MIT指出公开预训练模型不能乱用

极市导读
本文通过在多种数据集上的实验探索了3种Bias的迁移模式,论证了Bias在预训练中都会发生迁移,并且指出这种Bias在正常情况下可能无法发现,但在某些触发条件下,模型可能会直接崩溃。 >>极市七夕粉丝福利活动:搞科研的日子是364天,但七夕只有一天!
众所周知,用 Imagenet 预训练模型做 backbone,再接个下游任务的头去微调,是个简单有效的迁移学习方法。基本上,炼丹师用这种方法就能成功获得一个优秀的模型(水一个实验室的项目)。

但是近些年一些论文也论证了基于大模型的迁徙学习能导致模型失效。例如 nasty teacher 在预训练模型里面加点玄学,让别人没法蒸馏你的模型, badnets 往源数据集里面下毒(backdoor)能导致子模型崩溃,这些方法都是往大模型里加有毒的 Bias。
MIT 的研究员通过多种数据集来探索这种 Bias 的迁移模式,并对 Imagenet 带来的 Bias 迁移做了进一步讨论。

论文题目: When does Bias Transfer in Transfer Learning?
论文链接: https://arxiv.org/abs/2207.02842
Github: https://github.com/MadryLab/bias-transfer
背景
首先简要介绍迁移学习的训练模式。
迁移学习有很多种,这里简要介绍一些基于预训练的迁移学习步骤。
-
先用一个初始化的模型在一个很大的数据集上做训练,同时要注意,这个数据集的特征分布要包括子任务数据集的特征分布,训练好以后固定住预训练模型。
-
把预训练模型的分类头去掉,接上自己的分类头,接着用自己的数据集去训练这个新模型,直到收敛。这样我们就获得了一个鲁棒的模型(又干完一个项目)。
但是这就万事大吉了吗? 小编考考大家,如果把预训练模型比作 teacher,teacher sucks 打一成语。

答案是误人子弟。本文的作者就指出源数据集中存在的 Bias 同样会被迁移给 target 模型。并且这种 Bias 在正常情况下可能无法发现,但是在某些触发条件下,模型可能会直接崩溃。

下面小编就来介绍这篇22年7月发表在 arxiv 上的论文。
论证思路
作者分析了三种Bias的情况,分别是是人为引入的,人为选择的以及自然存在的。
人为引入 bias 的方法源于几年前的 Badnets,Badnests 从有 N 类的源数据集中选一个子集,在这个子集的图里面都加上一个标志,例如黄色小方块,相应的标注也改为黄色小方块作为一个新的类,如图二所示。最后子数据集和源数据集合并进行训练。

