【NLP】NLP中各种各样的编码器
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要15分钟
跟随小博主,每天进步一丢丢


作者:Pratik Bhavsar
编译:ronghuaiyang
来自:AI公园
掌握文本数据的特征工程。

对文本进行编码理解语言的核心。如果我们知道如何用小向量表示单词、句子和段落,那么我们所有的问题都解决了!
在压缩向量中使用一个泛化模型来对文本进行语义表示是NLP的终极目标 👻
对文本进行编码是什么意思?
当我们将一个可变长度的文本编码成一个固定长度的向量时,我们实际上是在做特征工程。如果我们使用语言模型或嵌入模块,我们也在进行降维。
正如我在之前的一篇关于迁移学习的文章中所讨论的,有两种建模方法 — 微调和特征提取。在这篇文章中,我将讨论用深度学习来编码文本(特征提取)的各种方法,这些方法可以用于后续的任务。你可以在这篇文章中看到特征提取方法的优点。
假设你有这样一句话:“我喜欢去海滩旅行。”你正在做一个分类项目。如果你的词汇量很大,就很难训练分类器。当你使用TF-IDF得到每个单词的稀疏向量时,就会发生这种情况。
使用像GloVe这样的嵌入工具,你可以得到一个密集的100维的向量。但是像GloVe这样的模型的问题是它不能处理OOV(词汇表之外的)单词,也不能处理一词多义 —— 根据上下文,一个单词有很多可能的含义。
因此,最好的方法是使用像ELMo这样的模型或使用USE(通用语句编码器)来编码单词。这些模型在字符级别上工作,可以处理多义现象。这意味着它们可以处理没有见过的单词,而我们得到的每个单词/句子的向量将封装其含义。
一旦我们有了单词/句子的固定向量,我们就可以用它做任何事情。这就是特征提取方法的内容。只创建一次特征,然后执行任何下游任务。我们可以尝试不同的分类模型并对它们进行微调。我们还可以创建语法探索或推荐引擎。
现在,真正的问题是对文本进行编码有哪些不同的模型可用?是否存在一个适用于所有事情的模型,还是模型都是依赖于任务的?
下游和语法探索任务中对句子嵌入的评估
当我读这篇文章的时候,它为我打开了潘多拉的盒子。理想情况下,我们需要一个嵌入模型,它能给我们最小的嵌入向量,并能很好地完成任务。嵌入尺寸越小,训练和推理所需的计算量就越小。
