GMTC 最新分享:不用 WebAssembly 也能实现 Web 虚拟机保护

今天我要给大家介绍一下今年做的一个项目:sablejs。项目的部分代码已经上传到了 Github,但 sablejs 1.x 版本的核心代码部分并没有对外公开,具体原因大家可以参考 Github Issues 的 sablejs 2.0 计划。大约明年 2.0 应该会产出稳定版本,到时候会完整放出对应的全部项目代码,但是目前 sablejs 1.x 版本是可用的。
这是我第二次作为讲师参加 GMTC,之前也是在 GMTC 深圳站有聊一些 WebAssembly 的内容,今天的议题其实和之前的议题是有一些关联性的,算是之前议题的进一步落地和思考。当然内容就和 WebAssembly 的关系不是很大了。在业余时间我有做过一些技术专栏文章的编写,同时也参与一些开源项目,大家如果有兴趣的话可以去看一看,然后帮忙点个 Star。
今天的分享我会先讲述一下项目的起因,其次是整个项目我们想达到的目标,接着就是我们在 sablejs 里应用的性能优化的思路和方案,这一块我觉得应该是对大家直接收益最高的部分,最后就是简要阐述一下 sablejs 2.0 的后期规划和开源计划。
我们先从项目背景说起。sablejs 的产生实际上是因为友验人机识别验证码这个产品,人机识别验证码这个产品大家应该都或多或少有相关的了解,如果我们简单的来理解的话,你完全可以把它理解为滑动验证码。目前非常多公司都有提供类似的产品和服务方案,包括且不限于极验、腾讯的防水墙、阿里人机验证、网易的易盾等。
在友验人机识别验证码这个产品里有三块核心的功能,分别是虚拟机保护,设备的特征识别以及 AI 的行为判断。对于设备的特征识别和 AI 的行为判断这两个功能而言,开源社区里有非常成熟的解决方案,例如 Tensorflow。因此使用类似的开源方案然后辅以数据,在我们的实践和落地当中是能够获取到比较精准的识别成功率的。
但对于虚拟机保护而言,特别是针对于 Web 的虚拟机保护,不管是开源还是商用方案都非常的不尽人意。说到这儿可能有人会疑惑,这个产品为什么还需要虚拟机保护这么复杂的东西?让我们看一看产品的执行逻辑,就应该能清晰的知道原因了。
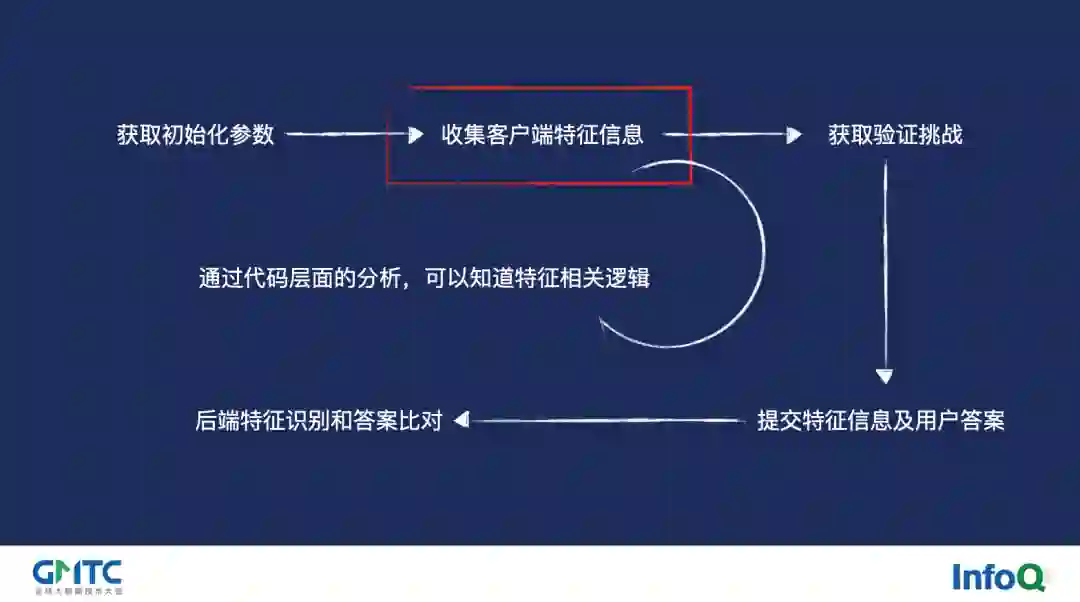
从上图我们可以看到验证的整个流程包含了:获取初始化参数、收集客户端特征信息、获取验证挑战、提交特征信息及用户答案、后端特征识别和答案比对这五个关键步骤。其中最核心的,同时也是最脆弱的部分就是客户端的特征收集。之所以要收集客户端的特征信息,是因为我们要以此来产出一个唯一的设备指纹来定位到唯一用户,以便帮助我们的模型来确认当前用户是否存在行为的异常,及时对恶意请求进行阻断,减少企业的被攻击风险。
但我们也知道 Web 自身是非常开放和包容的,有非常多帮助开发者开发调试的工具,比如 Chrome 的开发者工具。但这也带来了许多问题,其中之一就是,不管我们对代码进行多高强度的混淆,借助开发者工具的帮助我们都可以非常容易的对关键代码进行调试。因此如果想隐藏客户端特征信息的收集逻辑,即使进行了非常复杂的源代码混淆,我们仍然可以较为容易的进行逻辑的调试并且复原原有的代码逻辑。大家有兴趣的话可以去百度或 Google 一下现有人机识别相关产品的破解文章,应该可以看到非常非常多关于此类问题的探讨。
