阿里云RemoteShuffleService新功能:AQE和流控

一 RSS支持AQE
1 AQE简介
Partition合并
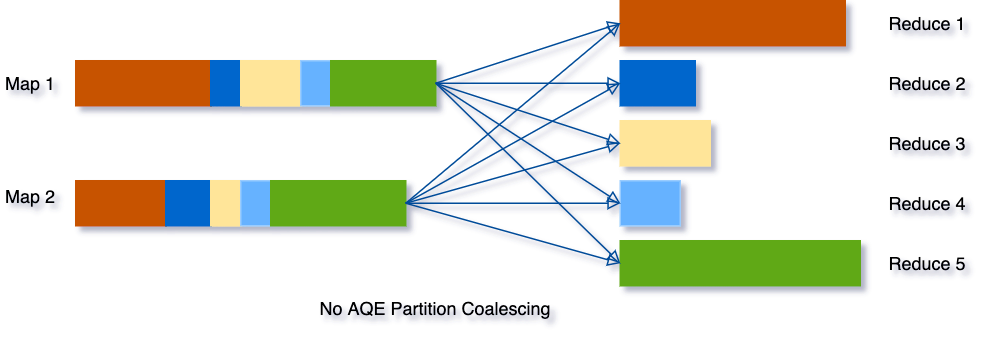

def getReader[K, C]( handle: ShuffleHandle, startPartition: Int, endPartition: Int, context: TaskContext): ShuffleReader[K, C]
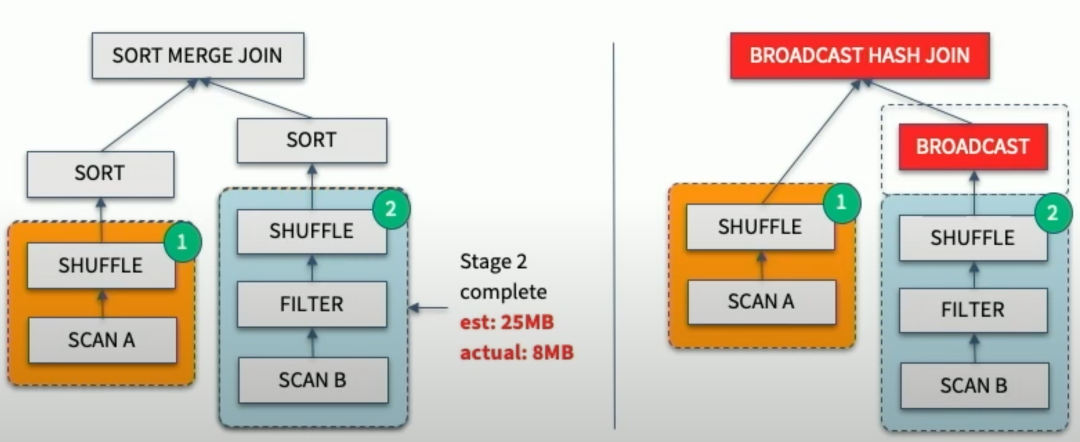
Join策略切换