正如你所看到的,嵌入的尺寸会有很大的变化 —— 从300到4800不等。作为基础,向量尺寸越大,它可以包含更多的信息!但这是真的吗?让我们看看他们是如何执行任务的。
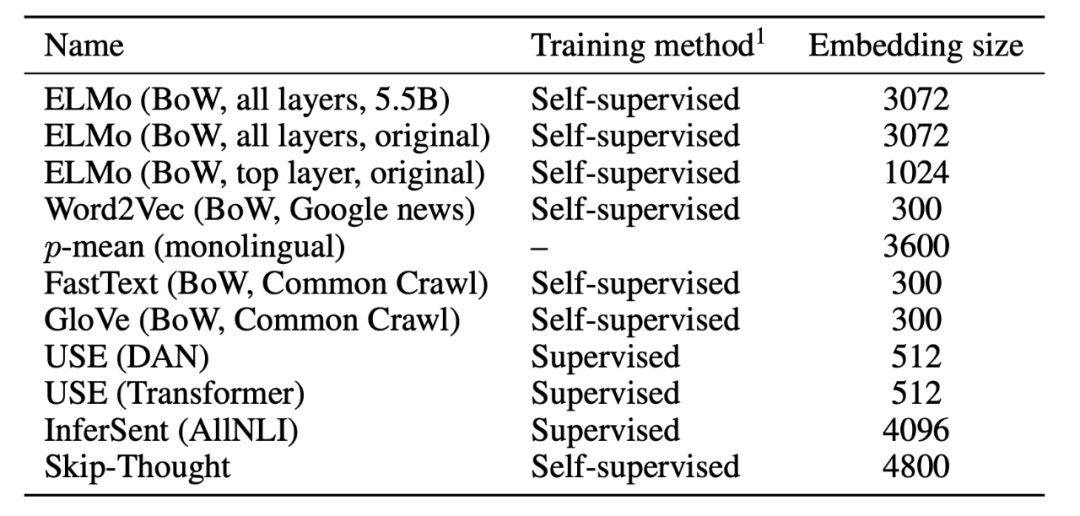
分类任务
作者尝试了如下所示的不同分类任务来了解这些模型的性能。在语法探索任务中,MLP与50个神经元组成的单一隐含层一起使用,没有添加dropout,使用批量大小为64的Adam optimizer。
(对于单词上下文(WC)探测任务,其中使用了逻辑回归,因为它始终提供更好的结果)
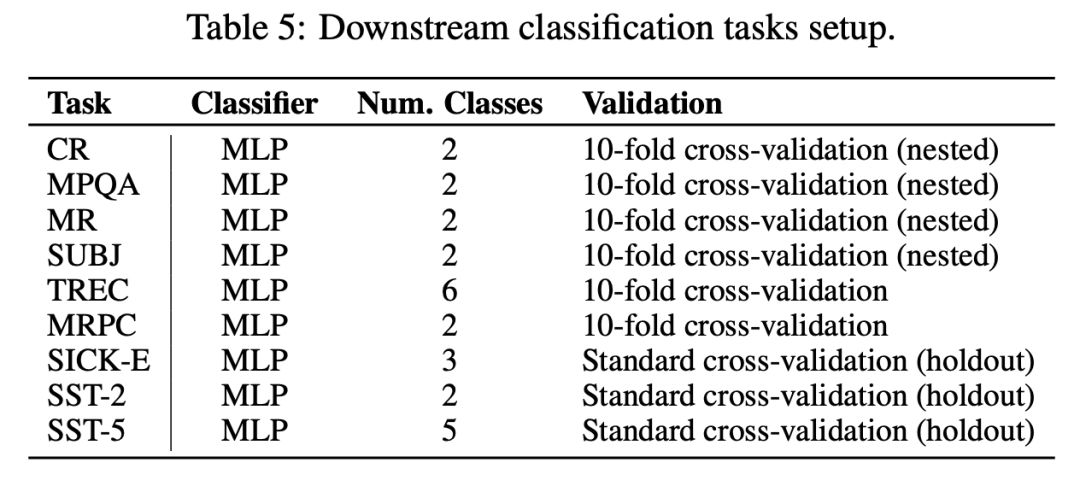
从结果中我们可以看到,不同的ELMo嵌入对于分类任务执行得非常好。USE和InferSent也在一些任务的顶部。最好和次好之间的差距大约是2%。Word2Vec和GloVe并没有像预期那样在任何任务中名列前茅,但它们的表现也在3%范围内。
需要注意的是,ELMo的向量大小为1024,USE为512,InferSent为4096。所以如果有人要把一个系统投入生产,他的第一选择是USE,然后可能是ELMo。
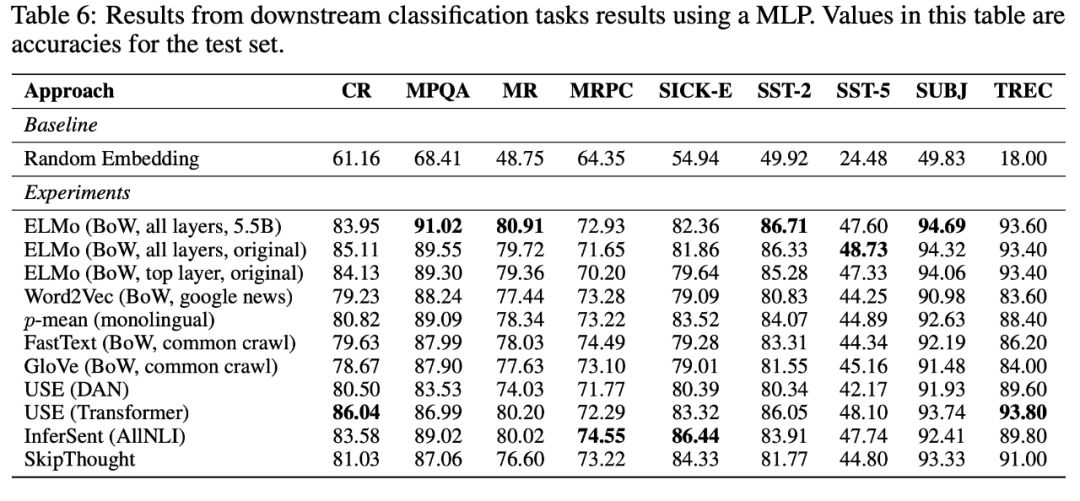
语义相关的任务
然后他们尝试了使用嵌入来处理语义关联和文本相似性的任务。这次使用(Transformer)模型显然是赢家。如果我们忽略了InferSent,它的嵌入比USE大8倍,USE远远领先于其他。
这为语义探索和相似问题类任务上提供了明确的选择。
顺便问一下,我们什么时候使用USE(DAN)和USE(Transformer)?USE(DAN)的性能是O(n),USE(Transformer)是O (n²),n是文本长度。所以,如果你正在处理长文本,你可能想要USE(DAN)。
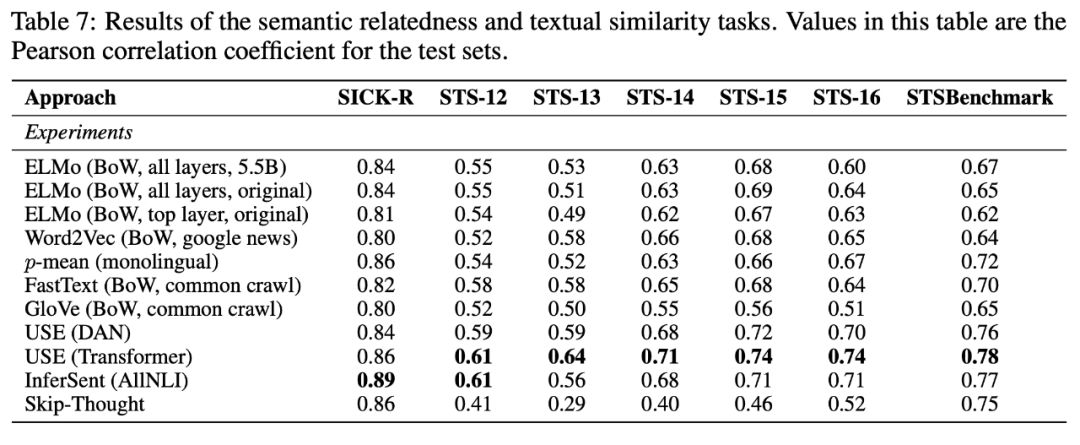
语法探索任务
接下来,他们展示了由一些深奥任务组成的语法探索任务的结果。在这种情况下,ELMo似乎统治了世界!
BShift (bi-gram shift)任务 — 目标是识别句子中的两个连续的tokens是否被倒转了,比如“This is my Eve Christmas”
