国产引擎 Cocos 的跨平台渲染器架构与实践 | GMTC

你好,我是 Cocos 引擎的创始人王哲。跟看到这篇文章的你一样,我也是一位程序员,虽然现在的主要工作更偏向于经营管理,但是程序员的底子已经刻到基因里了,所以在此想跟你分享一下 Cocos 引擎的技术架构与相关实践,希望能给你带来一些新的认识。
去年,我在 GMTC 深圳演讲开场时,对现场的听众做了一个小小的调研,我问他们中有多少人用过或者听过 Cocos,当时有很多人举手了,我当时十分开心。
但是大家对于 Cocos 的认识停留在什么阶段还是存在差别的。GMTC 演讲那天,我边上坐了两位来自阿里的哥们儿,寒暄之间我介绍自己是 Cocos 的,对方立刻反应过来了,同时说了《捕鱼达人》《欢乐斗地主》《开心消消乐》等多款用 Cocos 开发的游戏。我当时便调侃道,哥们你的信息有点“过季”了。
这几年我们做了很多事情,下面和大家一一道来。
目前市场上近乎所有的休闲、卡牌游戏,绝大部分的传奇类游戏,以及约 64% 的小游戏都是用 Cocos 开发的。所以在多数人印象中,Cocos 能做的游戏大约可以概括为下图所示的几种:
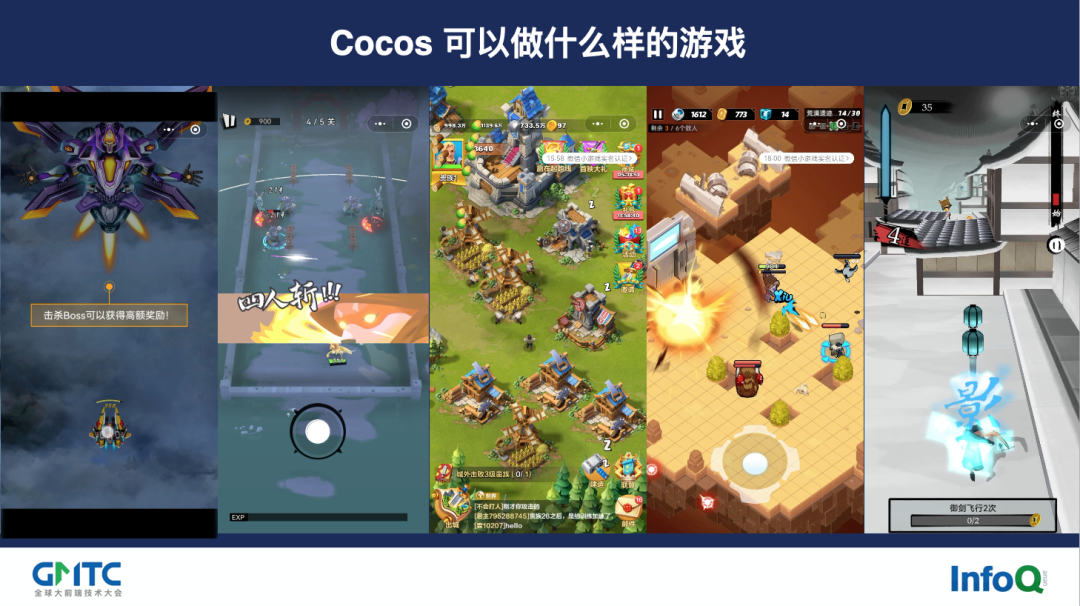
事实上,基于 Cocos 引擎开发的游戏类型远不止如此,还包括以《列王的纷争》和《乱世王者》为代表的 SLG 类,以《热血传奇系列》为代表的 RPG 类,以《动物餐厅》为代表的模拟经营类等游戏。2021 年,Cocos 还有一个更大的突破,就是合并了 2D 和 3D 两条产品线,推出了“ Cocos Creator 3.X ”版本,实现了在同一个编辑器既可以开发 2D 内容又能够开发 3D 内容的能力。
那这里的 3D 内容是前文所述的休闲 3D 吗?早已不是,我们今天的 3D 内容是这样的:
(赛博朋克)
对于上面这个 Demo,场景里有几百个动态光源,行业内的朋友认为可以达到 3A 级效果。而下面这个 Demo 则展示了在 Cocos Creator 中使用延迟渲染管线实现的环境光、烘焙等效果,而且可以在海思的 GPU 上跑到满帧。
(海思 CGKIT 光球)
从支持简单休闲的 2D 和 2.5D ,进化到如今的 3D 引擎,Cocos 的架构历经了多次迭代和演进,在这个过程中,我们有哪些思考?踩过哪些坑?以及 Cocos 和 Unity、Unreal 有哪些区别,我们为什么这么做?接下来,我将结合 Cocos 架构的演进历程,把这些心得分享给大家。
首先,我们先来看一下 Cocos 的早年架构是什么样子的。
早几年我还在自己写代码的时候,Cocos 引擎的架构是像下图这样的:
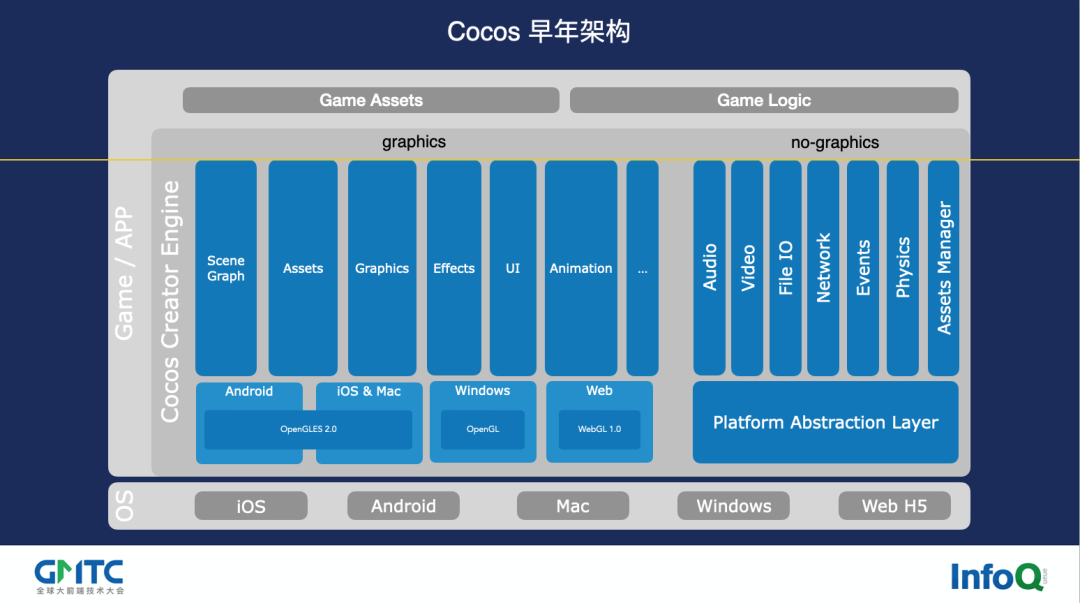