为了解决这个问题,我们就势必需要自行实现虚拟机保护,依靠这种方式大大增加反编译的难度,以此有效达到防恶意调试的目的。
对于 Web 端而言的话,要实现虚拟机保护最简单的方案实际上是通过 WebAssembly。由于 WebAssembly 它本身是完全独立于 JavaScript 引擎的,同时 WebAssembly 完全可以编译执行代码为二进制内容,因此在反调试上是有非常大的优势的。当然,考虑到大部分 Web 的同学更熟悉编写 JavaScript,我们便可以将 quickjs 和 WebAssembly 做一个结合,这样就能够得到一个非常完美的虚拟机保护方案了。
这个其实是我在之前 GMTC 上聊到过的思路,当然这个思路最后催生出了 SecurityWorker 并开源了出来。对于其他厂商而言,比如 Figma,他们也利用了同样的思路并将其用于用户 Web 插件的执行。尽管这两者用途不一样,但殊途同归,彼此的目的都是差不多的。
在整个实现落地的过程中,我们发现实际上 WebAssembly 这套方案也存在着一些问题,最明显的就是 WebAssembly 和 JavaScript 互相调用的安全性问题。究其原因在于 WebAssembly 和 JavaScript 是两套独立的执行环境,因此如果 WebAssembly 涉及到 DOM、BOM 的调用的时候,它务必需要跟 JavaScript 去做一些通信。那 WebAssembly 它是怎么去做通信的呢?答案是 WebAssembly 会直接使用 eval 来执行对应的 JavaScript 代码字符串。
eval 的使用是存在非常大的安全隐患的,因为我们完全有能力在 WebAssembly 执行前对 eval 进行复写拦截,从而获取到里面执行的 JavaScript 代码字符串。那我们怎么去解决这个问题呢?最简单的思路实际上就是我们让所有的相关执行都在同一个执行上下文环境中,这样就不存在通信的过程,也就不会存在此类的问题了。
根据这个思路,因为我们是需要访问 DOM、BOM 的 API 的,同时我们还需要限定在一个执行上下文环境中,那么我们可不可以尝试使用 JavaScript 编写一个 JavaScript 的解释器?参考了 Google Recaptcha 的相关文章后,我们认为这种思路是完全行得通的,同时开源社区也给出了非常多类似的实现,包括像 eval5、sval、sandboxjs...... 当然,他们也存在非常多的问题需要改进。
如果这么做,第一个我们就会面对的问题便是:解释器的性能。由于 JavaScript 自身是非常灵活,即使我们拥有了 V8 这样的底层执行引擎,从直觉上要基于 JavaScript 写出一个性能尚可的 JavaScript 解释器也会是个不小的挑战,这从各类开源实现的 benchmark 分数也可以得知。其次,目前所有能找到的相关开源实现都比较简陋,主要目的是供学习参考,自身并没有对 test262 的单测进行覆盖率的测试,用在实际生产中是存在比较大的风险的。
与此同时,我们也调研了一些商业公司的相关类似实现,其中包括腾讯以及字节。从调研结果上来看,他们的实现对于这块性能的优化也还是有很长的路需要走。除此之外,其 VM 实现的初始化耗时过长也是在实际生产中比较致命的一点。
