资源 | 跟着Sutton经典教材学强化学习中的蒙特卡罗方法(代码实例)

大数据文摘出品
作者:Ray Zhang
编译:halcyon、龙牧雪
用动态规划去解决强化学习的相关问题基本够了,但还是有很多限制。比如,你知道现实世界问题的状态转移概率吗?你能从任意状态随机开始吗?你的MDP是有限的吗?
好消息是,蒙特卡罗方法能解决以上问题!蒙特卡罗是一种估计复杂的概率分布的经典方法。本文部分内容取自Sutton的经典教材《强化学习》,并提供了额外的解释和例子。
初探蒙特卡罗
蒙特卡罗模拟以摩纳哥的著名赌场命名,因为机会和随机结果是建模技术的核心,它们与轮盘赌,骰子和老虎机等游戏非常相似。
相比于动态规划,蒙特卡罗方法以一种全新的方式看待问题,它提出了这个问题:我需要从环境中拿走多少样本去鉴别好的策略和坏的策略?
这一次,我们将再引入回报的概念,它是长期的预期收益:
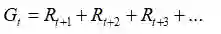
有时,如果环节不收敛,那么我们使用折扣因子:
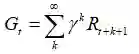
我们将这些回报Gt和可能的At联系起来试图推导出:
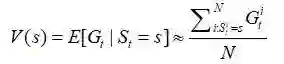
根据大数定律,当N逼近∞时,我们能够得到准确的期望。我们记i次模拟下标为i。
现在,如果这是一个马尔科夫决策过程(MDP)(99%的强化学习问题都是),那么我们知道它展现出了强马尔科夫性质,也即:
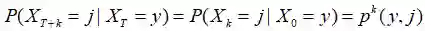
有了这些,我们可以很容易推导得到这样一个事实,即期望中的是完全无关的,从现在开始,我们将使Gs指示从某个状态开始的回报(移动那个状态到t=0)。
解决值函数的一种经典方式是对第一次s的发生的回报进行采样,也叫首次访问蒙特卡罗预测。那么一个找到最优V的一个有效的算法如下:
pi=init_pi()
returns=defaultdict(list)
for i in range(NUM_ITER):
episode=generate_episode(pi)#(1)
G=np.zeros(|S|)
prev_reward=0
for (state,reward) in reversed(episode):
reward+=GAMMA*prev_reward
#breaking up replaces s eventually,
#so we get first-visit reward.
G[s]=reward
prev_reward=reward
for state in STATES:
returns[state].append(state)
V={state:np.mean(ret) for state, ret in returns.items()}
另一种方法是每次访问蒙特卡罗预测,也就是你在每个环节中每一次发生s的回报都进行采样。在两种情况下,估计均成平方收敛于期望。
在蒙特卡罗方法的背景下,策略迭代的核心问题是,正如我们之前说过的,如何确保探索和开采?
一种补救大状态空间探索的方法是,明确我们从一个特定的状态开始并采取特定的行动,对所有可能性采用轮循方式对它们的回报采样。这假定我们可以从任何状态出发,在每一环节的开始采取所有可能的行动,这在很多情况下不是一个合理的假设。然而对于像21点纸牌游戏这样的问题,这是完全合理的,这意味着我们可以很容易地解决我们的问题。
在以下代码中,我们只需要对我们之前的代码(1)做一个快速的补丁:
# Before(Start at some arbitrary s_0,a_0)
episode=generate_episode(pi)
# After(Start at some specifics s,a)
episode=generate_episode(pi,s,a)
# loop through s, a at every iteration.
在线策略ε-贪婪策略
如果我们不能假设我们可以从任何状态开始并采取任意行动那怎么办呢?好吧,那么,只要我们不要太贪婪或者探索所有的状态无穷次,我们仍然可以保证收敛,对吗?