ELMo和非ELMo模型之间的差异非常大。
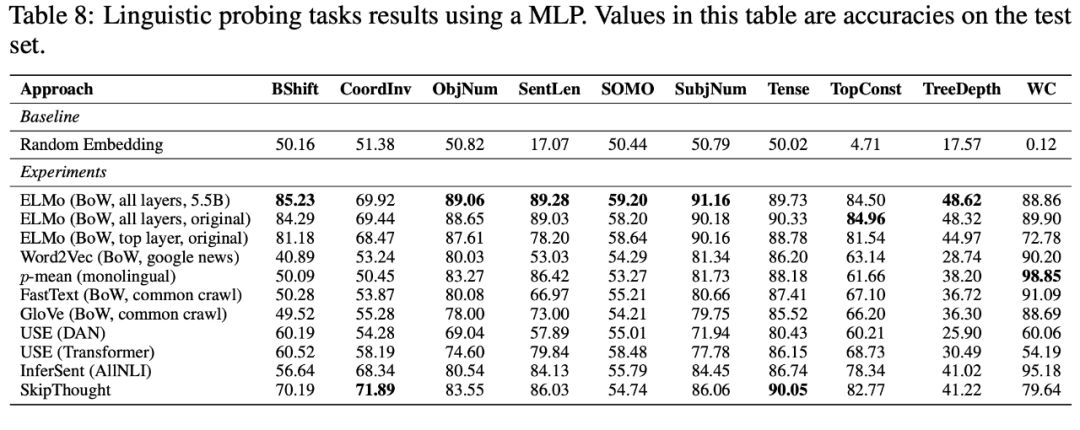
信息检索任务
在图像标题检索任务中,每个图像和语言特征都要进行联合评估,其目标是对给定标题的图像集合进行排序(图像检索任务 — text2image)或对给定图像的标题进行排序(标题检索 — image2text)。InferSent是一个明显的赢家。第二名是ELMo。
哪里都有ELMo 😀
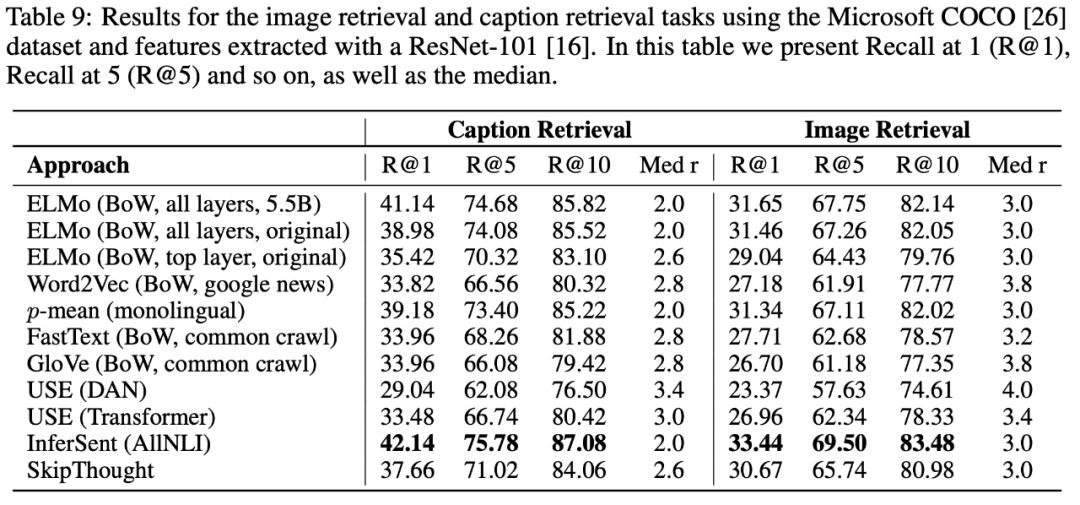
通用句子编码
正如我们所看到的,USE是一个很好的生产级模型,我们来讨论一下。我不会谈论ELMo,因为已经有很多关于它的文章了。
有两种类型可供使用
-
Transformer
-
DAN(Deep Averaging Network)
编码器采用小写的PTB tokens字符串作为输入,输出512维向量作为句子嵌入。这两种编码模型都被设计成尽可能通用的。这是通过使用多任务学习来实现的,其中一个编码模型用于满足多个下游任务。
USE(Transformer)
这使用了transformer架构,它为每个token创建上下文感知的表示。语句嵌入是通过添加所有tokens的元素创建的。
USE(DAN)
这是一个有争议的建模方法,因为它不考虑单词的顺序。首先将GloVe嵌入的词在一起做平均,然后通过前馈深度神经网络产生句子嵌入。
该模型利用深度网络来放大词嵌入中的细微差别,这些差别可能来自一个词,比如good/bad。大多数时候它表现得很好,但是实验表明它在双重否定下失败了,比如“not bad”,因为这个模型把“not”和消极情绪联系在一起。看一下最后一个例子。
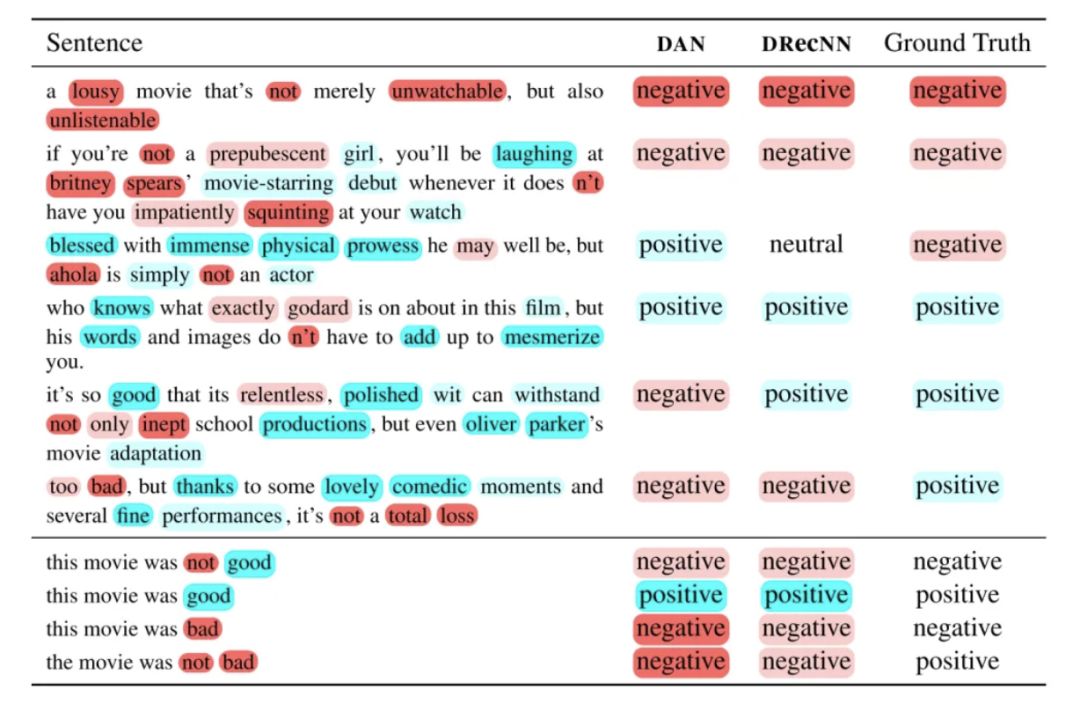
这使得(DAN)成为一个将新闻文章分类的好模型,但是在情感分类问题中,像“not”这样的词可能会改变意思。
你可以从上下文中学到些什么?
像DAN这样的模型和transformer一样好,这一事实提出了一个问题 —— 我们的模型是否关心词的顺序,并且顺序是否像我们认为的那样重要?