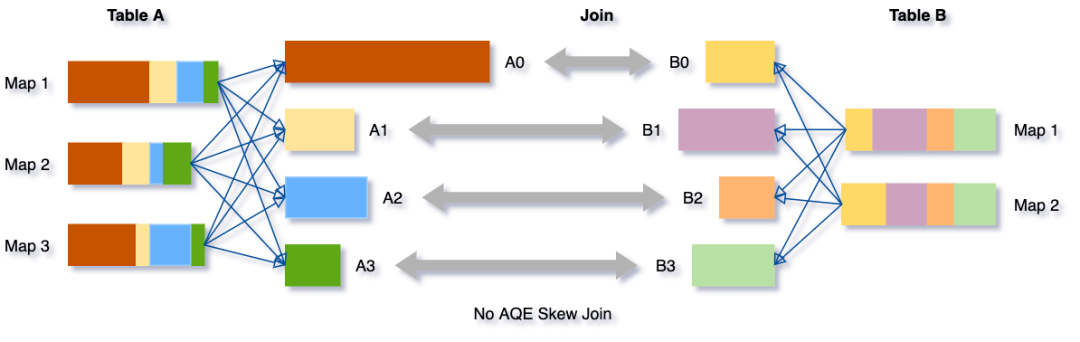
倾斜Join优化
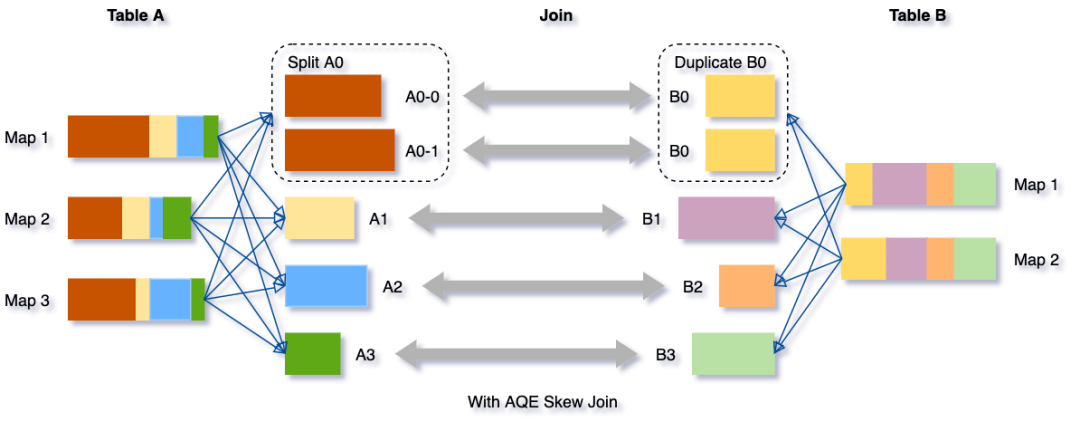
def getReader[K, C]( handle: ShuffleHandle, startMapIndex: Int, endMapIndex: Int, startPartition: Int, endPartition: Int, context: TaskContext, metrics: ShuffleReadMetricsReporter): ShuffleReader[K, C]
