Proxyless Service Mesh在百度的实践与思考

Service Mesh 已经在云原生界火了很多年,大家的探索热情依然不减。而最近一段时间 Proxyless Service Mesh 也开始进入大家的视野,比如:“Istio 官宣支持 gRPC Proxyless Service Mesh”,“Dubbo 3.0 引入 Proxyless Service Mesh 架构”。
那么,什么是 Proxyless Service Mesh?它和原来的 Proxy Service Mesh 有什么区别和优缺点?落地场景又有哪些呢?本文将结合 Proxyless Service Mesh 在百度的落地实践,带你一探究竟。
先来看下 Proxy Service Mesh,也就是最常见的 Service Mesh 架构,一般如下所示:
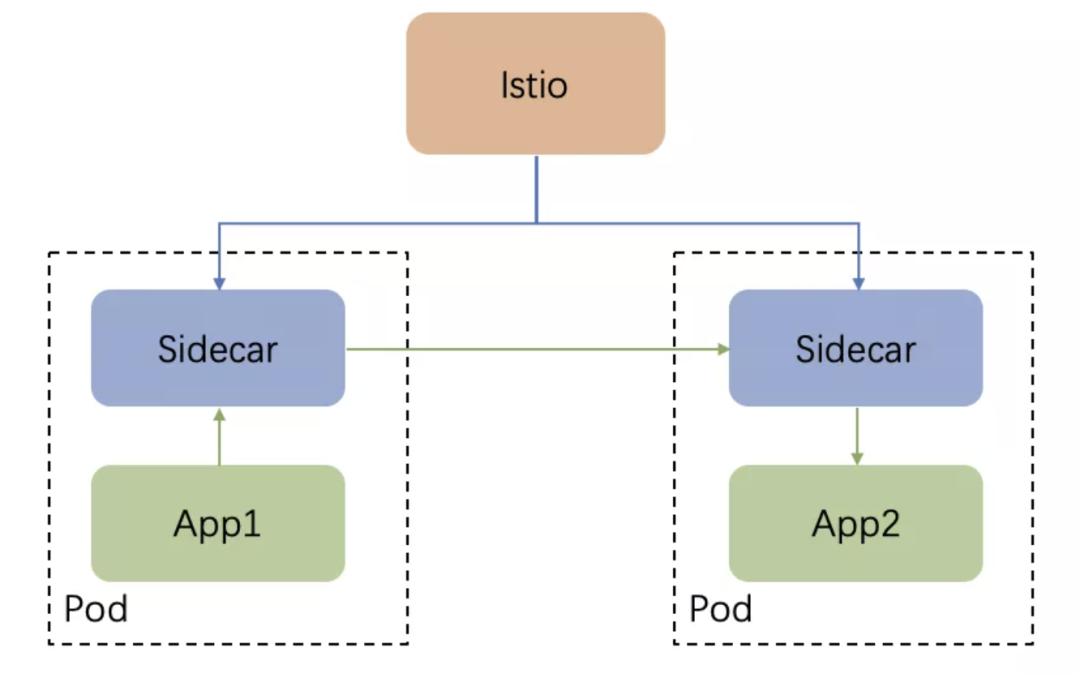
每个 App 的 Pod 里面,有一个独立的 Sidecar 进程,App 之间的通信都通过 Sidecar 进程转发。
有一个全局的控制平面(最常见的实现是Istio),下发配置到每个 Sidecar,控制具体请求的转发策略。
而 Proxyless Service Mesh 则是如下的架构:
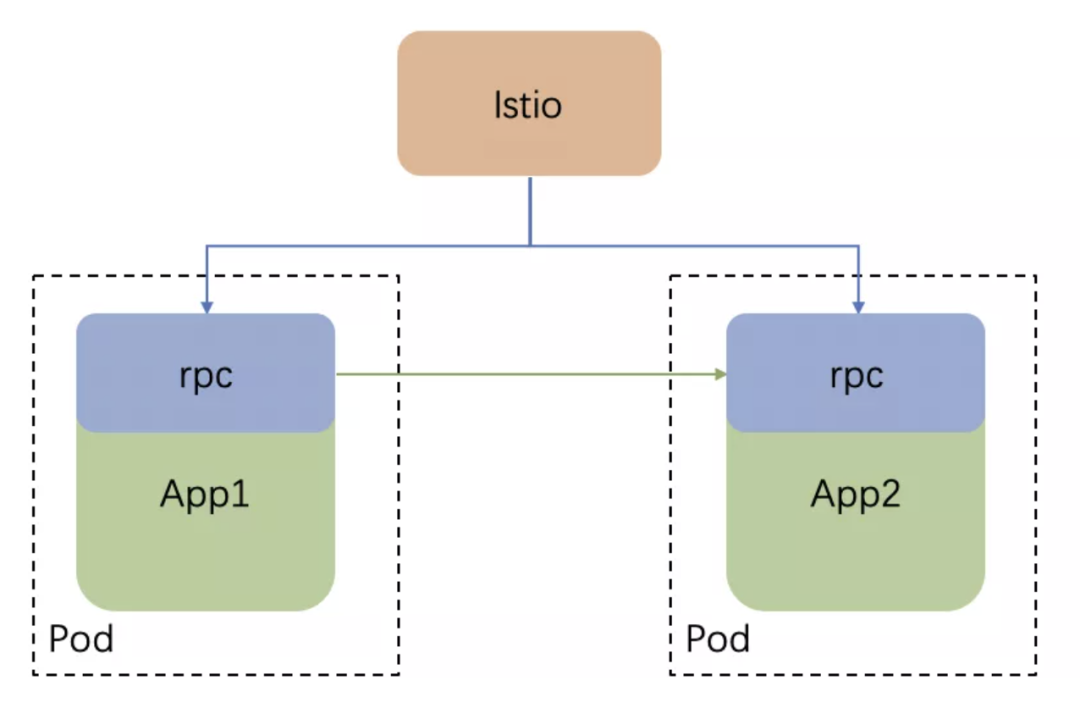
