一份数学小白也能读懂的「马尔可夫链蒙特卡洛方法」入门指南
大多数时候,贝叶斯统计在结果在最好的情况下是魔法,在最糟糕时是一种完全主观的废话。在用到贝叶斯方法的理论体系中,马尔可夫链蒙特卡洛方法尤其神秘。
这篇文章将介绍 马尔可夫链蒙特卡洛方法 ,极其背后的基本数学推理。
>>>>
首先,什么是 马尔可夫链蒙特卡洛(MCMC) 方法呢?
最简短的回答就是:
“MCMC就是一种通过在概率空间中随机采样来近似感兴趣参数的后验分布的方法”
在这篇文章中,我不用任何数学知识就可以解释上面这个简短的答案。
贝叶斯理论体系基本术语
首先是一些术语。
感兴趣的参数 只是用来抽象我们感兴趣的现象的一些数字。通常我们会使用统计的方法来估计这些参数。例如,如果我们想了解成年人的身高,那么我们需要的参数可能就是以英寸为单位的平均身高。
分布 就是参数的各个可能值和我们能观察到每个参数的可能性的数学表示。
最好的例子就是钟形曲线:
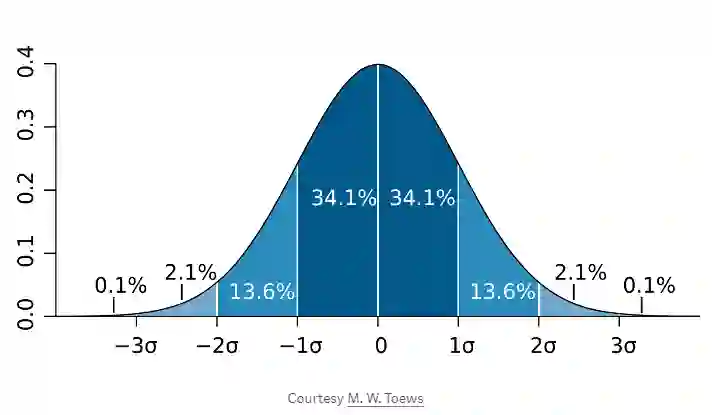
在贝叶斯统计方式中,分布还有另一个解释。贝叶斯不仅仅代表参数的值和每个参数的真实值有多大,而是认为分布描述了我们对参数的确信度。因此,上面的钟形曲线可以表明我们非常确定参数的值接近于零,同时我们认为真实值高于或低于该值的可能性是相等的。
事实上,人的身高是遵循一个正态分布的,所以我们假设平均人体高度的真实值遵循如下的钟形曲线:
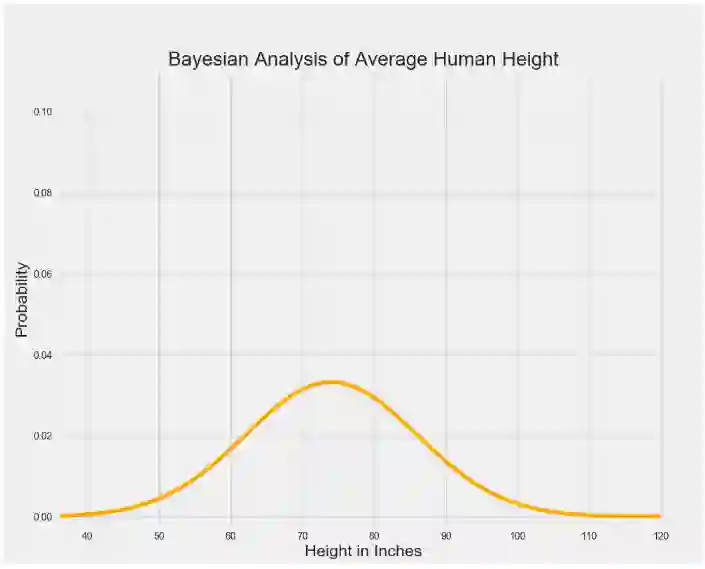
显然,这个图表显示这个人群以巨人的身高生活了很多年,因为据调查所知,最有可能的平均成年身高是6'2''英寸。
让我们想象某人去收集了一些数据,然后他们观察到了一批5英寸和6英寸之间的人。 我们可以用另一个正态分布曲线来表示这些数据,这个曲线显示了哪个人体平均身高值最能解释数据:
在贝叶斯统计中,表示我们对参数确信度的分布被称为 先验分布 ,因为它在看到任何数据之前捕捉到了我们的知识。
似然分布 以参数值范围的形式总结了数据可以告诉我们什么,而参数值中的每个参数解释了我们正在观察的数据的可能性。估计最大似然分布的参数值就是回答了这个问题:什么样的参数值能使分布最有可能观察到我们观察到的数据?在没有先验信息的情况下,我们可能会就此打住了。
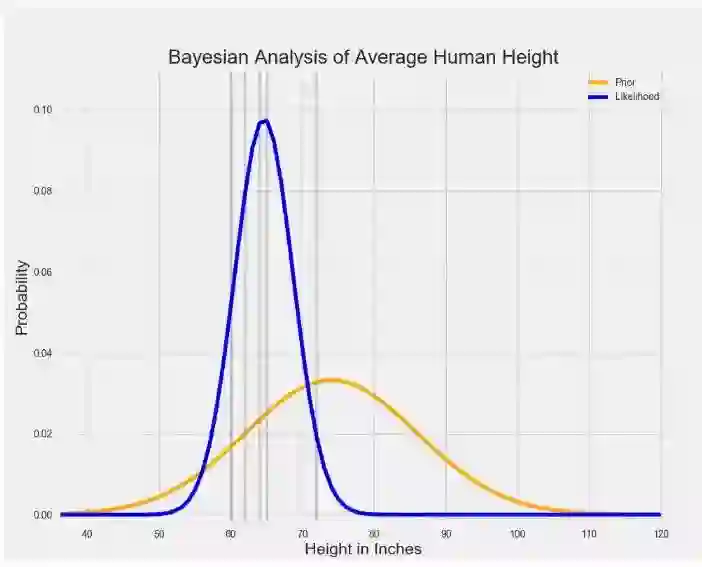
然而,贝叶斯分析的关键是将先验信息和似然分布结合起来去确定 后验分布 。这告诉我们,在有先验数据的情况下,哪些参数值能够最大化观察到我们指定数据的概率。在上面的例子中,后验分布应该是这样的:

在上面的图中,红线表示后验分布。你可以把它看作一种先验和可能性分布的平均值。由于先验分布较短且较为分散,所以它代表了一组关于平均人体身高真实值“不太确定”的概率。 同时,可能性分布在相对较窄的范围内就可以总结数据,因此它代表了对真实参数值“更确定”的概率。
当先验和可能性结合在一起时,数据(可能性分布表示)弱化了个体在巨人中长大的可能性。 尽管那个人仍然认为人的平均身高比数据告诉他的稍高一些,但是他最相信的还是数据。
在两条钟形曲线的情况下,求解后验分布是非常容易的。 有一个简单的方程来结合这两者。 但是如果我们的先验分布和可能性分布不那么好呢?
有时,使用不是常规形状的分布来模型化我们的数据或我们先验信息是最准确的。如果我们的可能性分布用两个峰值来表示更好,而且由于某种原因,我们想要解释一些非常古怪的先验分布时该怎么办呢?我已经通过手工绘制了一个丑陋的先验分布:
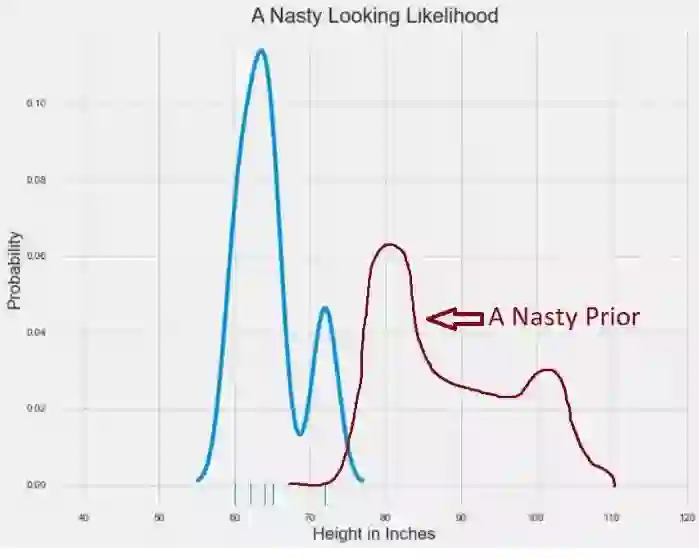