2 RSS架构回顾
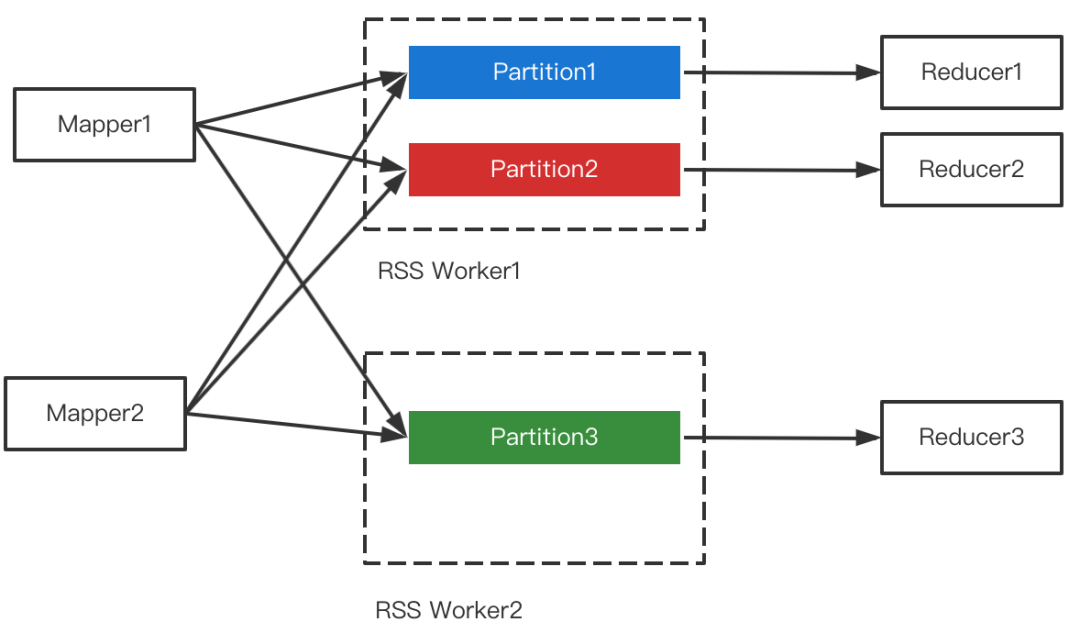
3 RSS支持Partition合并
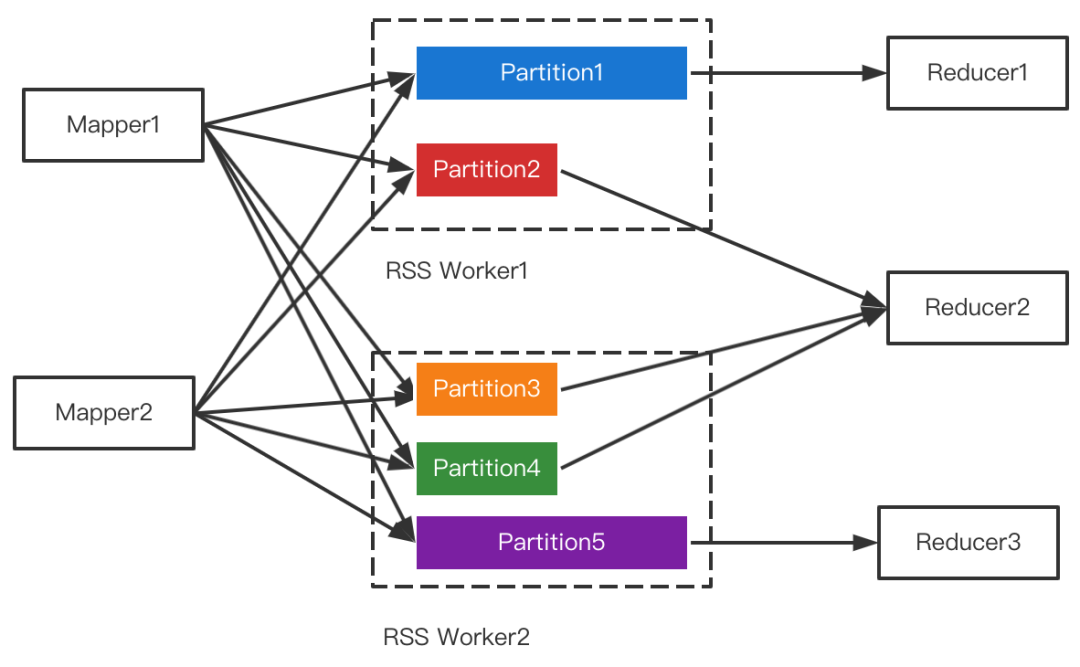
4 RSS支持Join策略切换
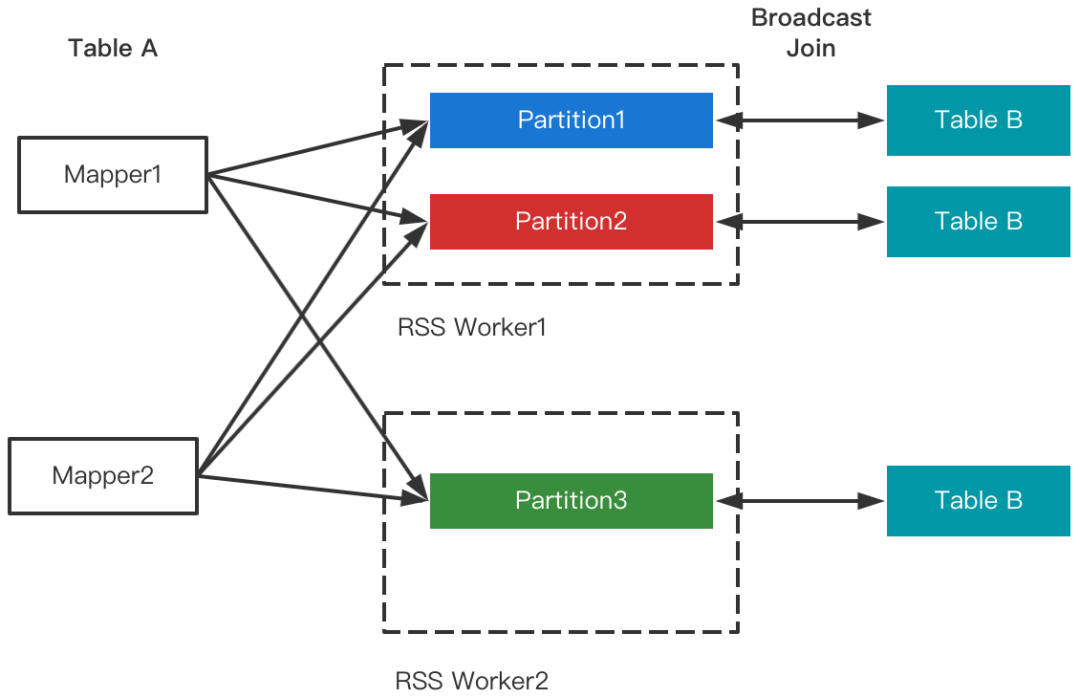
5 RSS支持Join倾斜优化

-
读取完整文件,并丢弃范围之外的数据。 -
引入索引文件,记录每个Block的位置及所属MapId,仅读取范围内的数据。
主动Split
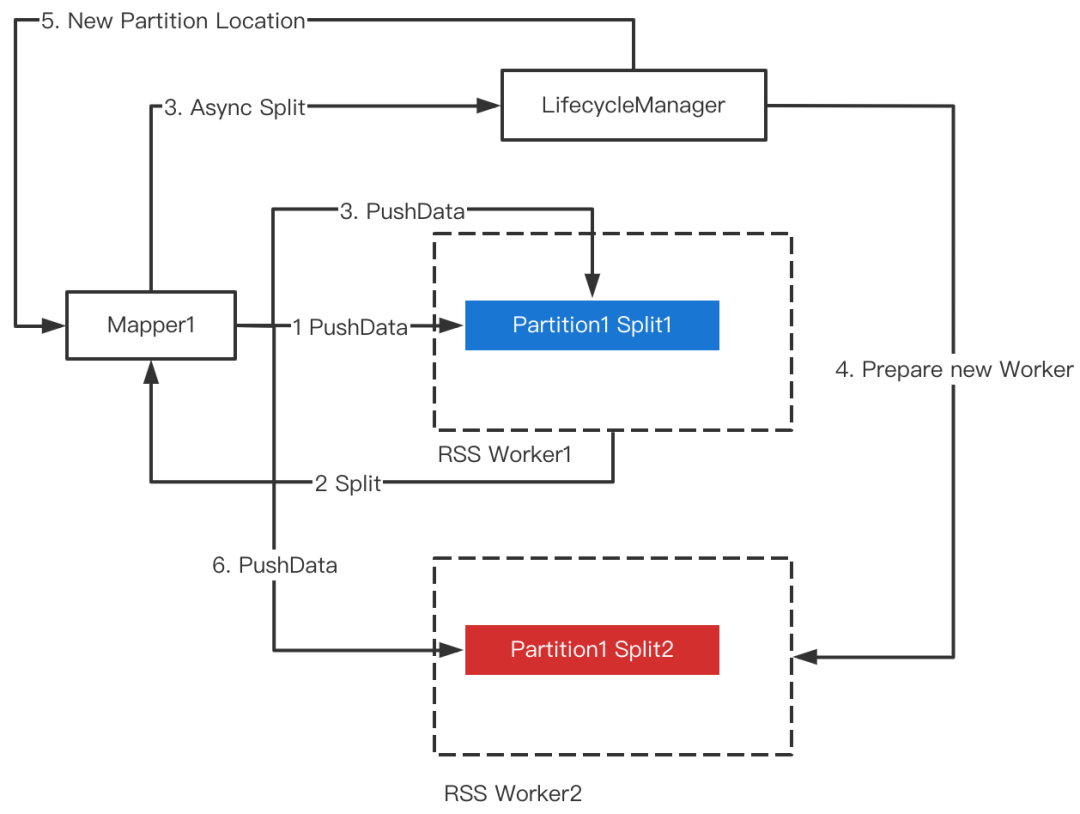
