算法
下面让我们来看两张动图,希望它们有助于直观地理解网络的训练过程。
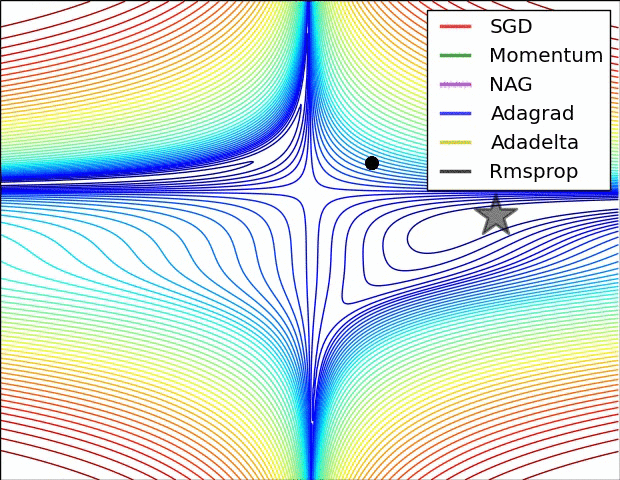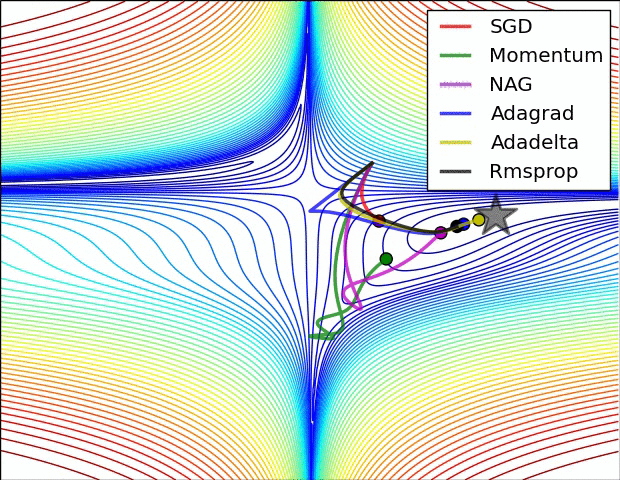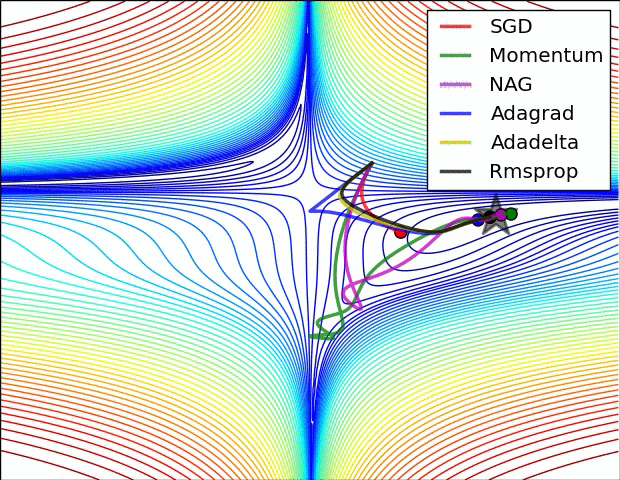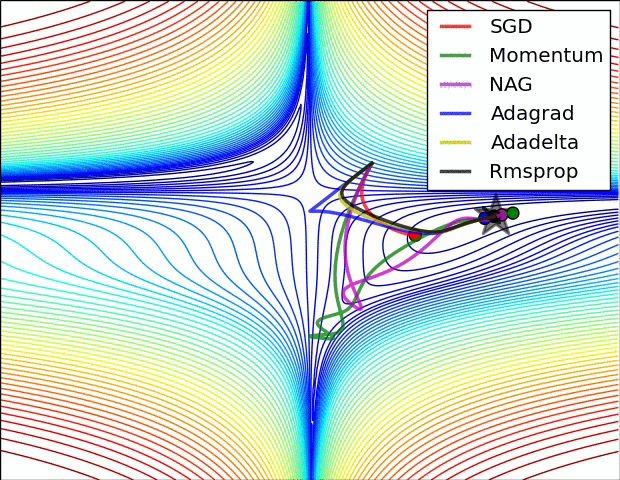
上图为误差平面的等值线图。从图中我们可以看到,自适应学习率方法干净利落地完成了收敛。而SGD、动量法、NAG收敛十分缓慢。其中,动量法和NAG在动量的作用下,欢快地朝着一个方向狂奔,相比之下,NAG更快反应过来。SGD倒是没有冲过头,可惜最后没能收敛到最优值。
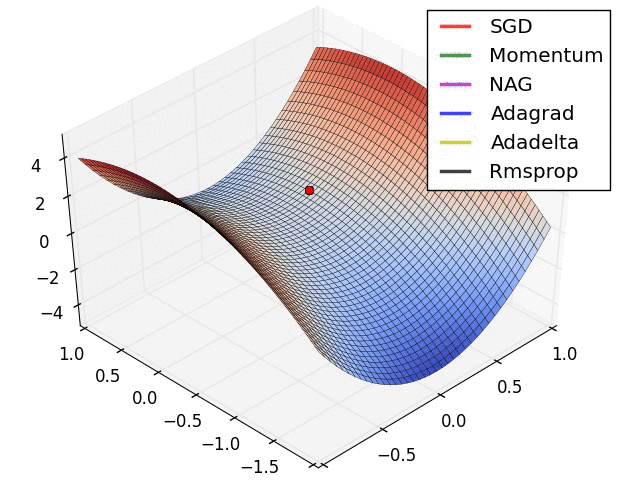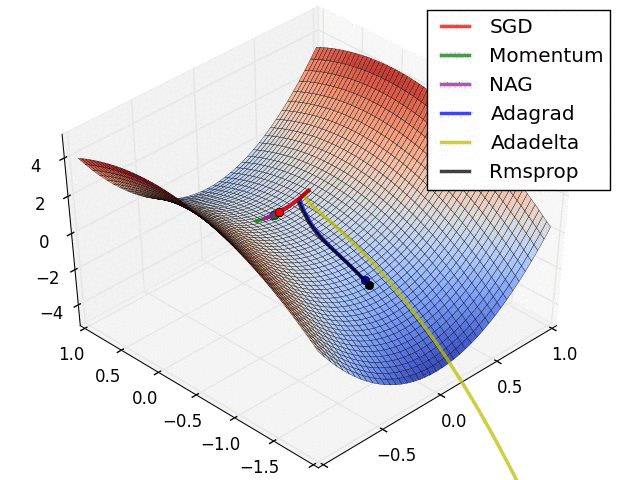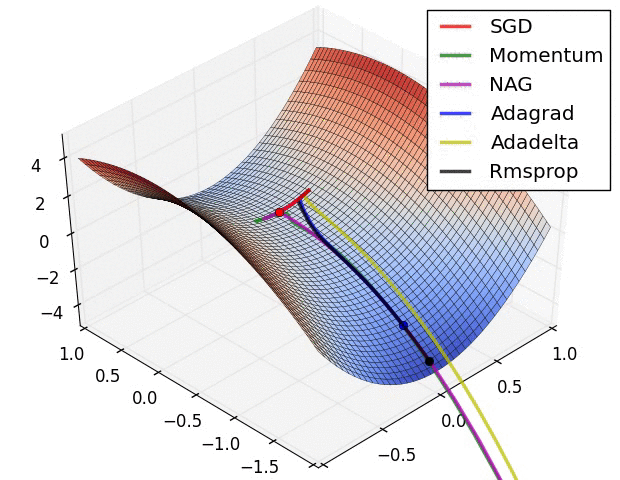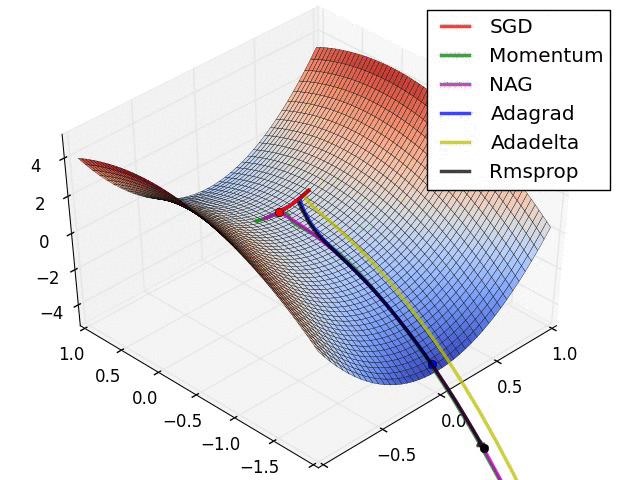
上图演示了不同优化算法在鞍点的表现。我们看到,自适应学习率方法毫不拖泥带水地摆脱了鞍点,动量法、NAG在鞍点徘徊良久后终于逃出生天,而SGD最终陷在鞍点无法自拔。
以上两幅动图均由Alec Radford制作。
应该使用哪种优化算法?
不幸的是,这一问题目前还没有明确的答案。这里仅能提供一些建议:
目前而言,用的比较多的优化算法是SGD、动量、RMSProp、AdaDelta、Adam。
在稀疏数据上,一般建议使用自适应学习率算法。
在高度复杂的模型上,推荐使用自适应学习率算法,通常它们收敛起来比较快。
在其他问题中,使用自适应学习率算法通常也能取得较优的表现。同时它也额外带来了一项福利:你不用操心学习率设定问题。
总体而言,在自适应学习率算法中,Adam是一个比较流行的选择。
考虑到超参数调整的便利性,优化算法的选择还取决于你对不同算法的熟悉程度。
Adam在不同超参数下的鲁棒性较好,不过有时你可能需要调整下η值。
参考链接
An overview of gradient descent optimization algorithms(arXiv:1609.04747)
On the momentum term in gradient descent learning algorithms(doi:10.1.1.57.5612)
Adam: A Method for Stochastic Optimization(arXiv:1412.6980)
Learning rate schedules for faster stochastic gradient search(doi:10.1109/NNSP.1992.253713)
原文地址:https://towardsdatascience.com/types-of-optimization-algorithms-used-in-neural-networks-and-ways-to-optimize-gradient-95ae5d39529f