让我们讨论一下我们从上下文中学到了什么?在本文中,作者试图了解这些上下文表示在哪些方面优于传统的词嵌入。
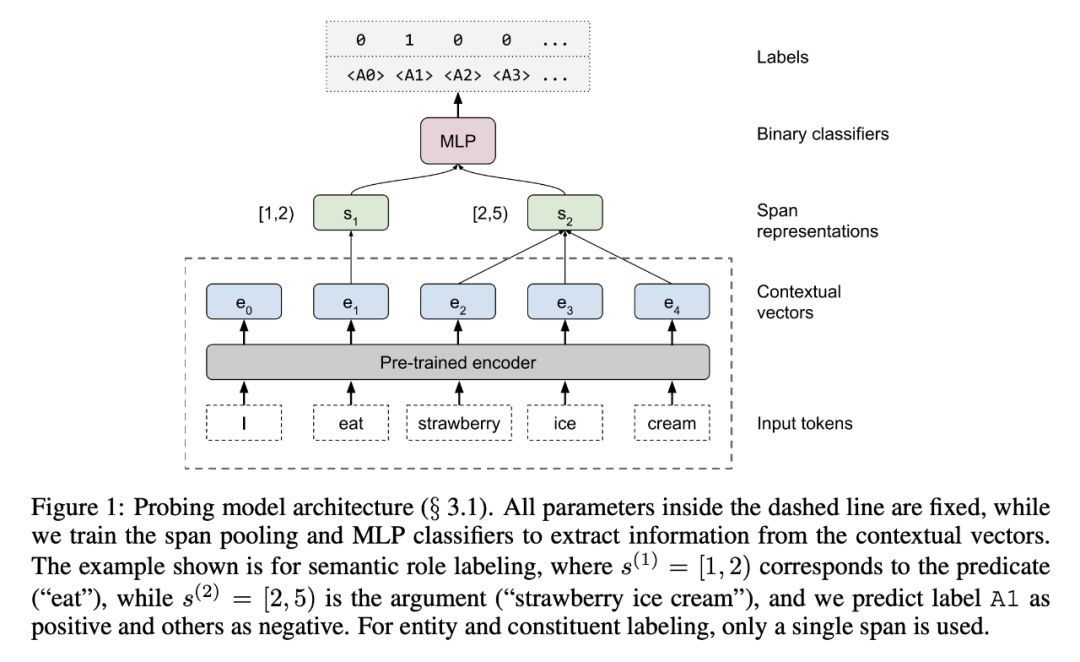
用来验证的任务
作者介绍了一套“边缘探测”任务,用于探测上下文化的词嵌入的子句结构。这些任务来源于核心的NLP任务,包含了一系列的语法和语义现象。
他们使用这些任务来探索上下文嵌入如何改进他们的词(上下文无关)基线。他们主要关注上下文化的单词嵌入的四个最新方法 —CoVe, ELMo, OpenAI GPT, 和BERT。

ELMo、CoVe和GPT都遵循类似的趋势(表2),显示出在被认为主要是语法上的任务(如依赖性和成分标记)上获得的收益最大,而在被认为需要更多语义推理的任务(如SPR和Winograd)上获得的收益较小。
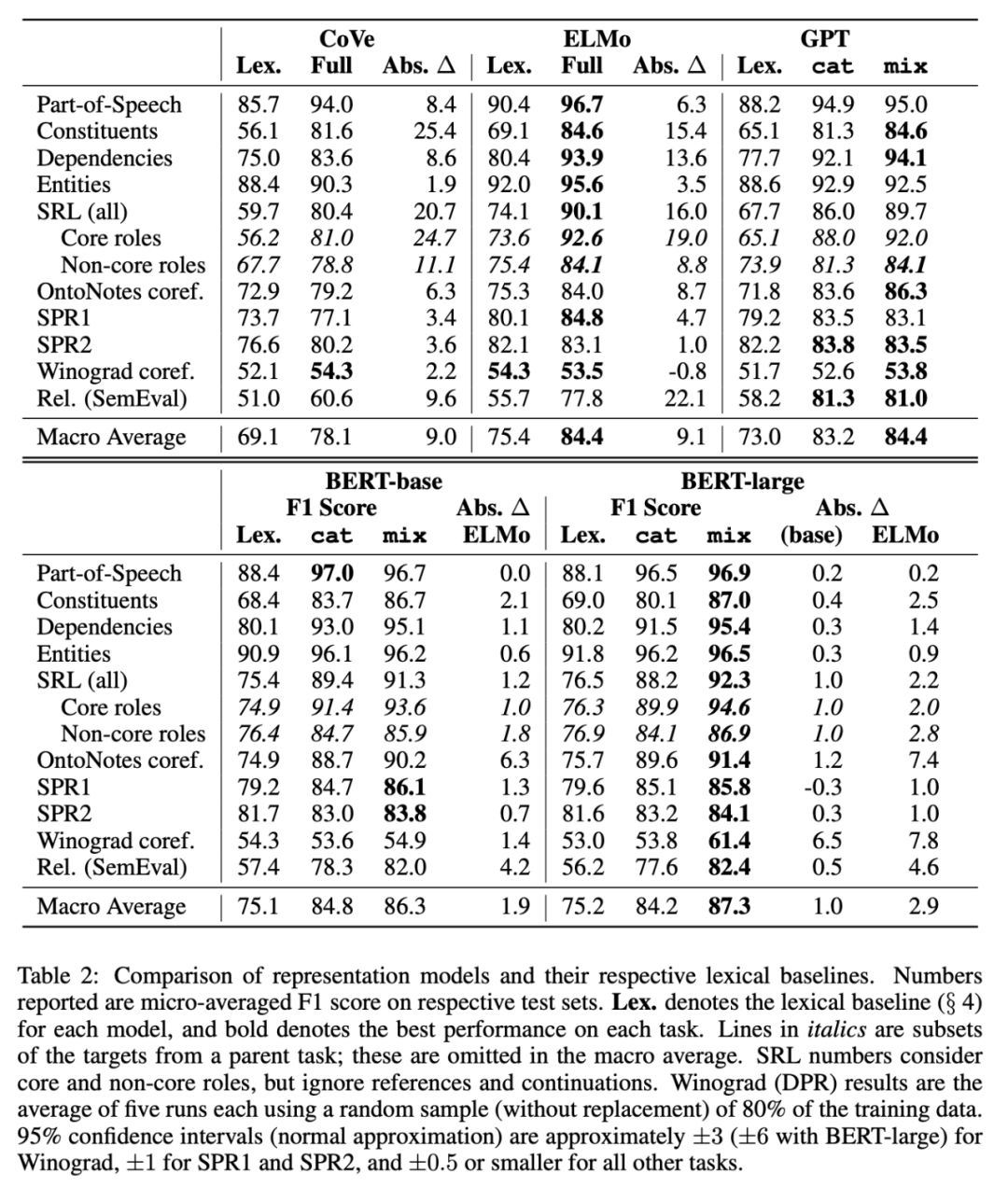
句子中有多少信息是通过长距离传送的(几个tokens或更多)?