那 VM 的执行性能差会造成什么问题呢?回到我们的业务场景中,我们知道友验实际上是需要获取到客户端的相关信息,然后使用这些相关信息生成一个唯一的设备指纹,并在本地进行相关的加密操作后传递给后端进行保存。如果你的 VM 执行性能太差,那么对于加密这种重计算的场景而言是没办法在 VM 内部执行的,因此我们便会将相关逻辑移动到 VM 外部,由 VM 去调用。由于相关加密逻辑在外部,我们通过开发者工具就能比较容易定位到相关代码区域,然后通过某些手段我们就能获取到待加密的客户端相关信息。所以如果你有逛看雪之类的安全论坛,你会看到非常多相关的破解教程,其思路大都会以此手段作为突破口。另外,VM 初始化时间链路过长也会牺牲掉使用方的首屏性能,导致使用方的页面性能过低。
基于以上一系列原因,考虑到开源及商用方案都存在许多不符合我们使用场景的问题,因此我们自行编写了一套全新的、尽可能符合规范的、相比而言性能更为出色的实现:sablejs。
sablejs 的目标其实非常简单,就是想成为一个更快更安全的 JavaScript In JavaScript 实现。目前它实际上有三个用途:
Web 的执行沙盒;
小程序和小游戏的动态执行;
Web 端的 JavaScript 的代码保护;
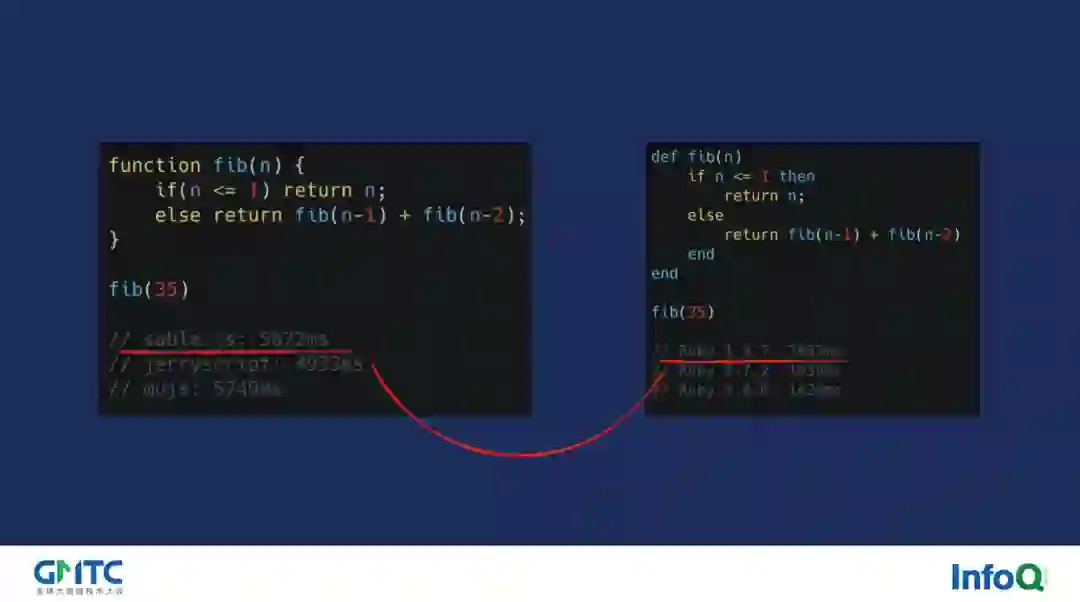
当然性能快与不快我们不能口说无凭,因此在这里我给大家一些数据用来比较直观的感受 sablejs 的性能。第一个例子很简单,我们通过 fibonacci 来小小的测试一下。通过结果大家可以发现,sablejs 相对于 JerryScript 等使用 C 编写的嵌入式 JavaScript 引擎的 WebAssembly 版本而言,其执行性能是非常接近的。同时相比于 Ruby 1.8.7 来说,sablejs 的性能还略胜一筹。当然,这个测试过于简单,我们需要更符合实际生产的例子,这样才更具有说服力。
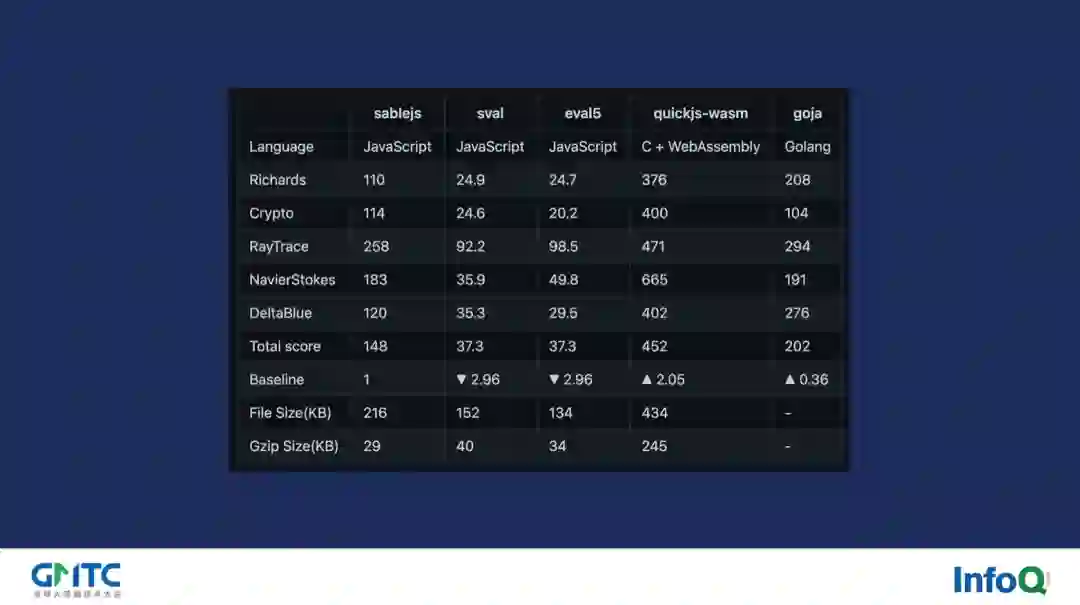
在这里我们选用了同 quickjs 一样的 V8 Benchmark Suits 来进行测试,当然这里面我们剔除了对于 GC 部分的测试,只对 CPU 相关的计算性能和语言特性实现做评分。大家其实从这个表上可以看得到,sablejs 相比于 sval 以及 eval5 这样的同类型实现是快非常多的。同时,相比于 quickjs 的 WebAssembly 版本而言,sablejs 毫不逊色,也仅仅慢 2 倍的样子。对比于 goja 这样的 golang 的 native 实现,sablejs 仅仅慢 36%!
从上面的结果我们可以得知,sablejs 在性能上是完全可以用于生产之中的。当然,上面的测试仅针对于 sablejs 的 1.0.6 版本,对于下一个版本 2.0 版本来说,我们将会有更大的性能提升,这块在最后会谈到。
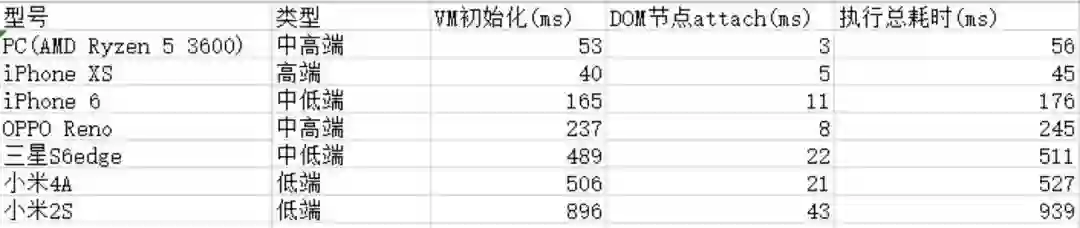
那么除了执行性能外,我们同样也需要考虑到 VM 初始化的性能。从表中可以看到,sablejs 在低端机的初始化时间都在 1 秒以下,而对于主流的硬件来说,VM 初始化时间的影响是非常理想的。
那么 sablejs 是如何做到相比于同类实现更高的性能和更低的初始化时间的呢?为了实现这个目标,实际上 sablejs 做了大量的细节的优化,但在本次会议上我们主要介绍三个比较重要的优化:
函数调用开销的消除
编译期的优化(计算操作与作用域)
对象属性的访问优化
需要强调一点,这些优化思路实际上不是自创的,而是从其他语言实现当中学习得到的。所以我们在介绍基本的优化思路之后,也会告知大家其具体的出处,如果大家有兴趣的话可以去搜一下对应具体代码实现。
第一个我们要聊到的是函数调用开销的消除。sablejs 在实现上是基于栈机的,栈机有一个非常典型的执行结构,即一个大循环。这个大循环里面实际上会有一个复杂的 switch-case 的结构,每个 case 分支会代表一个指令的执行。
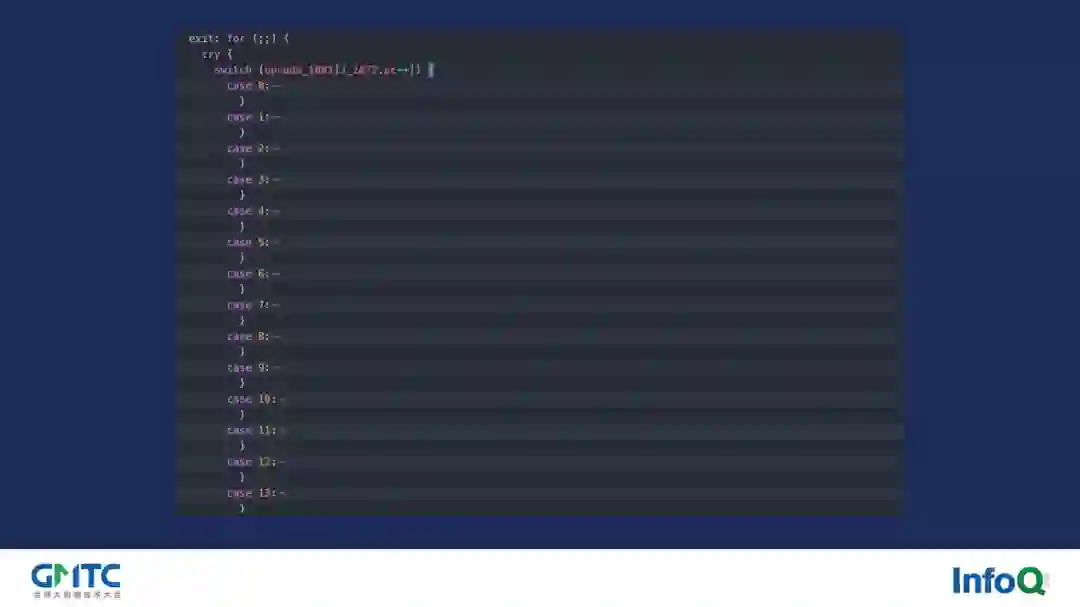
一般这些 case 分支所代表的具体数值我们统称为 opcode,比如上图的 case 0 在 sablejs 里代表的是 pop 指令,case 1 则代表的是 dump 指令...... 我们可以根据需要依次梳理和设计下去。
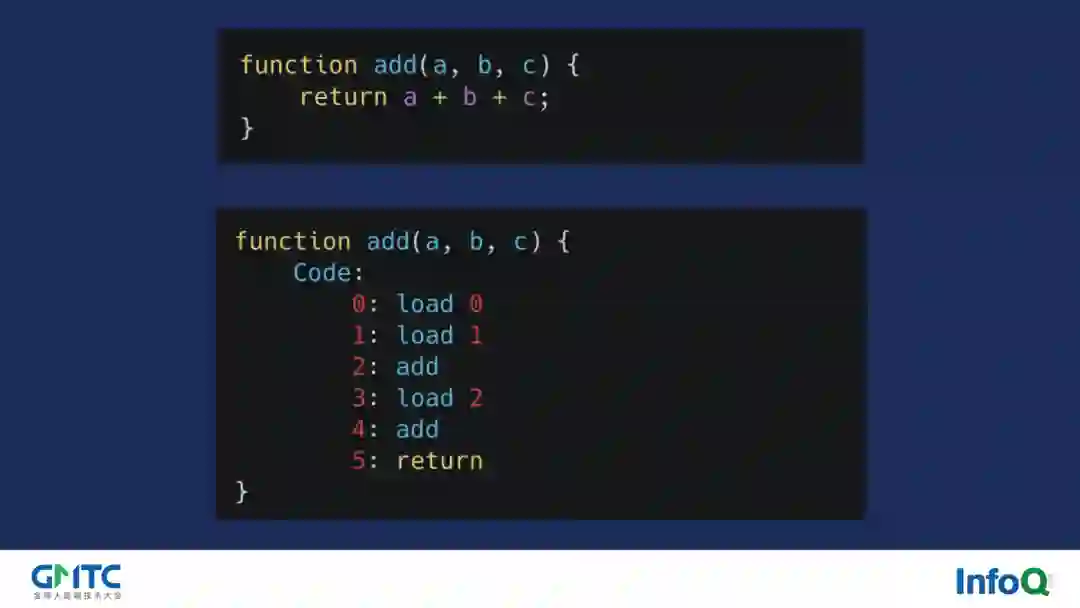
为了方便解释我们用一个简单的 add 函数来进行介绍。如图的 add 函数,如果我们将其转化为 opcode 表示的话,实际上他类似于图中下方所示。load 0 代表将 a 变量压栈,load 1 代表将 b 变量压栈,接着我们调用 add 指令将两者取出相加并将对应结果压栈从而完成 a+b 的操作。然后 load 2 又将 c 变量压栈,然后再次调用 add 指令取出相加并将对应结果压榨,最后 return 指令返回栈顶结果,结束完整个 add 函数的调用。
分支预测大失败
但实际上这么做了之后,如果我们通过 D8 进行 Profiling 就会发现,整个指令执行的部分是存在非常大的性能问题的,究其原因是对于这个部分的分支预测失败率非常高,直接导致了 V8 没有办法对这些指令函数进行 JIT。简单来说,由于 opcode 实际上是线性执行的,因此第一次可能是执行了 pop 指令,接着第二次执行了 dump 指令,但是第三次的时候可能是会通过 jmp 指令跳转到其他地方去执行了其他逻辑,如此反复,V8 是无法统计出你的哪些指令函数是执行比较频繁的,从而无法帮助我们生成高效的 JIT 进而导致性能问题。
如果我们再认真分析一下 Profiling 的结果,我们应该能确切看到大量的指令函数确实未被优化,根本就无法被 JIT 命中。针对这个情况,我们优化的思路自然就变为:我们能不能把频繁执行的函数都内联到整个指令执行大函数中,让 V8 帮我们对整个指令执行的大函数进行 JIT,这样的话对应性能应该会有一个比较大的提升。这种思路如果我们说专业一点的话其被称为 Inline Function,其实 Inline Function 这种做法最核心的作用是用来避免掉函数调用的开销,但在我们的场景里 Inline Function 不仅仅帮助我们解决了 JIT 的问题,同样的也减少了对应函数的调用开销,这是一个两全其美的事。
对于其他语言而言,要进行 Inline Function 这样的操作,最简单的办法就是使用宏,但我们知道 JavaScript 其实是没有这个语言特性的,所以说需要一些其他手段来达成。在这里我们先举一个 sablejs 代码中的例子。比如我们把 ECMA5.1 规范里的 strict equal 操作等价的写为代码,其类似于下面的样子。
