圣经书||《强化学习导论(2nd)》原书、代码、习题答案、课程视频大全
深度强化学习实验室报道
作者:DeepRL
下载地址见文章末尾
强化学习是现在人工智能领域里面最活跃的研究领域之一,它是一种用于学习的计算方法,其中会有一个代理在与复杂的不确定环境交互时试图最大化其所收到的奖励。现在,如果你是一个强化学习的初学者,由 Richard Sutton 和 Andrew Barto 合著的《Reinforcement Learning : An Introduction》可能就是你的最佳选择。这本书提供了关于强化学习的简单明了的关键思想和算法的解释。他们讨论了该领域的知识基础的历史延伸到了最新的发展的应用。

一、|| 关于圣经书:
本书全文共分三部分,17章内容
第一部分:列表(Tabular)解决法,第一章描述了强化学习问题具体案例的解决方案,第二章描述了贯穿全书的一般问题制定——有限马尔科夫决策过程,其主要思想包括贝尔曼方程(Bellman equation)和价值函数,第三、四、五章介绍了解决有限马尔科夫决策问题的三类基本方法:动态编程,蒙特卡洛方法、时序差分学习。三者各有其优缺点,第六、七章介绍了上述三类方法如何结合在一起进而达到最佳效果。第六章中介绍了可使用适合度轨迹(eligibility traces)把蒙特卡洛方法和时序差分学习的优势整合起来。第七章中表明时序差分学习可与模型学习和规划方法(比如动态编程)结合起来,获得一个解决列表强化学习问题的完整而统一的方案。
第二部分:近似求解法,从某种程度上讲只需要将强化学习方法和已有的泛化方法结合起来。泛化方法通常称为函数逼近,从理论上看,在这些领域中研究过的任何方法都可以用作强化学习算法中的函数逼近器,虽然实际上有些方法比起其它更加适用于强化学习。在强化学习中使用函数逼近涉及一些在传统的监督学习中不常出现的新问题,比如非稳定性(nonstationarity)、引导(bootstrapping)和目标延迟(delayed targets)。这部分的五章中先后介绍这些以及其它问题。首先集中讨论在线(on-policy)训练,而在第九章中的预测案例其策略是给定的,只有其价值函数是近似的,在第十章中的控制案例中最优策略的一个近似已经找到。第十一章讨论函数逼近的离线(off-policy)学习的困难。第十二章将介绍和分析适合度轨迹(eligibility traces)的算法机制,它能在多个案例中显著优化多步强化学习方法的计算特性。这一部分的最后一章将探索一种不同的控制、策略梯度的方法,它能直接逼近最优策略且完全不需要设定近似值函数(虽然如果使用了一个逼近价值函数,效率会高得多)。
第三部分:深层次研究,这部分把眼光放到第一、二部分中介绍标准的强化学习思想之外,简单地概述它们和心理学以及神经科学的关系,讨论一个强化学习应用的采样过程,和一些未来的强化学习研究的活跃前沿。
二、|| 关于作者:
1. Richard S. Sutton:(强化学习教父)