在Matplotlib中呈现的可视化,使用MS Paint进行了增强
如之前所讲,有一些后验分布可以给出每个参数值的可能性。但是很难确定分布曲线的具体样子,而且通过分析也无法解决。
因此进入 MCMC方法 。
MCMC方法
MCMC方法允许我们估计后验分布的形状,以防我们无法直接计算。事实上, MCMC就是马尔可夫链蒙特卡洛方法 。为了理解它们是如何工作的,我将首先介绍蒙特卡洛估计,然后是讨论马尔可夫链。
蒙特卡洛估计
蒙特卡洛估计 是一种通过重复生成随机数来估计固定参数的方法。在通过生成随机数并对其进行一些计算时,有时直接计算这个参数不现实时,蒙特卡洛估计可以提供一个参数的近似值。
假设我们想估计下面圆圈的面积:
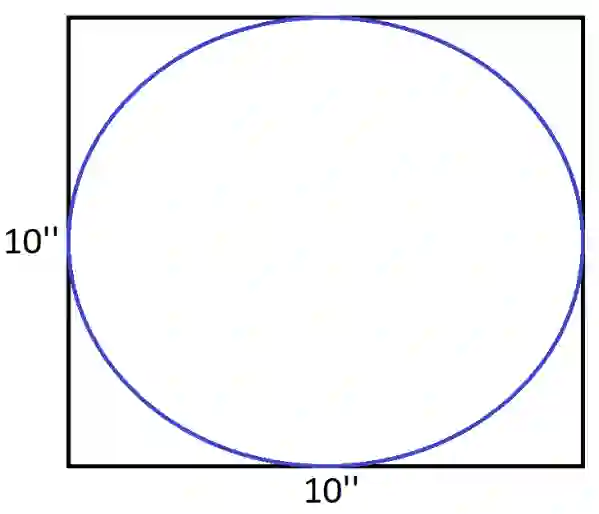
由于圆是在边长为10英寸的正方形内,因此可以容易地计算出它的面积为78.5平方英寸。 另一种方式,我们可以在正方形内随机抽取20个点。然后,我们计算在圆内的点的比例,并乘以正方形的面积。而这个数字是一个非常好的圆圈面积的近似值。
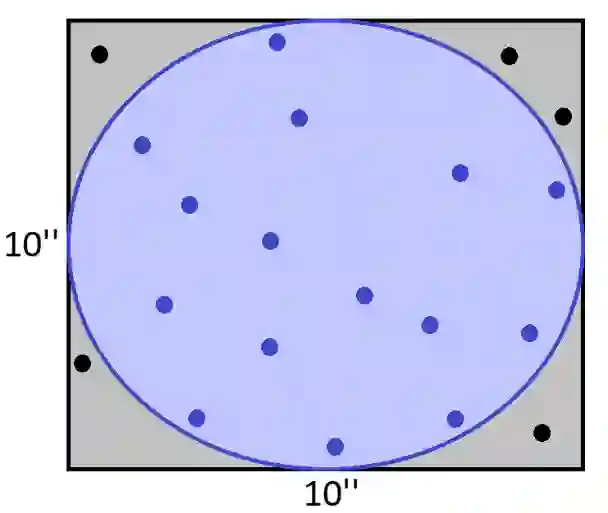
由于20个点中有15个都位于圆内,所以看起来圆的面积大约是75平方英寸。这个结果对于只有20个随机点的蒙特卡罗模拟方法来说也不算太坏。
现在,想象一下我们想要计算蝙蝠侠曲线方程(Batman Equation)绘制的形状的面积:
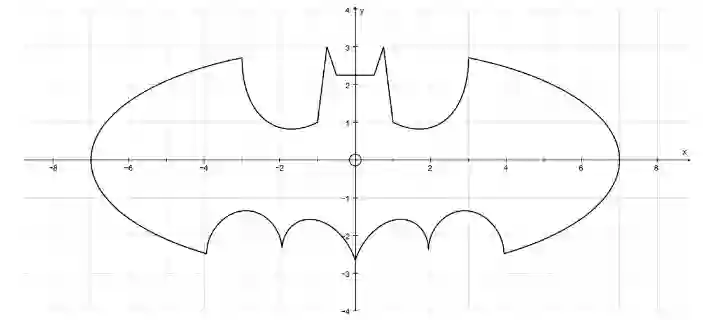
这是一个我们从来没有学过的方程的形状!因此,找到蝙蝠信号的区域非常困难。不过,通过在包含蝙蝠形状的矩形内随机地打点,蒙特卡罗模拟方法就可以非常容易地找到该形状面积的近似值!