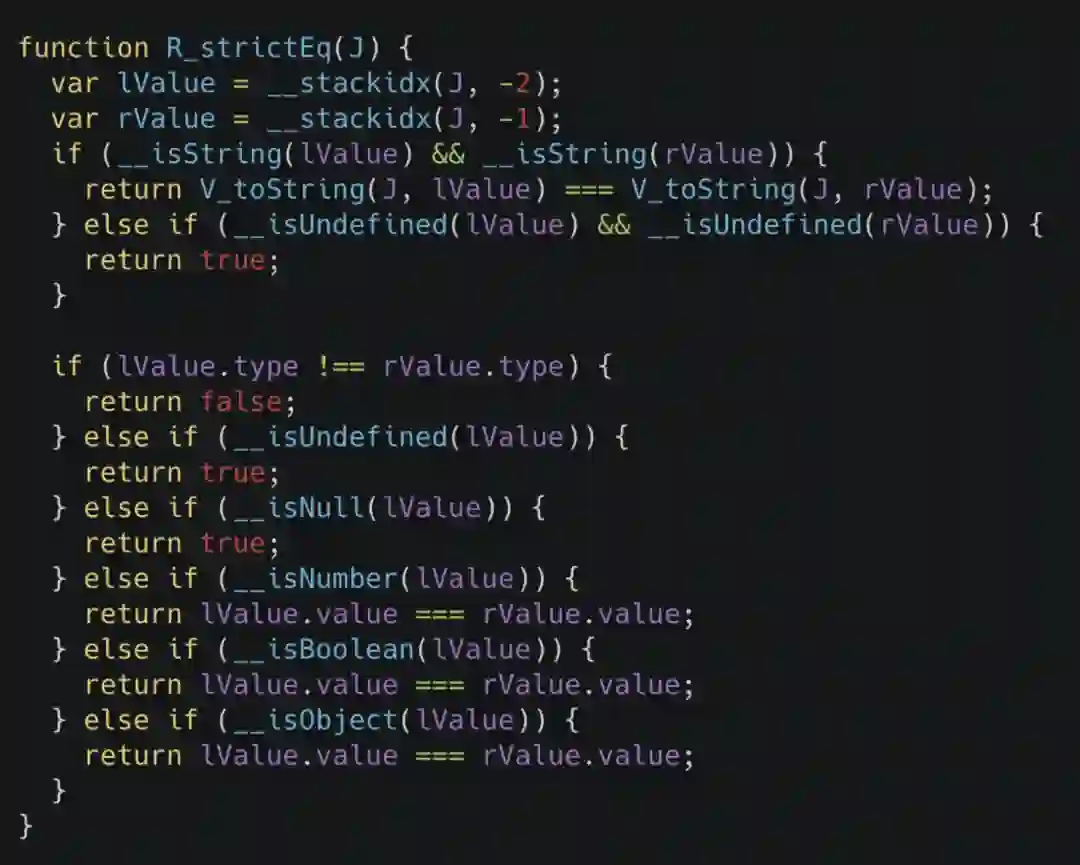
在这里你可以看到有非常多以下划线开头的函数调用,这些函数调用实际上会在整个编译的过程中被展开,如下图所示。
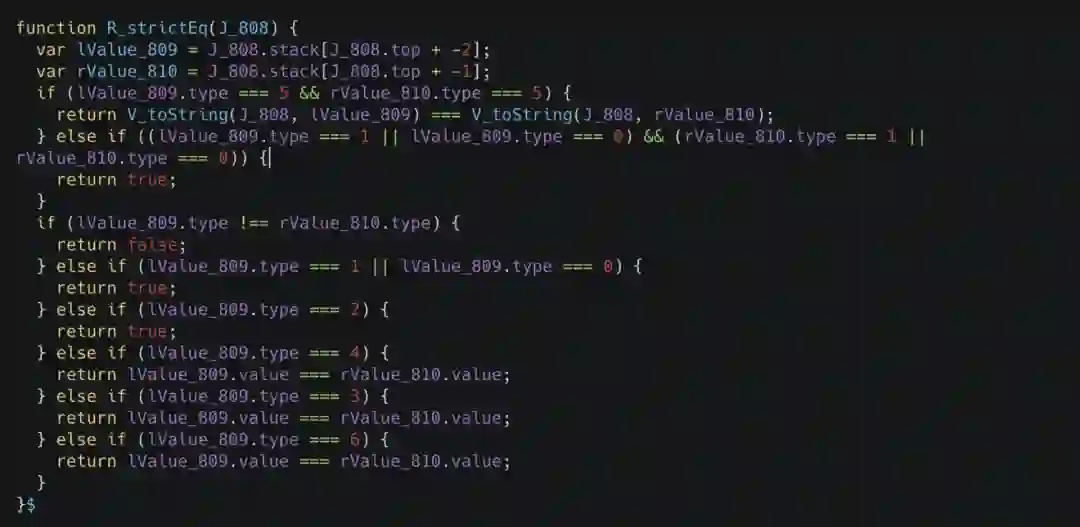
在这里,这些函数看或写起来都是普通的函数,但实际上它们在编译过程中会进行自动的展开,这就是宏的作用。

由于 JavaScript 没有宏这个东西,所以我们去社区找了一个较为成熟的宏的语法扩展:sweet.js。它的使用很简单,例如下图,我们使用 syntax 语法定义了一个 __isArray 函数,在编译过程中,如果你的代码有使用这个宏,那么编译器会把对应的 AST 对象传递给你的宏函数,最终你根据对应的相关信息生成一个语法节点返回给编译器即可执行展开操作。
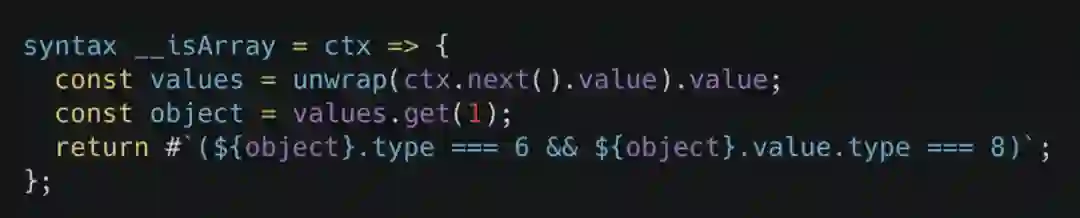
当我们这样做了之后再次 Profiling 发现,指令执行函数的整体性能提升非常明显,对于 V8 Benchmark Suits 而言,甚至达到了 30%-40% 的提升,整个指令执行函数都被 V8 进行了深度的 JIT,效果十分显著!
那函数调用开销的部分就没问题了么?其实我们后续还发现了一个问题,就是函数调用参数不匹配造成的额外开销,如果有兴趣大家可以研读一下这篇文章。

我们简单来说,假设我定义了一个含有三个参数的函数,而当我在调用这个函数的过程中我传入了五个参数,那么在这个情况下会造成什么问题呢?我们知道 JavaScript 非常灵活,如果传入参数不匹配的话,我们可以通过 arguments 来获取到其他参数。但是这种情况实际上是有代价的,因为多余的参数在底层是需要一些包装才能放置在 arguments 中的,因此如果对应函数调用太过频繁,那么这个包装的成本也是非常大的,因此如果要解决这个问题的话,我们仅需要保证参数的匹配即可。
函数开销的消除的相关优化思路均来自于 quickjs。quickjs 通过 C 语言的 #define 来对一些频繁执行的函数进行内联,如果大家有兴趣可以看看相关代码。
第二块我们要聊一下 sablejs 的编译期优化。由于 sablejs 在友验这个场景中是涉及到加密计算的,我们知道加密计算实际上大部分是数值计算,因此这块的优化也是十分重要的。由于 JavaScript 是动态语言,因此在一般的实现当中,我们都会将其作为 Boxed 类型来简化处理。但 Boxed 类型总会不可避免地涉及到拆箱和装箱的过程。在这个过程当中对于性能而言是会有损害的,因此 V8 基于此去引申了一个优化叫做 SMI,翻译过来就是 Small Integer,即小整型数。从下图我们可以看到,如果你的整型数在 2 的 32 次方这个范围内,他就是会被定义为 SMI,但如果超过了或者是浮点数,那么统一都被归纳为 HeapNumber。

那为什么要这么做呢?实际上我们看一下 SMI 和 HeapNumber 在内存当中的布局就可以清楚的知道了,如下图。
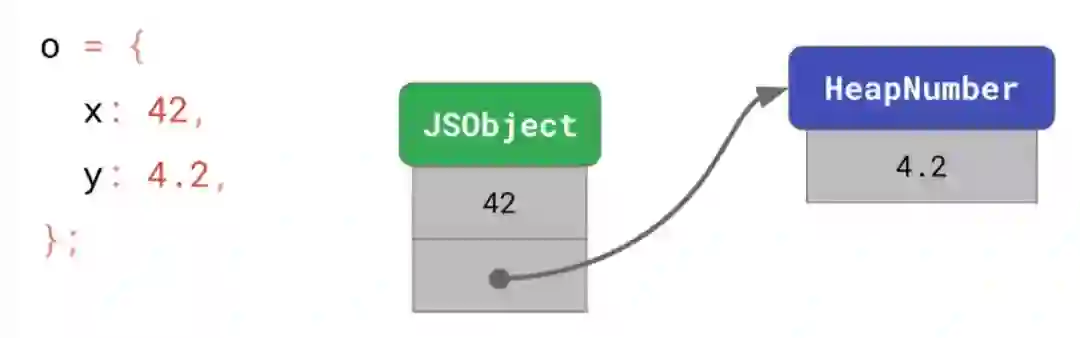
在这里我们可以看到,如果你申明了一个对象,这个对象的某个值为 42,从上面我们可以知道,42 肯定是一个 SMI,因此这个值是直接存放在了内存之中。但如果是个浮点数,比如 4.2,那么这个数实际上会在堆内存上另外开辟一块内存,然后进行这个数值的存放,而在这个对象内部由一个指针进行这块堆内存的访问。