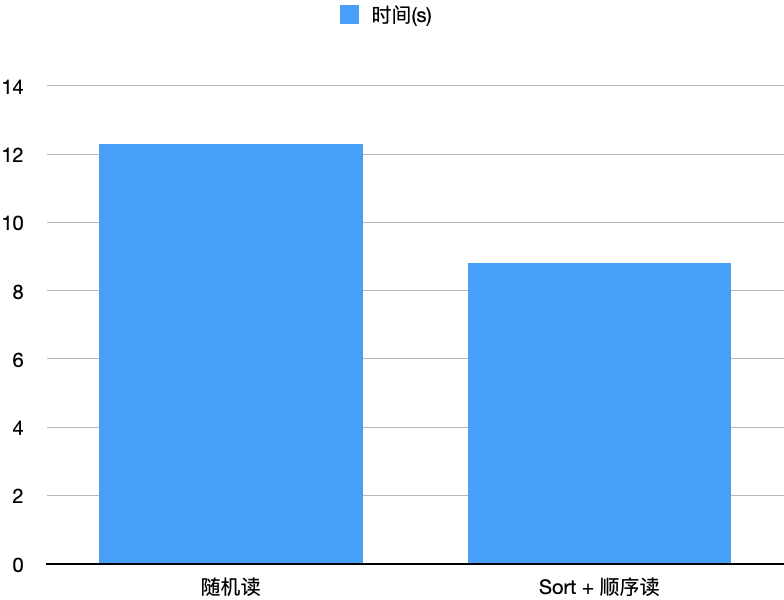
Sort On Read
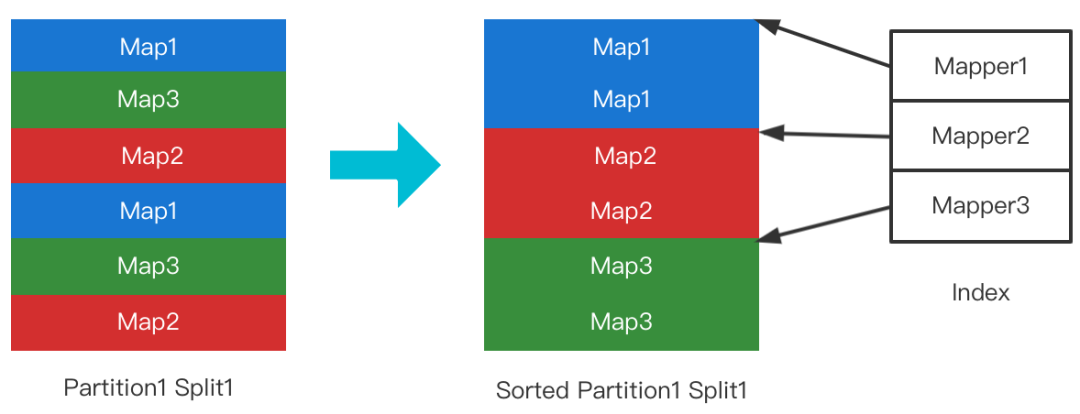
Sort优化
-
预先分配文件大小的内存,文件整体读入,解析并排序MapId,按MapId顺序把Block写回磁盘。 -
不分配内存,Seek到每个Block的位置,解析并排序MapId,按MapId顺序把原文件的Block transferTo新文件。 -
分配小块内存(如256k),顺序读完整个文件并解析和排序MapId,按MapId顺序把原文件的Block transferTo新文件。