在上面的架构图中可以看到,图形渲染这块,我们每个功能就是一个 Node,Node 中有两个最核心的函数:update 和 render。update 会将你的位置、形变等全部计算清楚,而 render 则把它画出来。
这就像两个循环,第一个先根据场景数把所有东西全部 update,比如说物理碰撞后产生的几个碎片,分别飞到什么位置,把这些全部计算清楚了。第二个就是画,它就是一个渲染技术,渲染节点画出来。
再往下,这个就是用 OpenGL 了,OpenGL ES,WebGL,就这一套,其他的渲染标准我不管,因为在以前也没有这些,所以我们只要把 OpenGL 搞定就行了,然后在各个平台全部跑通。
但是这个架构到了 3D 游戏的时代,它的支撑力就开始比较差了,因为 2D 游戏只要渲染一遍就够了,但是 3D 游戏的粒子系统、动画系统、光照和阴影等等都是独立计算又相互影响的,这个时候没办法再简单地通过不同节点来组装,渲染器也不能简单地通过一个个顺序的渲染函数组织,这个时候我们就需要一个新的架构来支撑。
经过我们多次的迭代演进,Cocos 当前架构如下图所展示:
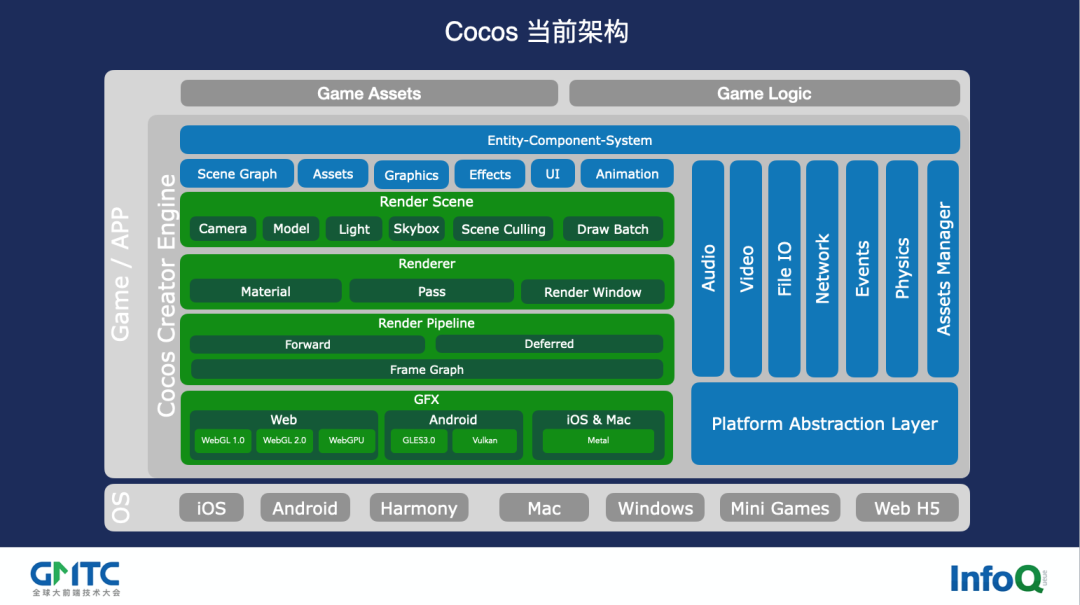
这里是以渲染器架构为主,从上面的架构图中可以看到,从渲染场景(Render Scene)开始,会有模型(Model)、光照(Light)、天空盒(Skybox)等,然后要做场景裁剪(Scene Culling)等等。
场景剪裁完成后会生成一系列的渲染对象,进入 Renderer 开始基于 Camera、材质(Material)、Pass 的优先级来组织渲染队列。
接下来,开始有渲染管线(Render Pipeline)。目前主流的渲染管线以 Forward Rendering/Deferred Rendering 为主,Cocos 和大多数引擎一样,支持这两种渲染管线。在此,特别提一下移动端的渲染管线,自从《原神》游戏火爆了之后,移动端也开始流行做延迟渲染。这个时候 Cocos 想到了 Frame Graph,在复杂的渲染管线下,存在各种不同需求的渲染 Pass 和流程,那么 Frame Graph 的价值就是把这些流程变成像拼乐高一样,把这些小零件组装起来,而且在未来还可以将这种方便的定制能力开放给开发者。
渲染器的最后一层就是 GFX 设备层。其实 GPU 的框架大同小异,但是不同操作系统和不同环境下使用的图形 API 不同,我们的 GFX 的做法是用统一的接口将所有图形 API 封装起来,无论底层是 OpenGL、Vulkan、Metal,还是 WebGPU,我们逐一接入封装清楚后,引擎就能直接使用统一的 GFX API 了。
接下来是 mainloop 时序。