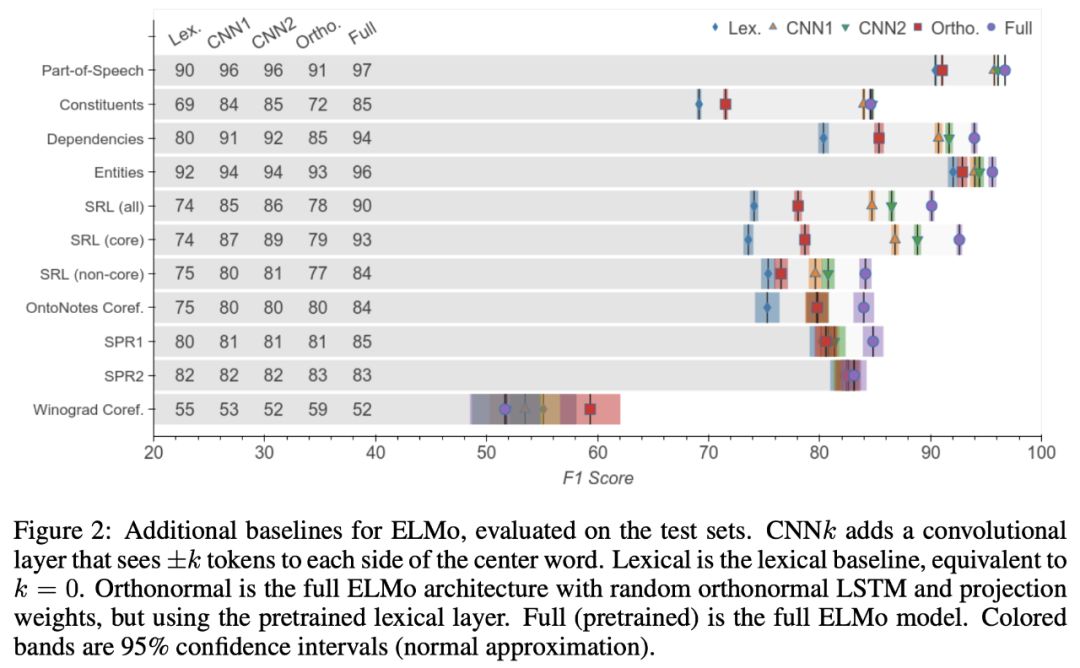
为了估计长距离传输的信息(几个tokens或多个tokens),作者使用卷积层扩展了词法基线,允许探测分类器使用本地上下文。如图2所示,添加宽度为3(±1 token)的CNN,可以缩小词法基线与完整ELMo之间的差距72%(平均任务),如果我们使用宽度为5(±2 tokens)的CNN,则可以扩展到79%。
这表明,虽然ELMo没有有效地对这些现象进行编码,但它所带来的改进主要是由于长距离的信息。
CNN模型和标准正交编码器在邻近跨距时表现最佳,但随着tokens距离的增加,其性能迅速下降。(该模型只能访问给定范围内的嵌入,如谓词 — 对,并且必须预测属性,如语义角色,这通常需要整个句子的上下文。)
完整的ELMo模型表现得更好,在d=0和d=8之间,性能只下降了7个F1点,这表明预训练的编码器确实对USE的远程依赖进行了编码。
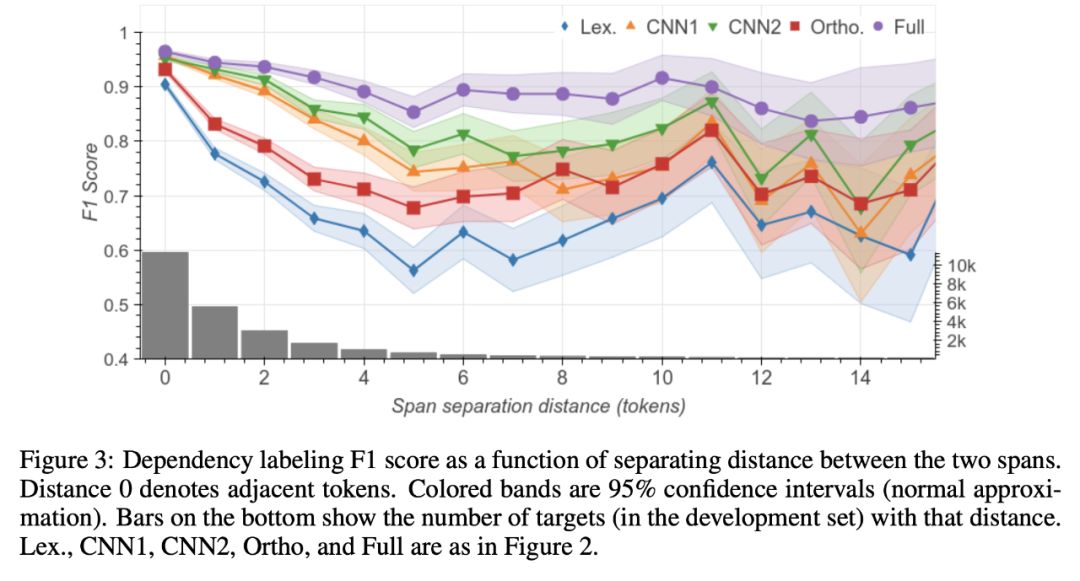
论文中的发现
首先,总的来说,与语义任务(例如,共同参考)相比,上下文化嵌入在语法任务(例如,成分标注)方面比非上下文化嵌入在语义任务(例如,指代关系)方面有很大的改进,这表明这些嵌入在语法编码方面比高级语义做得更好。
其次,ELMo的性能不能完全由一个访问本地上下文的模型来解释,这表明上下文化的表示确实编码了远距离的语言信息,这有助于消除长范围依赖关系和高级语法结构的歧义。
这是一个简单却难以克服的句子嵌入基线
既然我们知道上下文模型是可以打败的,那么有什么简单的技巧可以打败它呢?