以上是在线策略方法的主要属性之一,在线策略方法试图去改善当前运行试验的策略,与此同时,离线策略方法试图改善一种不同于正在运行试验的策略的策略。
说到这里,我们要规则化“不要太贪婪”。一种简答的方法是使用我们之前学过的k臂老虎机-ε-贪婪方法。回顾一下,我们以ε的概率从一个给定状态下所有行动的均匀分布中挑选,以1-ε的概率我们选argmaxtq(s,a)行动。
现在我们问:对于蒙特卡罗方法,这是否收敛到最优π*?答案是它会收敛,但不是收敛到那个策略。
我们从q和一个ε-贪婪策略π(s)开始:
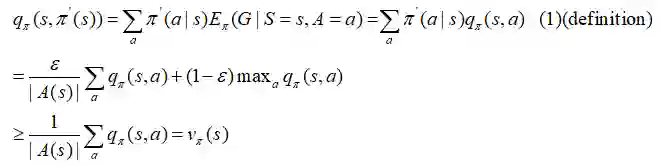
再一次,我们得到这个结论ε-贪婪策略,跟其他贪婪策略一样,对于Vπ执行单调的改进。如果我们回退到所有的时间步,那么我们得到:
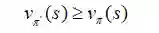
这就是我们想要的收敛性。
然而,我们需要去发现这个策略实际上收敛到什么。显然,即使最优策略是确定性的,我们的策略也被迫是随机的,不能保证收敛到π*。然而,我们可以修订我们的问题:
假定不是我们的策略保持以概率ε的随机性一致选择行动,而是环境不管我们的策略的规定随机选择一个行动,那么,我们能够确保一个最优解。证明的大纲在(1)中显示,如果等式成立,那么我们π=π,因此我们有Vπ=Vπ于环境,这个等式在随机性下是最优的。
离线策略:重要性采样
让我们介绍一些新的术语!
π是我们的目标策略。我们正努力优化它的预期回报。
b是我们的行为策略。我们使b产π以后会用到的数据。
π(a|s)>0⇒b(a|s)>0 ∀a∈A。这是收敛的概念。
离线策略方法通常有2个或者多个智能体,其中一个智能体产生另一个智能体需要的数据,我们分别叫它们行为策略和目标策略。离线策略方法比在线策略方法更异想天开,就像神经网络之于线性模型更异想天开。离线策略方法往往更强大,其代价是产生更高的方差模型和较慢的收敛性。
现在,让我们讨论重要性采样。
重要性采样回答了这个问题:“给定Eπ[G],Eπ[G]是什么?”换句话说,你怎样使用从b的采样中获得的信息去决定π的期望结果。
一种你能想到的直观方法就是:“如果b选择a很多,π选a很多,那么b的行为对于决π的行为是很重要的!”,相反:“如果b选择a很多,π不曾选择a,那么b在a上的行为π在a上的行为没有什么重要性”,很有道理,对吧?
所以这差不多就知道重要性采样的比率是什么概念了。给定一个轨迹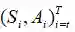
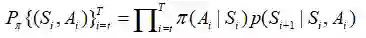
π和b之间的比率是:
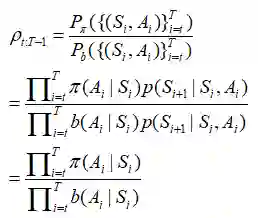
普通的重要性采样
现在,有很多方法可以利用
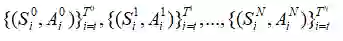
定义S的第一次到达时间为:
我们想要估计Vπ(s),那么我们可以使用经验均值去通过首次访问方法估计值函数:
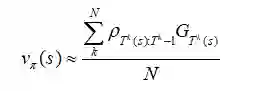
当然,这可以很容易地推广到每次访问方法,但是我想用最简单的形式来表达我的意思。这说明我们需要不同的方式来衡量每一环节的收益,因为对于π更容易发生的轨迹相比那些永远不会发生的需要赋予更多的权重。
这种重要性采样的方法是一种无偏估计量,但它存在极大的方差问题。假定第k个环节的重要性比率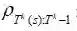
加权重要性采样
为了减小方差,一种简单直观的方法就是减少估计的大小,通过除以重要比率的大小的总和(有点像柔性最大激活函数):
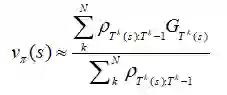
这叫做加权重要性采样,它是一种有偏估计(偏差渐进趋于0),但是减小了方差。在此之前,我们能够得到一个普通估计量的病态无界方差,但是这里的每个元素的最大权值都是1,通过此限制了方差有界。Sutton建议,在实践中,总是使用加权重要性采样比较好。
增值实现
与许多其它采样技术一样,我们可以逐步实现它。假设我们使用上一节的加权重要性采样方法,那么我们可以得到一些如下形式的采样算法:
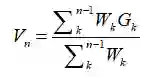
其中Wk可以是我们的权重。
我们想基于Nn来构造Nn+1,这是可行的。记Cn为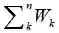
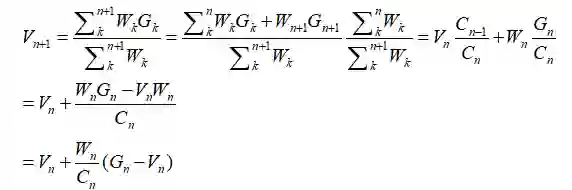
Cn的更新规则非常明显: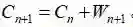
现在Vn是我们的值函数,但是一个非常相似的类比也可以应用到我们的行为Qn。
