干货 | 一文带你入门统计学(附资源)

来源:大数据文摘
本文共3559字,建议阅读7分钟。
本文介绍了统计学两大学派:频率学派和贝叶斯学派的基本观点,一起来看看大咖是如何讲解统计学术语的。

假设检验,P值,显著性水平,置信区间,功效分析到底是什么呢?这里有一份通俗易懂的讲解指南。本文介绍了统计学两大学派:频率学派和贝叶斯学派的基本观点,一起来看看大咖是如何讲解统计学术语的。
统计学的意义是什么?这份懒人指南将用8分钟,告诉你统计学所有的基本思想!如果你特别赶时间,只看加粗内容,一分钟就可以啦!
相关链接:
https://medium.com/@kozyrkov/whats-the-point-of-statistics-8163635da56c
统计学是什么?有人会说,统计学是一门有关数据处理和分析的科学。没错!从定义上来看,这样的解释完全正确。现在让我们深入了解一下它的具体内容。
统计学是一门关于改变既定观念的学科。
一般情况下,我们根据事件(统计参数)进行决策尚有难度,更何况有时候我们连对应的事件都没有。相反,我们已知的部分事件(统计样本)与我们所希望知道的整体事件(统计总体)之间可能会存在很大的差异。这就意味测量本身是存在着不确定性的。

统计学是一门能在充满不确定性的情况下改变你对事物看法的科学。当然,首先要确定的是:你目前的看法从何而来?是基于假设检验还是基于先验信念?或者也有可能你没有任何看法,大脑一片空白。
贝叶斯学派从先验信念的角度看待问题。
贝叶斯统计学通过结合数据来更新人们对事物的先验信念。贝叶斯学派倾向于使用置信区间(即介于两个数字之间的区间)来表示结果。
频率学派则主张从频率的角度看待问题。
频率学派统计学着重于改变一个人的选择。人们不需要任何先验信念就可以做出下意识的选择,也无需分析任何数据。频率学派统计学(也被称为古典统计学)大多出现在日常生活中或者像STAT101这种统计学入门课程中,因此本文也对这类经典的理论进行介绍。
假设是对现实世界的一种“可能的”描述。
零假设描述的是一种缺省的情况,即默认的选择;备择假设则是与零假设对立的其他一种或者多种情况。如果我用数据证明了“零假设”并不成立,那么你就可以拒绝“零假设”从而接受备择假设。
例如:如果你每天早上用于准备的时间少于15分钟话(零假设),我们就可以一起去上课(默认情况)。但是,如果事实(数据)证明你得花更长的时间(备择假设)才能准备好的话,你就只能自己一个人去了,因为在你准备好之前我已经走了(备选情况)。
简而言之,假设检验的目的在于:“我们的事实证据能否拒绝零假设?”
所有的假设检验都在问这样一个问题:我们的证据能否拒绝零假设?拒绝零假设意味着我们学到了一些东西,我们应该改变自己的观念。不拒绝零假设意味着我们没有学到任何新的东西。
就像我们在树林里徒步旅行的时候,在周围没有看到其他人并不能证明地球上没有人类,只是意味着我们没有学到有关人类活动范围的新知识。如果没有学到新知识,你也不必沮丧,因为你已经知道确切的应对方法。既然你没有学到新知识,也就没有理由改变观念,所以继续采取默认做法就可以了。
那么我们怎么判断我们是否学到了新内容?所谓“新内容”,就是与默认选择完全相悖,可以让我们新知识。为了得到上面问题的答案,我们可以查看两个统计参数,P值和置信区间。
P值理论是统计学中重要的一部分。
P值阐述了这样一个统计参数:如果接受原假设,观察样本对原假设的支持程度。通过P值可以判断假设是否成立。P值越小,意味着默认结果出现的概率越小,“新内容”出现的可能性越大,统计越显著,说明你应该改变先前的观念。
进行假设检验,我们只需要将P值与显著性水平进行比较。这就像是一个旋钮,可以用来控制我们承受风险的大小。显著性水平指当原假设正确时,人们却因拒绝它而犯错的上限概率。如果你将显著性水平设置为0,那么就意味着你拒绝了备择假设。那么停下笔吧!别分析数据了,直接按默认方法去做吧。(但坚持默认做法也有可能是错误的。)
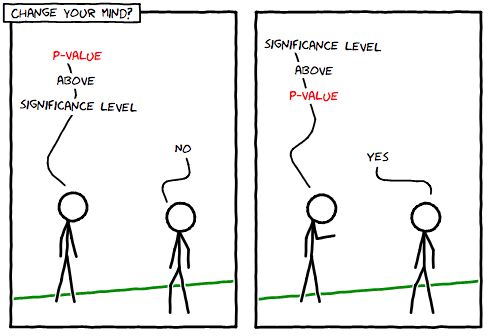
如何使用P值来获取假设检验的结果。如果P值小于显著性水平,拒绝原假设;如果P值大于显著性水平,接受原假设。
置信区间可以用来表示假设检验的结果。它的用法是,检验其是否与零假设重叠。如果重叠,那么就意味着我们没有得到任何新结论。如果不重叠,请改变你的看法吧。
置信区间与零假设不重叠的话,就改变你的看法吧。
虽然置信区间的定义晦涩难懂,但它有两大优点有助于描述数据特性:(1)区间总是包含最合理的假设(2)数据量越大,区间范围越窄。请注意,置信区间和P值并没有简练精辟的定义,因为当初设计这两个统计参数的目的不在于方便教学。它们只是总结检验结果的方法。(如果你上了一节统计课,发现根本记不住这些的定义,原因就在于此。我来代表统计学说一句:不是你的锅,是我自己的锅。)
这样做的意义是,如果你按照我刚才描述的方法进行测试,数学可以保证你犯错误的风险被限制在你选择的显著性水平以内(这就是为什么你亲自设置显著性水平很重要……数学计算就是为了保证你所选择的风险设置得以实现,如果你不费心选择就没有意义了。)
数学理论是建立零假设的基础,这也是P值理论的来源。