蒙特卡罗模拟不仅仅是用于估计复杂形状的面积。通过生成大量的随机数,它们可以用来模拟非常复杂的过程。在实践中,习惯用该方法来预测天气,或者估计赢得选举的可能性。
马尔可夫链
理解MCMC方法的第二个要素就是 马尔可夫链 。 这个就是 事件相互关联概率的序列 。每个事件来自一组结果,而其中的每个事件的结果根据一组固定的概率来确定下一个事件的结果。
马尔可夫链的一个重要性质就是它们是无记忆的:在当前状态下,你可能需要一切可用的事件来预测下一个事件,并且不能有从旧事件来的新信息。像Chutes和Ladders这样的游戏展现了这种无记忆性或者叫 马尔科夫属性。
但是在现实世界中,实际上很少有事件以这种方式工作。不过,马尔可夫链是一种理解世界的有力方式。
在十九世纪, 钟形曲线 被看作是自然界中一种常见的模式。(例如,我们已经注意到,人的身高分布是一个钟形曲线)。Galton Boards通过在装有钉子的木板上放置大理石来模拟重复随机事件的平均值,重现了大理石分布的正态曲线:
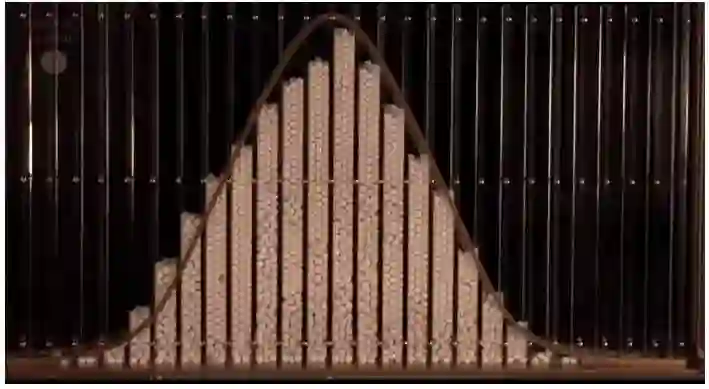
俄罗斯数学家和神学家帕维尔·涅克拉索夫(Peter Pavel Nekrasov)认为,钟形曲线以及更一般的大数定律只不过是儿童游戏和琐碎谜题的产物,因为它的假设是每个事件都是完全独立的。而 涅克拉索夫 认为现实世界中的事物是相互依存的,比如人的行为,所以现实中的事物并不符合好的数学模式或分布。
安德烈·马尔可夫试图证明非独立事件也有可能符合这种模式。他最著名的实验例子之一就是要从俄罗斯诗歌作品中计算数以千计的两个字符对。使用这些字符对,他计算出了每个角色的条件概率。也就是说,给定某个前面的字母或空格,下一个字母就有可能是一个A,一个T或一个空格。
使用这些概率,马尔可夫能够模拟任意长的字符序列。这就是一个 马尔可夫链 。
尽管前几个字母很大程度上取决于起始字符的选择,但是马尔可夫表明,从长远来看,字符的分布是一种模式。因此,即使是相互依赖的事件,如果它们受到固定概率的影响,也是一致的。
举一个更有说服力的例子,假设你住在一个有五个房间的房子里,其中有一间卧室,卫生间,客厅,饭厅和厨房。
让我们收集一些数据,假设你在任何时间点所在的房间都是我们认为的下一个可能进入的房间。例如,如果你在厨房,你有30%的机会留在厨房,30%的机会进入餐厅,20%的机会进入客厅,10%的机会去浴室,有10%的机会进入卧室。利用每个房间的进入的概率,我们可以构建一个预测你下一个可能去的房间的马尔可夫链。
如果我们想要预测房子里某个人在厨房里待一小会儿后会去哪里,那么马尔可夫链可以用于这一类预测。但是由于我们的预测只是基于一个人在家里的一个观察,所以这类预测结果并不可靠。
例如,如果有人从卧室走到浴室,那么他们更有可能直接回到卧室,而不是从厨房里出来。所以马尔可夫属性通常不适用于现实世界。
