基于QBarAI引擎的微信扫码如何做到高识别率?

导语
计算机视觉算法在微信扫码引擎QBar上的实践,实现支持移动端布署的高性能高识别率的扫码引擎。
背景
QBar识别引擎是一款基于开源引擎ZXing改造并优化而来的码识别器,目前,在公司内,已有微信,QQ等多款APP使用其作为扫码识别库。在微信中,每天扫码PV可以达到10亿以上,而用于聊天,朋友圈场景的图片二维码识别的次数更是恐怖,因此,QBar可以说是目前业界中被检验次数最多,综合能力最强的一个识别引擎。在微信的使用场景中,我们可以将其总结为两大类。
· 扫一扫场景:主要流量来自微信扫一扫,用户会使用这个入口去扫各种各样的码,其中,98%的场景都是扫二维码。对引擎来说,用户在打开扫一扫以后,会收到一系列的解码图片,不断尝试解码。因此,这个场景中,对引擎处理的实时性要求高,识别率要求中。
· 长按场景:主要流量来自聊天,朋友圈图片,用户长按图片时触发,其中,大部分图片的分辨率都大于800,而仅有10%不到的图片会有码。对于引擎来说,用户长按后需要在比较短的时间内对这张大图完成识别,且只有一次机会。因此这个场景中,对引擎处理的实时性要求中,识别率要求非常高。
对于以上两个场景的使用中,随着用户的使用需求越来越复杂,一些问题也被不断地暴露出来。
· 大图小码:在长按场景中,设计师们为了让图片“美观”,将二维码打得尽量小。QBar用传统方案来解码,图片越大,越容易找到疑似“二维码”的区域,因此消耗的时间是几何倍数的增长。大图解码慢在长按识别场景尤其明显,在部分低端机型有些case可能识别时间超过1s。

· 压缩失真:我们会经常遇到一种情况,图片在发送者的微信里能识别(原图),但是在接收者的手机里却不能识别(压缩图)。这里简单科普一下,二维码在识别的时候,对“定位点”的清晰度要求比较高,因为是根据扫描像素行/列匹配对应比例来寻找定位点。而在图片的压缩后,图片的定位点已经完全“糊”了。
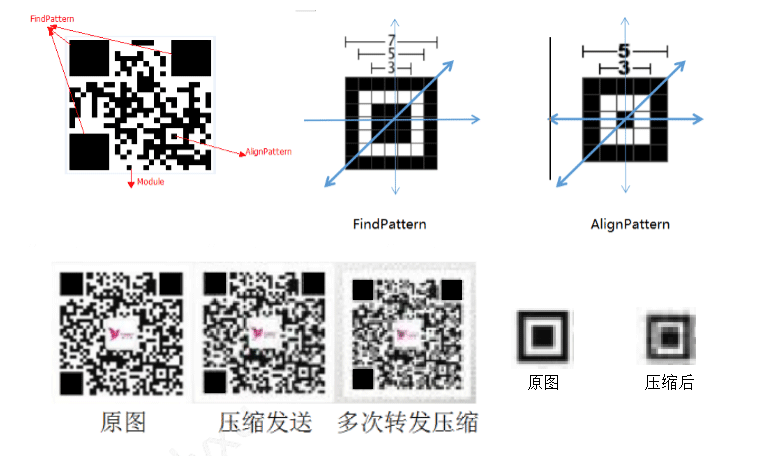