如果DAN证明平均词嵌入就可以得到很好的结果,如果我们可以找到一个智能的权重方案呢!本文介绍了如何将句子表示为加权平均,然后使用PCA/SVD进一步细化嵌入。
他们是这样写的:
“我们修改了这个理论模型,出于经验观察,大多数词嵌入方法,因为他们使用向量内积试图捕捉词的同现概率,最后给频繁的单词大的向量,并给了不必要的单词对大的内积,这样只是为了拟合偶尔出现在文档中的断章取义的话。
这些异常导致词向量的平均值在沿着语义上无意义的方向上有巨大的分量。我们对(Arora et al., 2016)的生成模型进行了修改,使用“平滑”术语,然后通过最大似然计算得到SIF的权重调整。
其中,以a为参数,**w = a/(a + p(w))**的权重,p(w)(估计值)的词频,他们称之为 — 平滑逆频率(SIF)。
利用这些权重,他们计算加权平均值,然后去掉平均向量对第一个奇异向量的投影(“共同分量去除”)。
论文中有趣的一句话 — “简单的RNNs可以被看作是解析树被简单的线性链所取代的特殊情况。”
SIF权值调整
这是计算SIF嵌入的方法:
-
计算语料库中所有单词的频率。 -
然后,给定一个超参数 a,通常设置为1e-3,和一组预先训练的词嵌入,在每个文本/句子上计算加权平均值。 -
最后, 使用SVD 从这些平均值中删除第一个分量,并获得新的语句嵌入。 删除第一个分量就像删除了最常见的信息,因为它捕获了关于平均嵌入的最大信息。
我的理解是,删除第一个分量就像从压缩向量中删除“均值”!我们剩下的是有关这个词的独特特征而不是完整的信息🤔
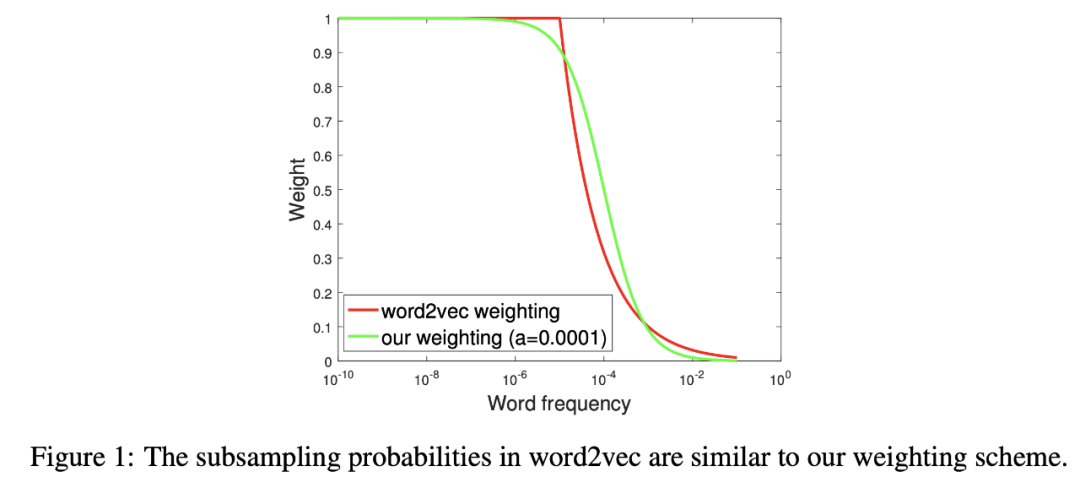
结果是惊人的,他们击败了复杂的方法,如DAN和LSTM。🤯
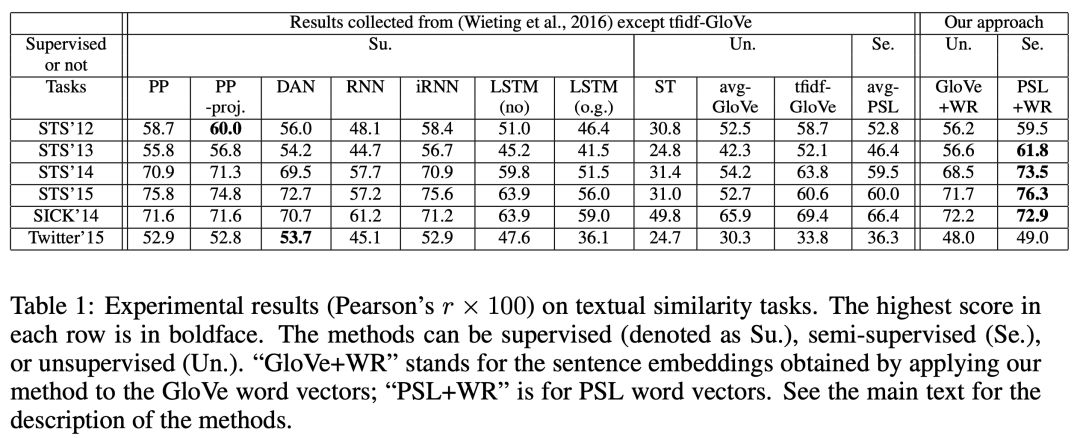
下面是相同的结果。
他们的贡献
对于GloVe向量,单独使用平滑逆频率加权比未加权平均提高约5%,单独使用共分量去除提高10%,同时使用两者提高13%。
Sentence-BERT: 使用Siamese BERT-Networks的句子嵌入
最先进的是什么? 😝
在这篇文章中,作者报告说我们正在做语义搜索,在10,000个句子中找到最相似的对需要BERT进行大约5000万个推理计算(约65小时)。BERT的构造使得它既不适合语义相似度搜索,也不适合非监督任务,比如聚类。
在一个包含n = 10,000个句子的集合中,找到与BERT n·(n−1)/2 = 49,995,000个推理计算相似度最高的一对句子。
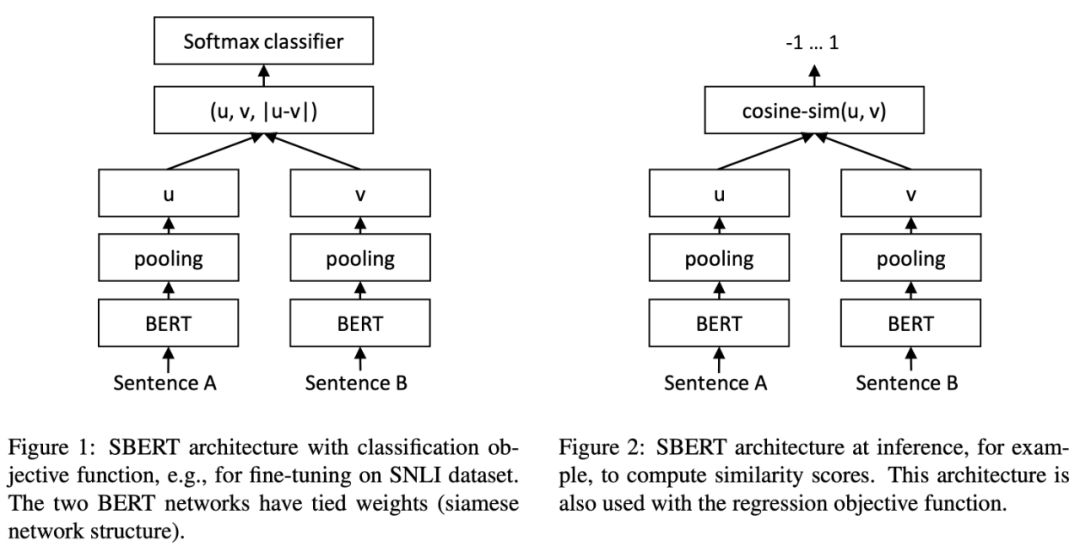
Sentence-BERT (SBERT)是预训练的BERT网络的一个修改,它使用siamese和triplet网络结构派生出语义上有意义的句子嵌入,可以使用余弦相似度进行比较。
这减少了寻找最相似的配对的努力,从使用BERT / RoBERTa的65小时减少到使用SBERT的5秒,同时保持了BERT的准确性。
This reduces the effort for finding the most similar pair from 65 hours with BERT / RoBERTa to about 5 seconds with SBERT, while maintaining the accuracy from BERT.