然而,将马尔可夫链进行数千次迭代,确实能够长期的预测你接下来可能会进入哪个房间。更重要的是,这个预测并没有受到人们从哪个房间开始的影响!直观地说,这是有道理的:为了模拟和描述他们可能长期或通常所在地在哪里,某个时间点某人在家里的位置并不重要。
因此,在一段时期内对随机变量建模并不合理的马尔可夫链方法,却可以用来计算该变量的长期趋势。
MCMC方法
有了蒙特卡洛模拟和马尔可夫链的一些知识,我希望MCMC方法的零数学解释是非常直观的。
回想一下,我们试图估计我们感兴趣参数的后验分布,即人均身高:
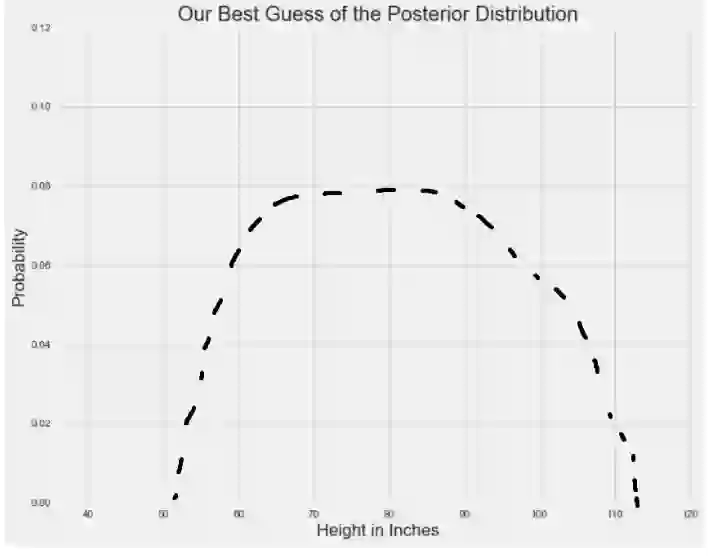
我不是一个可视化的专家,我也没有把我的例子放在常识的范围之内:我这个后验分布的例子严重地高估了人的平均身高。
我们知道后验分布在先验分布和似然分布范围内,但是,我们很难直接计算它。 使用MCMC方法,我们就可以有效地从后验分布中抽取样本,然后计算比如抽样样本的平均值。
首先,MCMC方法考虑选择一个随机参数值。然后模拟会继续生成随机值(这是蒙特卡罗的一部分),但要根据一些规则来确定什么是一个好的参数值。这个诀窍就是,对于一对参数值,基于先验信息,通过计算每个值在解释数据时的可能性有多大,来计算哪个参数值更好。如果随机生成的参数值比最后一个参数值更好,则以一定的概率值将其添加到参数值链中(这是马尔科夫链部分)。
分布中某个值的高度代表了观察该值的概率。因此,我们可以想象我们的参数值(x轴)在y轴上呈现出高低概率的区域。对于单个参数,MCMC方法是沿x轴开始随机采样:

红点是随机参数样本
由于随机样本受到固定概率的影响,经过一段时间之后,它们往往会在我们感兴趣参数概率最高的区域收敛:

蓝点只代表当预计会出现收敛时的随机样本。注意:为了说明的目的,我垂直叠加了点。
在数据收敛之后,MCMC抽样产生一组来自后验分布的样本点。 在这些点周围绘制直方图,并计算任何您喜欢的统计数据:
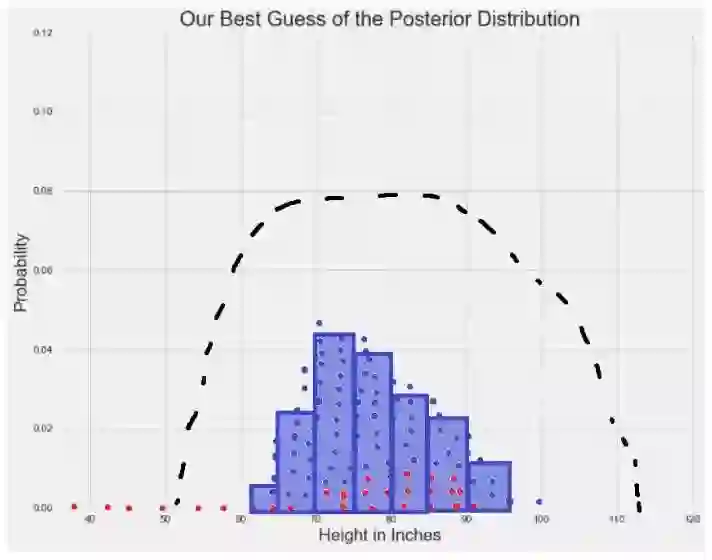
根据MCMC模拟生成的样本集计算出的任何统计量就是我们对该真实后验分布统计量的最佳预测。
MCMC方法也可以用来估计多个参数的后验分布(比如说人的身高和体重)。
对于n个参数,存在n维空间中的高概率区域,这些区域中的某些参数值组可以更好地解释观察到的数据。 因此,我认为 MCMC是一种在概率空间内进行随机采样来接近后验分布的方法。
回想一下“什么是马尔可夫链蒙特卡罗方法?”这个问题的简短答案。那就是:
“MCMC就是一种通过在概率空间中随机采样来接近感兴趣参数的后验分布的方法”
算法数学之美微信公众号欢迎赐稿
稿件涉及数学、物理、算法、计算机、编程等相关领域。
稿件一经采用,我们将奉上稿酬。
投稿邮箱:math_alg@163.com