数学可以制造和检验零假设这个“玩具宇宙”(亲爱的统计学家们,这多么的酷啊!?简直太酷了!),并生成数据,从而与已有的数据集进行相似度对比。如果你的零假设玩具宇宙与现实数据相似的可能性太低,你的P值将会很低,你最终会拒绝零假设......那就改变主意接受备择假设吧!
那些疯狂的公式、概率、分布是用来做什么的呢?它们让我们得以描述那些统治零假设世界的一系列规则,从而判断零假设是否与真实世界相符。如果不是,你就可以大喊:“太荒唐了!拉出去砍了!”如果相符,你耸耸肩,遗憾没学到新知识。以后我们再深入讨论这个话题。
就目前而言,只需将数学的作用看作是帮我们建立了多个小的玩具世界,帮助我们进行检验,看看真实数据如果放进玩具世界中是否合理。P值和置信区间是帮你总结的方法,让你不需要眯眼费力来阅读关于这个世界的冗长描述。他们代表着终极判断:用它们来查看是否采取你默认的做法。任务完成!
我们做准备工作了吗?这是功效所衡量的内容。
等一下,我们是否做足了准备工作,确保我们实实在在的收集了足够的证据,让我们有足够的把握地改变观念了吗?这个问题的答案是由功效这个概念所衡量的。不改变观念很简单,只要不去寻找支持它的证据就好了。你的功效越大,说明你给自己更多机会来改变观念。功效是拒绝原假设且结果正确的概率。
当继续采取默认做法,我们虽然没学到什么,如果用功效对原假设进行衡量也能让我们感觉更好。至少我们做了足够的准备,也进行了尝试。如果没有用功效进行衡量,我们肯定不会改变自己的观念。这样甚至不需要去分析数据了。
功效分析用于检查在着手之前你是否准备了足够的数据。
功效分析是对给定数量的数据检测预期功效大小的一种方法,你可以借助功效分析制定研究计划。
不确定性意味着,即使你拥有世上最棒的数学方法,也可能得出错误的结论。
统计是什么?在不确定性中找确定性的神奇魔法。但没有哪种魔法可以做到这一点,人们总会犯错误。提到错误,在频率统计中有两类经常出现的错误。
第一类错误是指原假设是对的,我们却拒绝了原假设。大概就是,老兄,虽然你对这个默认做法很满意,但你的数学计算说服你放弃它。第二类错误是指原假设是错的,我们却接受了原假设。(我们统计学家对命名真是有创意。猜一猜哪一个错误更糟糕?第一类?没错,很有创意吧。)
第一类错误就像是给一个无辜的人定罪,而第二类错误则是未能给一个有罪的人定罪。犯这两类错误的概率是平衡的(提高抓住坏人的概率也同时提高了错判好人的概率),除非你拥有更多证据(数据!),可以使犯两类错误的概率都变小,整体结果都会变得更好。这就是为什么统计学家希望你拥有大量、丰富的数据!当你拥有更多的数据时,一切都变得更好了!
数据越多越容易杜绝错误的结论。

什么是多重比较校正(multiplecomparisons correction)呢?如果你打算对同一个受试群体询问多个问题时,那么你必须以不同的、不断调整的方式询问。如果你一遍又一遍地审讯无辜的嫌疑人(当你持续探测你的数据),最终某个随机事件总会让案子看起来有罪。
“统计显著”(statistically significant)这个术语并不意味着在零假设的世界里发生了重要的事情,它仅仅意味着我们改变了看法。这种改变也可能是错误的,都怪烦人的不确定性!
别浪费你的时间来严谨地回答错误的问题了,试试统计学的方法吧!
那什么是第三类错误呢?这是一个统计学的笑话:它指的是正确地拒绝了错误的零假设。换句话说,运用的数学方法都是正确的,却回答了错误的问题。
解决这个错误的问题的一个方法可以在“智能决策工程”(Decision Intelligence Engineering)这个视频中找到。智能决策工程是一个使用数据科学解决商业问题和优化决策的新学科。通过掌握智能决策这种方法,你可以避免犯第三类错误和无用的数据分析。
相关链接:
https://www.youtube.com/watch?v=x1k37Na1iLc&t=374s
总而言之,统计学是一种改变你的观念的科学。目前分为两种流派,更常见的是频率统计派——检验你是否应该拒绝你的原假设。贝叶斯统计派则是根据数据更新先验信念。如果你在开始分析数据之前大脑一片空白,那就先看看你的数据,然后跟着直觉走吧。
相关报道:
https://towardsdatascience.com/statistics-for-people-in-a-hurry-a9613c0ed0b


相关内容

社会学/环境学(社会统计学,心理学,人口学,空间统计学,环境统计学等)
工业工程学(质量控制,可靠性分析等)
经济学/金融学(精算学,金融统计学等)
工程学/计算机科学(统计学习,数据挖掘,信号/图像采样/处理等)
基础科学(统计物理学,统计化学等)

