28篇论文、6 大主题带你一览 CVPR 2020 研究趋势

编译 | 陈大鑫
编辑 | 丛 末
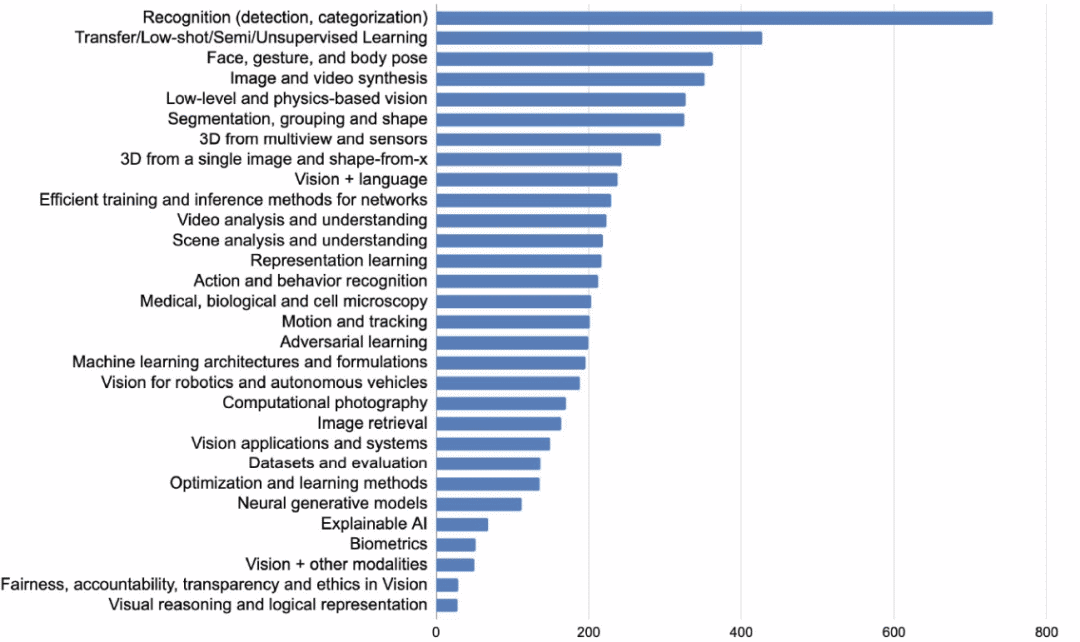
图像识别,检测和分割
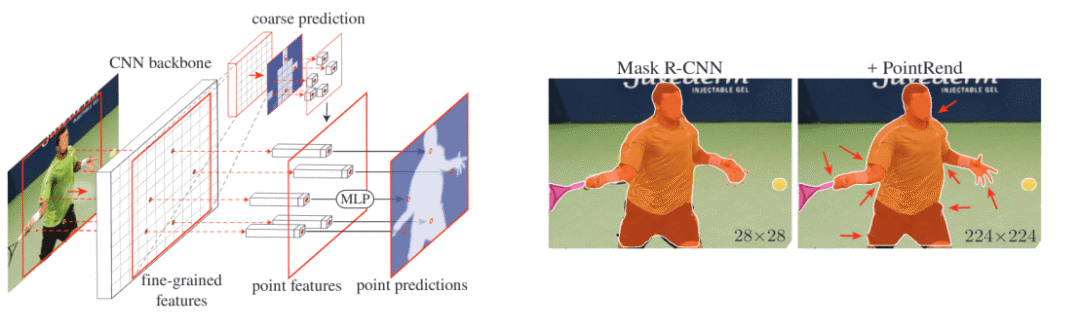
PointRend:将图像分割作为渲染
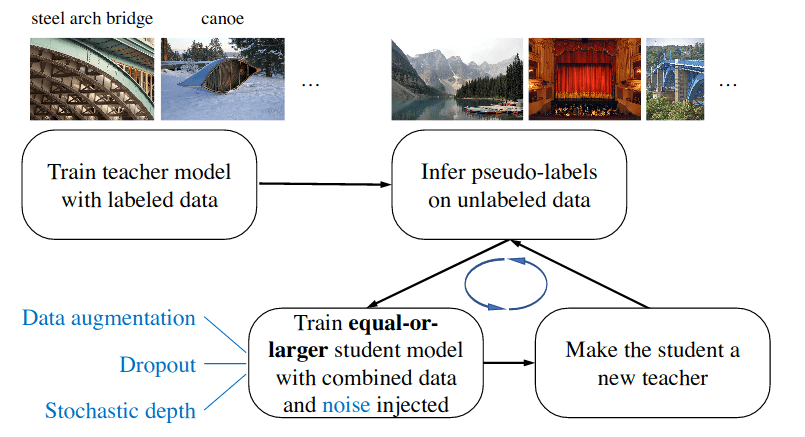
带有噪声的自训练Student改善ImageNet分类
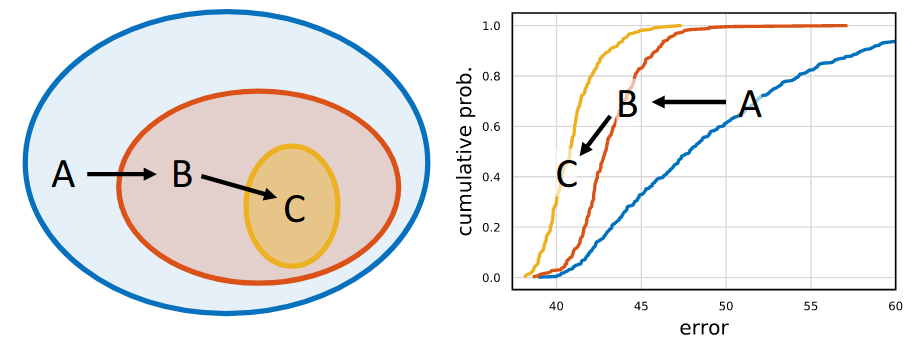
设计网络设计空间
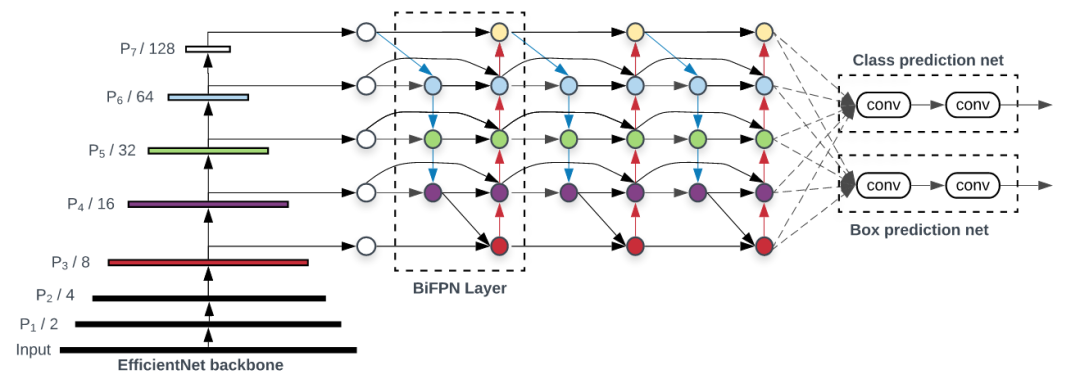
EfficientDet:可扩展且高效的目标检测
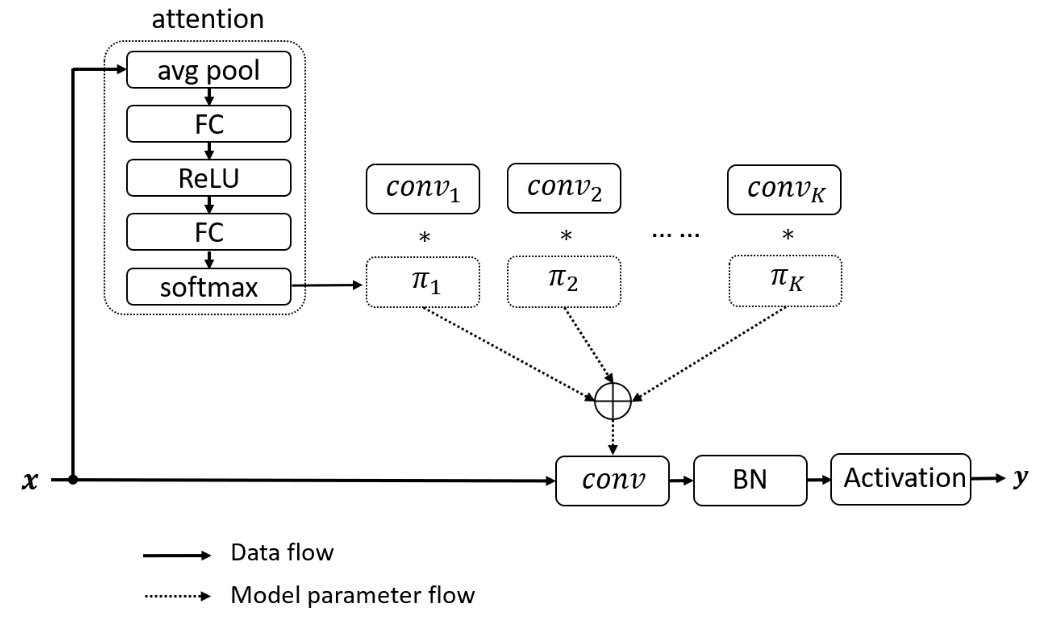
动态卷积:卷积核上的注意力
其他论文:
Deep Snake for Real-Time Instance Segmentation,https://arxiv.org/abs/2001.01629
Exploring Self-attention for Image Recognition, https://arxiv.org/abs/2004.13621
Bridging the Gap Between Anchor-based and Anchor-free Detection ,https://arxiv.org/abs/1912.02424
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization,https://arxiv.org/abs/1912.05027