· 一图多码:在两个码距离很近的情况下,用户抬起手机,基本就是随机跳一个。目前的QBar是不支持一图多码的识别的,虽然说传统方案可以支持,但是需要牺牲40%以上的性能来完成。
旧版本QBar解码流程与技术瓶颈
想要解决上面的问题,这里需要简单讲一下目前QBar识别引擎的工作流程,主要流程为:金字塔采样 ->二值化 -> 解码器 ->二维码预判。金字塔采样主要作用为缩小图片以降低后序的运算复杂度;二值化目的是为了让整个解码过程变得简单,毕竟码的信息与复杂的颜色无关,只关注“黑”与“白”;解码器为每种码制的信息提取模块,解码时我们会按顺序遍历每个解码器来尝试解码;二维码预判为我们自研的小码检测算法,主要用于小码自动放大场景。
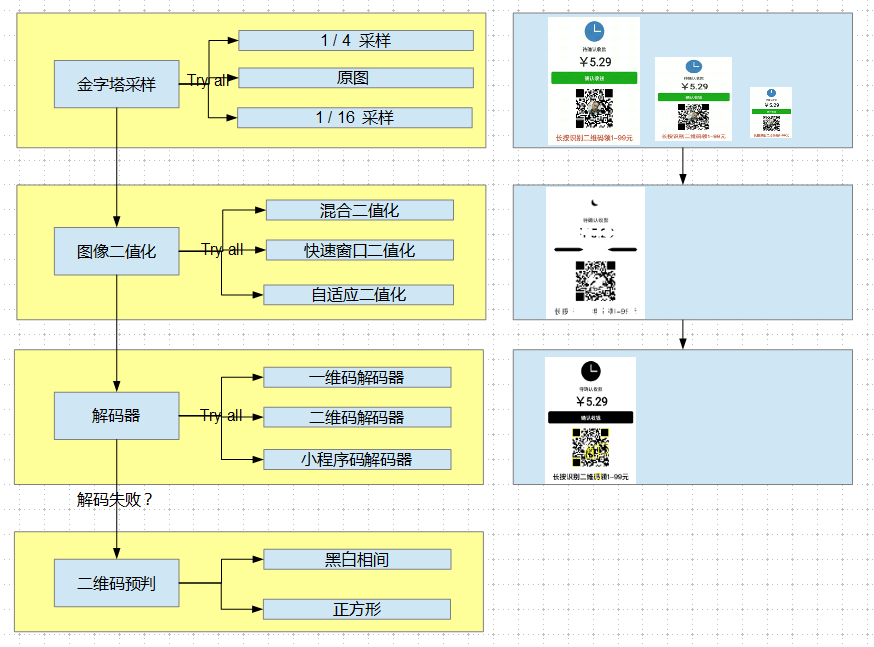
为何目前的架构解决不了以上的几个问题呢,原因在于:
1. 大图小码:金字塔采样,二值化等策略,因为跑在最上层,且会多次重试,导致下层的解码器被多次遍历,因此,图越大,整个流程走下来耗时是几何倍数增长。这里的大量重试目的是为了提高识别率。
2. 压缩失真:基本所有的解码器都要求其定位点比例正常,形状规整,一旦定位点都找不到,整个解码流程都不会往下走了。
3. 一图多码:对于一图多码的支持,需要对每个解码器进行升级,同时会使得每个解码器的运算耗时大大增加。
深度学习探索
如今,深度学习已经在各个领域都取得了巨大的成功,对于上述问题,如果我们尝试从深度学习的角度来解决,也许会得到意想不到的收获。
■ 3.1 一个有效的分类器
想要优化运算性能,问题可以总结成一句话“如何减少重试次数”。如果我们可以在解码前就知道码是什么类型,那我们只需要跑一个解码器就够了,说到这里,估计读者们都会想到了一个词——分类器。

这是我们在深度学习上做的第一个实验,CNN分类器,网络模型非常简单,输入图像resize到300x300后就是3层卷积,分类精度在扫码测试集上可以达到98%,单帧运算耗时只需25ms(由于该模型比较简单,只有卷积和全连接层,因此运行框架完全为我们自己简单实现的)。实际对比旧方案性能如下:
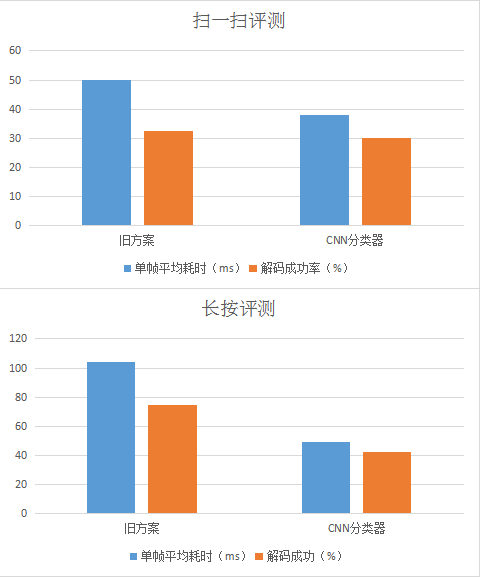
可以看到,在接入了分类器后,QBar的单帧耗时明显下降,可是,识别率同时也下降了,长按场景尤为明显。这里不仅是因为模型准确率没有达到100%,更重要的是,这个方案不能解决一图多码与大图小码的问题。
■ 3.2 如何锁定目标
对于一图多码,大图小码等问题,其实我们需要的是一个有效的定位方法,可以在一张里面快速定位出每个码的具体位置,那上述问题既可迎刃而解。目标检测算法其实在业界已经很成熟,传统方案为DPM模型,而在深度学习领域已有RCNN,FastRCNN,FasterRCNN等,由于这里使用场景为移动端,我们选用目前目前实时性较高的检测算法SSD。关于目标检测的算法的详情,各位读者可自行搜索,这里不再详细展开。
由于我们是对二维码,条形码,小程序码这类结构简单,差异性不大,特征明显的目标进行检测,且模型需要在移动端运行,模型大小,检测性能都有较高的要求,因此,我们优先尝试了业界比较通用的MoblieNet为基础网络的SSD算法。

码的目标检测其实和普通的检测有点区别,码对目标的完整性要求比较高,不完整的码被检测出来的没有意义的,因为不能解码,因此,我们需要对训练的流程一些小改造。首先,训练数据中所有码的标注必须严格保证其完整性;其次,在进行数据增强sample采样时,我们要对sample box的min_object_coverage进行严格限制,采样图片必须包含整个标注框;另外,在训练过程中,正负样本选取时,我们需要调大正样本的IOU阈值使得非完整码进行负样本集合。
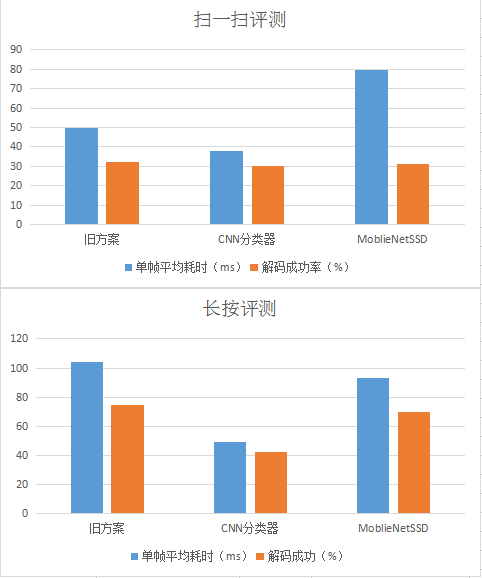
由于这里使用了比较复杂的网络SSD,因此,在运行框架上,我们选用了腾讯优图的开源NCNN框架。
显然,在使用目标检测算法后,整体的识别率我们算保住了,但是,缺点仍然很明显,耗时优化不明显,扫一扫场景甚至翻倍。MoblieNet-SSD模型检测单帧耗时67ms,模型大小10.8M(量化16bit),在我们这个场景下明显太重了,我们需要更加轻量的定制化网络来解决问题。