你可以先思考一下,为什么目前应用引擎有很多,而游戏引擎在全球能打的就剩 Unreal、Unity、Cocos 三家了?在我看来,是因为游戏引擎和应用渲染本质上是不一样的,应用渲染它可以描述为“敌不动我不动”,因为只要你没有输入或者没有通知响应,应用渲染是不会去重绘界面的,可以说是怎么省电怎么来。

游戏引擎可不是这样,游戏引擎可以理解为和视频播放器一样,是一个不断循环的过程。一般电影的帧率是 1 秒 24 帧就可以了,因为电影再高的刷新率理论上人眼就无法分辨了。但游戏与电影不同,游戏因为都是逐个静帧没有视觉残留可以过度,所以游戏里 30 帧的效果很勉强,后来人们觉得 30 帧也卡得不行,要求就变得更高了,变成 60 帧,现在还有高刷屏,有 90 帧、120 帧。
游戏引擎就是不管玩家动不动,画面一定处于一种运动的状态中。你可以注意一下所有的游戏画面,当你静止的时候,画面绝对不会一点都不更新,策划不会留出这种空间出来的,不然你会觉得这个游戏卡死了,对吧?所以当你玩家人物静止的时候,正常的画面里还会有人物的呼吸起伏,会有风吹草动,然后会有飞鸟过境等等这些。
在 2D 引擎时代,大家做 Batch 就很开心了,但在 3D 引擎时代多了 Camera 的概念,这里如何理解?可能有个主要的 Camera,但场景中还可能有个后视镜,还可能有一滩水,也可能有其他更复杂的情况。比如说一个人是一个 Model ,而你的这个人物身体可能由多个不同材质的 subModel 组成,然后每个 subModel 的材质可能包含多个渲染 Pass,他可能要画好多次,比如物体表面光照要画一次,阴影要画一次,如果有镜面有投影这些的话还要再画。这些复杂 Pass 的组织就是在 Frame Graph 里面去处理的,处理完以后就变成大量的渲染指令丢给 RenderQueue。
好,到这里就算渲染期结束了,接下来就是 GFX 的活了,让它直接去跟硬件交互就行。
Cocos 与竞争对手不太一样的地方是:有些引擎是在 PC 时代就已经有了,比如第一代 Unreal 是在 1998 年始发。而 Cocos 则是移动端优先,即优先在移动端上运行,移动端中引擎的 GPU 架构跟 PC 端是完全不同的。因此,无论是 PC 端优先还是移动端优先,亦或是两者兼顾,都会影响 Cocos 的整个架构设计。
举一个典型的例子,在 PC 端,它的渲染方式叫 Immediate Mode Rendering(IMR),它是如何立刻执行?只要渲染指令一下到 GPU 里面,它“啪”一条线就渲染出来,马上画出来了,它的 Buffer 在哪里?在显存里面。如果这时候出现问题了,比如说显存 64G 不够怎么办?不够就加显存,128G,256G,加完显存以后,GPU 再跟显存的交互就得加带宽,带宽加上去还不够?加电压,加电压不就快了吗?那这个功耗一上去,发热量提高怎么办?没关系,加风扇!就是“老夫一把梭,一条干到底”,有问题解决问题,反正 PC 端就是你爱干啥爱加什么装备都可以。