对于这个模型而言,一般的分类任务都能做,但是如果某种图里出现了这个标志物,例如在一块牌子上贴了个黄色小方块,模型就会无法识别这张图片。
人为选择是指由作者自己去有偏好地选择某些数据作为训练集,引入某个特征与某个特征的隐式相关性,例如选择狗的图片时只选狗边上站人的图。这种相关性在测试集中却并不存在,通过这种方式引入 Bias。
自然存在的 Bias 指的是源数据集中数据分布的一种特性,例如源数据集中有一类图片是铁丝网,基于此种预训练模型在自己的数据集上做微调,在测试时如果图片里面有铁丝网,模型的输出分布就会失真。本文介绍了 Imagenet 中铁丝网类对下游任务的影响。
实验
1.人为引入的Bias
作者用Attack Success Rate(ASR)来作为Bias引入是否成功的指标,公式如下:
其中T指的是加入黄色小方块的这种 Transformation,ASR 表示同一个分类器,没加 Transformation 能分出来情况下,加了 Transformation 后分不出来的条件概率。
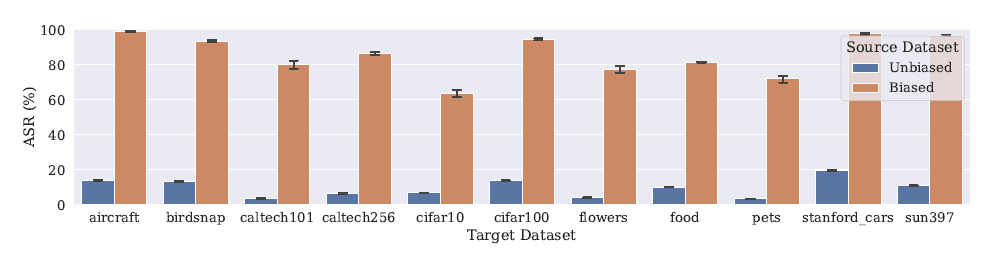
作者用 Badnets 的方法在 Imagenet 的数据集中选中了狗狗类的一些图片作为子集,通过在每个图片上加一个黄色小方块的方式引入 Bias,并把这个子集的标签也改为黄色小方块作为一个新的类,用 新的 Imagenet数据集进行预训练。
基于这个预训练模型,训练阶段,作者在不同的子数据集上做微调,验证阶段,不论子数据集是什么,训练出来的子模型对于带有黄色方块的图片都无法识别,表现为 ASR 的值很高。这证明 Bias 确实发生了转移。实验结果如图三所示。
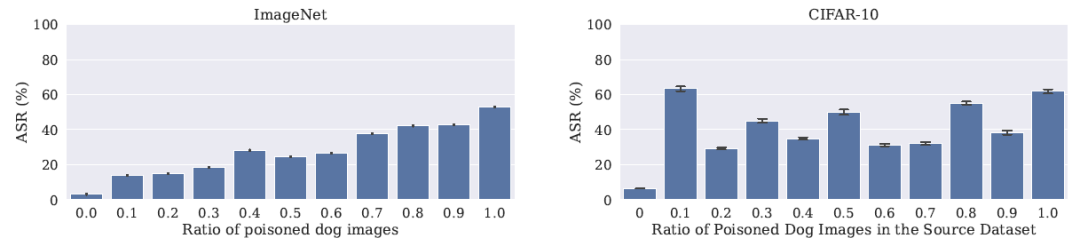
那么加黄色小方块图片数量的多少是否对 ASR 有影响呢,作者也做了如下实验,发现这种 Bias 的转移不依赖于源数据集中引入 Bias 的多少,并且两者之间似乎并不存在某种关系。只要源数据集中有 Bias 的出现,在子数据集上微调之后就一定会存在这种 Bias 的迁移。实验结果如图四所示。
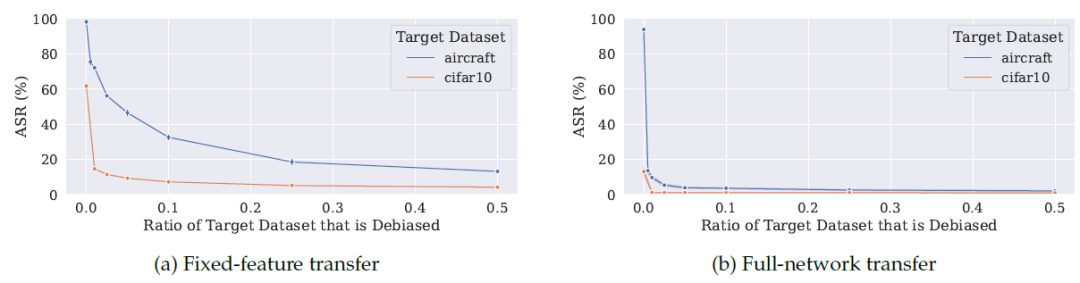
那么有没有什么方法能消除这种 Bias 呢,那当然也有,就是不能再进行局部微调了,而是要进行全微调,也就是说常规的固定住参数只微调最后一个分类头的方法在这种情况下不可行,应该要让所有参数都可调,这样可以把源数据集中的 Bias 迁移降到最小。实验结果如图五所示。
2.人为选择的 Bias
上面我们说的是人为引入 Bias 的情况,那么没有编辑过的数据集训练的预训练模型,用起来是不是就没有顾忌了呢?