从这里就可以明显感受得到,SMI 访问会更快且内存占用也会更少。除此之外,这样做的另一个原因就在于我们日常开发过程当中经常会涉及到一些小整数,对于这些小整数而言,我们可以使用一些快速整型算法来进行加减乘除等常用操作的性能优化。
那类似的优化思路可不可以拿入到 sablejs 的实现当中呢?结论是不可行。因为 sablejs 是建立在其他的 JavaScript 引擎之上的,因此这类优化都统一由底层引擎帮我们做了,如果我们在 sablejs 实现中再次使用类似的优化反而会造成性能的降低。好似我们陷入了僵局,所以就没办法进行相关的优化了么?让我们回到 ECMA5.1 的规范之中来尝试做一些讨论。
1 + 1;"1" + a;{} + []
可以看到 JavaScript 里的加法操作非常灵活,它可以是两个数值的相加,也可以是字符串的连接,甚至还可以是对象的相加。如果我们按照 ECMA5.1 的规范把相加这个操作实现为代码的话,其实际上如下图所示。
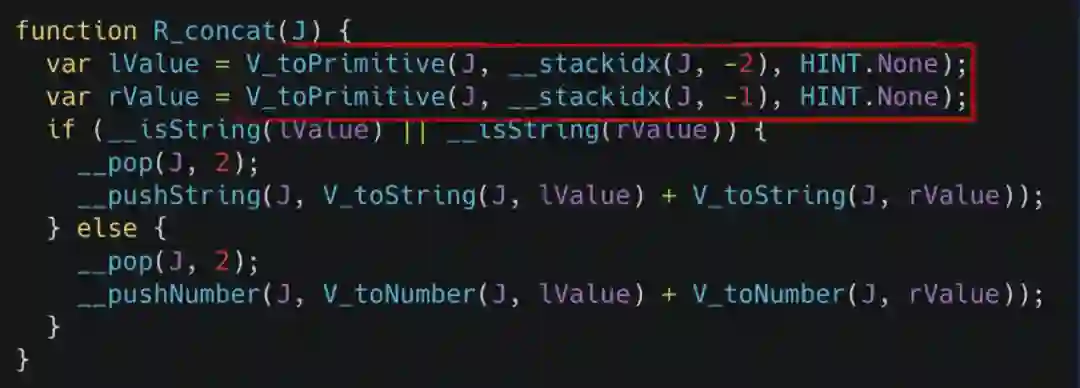
在这个实现里 toPrimitive 函数是其中最为重要也是非常重的一个函数。其内部逻辑简单来说就是它会去判断传入参数的类型,然后决定要不要调用原型上的 toString 以及 valueOf 方法,剩余的逻辑大家可以看到都是比较简单的,因此我们的优化重点就在于如何尽可能少的去调用 toPrimitive 函数。
首先对于 1 + 1 这样的代码而言,由于两边的类型都非常确定,因此在编译的整个过程中我们完全可以将其替换为 2,而不需要在运行时进行计算。这种做法我们叫做 Constant Folding,是编译里非常简单的优化手段。由于编译时已经帮助我们处理了相关逻辑,因此我们完全不需要在运行时执行加法操作的函数,从而性能有了非常多的提升。再来看看"1" + a 这样的代码,其左边类型是固定的,而对于右边而言是一个变量,对于这种情况,我们对于左值是不需要进行 toPrimitive 函数的调用的,同时下方的判断也可以直接被省略掉,直接就可以执行一个字符串的相加操作,这样也提升了运行时的性能,毕竟少做了不少的操作。最后对于{} + [] 这样的代码,那么就没有可优化的空间了,因此它会走完整的逻辑。
为了更好地针对这些 case 做相关的优化,sablejs 的实现中是会单独的为这些情况写独立的规则,其优化思路实际上是来自于 PHP。PHP 自身也会针对于很多 case 单独做相关的优化,然后依靠一个小的编译工具去产出一个 C 文件供自身使用,从而来达到性能提升的目的。
接着我们要简单讲讲关于作用域的优化,需要注意的一点是关于这块的优化每种实现都不一致,所以可能你在 V8 上不会发现任何区别,但在其他引擎上就会出现比较大的性能差距,这里我们主要拿 quickjs 来作为例子,让我们来看下方的代码示例。
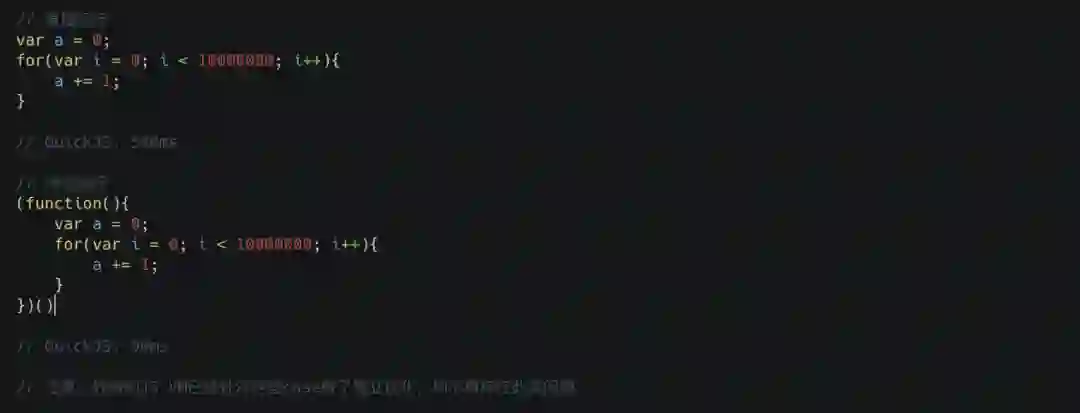
这个示例代码非常简单,就是循环执行 1 千万次的加法操作。从上面的结果我们可以看到,第一种直接运行方式耗时 540 毫秒,但是如果我们加一层 IIFE 那么它就立马降低到了 90 毫秒,这是为什么呢?