Look-into-Object: Self-supervised Structure Modeling for Object Recognition,https://arxiv.org/abs/2003.14142
Learning to Cluster Faces via Confidence and Connectivity Estimation,https://arxiv.org/abs/2004.00445
PADS: Policy-Adapted Sampling for Visual Similarity Learning,https://arxiv.org/abs/2001.00309
Evaluating Weakly Supervised Object Localization Methods Right,https://arxiv.org/abs/2001.00309
BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation,https://arxiv.org/abs/2001.00309
Hyperbolic Visual Embedding Learning for Zero-Shot Recognition,http://openaccess.thecvf.com/content_CVPR_2020/papers/Liu_Hyperbolic_Visual_Embedding_Learning_for_Zero-Shot_Recognition_CVPR_2020_paper.pdf
Single-Stage Semantic Segmentation from Image Labels,https://arxiv.org/abs/2005.08104
2
生成模型和图像合成
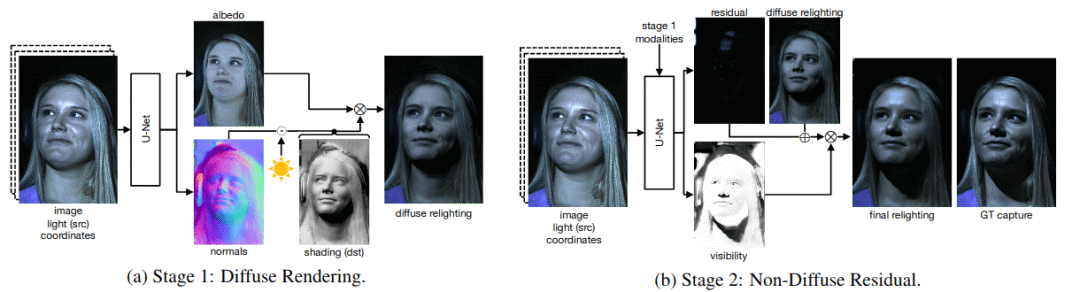
在定向光下学习物理引导的面部重照明
SynSin:从单个图像进行端到端视图合成

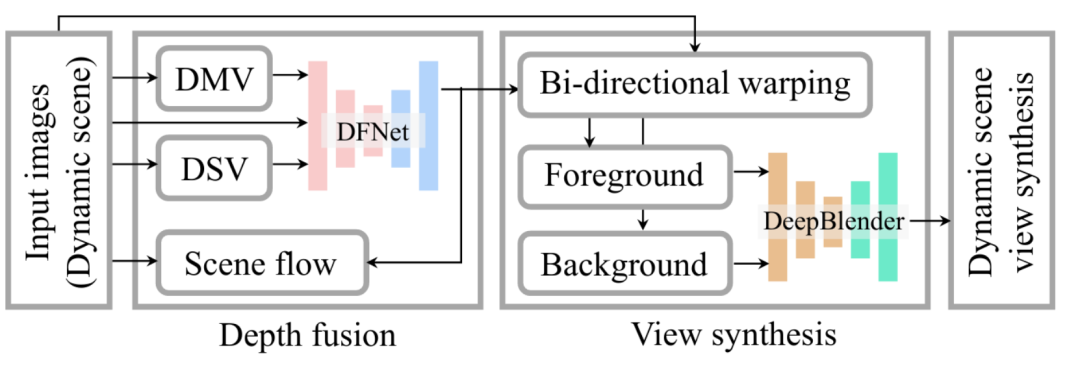
从单反相机合成全局相干深度的动态场景新视图

STEFANN:使用字体自适应神经网络的场景文本编辑器

MixNMatch:用于条件图像生成的多因子分离和编码

StarGAN v2:多域的多样化图像合成
论文地址:https://arxiv.org/abs/1912.01865
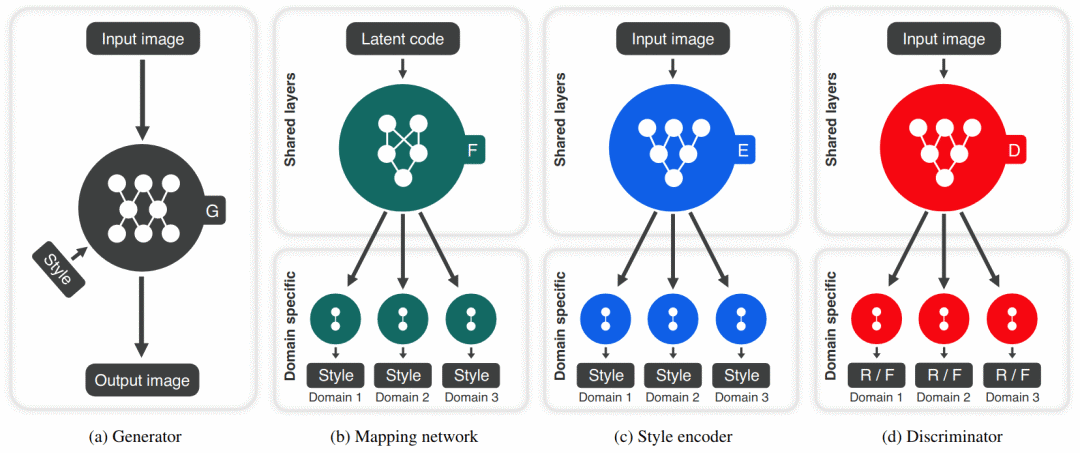
-
生成器,用于使用所需特定域的风格代码将输入图像转换为输出图像。 -
潜在编码器(或映射网络),为每个域生成风格代码,在训练过程中随机选择其中一个。 -
风格编码器可提取图像的风格代码,以允许生成器执行参考引导的图像合成 -
判别器可从多个域中区分真假(R / F)图像。
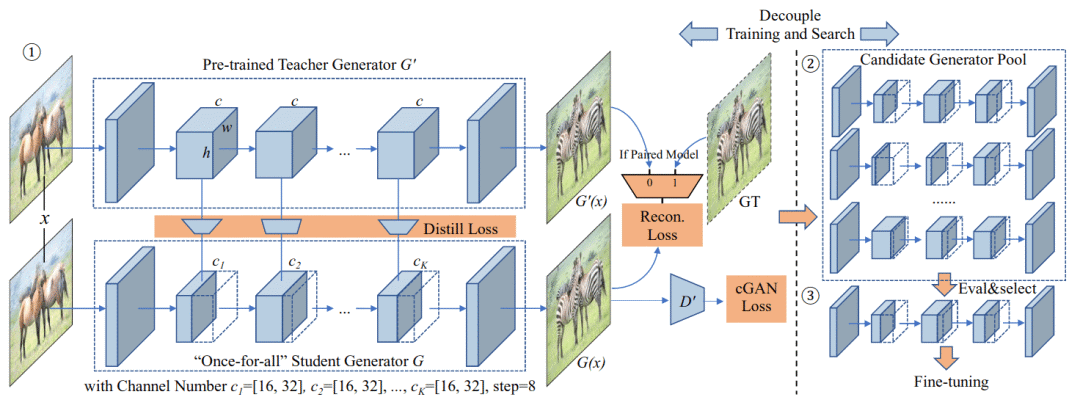
GAN压缩:交互式条件GAN的高效架构
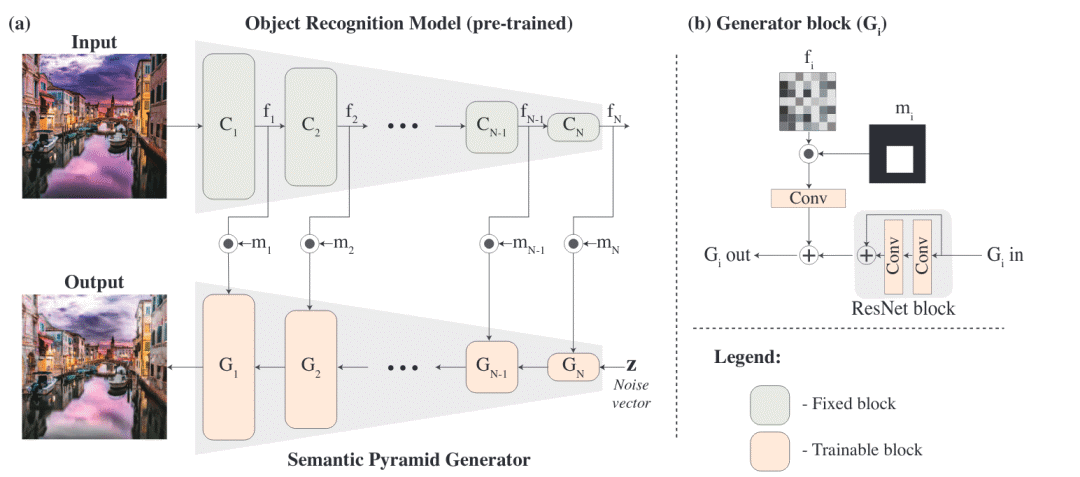
用于图像生成的语义金字塔
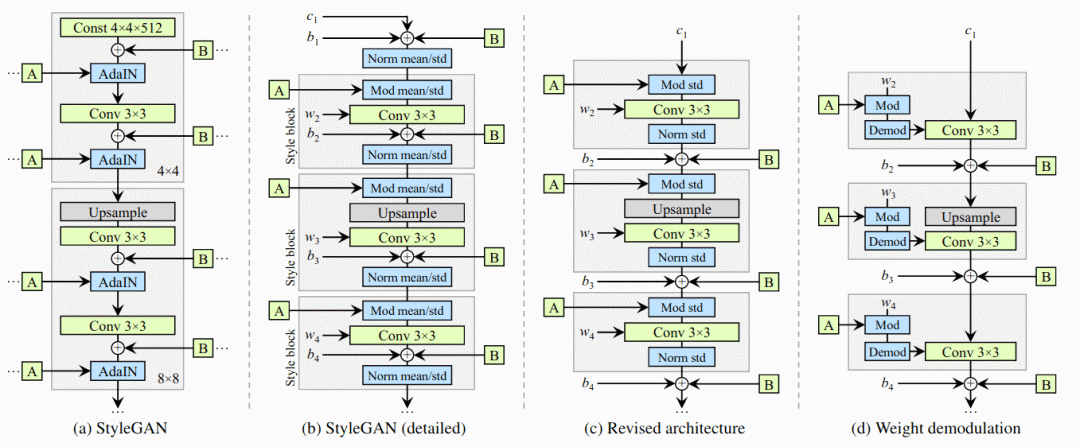
分析和改善StyleGAN的图像质量
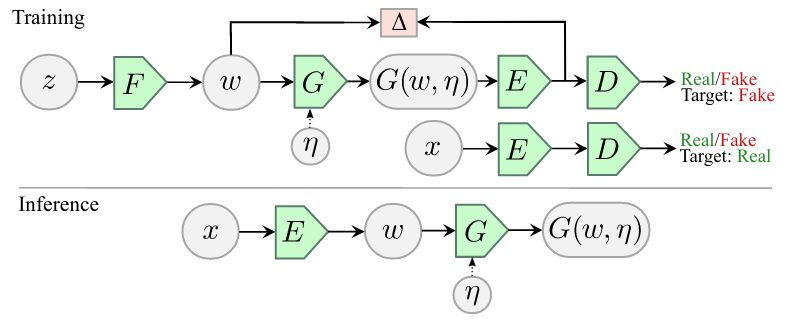
对抗性潜在自动编码器
其他论文:
Interpreting the Latent Space of GANs for Semantic Face Editing,https://arxiv.org/abs/1907.10786
MaskGAN: Towards Diverse and Interactive Facial Image Manipulation,https://arxiv.org/abs/1907.11922
Semantically Multi-modal Image Synthesis,https://arxiv.org/abs/2003.12697
TransMoMo: Invariance-Driven Unsupervised Video Motion Retargeting,https://arxiv.org/abs/2003.14401
Learning to Shadow Hand-drawn Sketches,https://arxiv.org/abs/2002.11812
Wish You Were Here: Context-Aware Human Generation,https://arxiv.org/abs/2005.10663
Disentangled Image Generation Through Structured Noise Injection,https://arxiv.org/abs/2004.12411
MSG-GAN: Multi-Scale Gradients for Generative Adversarial Networks,https://arxiv.org/abs/1903.06048
PatchVAE: Learning Local Latent Codes for Recognition,https://arxiv.org/abs/2004.03623
Diverse Image Generation via Self-Conditioned GANs,https://arxiv.org/abs/1912.05237
Towards Unsupervised Learning of Generative Models for 3D Controllable Image Synthesis,https://arxiv.org/abs/1912.05237
3
表征学习
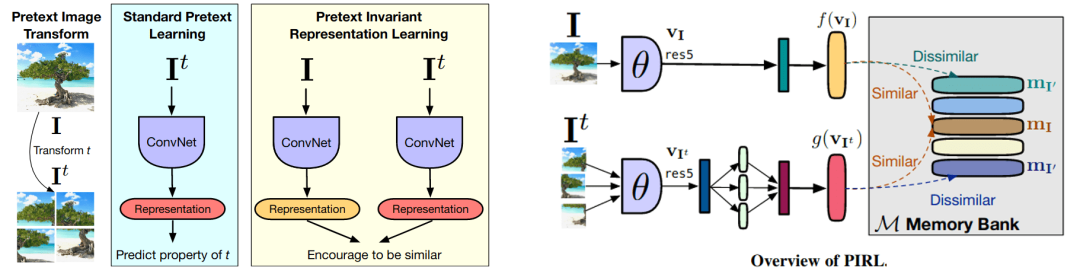
自监督学习的上下文不变表征学习
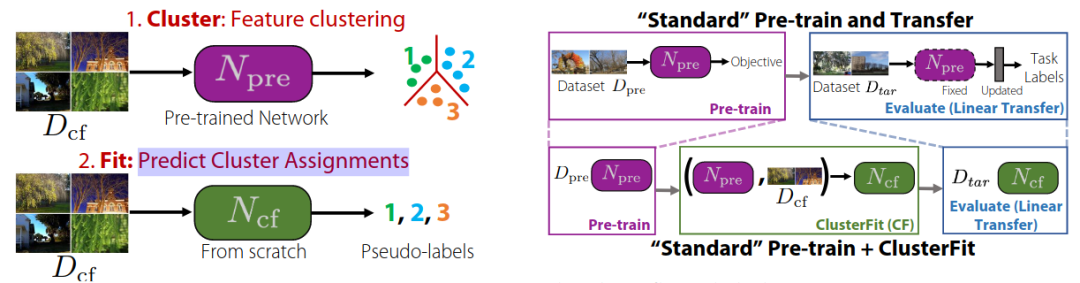
ClusterFit:改进视觉表示的泛化能力
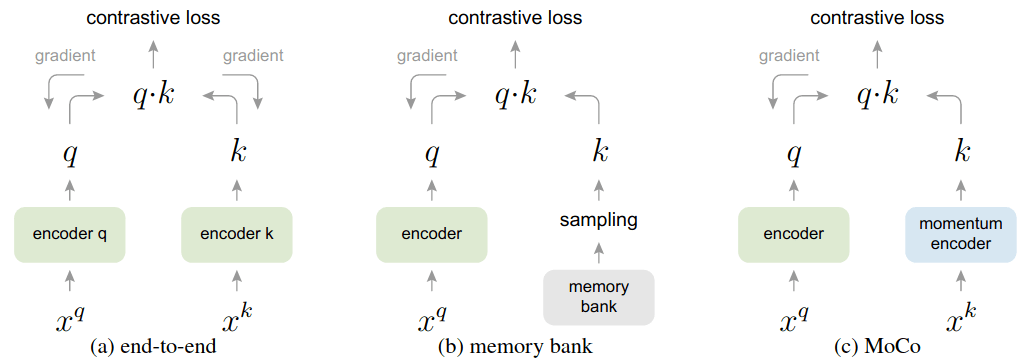
用于无监督视觉表征学习的动量对比
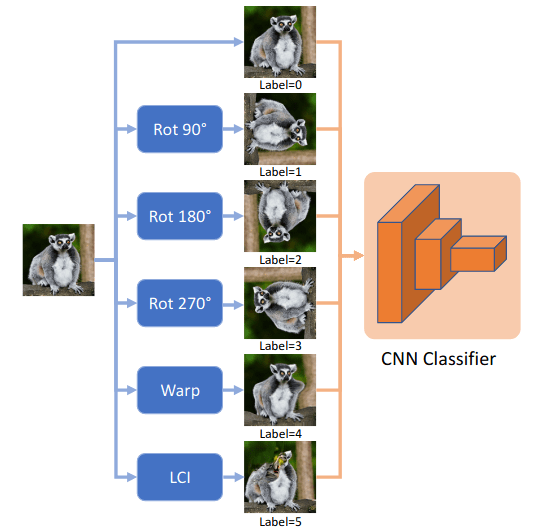
指导超越局部像素统计的自监督特征学习
其他论文:
Self-Supervised Learning of Video-Induced Visual Invariances,https://arxiv.org/abs/1912.02783
Circle Loss: A Unified Perspective of Pair Similarity Optimization,https://arxiv.org/pdf/2002.10857.pdf