由联编到 App 进程的 rpc 框架负责服务之间的通信。
控制平面下发配置到每个 rpc 框架,rpc 框架按照配置进行具体请求的转发(以上架构图是经过简化的,以目前主流的 Proxyless 实现,比如 gRPC 和 Istio 之间的通信是由 Istio Agent 来代理的,但这不影响后面的讨论)。
如果简单对比上述架构,不难得出 Proxyless 和 Proxy 模式的优缺点:
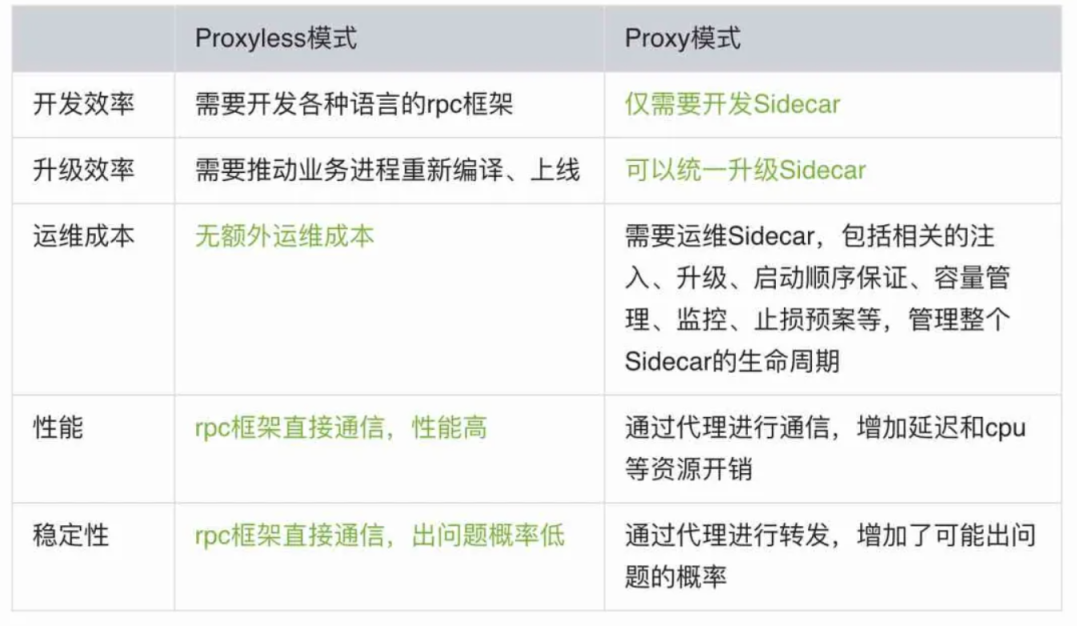
以上仅是一些直观的分析,但当真正落地 Proxyless Service Mesh 的时候,会发现情况并不是我们想的那么简单。
百度从 2018 年开始引入 Service Mesh,一开始是 Proxy 模式。到了 2020 年,我们在落地一些业务线的时候,发现 Proxy 模式很难在整个业务线全面铺开:
业务其实能够接受 Proxy 带来的额外资源开销,毕竟我们已经做了很多优化,比如将社区 Both Side 模式改成 Client Side 模式(即一次请求只过 Client 端的代理,不经过 Server 端的代理);比如将 Envoy 的流量转发内核替换成 bRPC。我们能做到 Sidecar 占业务进程的 cpu 消耗在 5% 以内,有的业务甚至不到 1%。