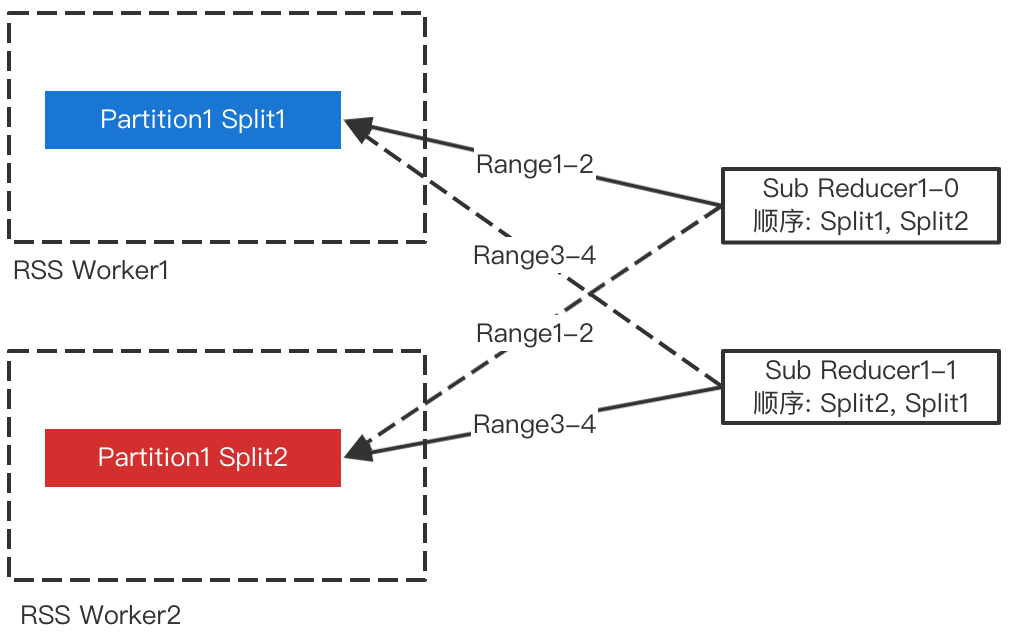
整体流程
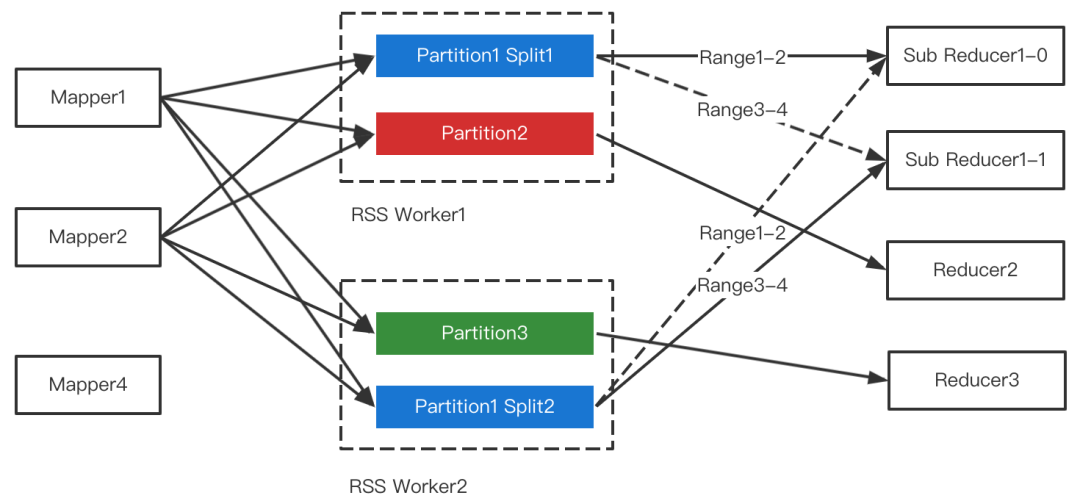
二 RSS流控
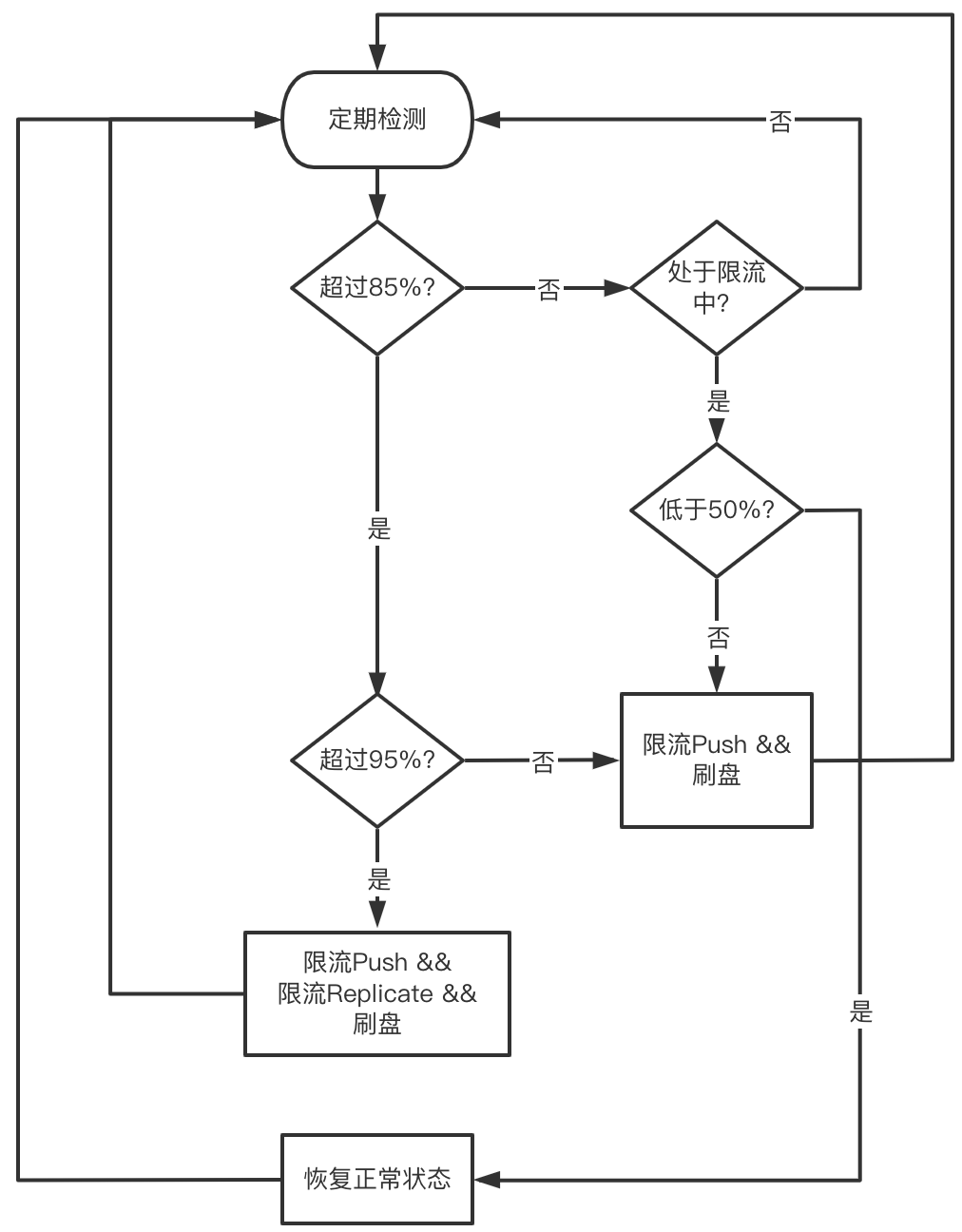
-
Client在每次PushData前先向Worker预留内存,预留成功才触发Push。 -
Worker端反压。
-
Client推送的数据 -
主副本发送的数据
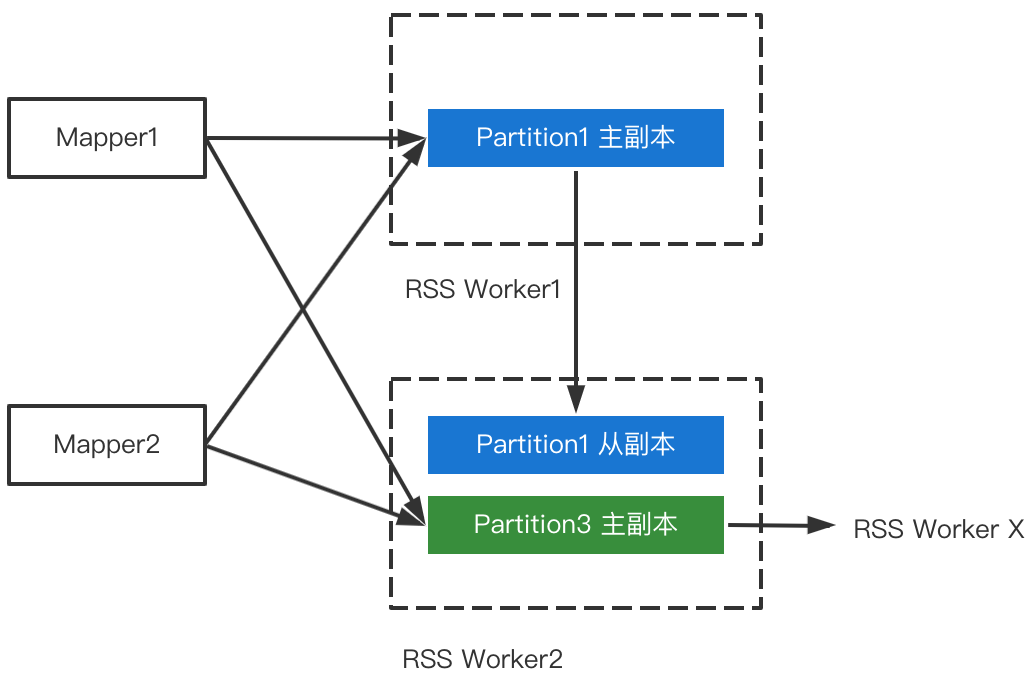
-
Replication执行成功 -