但是移动端不一样,移动端我们是没法加风扇的,而且最惨的是它没有显存这个概念,一块芯片 SoC 里面 GPU 得跟 CPU 去共享内存,这时候渲染跟内存的读写,IO 就已经卡在你这边了,那更不用说性能的提升了。
上帝说要有光,于是我们针对移动端做了一套渲染的解决方案。
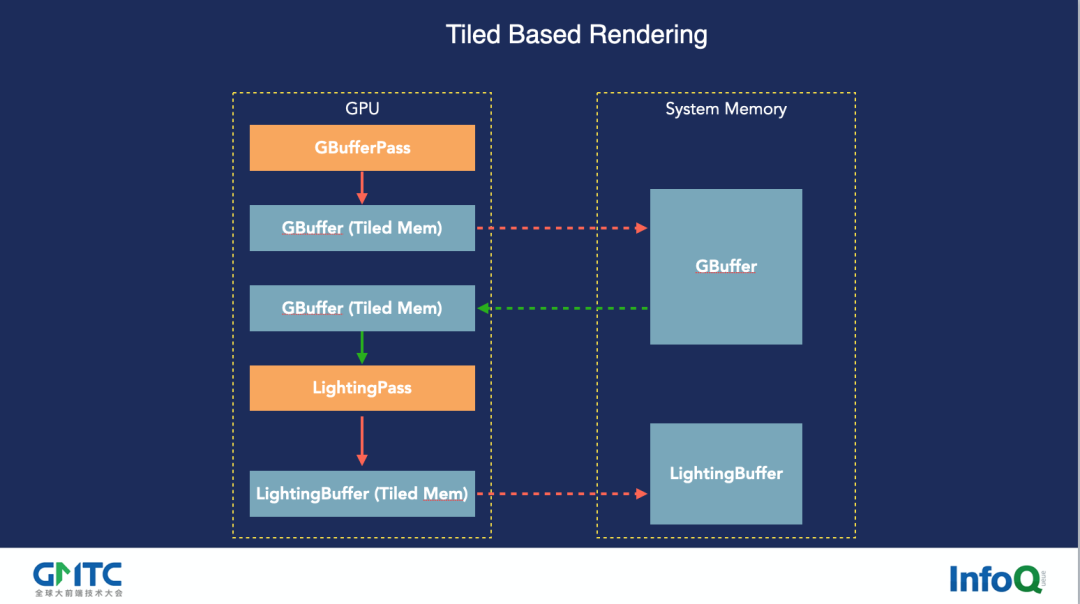
上图是传统延迟管线在移动端 Tiled Based GPU 上的简要渲染流程。在流程中可以看到,有 GBuffer 和 Tiled Memory,这一般就是 32KB、64KB,如何处理?其实和易旭昕老师讲的方法类似,就是分区,分而治之。
这是在编程里是很常见的问题,一个东西太大了,要塞到外面的内存去,读写、IO 特别慢。没关系,我们将它拆成一个个小格子。Tiled Memory 有 32×32,也有 64×64,现在比较新的是 64×64,可以把整个画面拆成小小的。
这里需要注意的是,如果要优化好移动端的功耗,就要避免把 GBuffer 存储到 System memory 中,直接在 TIled Memory 中处理完以后不要往外读了,每个 Tile 存完 GBuffer 以后直接做光照,这样就可以省掉 Gbuffer 的 IO 开销,做完光照计算,结束。这时候因为它很小,不像 PC 的显存,你可以爱用多少用多少,在移动端就感觉像玩十字绣一样,你得很小心地去用它。
所以在整个的渲染流程中,你需要提前规划好每一步缓存。如果存完之后又想重新画一个东西,那么就浪费了这部分缓存,浪费以后又开始在手机上面频繁地读写系统的内存,那之前所有功夫就全部白废了。
这是移动端跟 PC 端的一个非常本质的区别,Cocos 是移动端优先,所以我们的整体架构就是符合这种 best practice。当然大家在使用引擎的时候是无需关心这些内容的,一般现代引擎都会把这些东西都封装好供你使用。这里提一句,上文所述的这些在开源仓库里都可以拿到,因为 Cocos 是开源的。

前文提到,GFX 可以把所有不同的地方全部封装出来,这部分 Cocos 也是开源的,是 MIT license,因此大家可以商用。所以如果你们要做图形渲染的话,就算代码看不懂也没关系,可以整个直接拿去使用。比如说,后面 WebGPU 出来,或者 Metal 的新版本、Vulkan 的新版本出来,直接再往里面加就可以了。这样一来,就不用再去管那些芯片厂商有什么新技术,免得影响到你上面整个架构的运行。
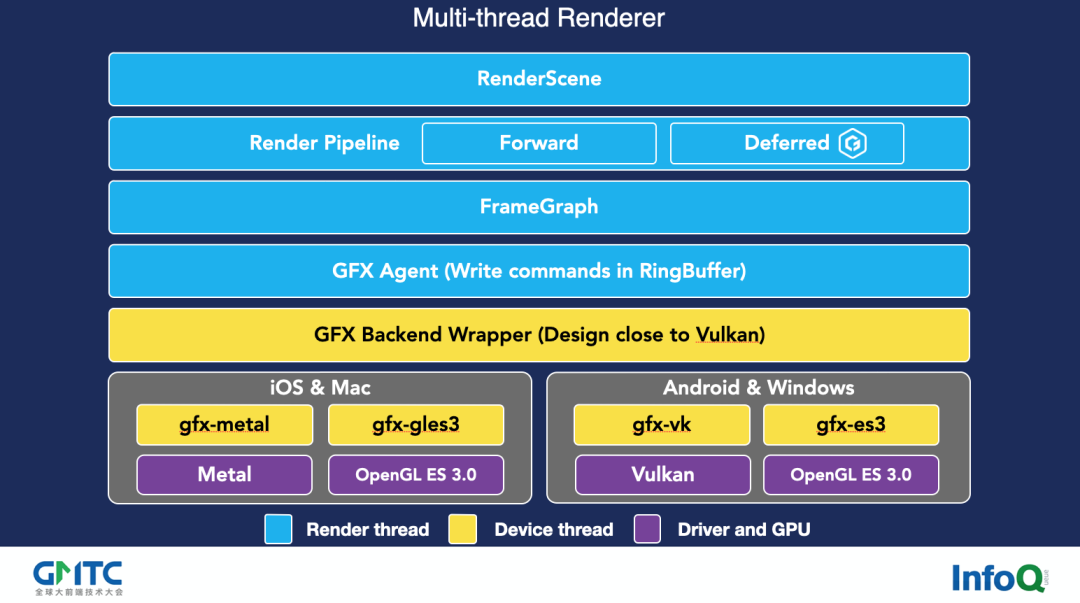