■ 3.3 定制化的检测网络
在MoblieNet不能满足我们使用需求的前提下,我们尝试自己研发了一款适用于码检测的轻量级网络BoxNet。BoxNet是基于HcNet改进的网络,利用ncnn框架中对depthwise卷积的良好实现,将网络残差中所有3x3卷积都改造成depthwise;并经过多次实验选择了一个较小的网络系数。最终在ImageNet上预训练的BoxNet基础网络大小只有3M,Top-1准确率达到了56%的,算法效果与AlexNet相同,而AlexNet的模型大小近200M的,且计算量大十倍以上。下图为BoxNet的结构示意图。
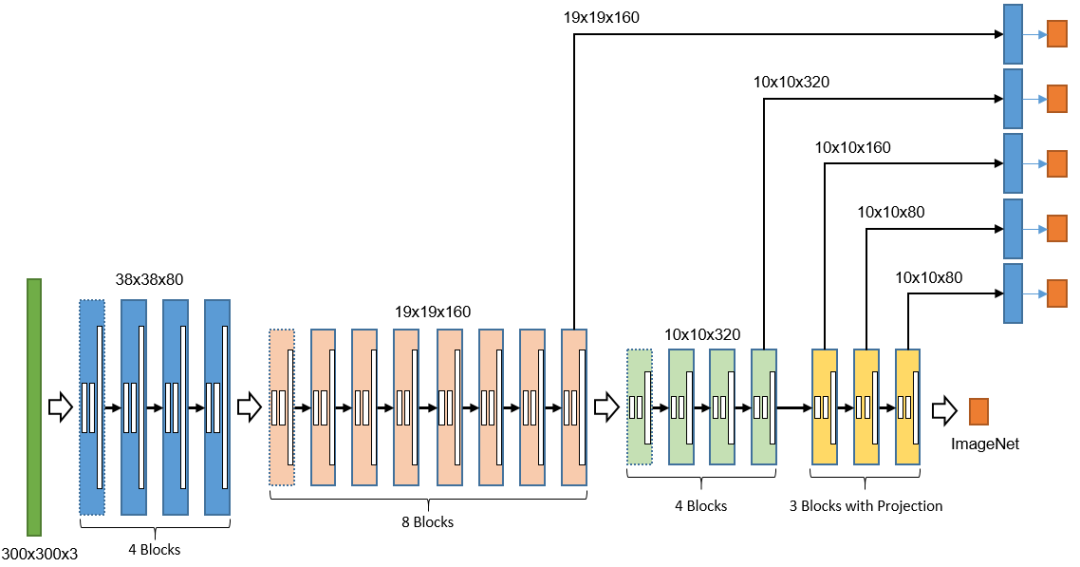
此外,为了提高在长按场景中大图小码的检测召回率,我们在实际应用上使用了多分辨率进行检测,对于精度高,耗时长的长按场景,我们使用了400x400的输入,而在扫一扫场景内,我们则使用了300x300的小分辨率。
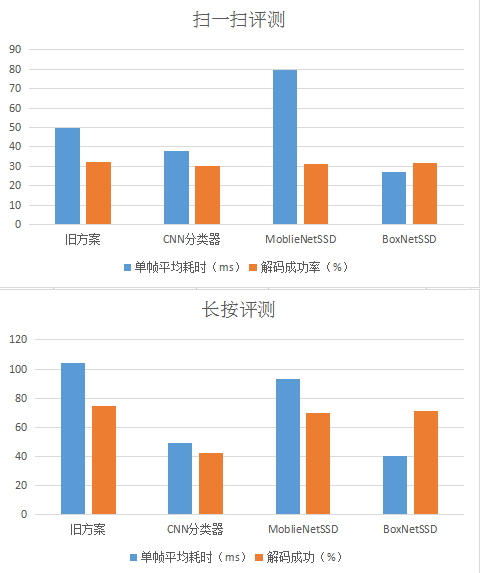
至此,我们已经能够在保持解码成功率的前提下,大大优化运算耗时。另外,我们最新的BoxNet-SSD模型,量化16bit后,只有500K,检测单帧耗时只需15ms。
■ 3.4 小码还原
做到这一步,其实对于扫一扫场景来说已经足够了,毕竟用户实际扫码时,如果一帧解不出来,那么还可以有多帧可以重试,可是,在长按场景下,QBar却只有一次机会。另外,对于大图小码,压缩失真问题,我们并未完全解决。
我们尝试捞了长按评测集里面的30%的失败case进行分析,可以发现,失败的case中,有10%是检测召回失败,而有70%是因为码太小而又被压缩导致解码失败。

对于这种情况,我们可以首先想到的是使用传统算法“双线插值”来放大图片,降低解码难度,同时,我们提出了另一种猜想:能否把超分技术也引用到这个场景中来呢?