当我们更新值函数的时候,我们也能更新我们的策略π,我们能够用虽旧但是很好用argmaxtq(s,a)来更新π。
折扣意识重要性采样
到目前为止,我们已经计算了回报,并采样了回报得到了我们的估计。然而我们忽视了G的内部结构。它真的只是折扣奖励的求和,我们未能将它纳入到比率中ρ。折扣意识重要性采样将γ建模为终止的概率。环节的概率在一些时间步t终止,因此必须是一个几何分布geo(γ):
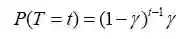
全部回报可以认为是对随机变量Rt求期望:
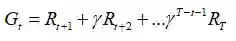
可以构造一个任意的裂项求和如下:
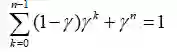
以此类推,我们可以看到,令k从x处开始,那么我们有γx
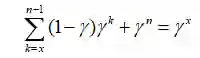
将上式代入G得到:
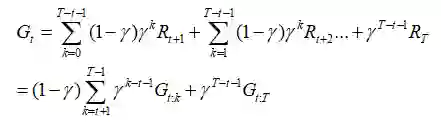
这将导致Rt项中的等效系数1,γ,γ2等。这就意味着,我们现在能够分解Gt,并且在重要性采样比率中使用折扣。
现在,回忆我们之前得到的:
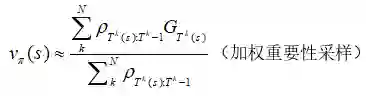
如果我们扩展G,我们会有:
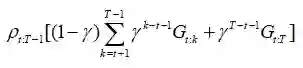
注意我们是怎样在所有的回报中使用相同的比率的。一些回报,Gt.t+1,被整个轨迹的重要性比率相乘,这在模型假设:γ是终止概率下是不正确的。直观上,我们想要给Gt.t+1Pt.t+1,这很容易:
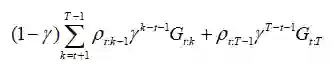
啊,好多了!这样,每个部分回报都有他们正确的比率,这极大解决了无界方差问题。
单个奖励重要性采样
另一种缓解p和它的方差问题的方式,我们可以将G分解为各个奖励,然后做一些分析,让我们研究一下Pt.T-1Gt.T:
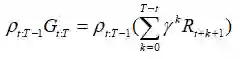
对于每一项,我们有Pt.T-1γkRt+k+1。扩展p,我们发现:
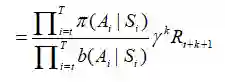
在没有常数γk的情况下求期望:
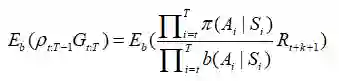
记住E(AB)=E(A)E(B)当且仅当它们是独立的。显然根据马尔科夫性质,任意π(Ai|Si)和b(Ai|Si)都是独立于Rt+k+1,(如果i≥t+k+1),且
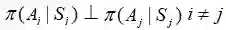
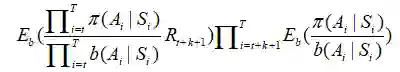
这个式子看起来也许非常丑,但是我们发现:
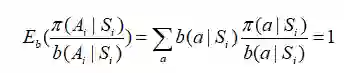
所以我们可以完全忽略后半部分,从而得到:
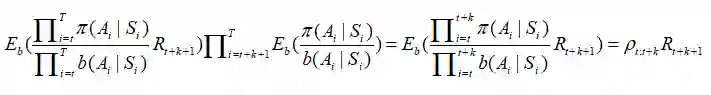
这是什么意思呢?我们完全可以用期望来表示最初的和:
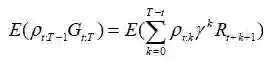
这又一次将减少我们估计量的偏差。
Python中的在线策略模型
因为蒙特卡罗方法通常都是相似的结构。我在Python中创建了一个离散蒙特卡罗类,可以用来插入和运行。
代码下载:
https://github.com/OneRaynyDay/MonteCarloEngine
"""
General purpose Monte Carlo model for training on-policy methods.
"""
from copy import deepcopy
import numpy as np
class FiniteMCModel:
def __init__(self, state_space, action_space, gamma=1.0, epsilon=0.1):
"""MCModel takes in state_space and action_space (finite)
Arguments
---------
state_space: int OR list[observation], where observation is any hashable type from env's obs.
action_space: int OR list[action], where action is any hashable type from env's actions.
gamma: float, discounting factor.
epsilon: float, epsilon-greedy parameter.