数据写盘成功
-
数据写盘成功
三 性能测试
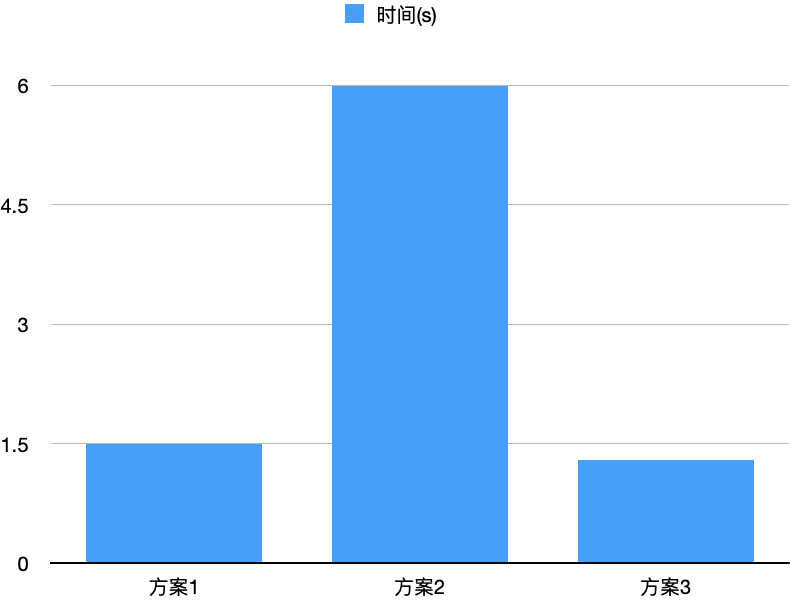
1 测试环境
spark.sql.adaptive.enabled truespark.sql.adaptive.coalescePartitions.enabled truespark.sql.adaptive.coalescePartitions.initialPartitionNum 1000spark.sql.adaptive.skewJoin.enabled truespark.sql.adaptive.localShuffleReader.enabled false