我们知道 JavaScript 实际上是有一个叫做作用域链的概念,像上面的代码,当我要去访问变量时它是根据当前作用域链来进行查找的,这个查找的过程实际上非常的耗时,因为我们通常会将作用域链抽象成一个一个嵌套的 Scope 的对象,对象访问是需要依靠 Hash 来获取 key 对应值,整个过程是比较慢的。但下面的 IIFE 版本实际上变量的访问是不走作用域链查找的,而是直接访问了栈,我们知道栈的一般实现会使用数组,因此的话访问非常快速,这就是为什么下面性能快那么多的原因。
在这一块 sablejs 也会做类似的优化,在内部我们实际上对于函数有一个 lightable 的标识,如果这个函数没有访问函数作用域外的变量,也没有使用到 arguments 等操作时,sablejs 会尽可能的把对应的变量分配在栈上面,这个时候我们就称这个函数是 lightable 的,从而性能得到提升。
这块优化实际上大量参考了 Lua 和 mruby 的实现,他们内部对于外部变量引用统称为 upval,如果大家感兴趣可以去看看相关实现。
最后我们要说的是对象属性的访问。实际上做了上面的诸多优化后 sablejs 的性能已经相比其他同类实现高很多了,但是在测试过程中我们也发现对于对象属性访问这块的性能实际上是非常差的,同时这块又是非常常用的语法,所以我们势必需要对其做一些优化。这块实际上是使用 Inline Cache 来进行优化的,网上已经有非常多的文章介绍了,我们由于时间关系就不说细节了,我们简单说说它的想法。
网上的文章讲述 Inline Cache 非常复杂,涉及到了 Hidden Class、编译及运行期的 Stub 替换等等逻辑,但实际上如果你抛开那些复杂的数据结构和执行细节的话,它的优化思路实际上非常简单且直接的。
访问一个对象实例的属性这个操作在 ECMA5.1 的规范里是非常非常复杂的,就像下图一样,你要执行很大一圈之后才能获得一个值。但如果我们对象属性从来都没有变化的话,每次访问都进行这么一次完整操作就太不合算了,因此直觉告诉我们应该进行缓存。实际上 Inline Cache 就是缓存的思路,只是说它依靠的是 Hidden Class 以及编译及运行期的 Stub 替换等手段来达到缓存的性能提升目的。
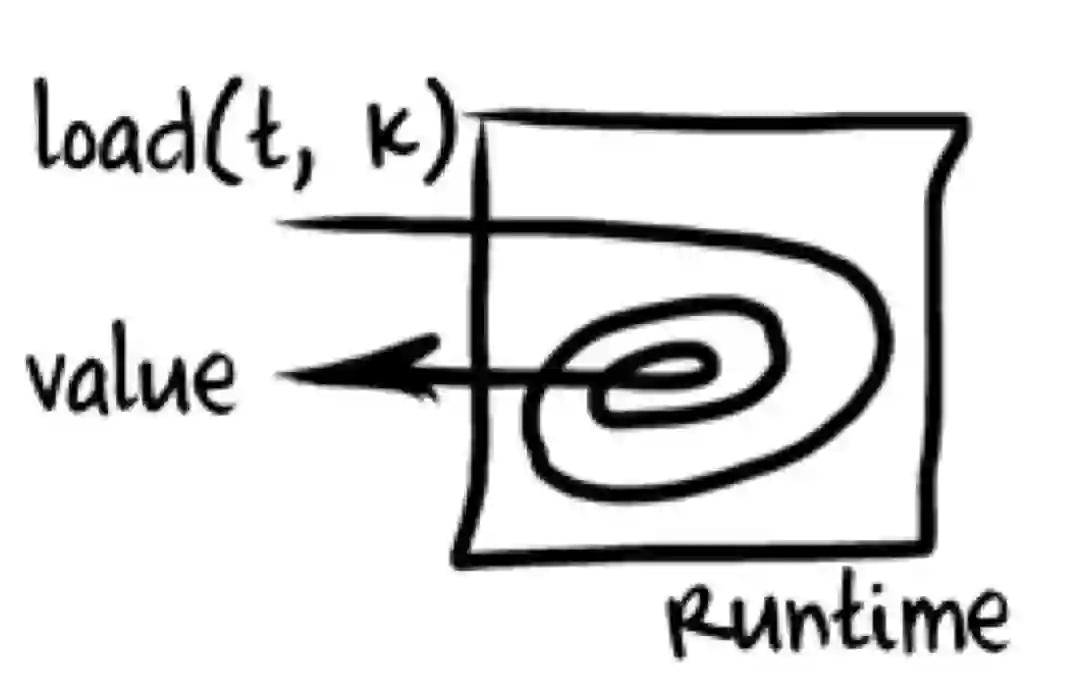
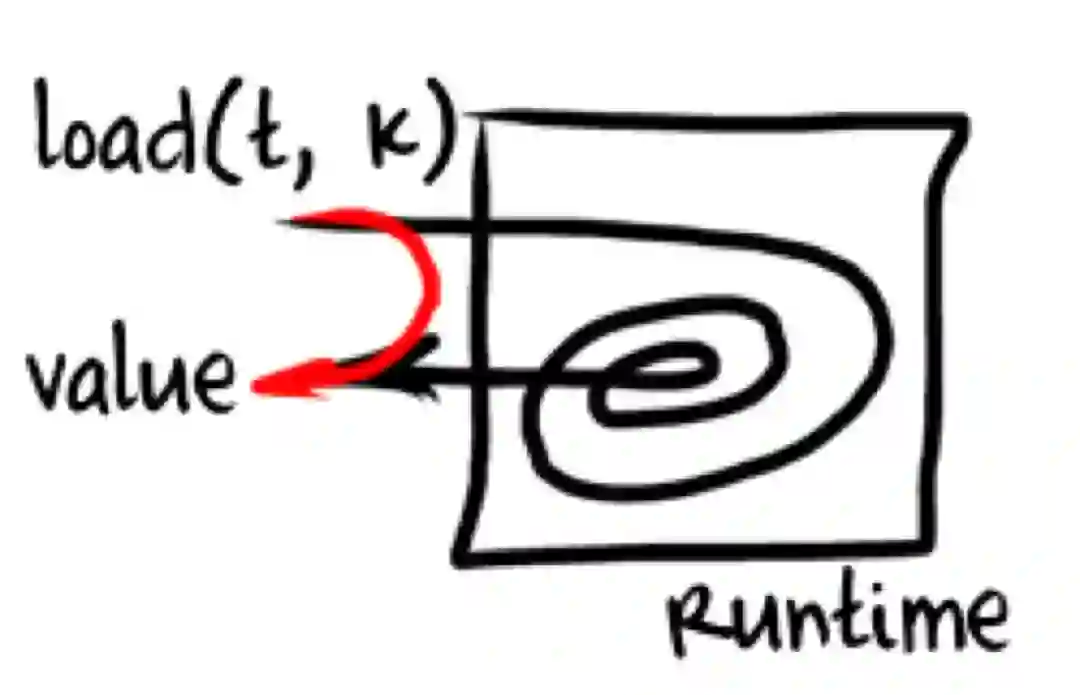
sablejs 内部只是针对了很少的场景做了 Inline Cache,因为 Inline Cache 的实现还是比较麻烦的,如果要尽可能覆盖所有 case 的话需要花不少时间。与此同时由于 sablejs 最开始只是写给我们自己用,因此我们就只是针对我们常用的 case 进行了 Inline Cache 的优化。但整体优化的效果还是很明显的,在频繁变量属性访问的场景下,其可以帮助我们从原有 700 多毫秒的耗时降低到 100 多毫秒,这非常惊人!