接下来说一下多线程。我见过一些刚入门的程序员写多线程都很开心,直接来一个 slightly poor、Job System,各种线程满天飞,也觉得自己特别酷。在我最早的时候是做硬件的,实际上只有一个单独的硬件的 IO,才值得你去开一个线程,否则的话,在 CPU 里面切换线程的开销,大于你多线程的收益,这并不划算。
像 GPU、网络、物理可能值得开一个线程,但也不是说物理全部值得去开,像最新的骁龙 888 CPU,也叫 1+3+4,即 1 个超大核加 3 个大核加 4 个小核,那也就 8 个核。8 个核你没有必要开十几个线程,所以这个多线程的结构图,多线程里面常见的就是这种生产者消费者模型,大家应该都玩过。
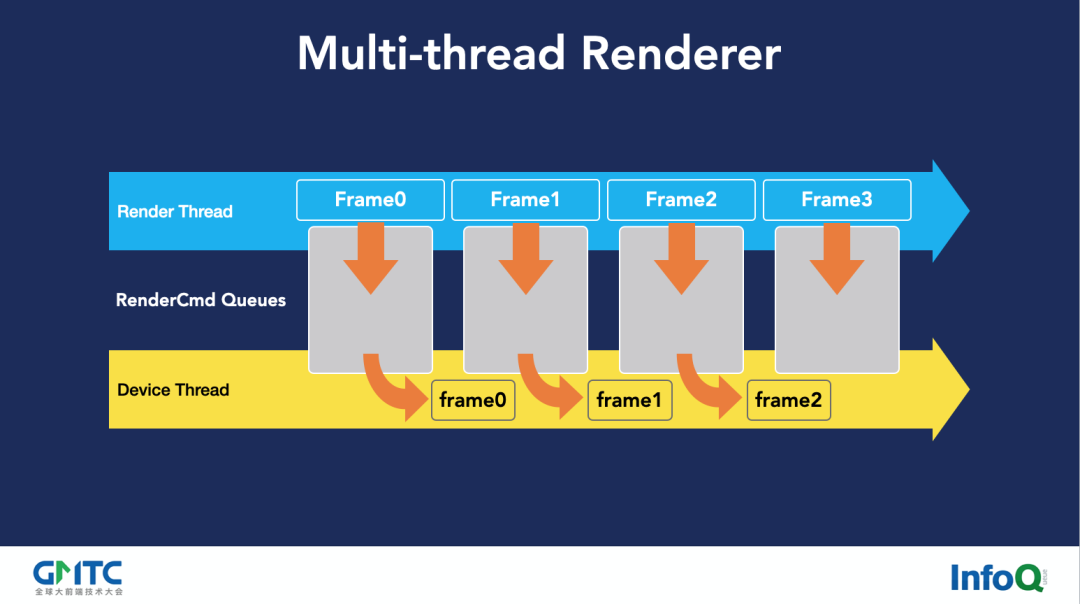
上图中的 Render Thread,以及物理、网络你也不用管。从渲染的线程,我处理完一帧,然后压到 RenderCmd Queues 这个 Buffer 以后,丢给 GFX。这个地方就像一个用来录制 GPU 的独立设备线程,上面是生产者,下面是消费者,这种模型比较普遍。
不过,我曾经见过一个游戏公司写的多线程,他们是没有这种消费者的 wait,wait signal,类似这种写法,他们是直接拿一个 while(1),然后读一下有没有,没有的话是 false。好,我 sleep10 毫秒,然后接着再上去再读一下,看没有,我再 sleep10 毫秒,结果导致整个功耗就非常高。
这件事让我印象特别深刻,当时这个游戏公司整个组有 20 个人通宵加班了差不多十来天,还没找到什么问题,觉得引擎为什么发烫呢?一定是引擎性能有问题。然后实在解决不了就找到了我们,结果那行代码他们付了我二三十万,最后发现其实根本不是渲染问题,是在外面,他们在性能同步的地方出问题了。

FrameGraph 自定义渲染管线,实际上这个是寒霜引擎在 GDC 上分享的一个设计。
基本流程分为 Setup 初始化阶段、Compile 编译阶段和 Execute 执行阶段。Setup 是用户指定的渲染流程描述,接着引擎每帧都会实时针对所有 Pass 构建渲染图,梳理整个渲染流程,最后再去执行用户的实际 Pass 回调。
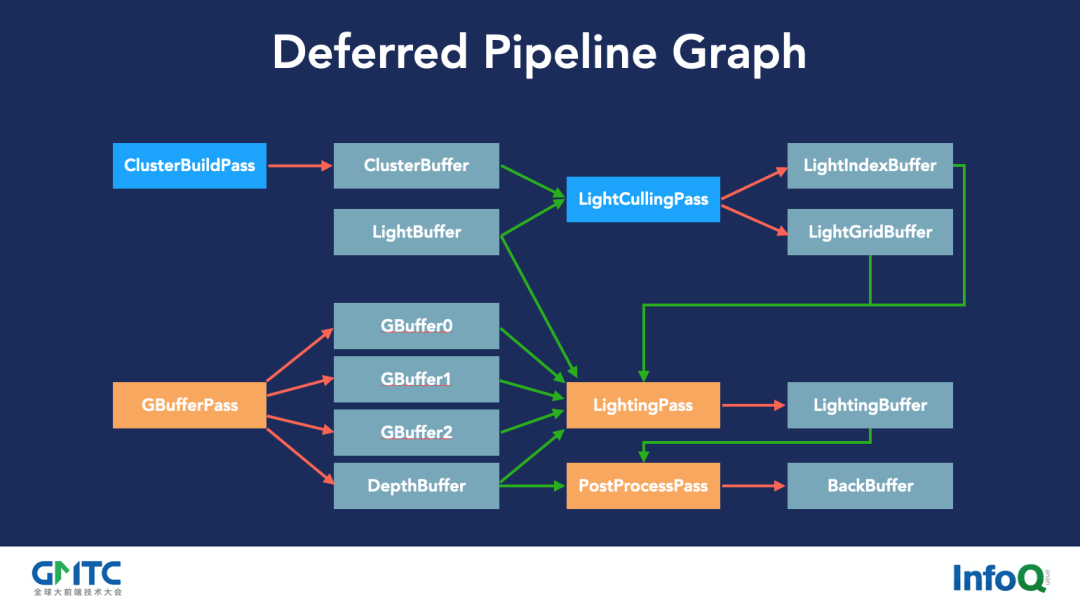
这是我们引擎延迟渲染管线简化后的流程,橙色方块都是渲染 Pass,蓝色方块是 Compute Shader 计算 Pass,我们的计算 Pass 是基于视锥簇的光源剪裁算法,针对每个光源计算影响范围,最后 Lighting Pass 阶段只考虑对物体可能有影响的光源,减少对光照的计算量。
