重磅 | 经典教材 R. Sutton《增强学习导论》最新版(548PDF)

精彩回顾
2018新智元产业跃迁AI技术峰会圆满结束,点击链接回顾大会盛况:
爱奇艺 http://www.iqiyi.com/l_19rr3aqz3z.html
腾讯新闻 http://v.qq.com/live/p/topic/49737/preview.html
新浪科技 http://video.sina.com.cn/l/p/1722511.html
云栖社区 https://yq.aliyun.com/webinar/play/419
斗鱼直播 https://www.douyu.com/432849
天池直播间 http://t.cn/RnQPhuY
IT大咖说 http://www.itdks.com/eventlist/detail/1992
新智元编译
编译:克雷格
【新智元导读】加拿大阿尔伯塔大学著名增强学习大师 Richard S. Sutton 教授的经典教材《增强学习导论》(Reinforcement Learning: An Introduction)第二版近期更新,现书稿的草稿在其主页提供,新智元编译图书的目录部分,全书(英文版 draft)可在新智元公众号下载。本书系统性地介绍了增强学习,共548页,其中不乏许多新颖的应用案例分析。
《强化学习导论》电子书地址:
https://drive.google.com/file/d/1xeUDVGWGUUv1-ccUMAZHJLej2C7aAFWY/view