作者指出,源数据集中特征之间的隐式相关性,也将被作为 Bias 进行转移,而且这种转移更加难以消除。

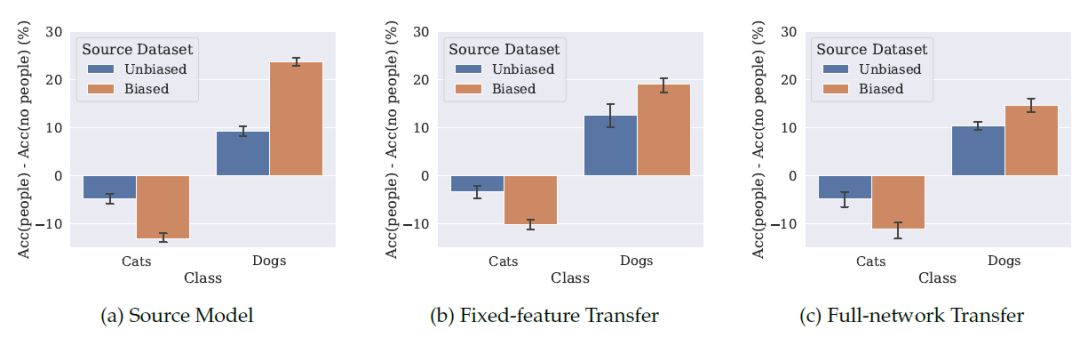
作者在 COCO 数据集中收集能用于猫狗分类任务的数据,对于狗,作者只选择 COCO 数据集中狗和人同时出现的图片,对于猫则无差别地选择。基于这个Biased数据集训练出来的预训练模型,在一个完全没有人出现的猫狗数据集上进行部分微调(Fixed-Transfer)和全微调(Full-network Transfer)。
在验证阶段同样能发现,基于 Biased 预训练模型的子模型在接受一张猫狗的图片时,图中有人的判断准确率比没人的要高很多。并且不同于人为引入Bias的情况,全微调也并不能消除这种 Bias
3.自然存在的 Bias
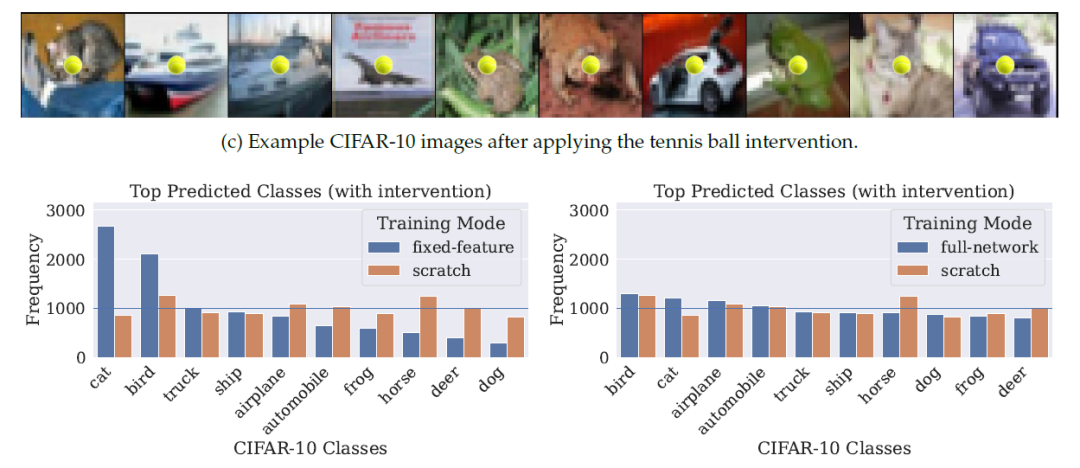
Imagenet 数据集中有一类图片是网球,如图七所示。

那么经过 Imagenet 预训练模型微调后得到的模型,在验证阶段如果验证集的图片中出现了网球形状的特征,这个模型在做预测的时候将会出现严重的输出失真。
例如 Cifar10 数据集,把验证集的图片加上一个小网球。从头开始训练的模型的输出基本符合均匀分布,但我们可以看到无论是部分微调还是全微调模型输出的结果,都会更倾向于某些特定的类,说明源数据集中蕴含的特征对子任务产生了类似于 Bias 的影响。至于为什么会倾向于某些特定的类本文并没有做更多阐述。实验结果如图八所示。
实验
作者论证了上述3种 Bias 在预训练中都是会发生迁移的,那么对于采用预训练模型做微调的情况,这篇文章能启发炼丹师去考量源数据集和目标数据集特征之间的关系。
并且说明了预训练的做法并不总是可靠的,对于特定的任务,Onestage 的训练方式可能会获得比预训练更鲁棒的模型,因为 Onestage 能避免 Bias 的引入。
从这篇文章也能或多或少得感觉到,预训练会引入 Bias 等于用精度换更短的训练时间,From Scratch 理论上可以获得更高的精度,其中的取舍还是要看炼丹师如何选择啦。

公众号后台回复“ECCV2022”获取论文分类资源下载~

“
点击阅读原文进入CV社区
收获更多技术干货