RSS_MASTER_MEMORY=2gRSS_WORKER_MEMORY=1gRSS_WORKER_OFFHEAP_MEMORY=7g
2 TPCDS 10T测试集
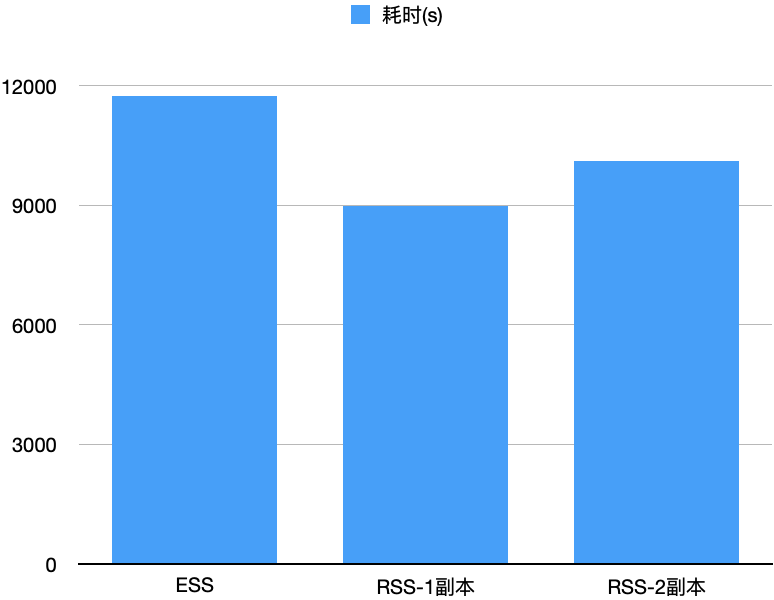
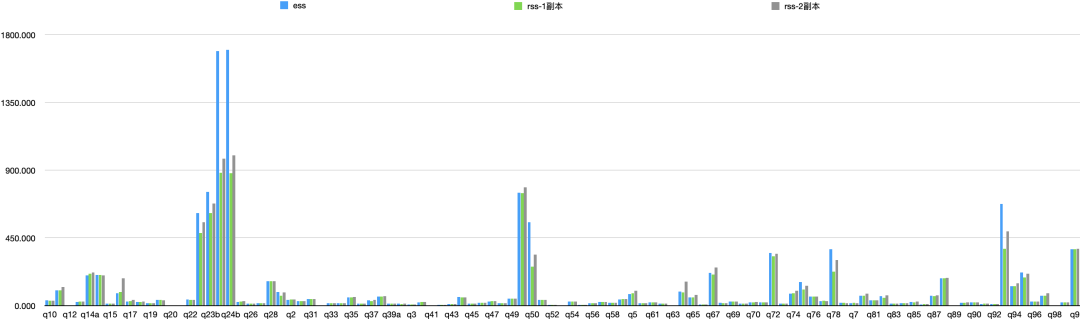
相关链接
Reference
服务发现与配置管理高可用最佳实践
登录查看更多
相关内容

专知会员服务
34+阅读 · 2020年6月19日
专知会员服务
17+阅读 · 2020年3月9日
专知会员服务
35+阅读 · 2020年1月6日
Arxiv
0+阅读 · 2022年6月10日
Arxiv
23+阅读 · 2019年12月12日
Arxiv
12+阅读 · 2018年1月29日



相关VIP内容
专知会员服务
34+阅读 · 2020年6月19日
专知会员服务
17+阅读 · 2020年3月9日
专知会员服务
35+阅读 · 2020年1月6日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年6月10日
Arxiv
23+阅读 · 2019年12月12日
Arxiv
12+阅读 · 2018年1月29日