在移动端上,我们将前向管线的动态光源限制为 4 个,超过 4 个以后会对性能有影响,因为每个光源在每个物体上都需要增加一个 Pass,复杂度是乘法关系。前面提到我可以跑上千个光源,虽然里面也有视锥簇裁剪的贡献,但很重要一点就是必须用延迟渲染,延迟渲染它实际上就是所有物体全部画完以后,存在 GBuffer 里面,最后在光照 Pass 中一次性计算所有光源的影响,所以增加光源变成是一个加法关系,而不是一个乘法关系,性能就会高非常多。
当然 GBuffer 占用的存储空间较大,因为现在的手机内存会比较大一些,所以是在拿内存去换性能,但是也因为延迟渲染本身比较占内存,后面如果做后效做抗锯齿用 MSAA 的算法,内存占用还要乘 4,这是一个问题。
第二个问题是它没办法去处理那种半透明的物体,所以如果遇到半透明物体的话,还是要按照 Forward 正常的渲染的流程,比如有个玻璃瓶、小弹珠等半透明的这些东西还要单独再画一轮,这是一个缺点。
所以就目前前端来讲,我还没有看到哪一个项目有疯狂到要用这个 Deferred Rendering,因为感觉更多是炫技用,证明已经可以做到这个程度了,但实际上大家还是保守一点在用 Forward Rendering,不然内存真的很容易爆掉。

(延迟渲染管线 - 动态光源)
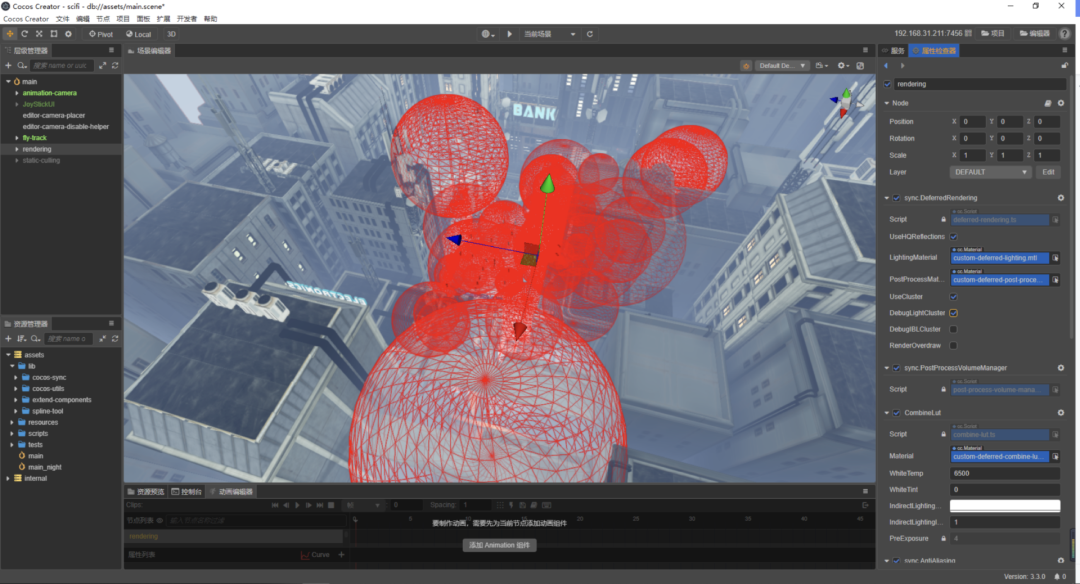
(上百个动态光源)
这里提一下 Bloom,这个比较普遍,所有光照的后渲染效果,都需要稍微有点灰光的效果才不会显得虚假,比如说下面这张图的光都带有 Bloom 的效果。

(加入后处理特效:Bloom)
还有抗锯齿,因为用延迟渲染 MSAA 用不了,内存会爆掉,那我们就用 TAA 了,效果也还不错的。上图的是剔除的,正常的视锥体裁剪,它是按物体去裁剪,算物体的遮挡关系,但是物体奇形怪状的,你也不能指望说前面就是一个特别大的物体,把后面小的全部挡住,所以这边算的方式是跟前面的做法一样,先把场景切成一个个小格,然后计算格子之间的遮挡关系,预存储起来。运行时直接取遮挡关系,如果后面的格子被遮挡了,后面格子里面的所有物体就不需要了,所有光源物体全部拿掉即可。

然后接着再去根据剔除完以后剩的那些格子,把这个格子里面的物体的遮挡再进一步去计算。
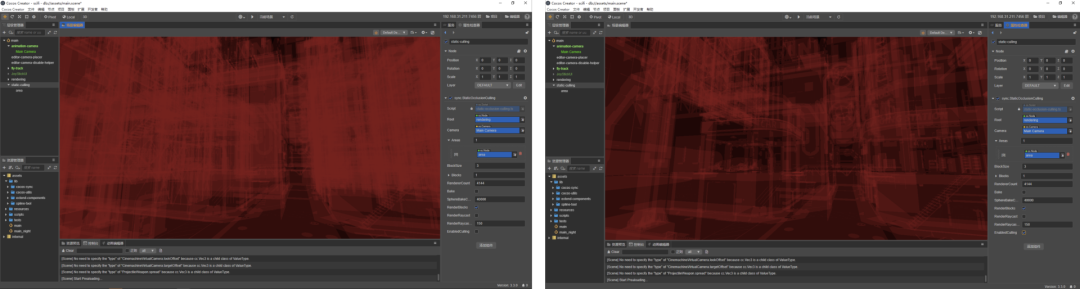
(加入 PVS (Potential Visible Set Culling))
像上面左边这张图是还没有加入 PVS 的情况,所有红色东西都是要画的,但如果是先做了一次裁剪的话,可以看到整个需要画的东西就少非常多(如右图),因为很多东西我们根本看不见,这时候整个 Drawcall 能够降低 50% 左右。
前面分享的都是开源代码,接下来,我想分享一些宏观的观点。
同样是引擎,Cocos 与 Unity、Unreal 有很大的区别,相比之下,另外两家更侧重原生,在 H5 和前端技术上似乎和他们没有关系,而 Cocos 引擎为什么要做这件事情呢?