Inline Cache 的具体思路和部分实现均借鉴了 V8。当然,使用 JavaScript 实现这部分内容会有一些区别,但总体上的做法是差异不大的。
最后的最后我们要说一说 sablejs 后续的规划:sablejs 2.0。2.0 的目标主要分为两块,一块是性能的继续的提升,一块是内部模块动态加载。由于现在 2.0 的完成度还非常低,因此完整的 V8 Benchmark Suits 是没有办法跑起来的,为了展示一下 sablejs 2.0 的性能提升效果,我们用一个下面的简单例子来说明。

像这个一千万次的加法测试,大家可以发现 2.0 版本相比于 1.0.6 版本快 2 倍多,同时相比于 quickjs 的 WebAssembly 版本只慢了 17.39%,整个性能的提升是非常让人兴奋的。那怎么达到的呢?实际上也很简单,回到我们最开始的时候关于栈机的部分,从下图我们可以看到,栈机的实现都会有一个经典的 switch-case 结构,并且通过上面的介绍我们也知道,这个大循环里的 switch-case 是非常影响分支判断的,那么如果要在我们上述优化方案的基础上再进行优化,那唯一的思路就是:取消掉整个大循环里及其 switch-case。

如何去做呢?实际上就是把对应的语句直接翻译为栈操作,然后让 V8 帮助我们去 JIT 每一个函数,它的整个过程如下图所示。
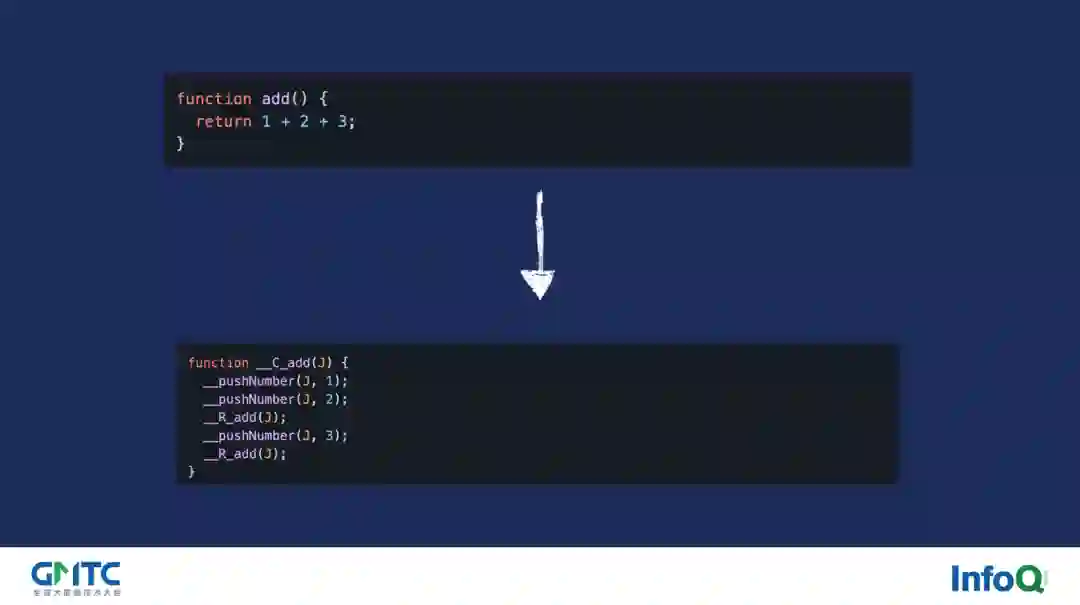
比如针对 add 函数而言,我们可以看到最终其内部的相关操作都被直接编译为了我们的栈操作对应的 _pushNumber _R_ad 等函数,这些栈函数是由运行时去提供的。这样一番操作后再经过各项宏的展开,其也能达到难以调试的目的,与此同时性能的提升也非常巨大。
对于这块的实现和想法来自于一个 JavaScript 的 JVM 实验性项目:DoppioJVM,它们使用了类似的思路来优化其自身的性能,在他们的测试中,针对于 CPU 密集计算的场景而言总体会有 4 倍左右的提升,非常让人惊叹。
这就是我今天分享的所有内容,谢谢大家。
本文由 InfoQ 整理自 sablejs 作者赵洋在 GMTC 全球大前端技术大会(深圳站)2021 上的演讲《Inside sablejs——打造更快更安全的 JavaScript 实现》。
作者简介:
赵洋,曾任百度、腾讯、全民直播前端工程师,Modern Web/GMTC/GIAC/FDCon 等多个会议讲师,《深入浅出 SSR 服务》《WebAssembly 实践》等多个专栏文章作者,同时也是 WXInlinePlayer、SecurityWorker、Sable.js 等多个开源项目的作者及代码贡献者,对 WebAssembly 及 Compiler 等领域有诸多的实践和业务落地。
Nginx之父突然离职,程序员巅峰一代落幕
微软壕掷 687 亿美元买动视暴“乱”:你激动个啥?
华为也为Rust“狂”:揭秘国内唯一Rust基金会创始成员背后的人与事
市值超 1.7 万亿的Netflix是如何做决策的?
《中国卓越技术团队访谈录》是 InfoQ 打造的重磅内容产品,为了能进一步了解读者的实际需求和喜好,持续为大家生产有价值、具备启发性的内容,我们发起了本次调查,真诚邀请广大社区读者参与问卷。同时,如果你希望 InfoQ 关注并采访你所在的技术团队,也可以通过本问卷报名,报名选项在问卷底部。
点击【阅读原文】,即刻参与有奖问卷调查,还有机会获得精美礼品。
如对本次调研有任何疑问或建议,欢迎联系微信 13512772438。

点个在看少个 bug 👇