Richard S. Sutton 教授被认为是现代计算的强化学习创立者之一。就职于他为该领域做出了许多重大贡献,包括:时间差分学习、策略梯度方法、Dyna 架构。Sutton 博士进入的第一个领域甚至与计算机科学无关。他先是获得了心理学学士学位,然后才转向计算机科学。
目前就职于加拿大阿尔伯塔大学计算机科学系与Google-DeepMind,他的弟子David sliver正是DeepMind创造AlphaGo的带头人。
个人主页:http://www.incompleteideas.net/
Retired Co-Director Autonomous Learning Laboratory
College of Information and Computer Sciences
272 Computer Science Building
University of Massachusetts Amherst
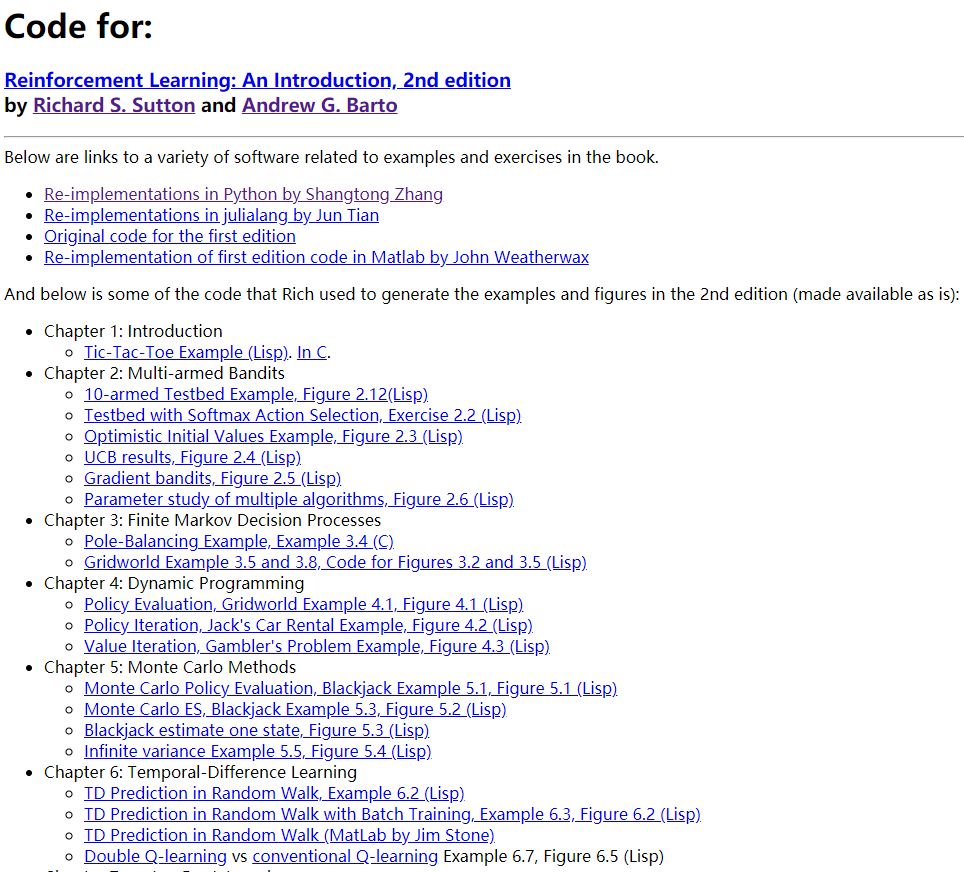

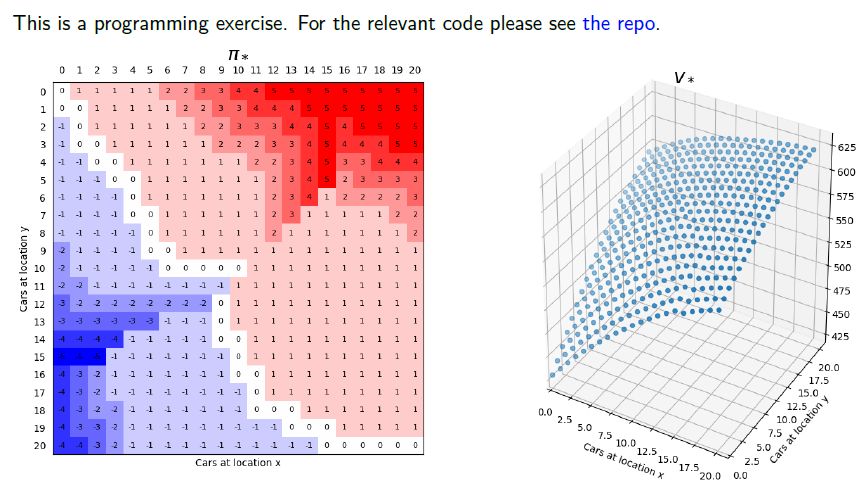
书籍主页:http://incompleteideas.net/book/the-book-2nd.html
完
第48篇:全网首发最全深度强化学习资料(永更)
第47篇:30+个必知的《人工智能》会议清单
第46篇:2019年-57篇深度强化学习文章汇总
第44篇:深度强化学习入门到精通资料综述
第43篇:顶会征稿 || ICAPS2020: DeepRL
第42篇:实习生招聘 || 华为诺亚方舟实验室
第41篇:滴滴实习生|| 深度强化学习方向
第39篇:Call For Papers# IJCNN2020-DeepRL
第37篇:DQN系列(1): Double Q-learning
第36篇:从Paper到Coding, DRL挑战34类游戏
第35篇:复现"深度强化学习"论文的经验之谈
第34篇:α-Rank算法之DeepMind及Huawei改进
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第13期论文:2020-1-21(共7篇)
第12期论文:2020-1-10(Pieter Abbeel一篇,共6篇)
第11期论文:2019-12-19(3篇,一篇OpennAI)
第10期论文:2019-12-13(8篇)
第9期论文:2019-12-3(3篇)
第8期论文:2019-11-18(5篇)
第7期论文:2019-11-15(6篇)
第6期论文:2019-11-08(2篇)
第5期论文:2019-11-07(5篇,一篇DeepMind发表)
第4期论文:2019-11-05(4篇)
第3期论文:2019-11-04(6篇)
第2期论文:2019-11-03(3篇)
第1期论文:2019-11-02(5篇)



