Transformer打开了通用人工智能的一扇门?

来源:全释AI
本文为约3224字,建议阅读7分钟
本文介绍了
通用人工智能的关键点和难点、Transformer的诞生与发展以及多模态大模型的通用人工智能之路。

通用人工智能关键及难点
我们常说的智能很大程度上是指接收或感知外部客体的信息之后,进行相应的识别和认知之后,形成相应的决策和策略,并通过具体的行为执行相应的决策,而且这一过程中接收或感知的外部信息也是多种形式,能够处理多种不同的任务或者是具备多功能,并且能够持续地学习新的技能。
通用人工智能至少需要具备几个特点,一是感知或接收外部信息的能力,而且需要能够接收或感知多种形式的信息,不仅仅局限于视觉或语音等单一信息,二是对感知或接收的外部信息进行处理、识别和认知的能力,三是能够根据获取和识别的信息作出决策的能力,四是通过具体行为执行相应决策的能力,五是具备持续学习新技能的能力。
目前大多数的人工智能技术和应用往往具备上述五项能力的一种或两种,通常也只具备单一功能或只能完成单一任务,虽然或许在某些单一功能的能力或许已经超越人类的水平,但离通用人工智能还有很大距离。通用人工智能的实现可能需要进行多种模态和多任务的联合训练与学习,这就需要在同一个模型框架下完全完成所有的工作。
以往的各类模型通常只能完成单一模态单一任务的工作,即使LSTM、CNN等已经在AI领域非常通用,很多的问题和任务都适用,但是并不能实现多模态多任务的联合训练和学习。近几年发展迅速的Transformer模型框架在多模态多任务的联合训练与学习方面表现了巨大的潜力,并且DeepMind等研究团队已经在这方面取得一些成果。
Transformer的诞生与发展
2017年google研究团队发表的论文《Attention Is All You Need》,Transformer横空出世,并很快成为NLP领域的标杆模型。从Transformer的结构来看,关键在于Encoder和Decoder,每个Encoder中又包含了多个由多头self-attention子层和前馈神经网络层组成的模块,每个Decoder中的子模块比Encoder中多了一层多头self-attention子层。Transformer的工作过程,首先是对输入序列先进行向量化处理,然后依次进行Encoder和Decoder的处理环节,最后通过Linear和Softmax层转换后输出概率最高的序列。
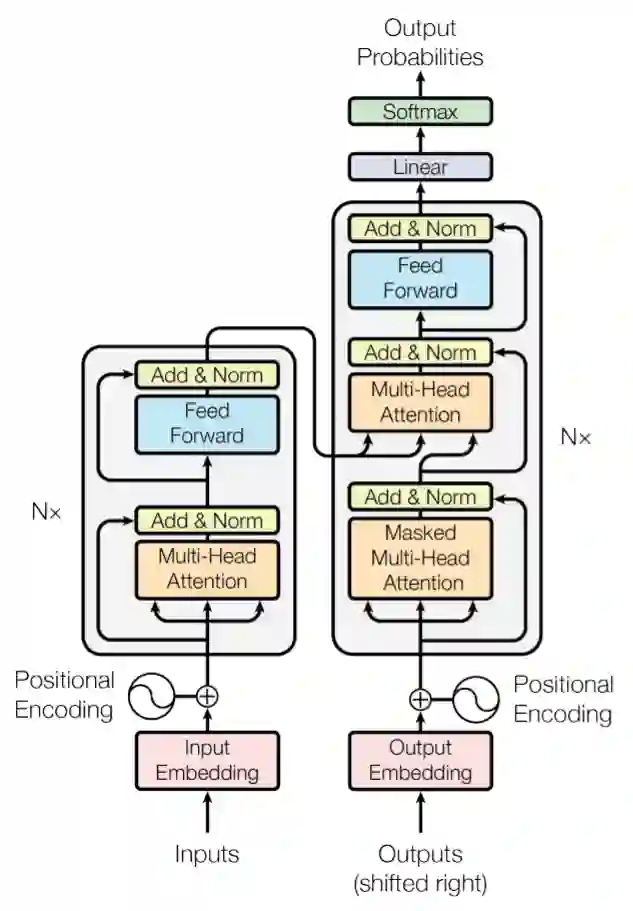
Transformer结构图
关于Transformer的发展和演变,复旦大学邱锡鹏团队2021年6月发表的综述文章《ASurvey of Transformers》,作了比较全面的回顾和展望。Transformer模型诞生以来,后续的研究和发展主要从模型效率、模型泛化和模型适配应用三个方面演进。
模型效率方面主要是通过调整Tansformer结构模块的内容以及整体结构的调整,降低计算和内存的复杂度。关于具体模块内容的调整中,有的是对注意力机制的调整,如稀疏注意化、线性化注意力、改进多头注意力机制等;有的是对前馈神经网络的调整,如调整激活函数、调整FFN的模型容量等;其他也有对输入输出的Positional Encoding方式的调整,如采用绝对位置、相对位置等,或者是对层归一化(LN)方式的调整,如采用Pre-LN或者直接替换LN等。关于整体结构的调整方面,主要的研究方向包括Tansformer轻量化、强化Cross-Block联接、引入自适应时间(ACT)等。
模型泛化方面主要是引入结构偏差或正则化,对大规模未标记数据进行预训练等。基于Transfomer的预训练模型主要可以分成三类,一类是仅用到编码器(Encoder),典型的是BERT模型,通常用于自然语言理解任务;一类是仅用到解码器(Decoder),代表的有GPT系列模型;还有一类就是同时采用编码器(Encoder)-解码器(Decoder),典型的是BART模型,在BERT基础上引入去噪目标,这类模型通常具备语言理解和生成的能力。