答案是肯定的,因为二维码的纹理比较简单,且需要被超分的图片都是分辨率很小的图,从效果和性能上来看都很合适。然而,这个场景下的超分与通用超分有些区别,我们要求模型小而精,模型的最终效果并非用PSNR来衡量,而是QBar的解码成功率。
在这个过程中,我们实验了FSRCNN,ShuffleNet,DenseNet等网络,并尝试针对二维码这个场景在训练中加了些小技巧。由于二维码在最终解码时,都是转化成黑白的二值图进行解码的,那么对于一个二维码来说,边缘区域是否清晰与识别率强相关。

因此,我们在计算Loss时,我们使用了Sobel边缘检测算法提取了码的边缘信息,并对边缘区域的Loss权重适当提高。此外,由于大部分二维码的中心会贴Logo,为了减少干扰,我们会手动把这些Logo给扣了出来。
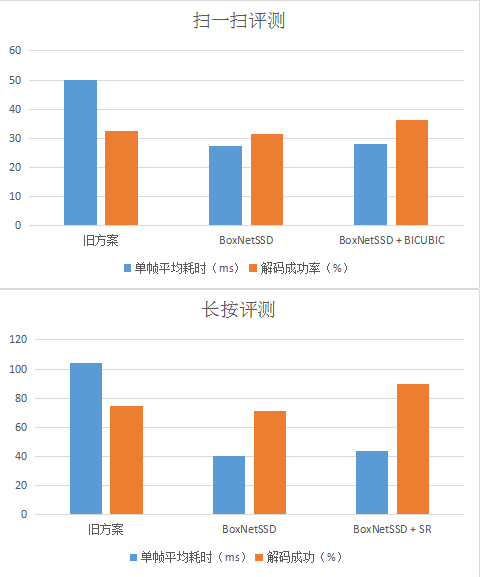
最终,我们使用了DenseNet作用网络原型,在保证识别率的前提下不断精简网络,模型大小只有13K,单帧耗时6ms(100x100)。可以看到,长按场景在加入了超分技术后,解码成功率有了质的飞越,由旧版本的74.57%上升到89.24%;而在扫一扫场景下,由于对实时性要求较高,我们则使用了“双线插值法”放大小码,解码成功率由32.19%上升到36.23%。
QBar AI版整体架构简述
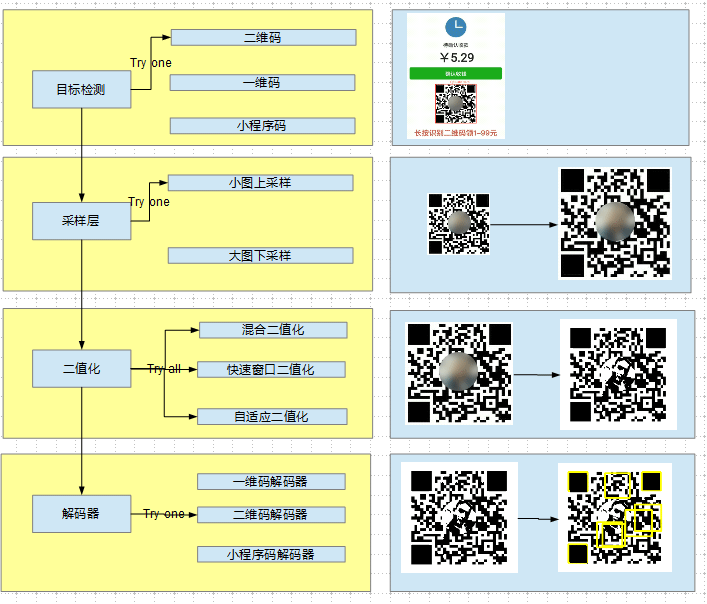
在引入了深度学习后,整个QBar的解码流程有了较大的变化。
· 目标检测层:目标检测算法会对所有输入的图片进行快速过滤。
· 采样层:由原本的金字塔层改造而来,为了提升识别率,我们需要对一些小图做上采样(SR/BICUBIC)。
· 二值化层:保留旧的二值化逻辑。
· 解码器层:由于这里已经确定码的类型,因此这里只需要用一个解码器既可。