If the parameter is an int, then we generate a list, and otherwise we generate a dictionary.
>>> m = FiniteMCModel(2,3,epsilon=0)
>>> m.Q
[[0, 0, 0], [0, 0, 0]]
>>> m.Q[0][1] = 1
>>> m.Q
[[0, 1, 0], [0, 0, 0]]
>>> m.pi(1, 0)
1
>>> m.pi(1, 1)
0
>>> d = m.generate_returns([(0,0,0), (0,1,1), (1,0,1)])
>>> assert(d == {(1, 0): 1, (0, 1): 2, (0, 0): 2})
>>> m.choose_action(m.pi, 1)
0
"""
self.gamma = gamma
self.epsilon = epsilon
self.Q = None
if isinstance(action_space, int):
self.action_space = np.arange(action_space)
actions = [0]*action_space
# Action representation
self._act_rep = "list"
else:
self.action_space = action_space
actions = {k:0 for k in action_space}
self._act_rep = "dict"
if isinstance(state_space, int):
self.state_space = np.arange(state_space)
self.Q = [deepcopy(actions) for _ in range(state_space)]
else:
self.state_space = state_space
self.Q = {k:deepcopy(actions) for k in state_space}
# Frequency of state/action.
self.Ql = deepcopy(self.Q)
def pi(self, action, state):
"""pi(a,s,A,V) := pi(a|s)
We take the argmax_a of Q(s,a).
q[s] = [q(s,0), q(s,1), ...]
"""
if self._act_rep == "list":
if action == np.argmax(self.Q[state]):
return 1
return 0
elif self._act_rep == "dict":
if action == max(self.Q[state], key=self.Q[state].get):
return 1
return 0
def b(self, action, state):
"""b(a,s,A) := b(a|s)
Sometimes you can only use a subset of the action space
given the state.
Randomly selects an action from a uniform distribution.
"""
return self.epsilon/len(self.action_space) + (1-self.epsilon) * self.pi(action, state)
def generate_returns(self, ep):
"""Backup on returns per time period in an epoch
Arguments
---------
ep: [(observation, action, reward)], an episode trajectory in chronological order.
"""
G = {} # return on state
C = 0 # cumulative reward
for tpl in reversed(ep):
observation, action, reward = tpl
G[(observation, action)] = C = reward + self.gamma*C
return G
def choose_action(self, policy, state):
"""Uses specified policy to select an action randomly given the state.
Arguments
---------
policy: function, can be self.pi, or self.b, or another custom policy.
state: observation of the environment.
"""
probs = [policy(a, state) for a in self.action_space]
return np.random.choice(self.action_space, p=probs)
def update_Q(self, ep):
"""Performs a action-value update.
Arguments
---------
ep: [(observation, action, reward)], an episode trajectory in chronological order.
"""
# Generate returns, return ratio
G = self.generate_returns(ep)
for s in G:
state, action = s
q = self.Q[state][action]
self.Ql[state][action] += 1
N = self.Ql[state][action]
self.Q[state][action] = q * N/(N+1) + G[s]/(N+1)
def score(self, env, policy, n_samples=1000):
"""Evaluates a specific policy with regards to the env.
Arguments
---------
env: an openai gym env, or anything that follows the api.
policy: a function, could be self.pi, self.b, etc.