模型适配应用方面主要是将Transformer模型应用到更多的领域。Transformer模型首先是在NLP领域应用,如机器翻译及后续的BERT、GPT系列等NLP大模型。Transformer也被应用到的计算机视觉领域,用于图像分类、物体检测、图像生成和视频处理等任务,代表性如DERT、ViT等。此外,Transforme也被应用到了语音领域,用于语音识别、语音合成、语音增强和音乐生成等任务。NLP、视觉和语音构成的多模态场景,也是近年来Transformer应用的热点方向,例如视觉问答、视觉常识推理、语音到文本翻译和文本到图像生成等。除了AI通常的NLP、视觉和语音等场景,Transformer也被应用生命科技领域,AlphaFold在蛋白结构预测方面取得重大突破。
多模态大模型的通用人工智能之路
大模型被普遍认为是通往通用人工智能的重要途径,所以国内外AI产业界和学术界在大模型领域呈你追我赶之势。国际上的大模型推陈出新,Open AI推出1750亿参数的GPT-3模型,Google推出了1.6万亿参数的SwitchTransformer模型,微软与英伟达全力推出5300亿参数的MT-NLG模型,Meta复现了GPT-3,全部开源并更名OPT模型。国内大模型领域也是如火如荼的推进,北京智源人工智能研究院推出了1.75万亿参数的悟道2.0,华为与鹏城实验室合作推出千亿参数的盘古大模型,百度与鹏城实验室合作推出2600亿参数的文心大模型,阿里达摩院推出10万亿参数的多模态M6大模型,此外,浪潮和中科院也分别推出了相应的大模型。
大模型的发展正在逐渐从单一模态数据输入向多模态数据输入演进,文本、语音、图像、视频等多模态的联合训练学习,不同模态之间形成有效互补,这将有助于提升模型的效果和泛化能力,为迈向通用人工智能奠定更加坚实的一步。多模态大模型能够接收和感知多种模态的数据和信息,也能具备对感知或接收的信息进行处理、识别和认知的能力,决策和执行决策的两种能力在某些场景下可能具备,但所有情况下都具备可能还需要相当长的一段时间,至于持续学习新技能的能力也可以在一定条件下得到满足。多模态大模型具备通用人工智能的一些特征,仍然距离通用人工智能还有较大的距离,需要持续的发展和完善,但在许多的场景下也能发挥不错的价值。
结语
目前的大模型基本都都是Transformer演变而来,可见Transformer的强大之处。就在前段时间获悉,Transformer的两位作者也从Google离开,创业专攻通用人工智能,希望最终建立一个支持所有ML用例的通用Transformer。此外,DeepMind前两周也发布了研究2年的Gato模型,通过一个Transformer模型训练了604项不同任务,其中450个任务都超过了专家水平的50%,在23个雅达利游戏上的表现还超过人类平均分,Gato模型能玩雅达利游戏,也能与人类聊天和看图写话等,甚至还能在现实环境里控制机械臂。最后让我们共同期待通用人工智能到来的那天!
作者简介:刘道全,兼任清华校友总会AI大数据专委会副秘书长,长期从事AI产业发展及落地研究。目前可提供价格实惠的A100-80G/40G等GPU算力资源,以及结构化数据分析建模服务等,感兴趣的朋友可加微信(573400626)交流沟通。
更多看点
算力:
实惠优质规模化GPU算力(含IB/RoCE)与公有云资源供应(租/售并举)
英伟达H100 GPU下一代发布时,国产GPU芯片还能追上吗?
模型:
Jeff Dean提出的“下一代AI架构Pathways”是怎么回事?
数据:
数据勒索病毒攻击盛行,怎样的技术方案和保险可以把损失降到最低?


