帝国的黄昏(3):SQL是世界上最牛逼的语言



来源/作者:飞总聊IT
数据猿官网 | www.datayuan.cn

今日头条丨一点资讯丨腾讯丨搜狐丨网易丨凤凰丨阿里UC大鱼丨新浪微博丨新浪看点丨百度百家丨博客中国丨趣头条丨腾讯云·云+社区

1
关系代数诞生于1969年,甲骨文诞生于1978年。这期间的历史很漫长,所以本系列文章等甲骨文上场起码还有好几个章节。
由于历史都比较久远,在我出生前,查史料非常的辛苦,这个系列写的很慢。
我这个标题暴露了我具体想要讲啥。而且我相信有无数多人不同意我的观点。但是没办法, 我是做数据库系统的,我对SQL的崇拜有如滔滔江水,绵绵不绝。再加上我是写文章的,自然是我想用什么标题就用什么标题了。

IBM对祖师爷Edgar Frank Codd的关系模型的态度很暧昧:不拒绝,不反对,但是也不给钱做系统。现在回头去看究其原因是怕影响了自己已经有的IMS这个层次模型数据库的钱。
但是,Codd也是一个非常顽强的人,他就去找IBM的大客户,给大客户们洗脑说关系数据库才是未来,层次是过去。大客户们被洗的都信了关系代数神教以后就回头找IBM,说赶紧给爸爸们做一个关系数据库出来。
IBM不怕Codd,但是经不住客户金主爸爸们反复要求,就在自己的Future System里加了一个新的研究对象:System R。Future System项目是IBM1970年前后开展的一个大型研究项目,为的是开发出革命性的新软件和硬件。当时如日中天的IBM可谓浩浩荡荡的撒钱。
2
System R是数据库历史上有标志性意义的一个系统。我们以后还要专门讲到它。System R团队成立于1973年。里面包括了后来很多在数据库圈里声名显赫的人,包括后来的图灵奖获得者Jim Gray。当然,也不知道IBM怎么想的,IBM把System R团队和Codd给隔离开来了。
1974年的时候,Donald Chamberlin和Raymond Boyce发表了一篇论文:SEQUEL: A structured English query language。为了给大家看看这篇论文怎么样,我特意去ACM的数据库里搜了一下,截图如下:
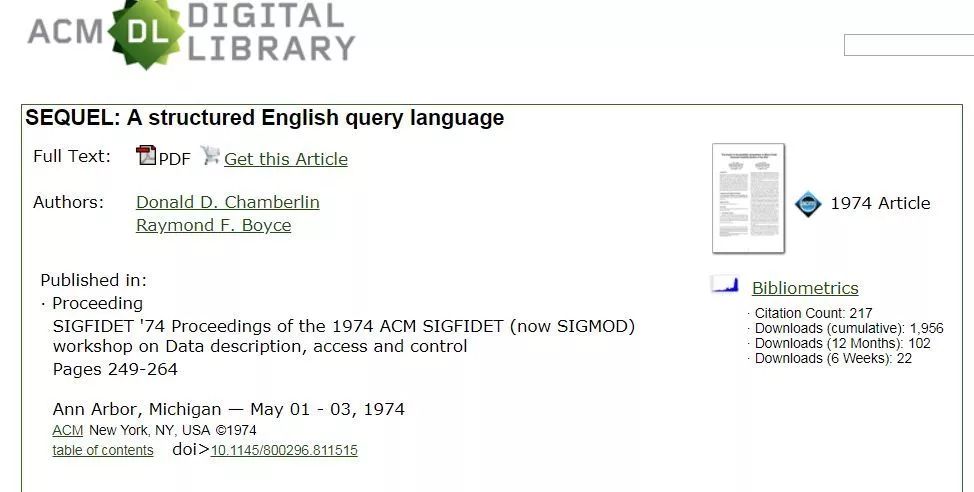
那为什么SEQUEL变成为SQL了呢?是因为IBM发现原来SEQUEL居然是英国一家公司的注册商标,于是就只好改了。再后来,IBM为了和Ingres竞争(以后会讲),抢先把SQL提交给标准委员会。于是SQL的全称也偷偷的换成了Standard Query Language---一个更为霸气的名字。
我想这个世界上大部分计算机程序员,DBA,数据科学家,数据工程师等等,多多少少都会写点SQL查询:SELECT ... FROM ... WHERE...。SQL诞生于1974年,又被如此广泛应用,所以我还是觉得它是全世界最牛逼的语言。
3
Codd在提出关系模型的时候,论文里有一个查询语言叫Alpha。但是因为和System R的人员隔离,对方又发明了SQL。到底是Alpha好还是SQL好呢?
历史上另外一个图灵奖获得者Michael Stonebraker在他的系统Ingres里使用了类似Alpha的查询语言,所以有人觉得IBM再发吗SQL是傻逼行为。
才写了三篇文章,已经跳出来三个未来的图灵奖获得者了。数据库领域一共有四个图灵奖获得者,他们先后都会反复出现在这个系列里。
从我个人的看法来说,SQL这个语言入门简单,但是如果想要写复杂的查询,那就是天堑一样的鸿沟。所以这样的语言是不是设计合理是见仁见智的。
但是SQL有一个问题,它和关系代数是不一致的。它的SELECT是关系代数里面的的PROJECT。关系代数里面的SELECT是它的WHERE 和HAVING。如此的不一致性,对初学者是困惑。
SQL还继承了关系代数最大的一个坑:NULL。简单来说关系代数是三元关系:TRUE, FALSE, NULL。而不是常见的两元关系。这里引入NULL之后带来一系列复杂的规则变化,是SQL最大的坑之一。
作为一个做数据库的人,如果没有因为修NULL相关的bug而苦思不得其解的话,作为一个用数据库的人,如果不清楚NULL有多坑人的话,都是不合格的。
Raymond Boyce发表完论文的当年就因为动脉瘤去世了。Donald Chamberlin则独享了SQL的荣光。他因为SQL获奖无数,成为了ACM fellow, IEEE fellow,IBM fellow,美国工程院院士等。我在2008年去IBM实习的时候见到了Donald,当时从照片看到真人的时候,真有跪了的冲动。这是活宝啊。
END
找大数据,搜数据猿