主要思想
-
与其在模型中运行所有的A-B对并得到一个分数,不如训练一个模型来对相似的句子生成相似的嵌入。 使用这种方法,一旦为适当的任务训练了一个模型,我们就可以为每个句子创建一次嵌入。 -
每次我们得到一个查询,我们使用余弦距离计算查询与所有其他预计算的句子嵌入的相似度,这是线性时间,使用比如FAISS之类的库可以计算的很快。
为了做出好的编码器,他们训练了一个有固定权重的双编码器 — 一个siamese network!
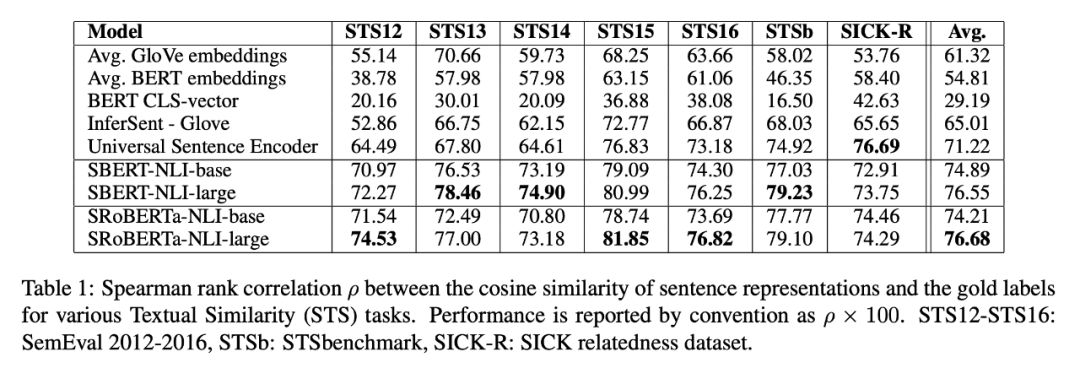
结果达到了一种新的state of the art,除了SICK-R之外,在某些数据集上获得了相当大的收益。
词向量集合的关系
这篇论文发表于2019年10月。本文研究了统计相关系数在词向量集上的应用,作为计算语义文本相似度的一种方法。令人惊讶的是,USE显示比BERT更高的统计相关性。
此外,与皮尔逊相关进行比较,向量的最大和最小池化要比均值池化效果好。
这是否意味着USE更适合语义搜索? 🤔
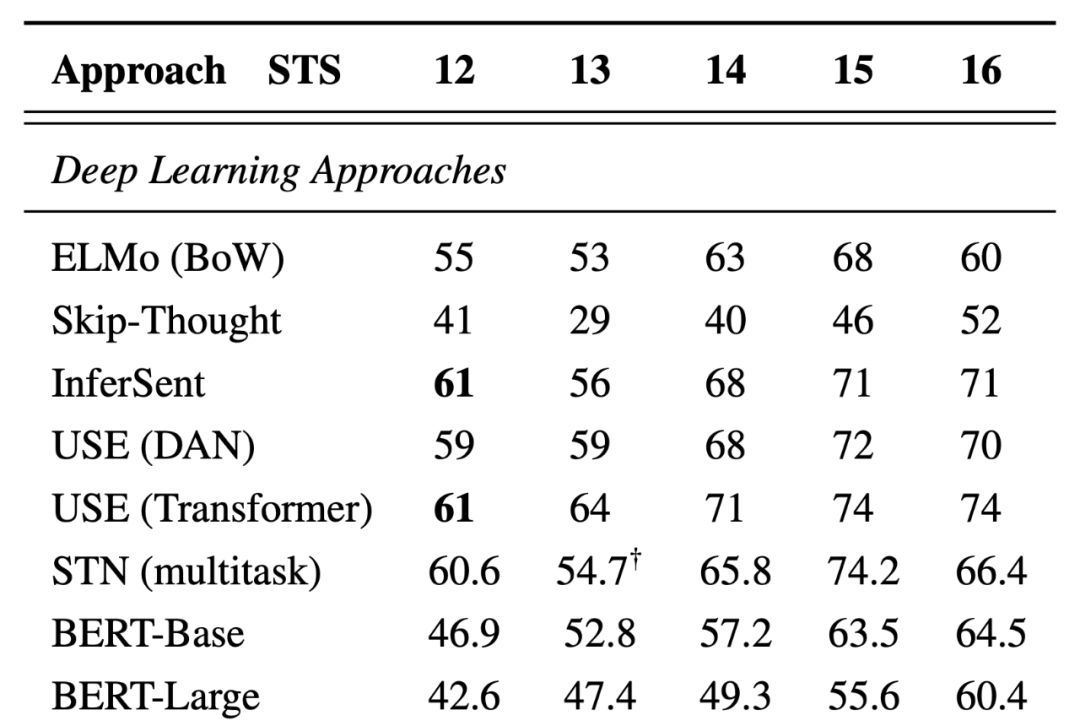
BERT, ELMo, USE and InferSent Sentence Encoders: 研究推荐论文的万灵药?
到目前为止,我们一直在比较传统机器学习和深度学习。但如果我们能同时利用这两者呢!👻
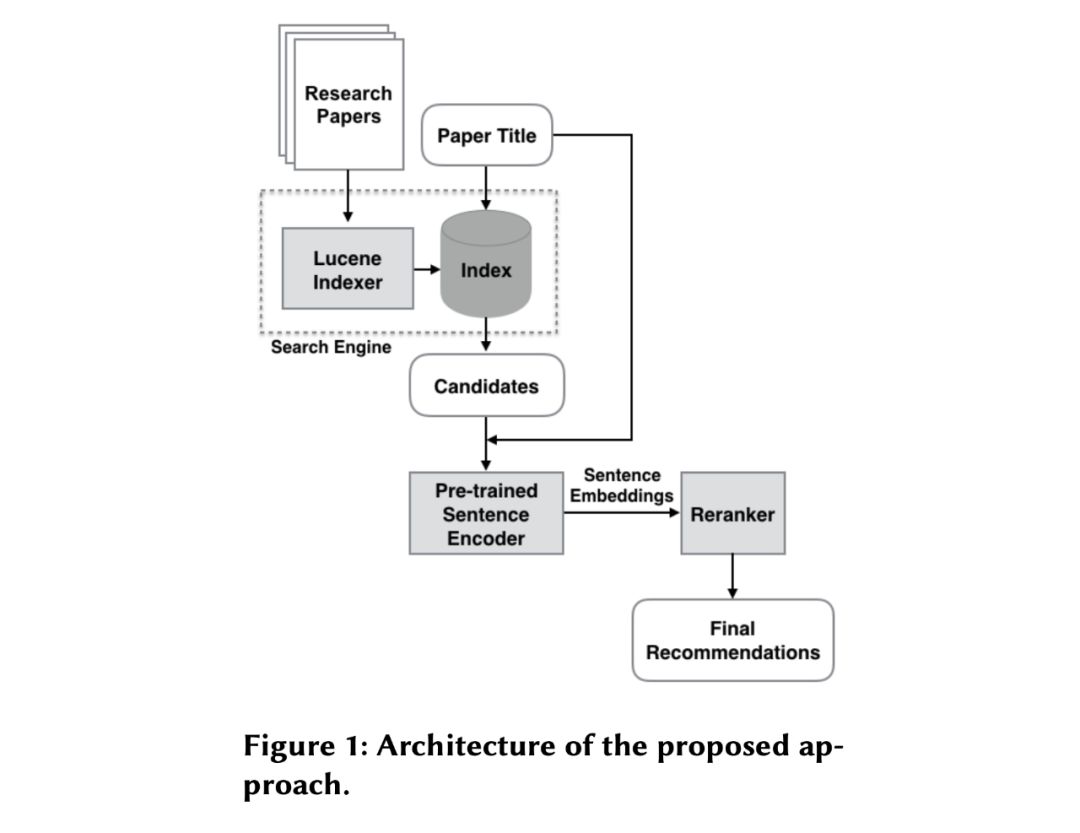
在大型语料库中使用语句嵌入在生产推荐系统中似乎不太可行,因为需要在几秒钟或更少的时间内返回推荐。
作者报告说BM25查询花费大约5毫秒来检索多达100个结果。通过不同的模型计算嵌入和重排20、50和100个标题所花费的额外时间如下所示。USE (DAN)是最快的,重新排序20或50个标题需要0.02秒,重新排序100个标题需要0.03秒。
你可以看到USE(DAN)超级快!