Learning Representations by Predicting Bags of Visual Words,https://arxiv.org/abs/2002.12247
4
计算摄影
学会看透障碍物

背景抠图:世界是你的绿幕

使用上下文相关的分层深度修补进行3D摄影

脉冲:通过生成模型的潜在空间探索进行自监督的照片上采样
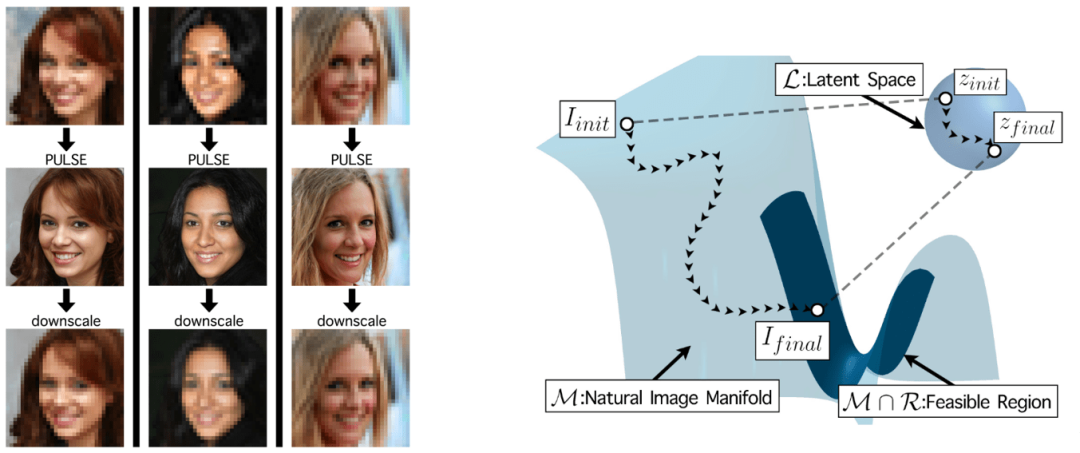
其他论文:
Learning to Autofocus,https://arxiv.org/abs/2003.08367
Lighthouse: Predicting Lighting Volumes for Spatially-Coherent Illumination,https://arxiv.org/abs/2003.08367
Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resolution,https://arxiv.org/abs/2002.11616
Explorable Super Resolution,https://arxiv.org/abs/1912.01839
Deep Optics for Single-shot High-dynamic-range Imaging,https://arxiv.org/abs/1908.00620
-
Seeing the World in a Bag of Chips,https://arxiv.org/abs/2001.04642
5
迁移/小样本/半监督/无监督学习
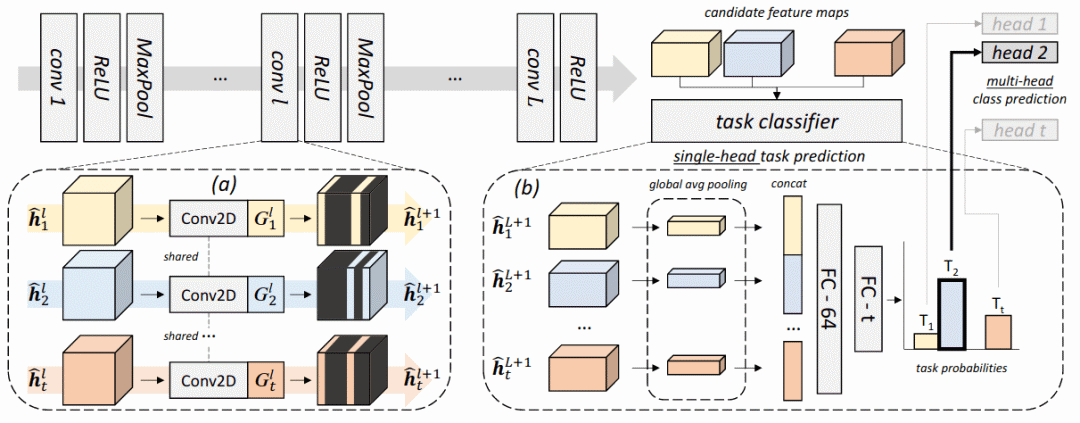
用于任务感知的持续学习的条件通道门控网络