全书目录
第二版引言
第一版引言
符号总结
1. 增强学习的问题
1.1 增强学习
1.2 案例
1.3 增强学习要素
1.4 限制和范围
1.5 一个延伸案例:Tic-Tac-Toe
1.6 小结
1.7 增强学习的历史
2. 多臂赌博机(Muti-arm Bandits)问题
2.1 K-臂赌博机问题
2.2 行动值方法
2.3 The 10-armed Testbed
2.4增量实现
2.5 追踪一个非稳态解
2.6 优化初始值
2.7 置信上界行动选择
2.8 梯度赌博机算法
2.9 关联检索
2.10 小结
3. 有限马尔科夫决策过程
3.1 代理(agent)环境交互
3.2 目标和回馈
3.3 返回
3.4 为插入或连续性任务统一符号
3.5 策略和价值函数
3.6 优化策略和价值函数
3.7 优化和近似
3.8 总结
4. 动态编程
4.1 策略估计
4.2 策略改进
4.3 策略迭代
4.4 迭代值
4.5 异步动态编程
4.6 泛化的策略迭代
4.7 动态编程的效果
4.8 总结
5. 蒙特卡洛方法
5.1 蒙特卡洛预测
5.2 蒙特卡洛对行动价值的评估
5.3 蒙特卡洛控制
5.4 不读取(Explore)开始条件下的蒙特卡洛控制
5.5 通过重要抽样进行无策略(off-Policy)预测
5.6 增量实现
5.7 Off-Policy 蒙特卡洛控制
5.8 *Discounting-aware Importance Sampling
5.9 *Per-decision Importance Sampling
5.10 总结
6. 时间差分(TD)学习
6.1 时间差分预测
6.2 时间差分预测方法的优势
6.3 TD(o)的最佳性
6.4 Sarsa:在策略(On-Policy) TD 控制
6.5 Q-Learning:连策略TD 控制
6.6 期待的Sarsa
6.7 偏差最大化和双学习
6.8 游戏、afterstates 和其他具体案例
6.9 总结
7. 多步骤 bootstrapping
7.1 n-step TD 预测
7.2 n-step Sarsa
7.3 通过重要性抽样进行 n-step 离策略学习
7.4 *Per-decision Off-policy Methods with Control Variates
7.5无重要性抽样下的离策略学习:n-step 树反向算法
7.6 一个统一的算法:n-step Q( σ)
7.7 总结
8. 用列表方法进行计划和学习
8.1 模型和计划
8.2 Dyna:融合计划、行动和学习
8.3 模型错了会发生什么
8.4 优先扫除 (prioritized sweeping)
8.5 Expected vs. Sample Updates
8.6 Trajectory Sampling
8.7 Real-time Dynamic Programming
8.8 计划作为行动选择的一部分
8.9 启发式搜索
8.10 Rollout Algorithms
8.11 蒙特卡洛树搜索
8.12 本章总结
8.13 Summary of Part I: Dimensions
9. 使用近似法的在政策预测
9.1 价值函数的近似
9.2 预测目标(MSVE)
9.3 随机梯度和半梯度的方法
9.4 线性方法
9.5 线性方法中的特征构建
9.5.1 多项式
9.5.2 傅里叶基础
9.5.3 Coarse coding
9.5.4 Tile Coding
9.5.5 径向基函数
9.6 Selecting Step-Size Parameters Manually
9.7 非线性函数近似:人工神经元网络
9.8 最小平方TD
9.9 Memory-based Function Approximation
9.10 Kernel-based Function Approximation
9.11 Looking Deeper at On-policy Learning: Interest and Emphasis
9.12 总结
10. 用近似法控制on-policy 在策略
10.1 插入式的半梯度控制
10.2 n-step 半梯度Sarsa
10.3 平均回馈:连续任务中的新问题设定
10.4 “打折”的设置要考虑可用性
10.5 n-step 差分半梯度Sarsa
10.6 总结
11. 使用近似法的离策略方法
11.1 半梯度的方法
11.2 Barid 的反例
11.3 The deadly triad
11.4 Linear Value-function Geometry
11.5 Gradient Descent in the Bellman Error
11.6 The Bellman Error is Not Learnable
11.7 Gradient-TD Methods
11.8 Emphatic-TD Methods
11.9 Reducing Variance
11.10 总结
12. 合格性追踪
12.1 λ-返回
12.2 TD(λ)
12.3 n-step Truncated λ-return Methods
12.4 Redoing Updates: The Online λ-return Algorithm
12.5 真实的在线TD(λ)
12.6 蒙特卡洛学习中的Dutch Traces
12.7 Sarsa(λ)
12.8 Variable λ and γ
12.9 Off-policy Eligibility Traces with Control Variates
12.10 Watkins’s Q(λ) to Tree-Backup(λ)
12.11 Stable Off-policy Methods with Traces
12.12 Implementation Issues
12.13 结论
13. 策略梯度方法
13.1 策略近似及其优势
13.2 策略梯度的原理
13.3 增强:蒙特卡洛策略梯度
13.4 使用基准增强
13.5 评估-决策方法(Actor-Critic)
13.6 连续问题中的策略梯度(平均回馈率)
13.7 连续行动中的策略参数化
13.8 总结
14.心理学
14.1 预测和控制
14.2 经典的调节
14.2.1 Blocking and Higher-order Conditioning
14.2.2 rescorla wagner 方法
14.2.3 TD模型
14.2.4 TD 模型模拟
14.3 有用条件
14.4 延迟的增强
14.5 认知图
14.6 习惯和目标导向的行为
14.7 总结
15. 神经科学
15.1 神经科学基础
15.2 回馈信号、价值、预测误差和增强信号
15.3 回馈预测误差假设
15.4 回馈预测误差假设的实验支持
15.6 TD 误差/ 多巴胺对应
15.7 神经评估-决策
15.8 评估-决策的学习规则
15.9 快乐主义的神经元
15.10 集体增强学习
15.11 大脑中基于模型的方法
15.12 上瘾
15.13 总结
16. 应用和案例分析
16.1 TD-Gammon
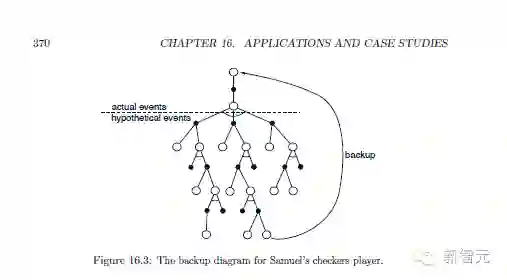
16.2 Samuel 的西洋棋玩家
16.3 Watson的 Daily-Double
16.4 优化记忆控制
16.5 人类水平的电子游戏
16.6 下围棋
16.6.1 AlphaGo
16.6.2 AlphaGo Zero
16.8 个性化网页服务
16.9 热气流滑翔
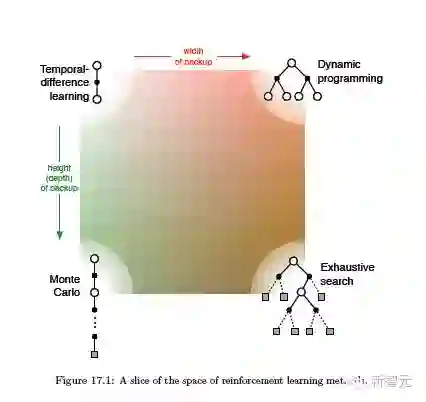
17.前沿
17.1 General Value Functions and Auxiliary Tasks
17.2 Temporal Abstraction via Options
17.3 Observations and State
17.4 Designing Reward Signals
17.5 Remaining Issues
17.6 Reinforcement Learning and the Future of Artificial Intelligence
参考文献
说明


《强化学习导论》电子书地址:
https://drive.google.com/file/d/1xeUDVGWGUUv1-ccUMAZHJLej2C7aAFWY/view
精彩回顾
2018新智元产业跃迁AI技术峰会圆满结束,点击链接回顾大会盛况:
爱奇艺 http://www.iqiyi.com/l_19rr3aqz3z.html
腾讯新闻 http://v.qq.com/live/p/topic/49737/preview.html
新浪科技 http://video.sina.com.cn/l/p/1722511.html
云栖社区 https://yq.aliyun.com/webinar/play/419
斗鱼直播 https://www.douyu.com/432849
天池直播间 http://t.cn/RnQPhuY
IT大咖说 http://www.itdks.com/eventlist/detail/1992