"""
rewards = []
for _ in range(n_samples):
observation = env.reset()
cum_rewards = 0
while True:
action = self.choose_action(policy, observation)
observation, reward, done, _ = env.step(action)
cum_rewards += reward
if done:
rewards.append(cum_rewards)
break
return np.mean(rewards)
if __name__ == "__main__":
import doctest
doctest.testmod()
如果你想在不同的库中使用它,可以自己尝试一下。
举例:21点纸牌游戏
在这个例子中,我们使用OpenAI的gym库。在这里,我们使用一个衰减的ε-贪婪策略去解决21点纸牌游戏:
import gym
env = gym.make("Blackjack-v0")
# The typical imports
import gym
import numpy as np
import matplotlib.pyplot as plt
from mc import FiniteMCModel as MC
eps = 1000000
S = [(x, y, z) for x in range(4,22) for y in range(1,11) for z in [True,False]]
A = 2
m = MC(S, A, epsilon=1)
for i in range(1, eps+1):
ep = []
observation = env.reset()
while True:
# Choosing behavior policy
action = m.choose_action(m.b, observation)
# Run simulation
next_observation, reward, done, _ = env.step(action)
ep.append((observation, action, reward))
observation = next_observation
if done:
break
m.update_Q(ep)
# Decaying epsilon, reach optimal policy
m.epsilon = max((eps-i)/eps, 0.1)
print("Final expected returns : {}".format(m.score(env, m.pi, n_samples=10000)))
# plot a 3D wireframe like in the example mplot3d/wire3d_demo
X = np.arange(4, 21)
Y = np.arange(1, 10)
Z = np.array([np.array([m.Q[(x, y, False)][0] for x in X]) for y in Y])
X, Y = np.meshgrid(X, Y)
from mpl_toolkits.mplot3d.axes3d import Axes3D
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.plot_wireframe(X, Y, Z, rstride=1, cstride=1)
ax.set_xlabel("Player's Hand")
ax.set_ylabel("Dealer's Hand")
ax.set_zlabel("Return")
plt.savefig("blackjackpolicy.png")
plt.show()
当没有可用的A时,我们得到一个非常漂亮的图形,(网络中Z为Flase)。
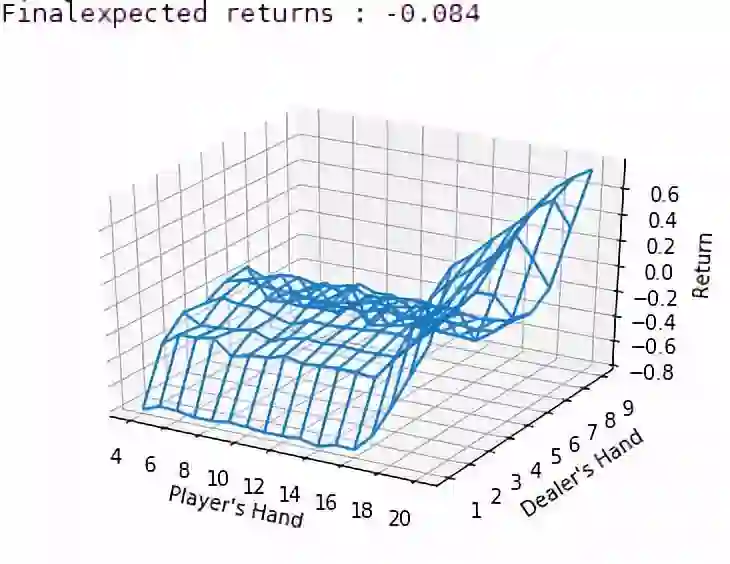
我也写了一个模型的快速的离线策略版本,还没有润色过,因为我只想得到一个性能基准,这是结果:
Iterations: 100/1k/10k/100k/1million.
Tested on 10k samples for expected returns.
On-policy : greedy
-0.1636
-0.1063
-0.0648
-0.0458
-0.0312
On-policy : eps-greedy with eps=0.3
-0.2152
-0.1774
-0.1248
-0.1268
-0.1148
Off-policy weighted importance sampling:
-0.2393
-0.1347
-0.1176
-0.0813
-0.072
举例:悬崖行走
对代码的更改实际上非常小,因为正如我所说的,蒙特卡罗采样是与环境无关的,我们修改了这部分代码(除去绘图部分):
# Before: Blackjack-v0
env = gym.make("CliffWalking-v0")
# Before: [(x, y, z) for x in range(4,22) for y in range(1,11) for z in [True,False]]
S = 4*12
# Before: 2
A = 4
们运行gym库得到了Eπ[G]为-17.0。还不错!悬崖行走问题是一幅一些区域为悬崖一些区域为平台的地图。如果你在平台上行走,你的每一步将获得-1的奖励,如果你从悬崖上摔下来,将得到-100的奖励,将你降落在悬崖上时,你会回到起点,不管地图多大,每一个环节-17.0似乎是近乎最优的策略。
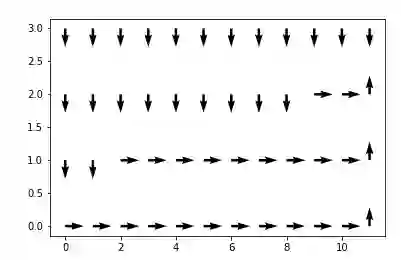
我们可以看到,蒙特卡罗方法对于计算任意行为和观察空间具有诡异的概率分布的任务的最优值函数和行为值是一种很好的技术。在未来,我们会考虑蒙特卡罗方法更好的变体,但是这也是强化学习基础知识中的一块伟大的基石。
References:
Sutton, Richard S., and Andrew G.Barto. Reinforcement Learning: an introduction. The MIT Press, 2012.
相关报道:
https://oneraynyday.github.io/ml/2018/05/24/Reinforcement-Learning-Monte-Carlo/#on-policy-model-in-python
【今日机器学习概念】
Have a Great Definition