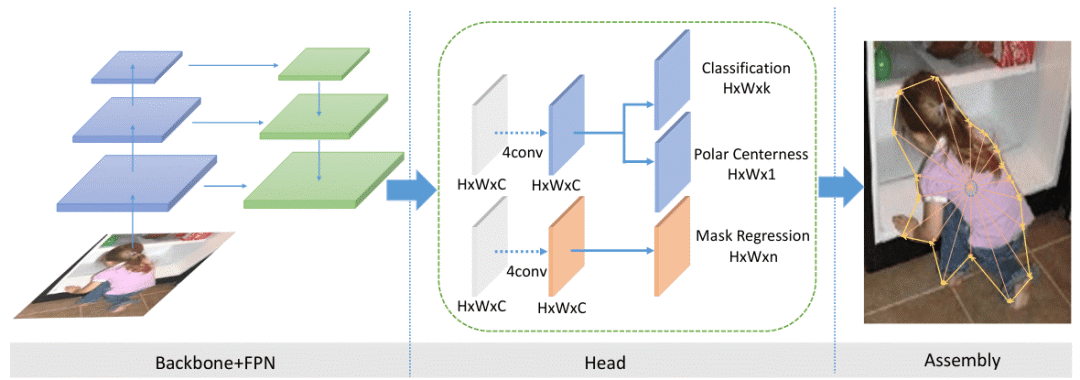
PolarMask:具有极坐标表示的单镜头实例分割
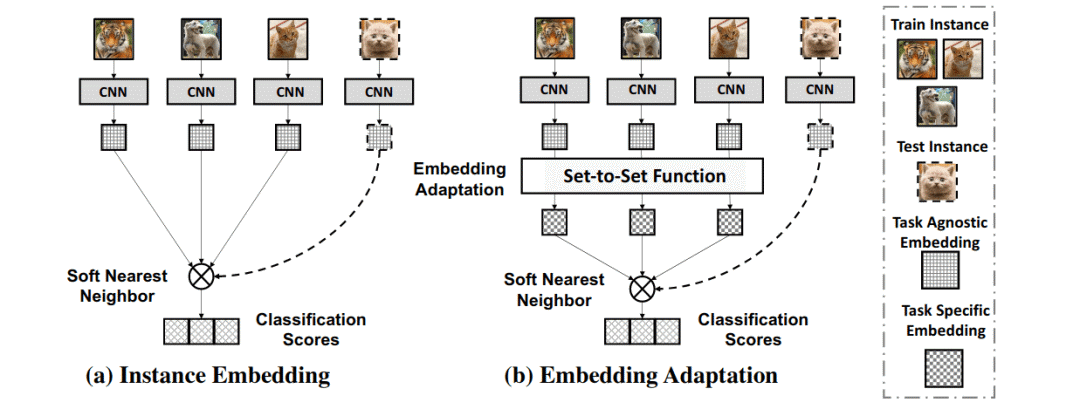
通过嵌入自适应与设置到设置的功能进行小样本(Few-Shot)学习
迈向可分辨性和多样性:标签不足情况下的批量神经核范数最大化
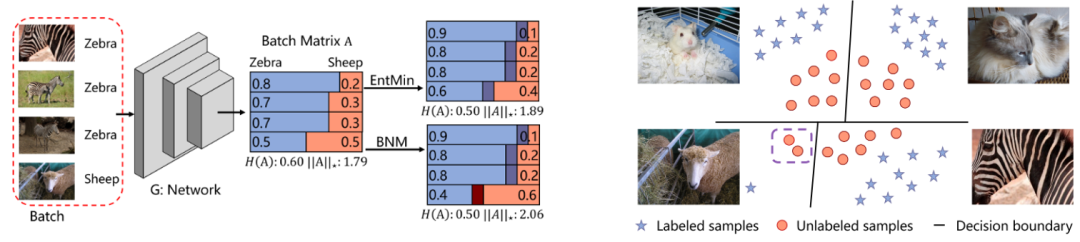
其他论文:
-
Distilling Effective Supervision from Severe Label Noise,https://arxiv.org/abs/1910.00701 -
Mask Encoding for Single Shot Instance Segmentation,https://arxiv.org/abs/2003.11712 -
WCP: Worst-Case Perturbations for Semi-Supervised Deep Learning,http://www.eecs.ucf.edu/~gqi/publications/CVPR2020_WCP.pdf -
Meta-Learning of Neural Architectures for Few-Shot Learning,https://arxiv.org/abs/1911.11090 -
Towards Inheritable Models for Open-Set Domain Adaptation,https://arxiv.org/abs/1911.11090 -
Open Compound Domain Adaptation,https://arxiv.org/abs/1909.03403
6
视觉与语言
12合1:多任务视觉和语言表示学习

其他论文:
-
Sign Language Transformers: Joint End-to-End Sign Language Recognition and Translation,https://arxiv.org/abs/2003.13830 -
Counterfactual Vision and Language Learning,http://openaccess.thecvf.com/content_CVPR_2020/papers/Abbasnejad_Counterfactual_Vision_and_Language_Learning_CVPR_2020_paper.pdf -
Iterative Context-Aware Graph Inference for Visual Dialog,https://arxiv.org/abs/2004.02194 -
Meshed-Memory Transformer for Image Captioning,https://arxiv.org/abs/1912.08226 -
Visual Grounding in Video for Unsupervised Word Translation,https://arxiv.org/abs/2003.05078 -
PhraseCut: Language-Based Image Segmentation in the Wild,https://people.cs.umass.edu/~smaji/papers/phrasecut+supp-cvpr20.pdf