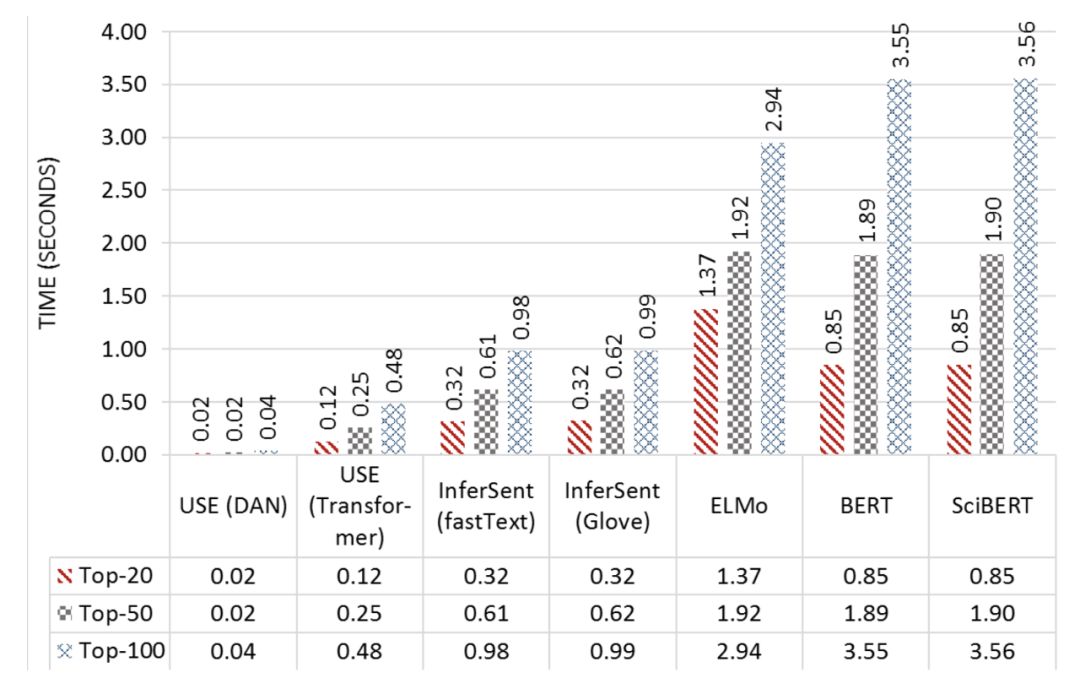
最后,BERT和SciBERT使用BERT-as-server是重排序100个标题最慢的,大约需要4.0秒。这意味着它们不能用于实时重排序推荐,除非提供更高的计算资源(如GPU或TPU)。
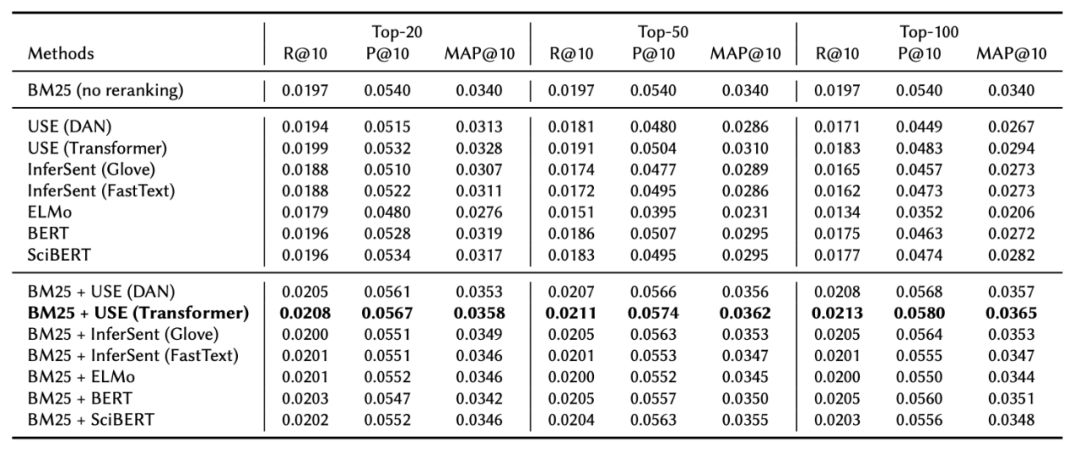
最佳的方法
-
使用Apache Lucene的BM25检索前得到20、50或100个推荐候选项的列表。 -
获取top-k的句子嵌入,使用查询嵌入计算余弦相似度评分。 -
将标准化后的BM25的初始得分与句子嵌入的语义相似度得分进行线性组合,将得分相加(将统一的权重设置为0.5),生成最终的排序推荐。
总结
我写这篇文章的主要原因是为了阐明如何为我们的问题选择一个现有的模型。我们有各种各样的模型、方法和任务。毫无疑问地选择一个模型会导致过度工程化,而像USE(DAN)这样的简单模型可以解决这个问题。有时一个CNN可以解决ELMo的问题。

英文原文:https://medium.com/modern-nlp/on-variety-of-encoding-text-8b7623969d1e