这里,我想分享一个概念叫“流量底座”,这是我自己造的词。
国外的生态流量底座是 iOS 和 Andriod,是操作系统。这种流量底座有几个明显的特点:
一是对内容有巨大的需求,系统直接面对 C 端用户,系统没办法全部做完所有内容,所以需要大量内容供应商开发出各种 App 形式,来满足 C 端五花八门的需求。
二是禁止二级生态,比如 iOS 下的 App Store 就禁止开发者用下载可执行的脚本,例如动态地下载 H5、JavaScript 代码、Lura 代码到 App 里面运行,因为只要开放这样做,开发者就可以做出各种游戏盒子、游戏大厅,进而产生二级生态。
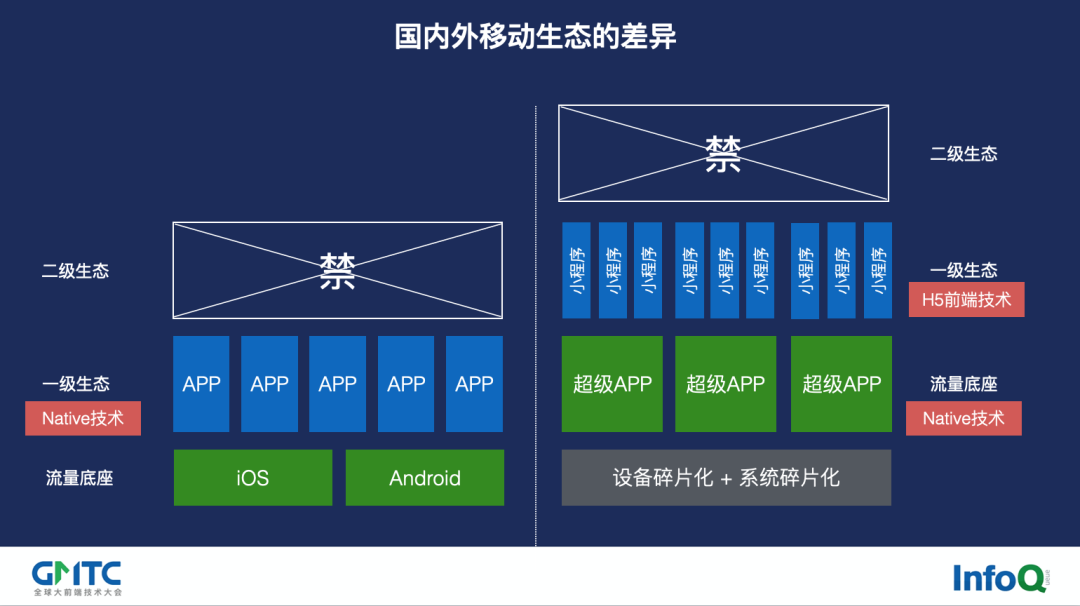
再看国内,华为、小米、OPPO、vivo 等各类手机品牌都有各自的应用商店和生态,但国内真正的流量底座却是超级 App,坐拥真正的流量入口。
为何这样说呢?流量底座,其实就是有议价能力的谈判权。在国内,手机用户已经不喜欢去下载一个新的 App 了,大家更习惯用手机扫码完成健康卡查询、点外卖、共享单车、支付等操作。所以,国内的这些超级 App 在流量底座之上,会建立自己的生态。比如说微信,微信为了满足 C 端用户五花八门的需求,推出了小程序、小游戏,并在此上建立生态。
值得注意的是,App 用 Natice 技术开发的情况下,其上部的生态技术只能选择前端技术,因此,国内的前端技术发展相比国外,是更加活跃的。
但前端技术并非只是为了降低跨平台开发的成本,在之前 GMTC 演讲的现场,有位来自字节的老师也提到两点原因,一是降低开发成本,二是降低渠道更新成本。其实,只有小厂才有跨平台的需求,大厂有足够的能力可以直接分为两个不同的项目组进行,以保证原生版本有更好的体验。但核心是,除了大厂自身的选择之外,还要考虑小程序、小游戏的生态。
这个差异导致了我们的设计,还记得本文开头的 Cocos 引擎的架构图吗?其实已经很复杂了,已经写了几百万行代码。
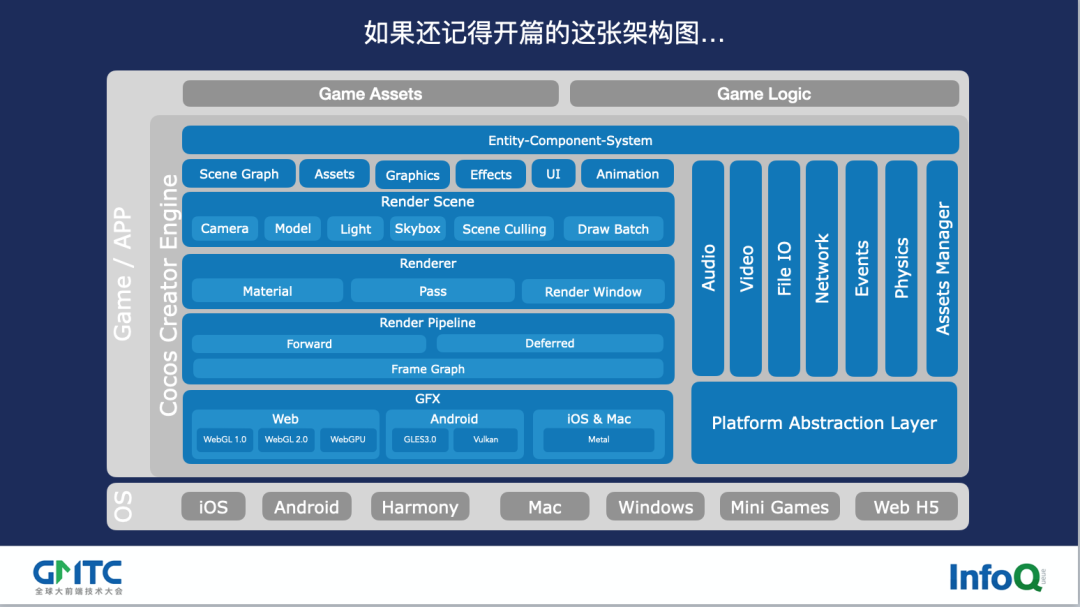
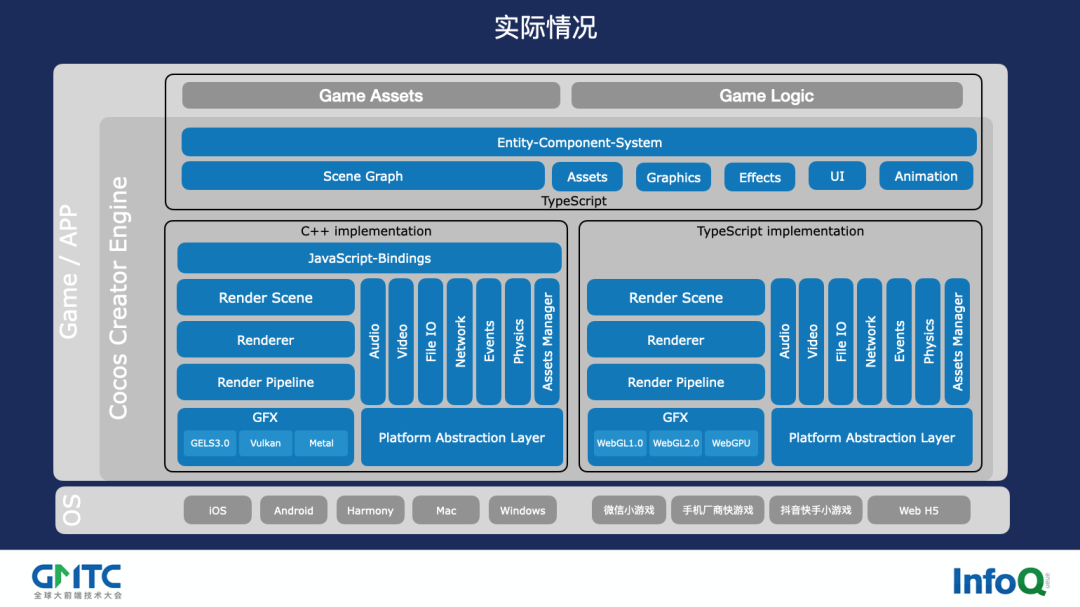
实际上,我们的架构是上图这样的,这部分是前端会用到的,我们用 TypeScript 去写,整个是落在 Web 平台上面,非常适用于各种小游戏、手机厂商的快游戏、抖音快手小游戏、Web H5 等等,现在已经有成千上万的开发者在用 Cocos 开发适用自己平台的产品。说句题外话,这也衍生出了很多市场的岗位需求,很多知名厂商比如爱奇艺、美团、腾讯等,我之前还看到 QQ 音乐有个高级职位在找 Cocos 人才。
另外一方面,Cocos 同样服务于原生手游,许多手游要上硬核厂商渠道,也要出海,而海外则没有 H5 游戏生态。这时候怎么办?我用 C++ 实现一遍,所以这两块引擎是有两组人在写的。这里可能会有问发问,那你为什么不用 WebAssembly 直接编译过来?我只能告诉你 WebAssembly 是有坑的,这个事情我们有实践经验,如果我把这一块东西用 WebAssembly、C++ 直接编译到 TypeScript,跑在浏览器上可不可以?是可以的。