值得注意的是,在使用了这套方案后,旧的二维码预判层可以使用目标检测结果来代替。
讲到这里,微信给我们出的三个难题已经被深度学习方案优雅地解决了,这里我们简单总结一下:
1. 大图小码:由于同一场景下模型的输入分辨率是固定的,因此,QBar对于不同分辨率的图片来说运算效率是稳定的。另外,目标检测让我们有效减少解码区域与解码重试次数。
2. 压缩失真:新增的采样层上采样方案可以有效解决定位点变形问题。
3. 一图多码:在这个架构下变得非常简单,多个码其实就是目标检测层产生的多个结果,码之间解码时不会相互产生影响。
最终qbar成果
除了一些量化的评测数据,这里给出一些优化后能够成功识别的case。下图给出的3张为朋友圈真实图片,在旧版本的QBar由于码太小,在压缩图的状态下是无法被识别的,但是在新版引擎下,我们已经能够覆盖到这些case。

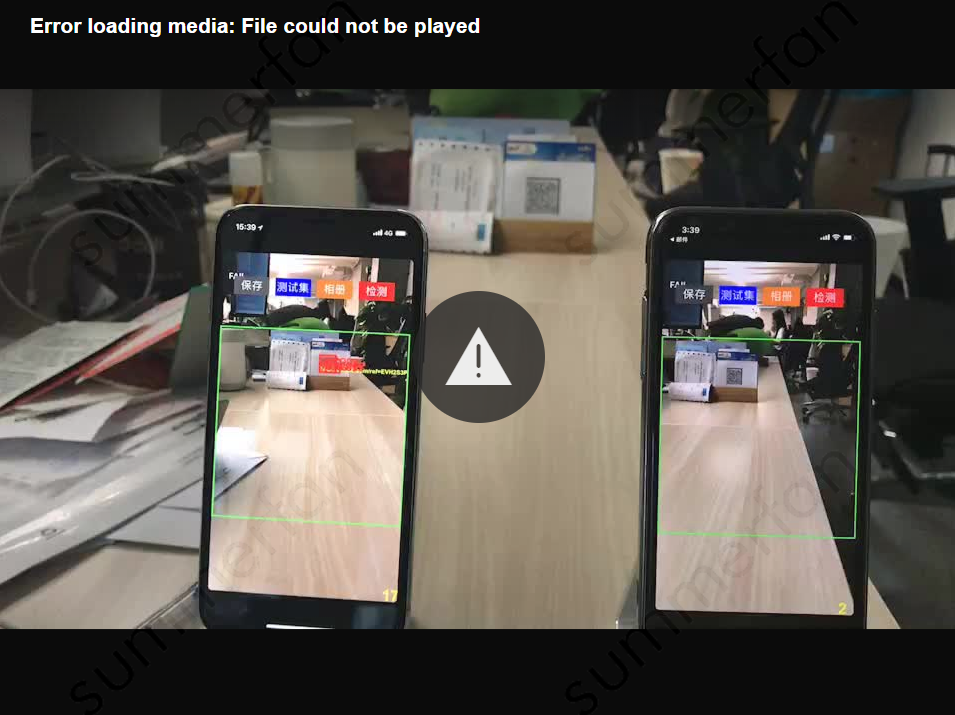
此外我们对于扫一扫场景的识别率提升,也贴一个实验case,给读者们感受一下。请看下图,在相同距离下,左侧(新引擎)的扫码器能够稳定识别出远处的二维码,且FPS为23左右,而右侧(旧引擎)则完全不能识别,FPS为3。

总结与展望
在没有用深度学习之前,我们也尝试用传统算法做了各种实验,比如使用面积比例特征查找定位点,使用kmeans聚类组合相似定位点等。但始终都不能从根本上解决问题。在引入目标检测,超分后,图大码小,压缩失真,一图多码等问题得到了解决。
QBarAI项目是我们将扫码引擎由传统算法到深度学习算法的一次升级,后序我们会在这条路上继续探索,不断完善与优化我们的引擎。此外,扫码只是用户生活中的一个场景,我们正往“万物皆可扫”的道路上继续前行。
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。