但问题在于什么?前文提及,大家还是要热更的,不能够动态更新的前端是没有灵魂的。我们的游戏都是有灵魂的,所以它这上面用动态脚本去写,但是动态脚本如果去调 WebAssembly 这坨东西,开销非常大,无论是从 JavaScript 也好,TypeScript 也好,调用 WebAssembly 编译出来的这套东西,消耗都是非常大的,最后性能其实还不如直接再写一遍。所以我们为了让大家提高性能,这么多的东西真的就写两份了,这个是目前我们的实际情况。
在这里,其实我只是想说的是,轮子是真的不好造,我们做 Cocos 已经今年第十一年了,我觉得我们算世界第三吧。
•github.com/cocos/engine•github.com/coocs/native-engine•cocos.co
最后跟大家分享两个开源仓库,第一个仓库是我们 H5 这一块的引擎,纯前端的代码全部开源了;第二个 native-engine 是跑在 iOS、安卓上面,还有 windows 和 macOS 上面的原生引擎,也是开源了,都是 MIT license。大家要用的话,不管你要用 Rendering 这层,还是你要用底下 GFX 这一层,直接拿去用,就不要自己造轮子了,有问题可以到“Cocos.com”的论坛上面问我们,我也经常在上面回答问题。
在游戏行业之外,Cocos 也已经进入了更多的领域。比如为教育行业推出的互动课件编辑器 Cocos ICE、为 IoT 设备以及更多屏幕推出的 HMI 人机交互界面,并在 XR、AR、汽车驾驶导航、儿童编程、手表甚至虚拟角色等多个领域都有了方案积累。
也有很多人问我们是不是元宇宙,我的回答是:Cocos 不是元宇宙,但 Cocos 是用来生产元宇宙的工具。不管元宇宙的发展是怎样,总是要有内容,要有实时互动,那么 Cocos 就专门做这个的。
结尾打个广告,大家如果真的也想造轮子的话,欢迎加入我们,加入 Cocos,一起写这个好玩的引擎。(联系邮箱:hr@cocos.com)
本文由 InfoQ 整理自雅基软件 CEO 王哲在 GMTC 全球大前端技术大会(深圳站)2021 上的演讲《Cocos 引擎的跨平台渲染器架构与实践》。
王哲 雅基软件 CEO
Cocos 引擎的创始人和 CEO。经过十年的深耕,目前 Cocos 在全球拥有 150 万的注册开发者,遍布全球超过 203 个国家和地区,服务了 40% 的手机游戏、64% 的 H5 和小游戏、90% 的在线教育 App,以及大量的 IoT 和数字孪生开发者。
今年 6 月 10 日 -11 日,第一场 GMTC 全球大前端技术大会即将落地北京。大会策划涵盖前端业务架构、前端 DevOps、前端性能优化、IoT 动态应用开发、TypeScript、移动端性能与效率优化、前端成长实战、团队可持续建设、跨端技术选型等 15 个专题,邀你一起探寻前端技术的热门方向及落地实践。
更多精彩议题持续打磨上线中,点击底部【阅读原文】直达大会官网,7 折特惠仅剩最后 1 天,现在下单立减 1440 元!感兴趣的同学联系票务经理:17310043226

点个在看少个 bug 👇