但业务无法接受 Proxy 带来的延迟增长,即使我们已经把 Proxy 单次转发增加的延迟优化到 0.2 毫秒以内,但由于整个业务系统包含了很大的一个调用拓扑,每条边上增加一点点的延迟就能导致流量入口模块增加较大的延迟,进而对业务 KPI 造成影响。
因此我们开始引入如下的 Proxyless Service Mesh 模式:
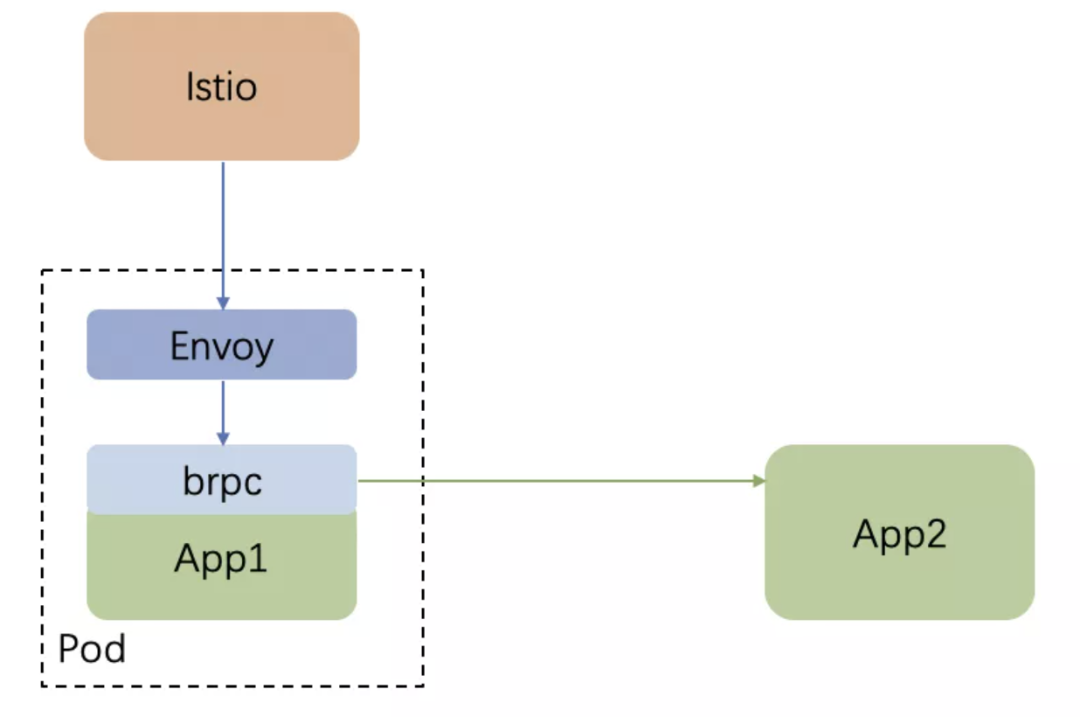
Envoy 从 Istio 拿到流量转发配置,并转化成 bRPC 能识别的配置
bRPC 通过 http 接口从 Envoy 中拿到流量转发配置,并且按照该配置去调用其它服务
这种方式的好处是:
业务接入 Mesh,不会带来延迟增长,也不会增加明显的资源开销(这里的 Envoy 仅处理配置,资源开销极小)。
业务可以享受 Mesh 的便利性,如集中管理配置、动态下发配置生效,不再需要改代码或改配置、上线、重启生效,极大提升了服务治理的效率。
但是,第一阶段方案,存在一些明显的问题:
bRPC 里支持的服务治理策略较少,仅支持 Istio 中的少量功能,这就意味着大部分 Istio 的能力无法通过 Proxyless 模式享受到。
随着业务不断增加的需求,我们势必要在 Service Mesh 中增加更多的服务治理能力。对于 Proxy 模式,我们需要在 Envoy 中开发,而对于 Proxyless 模式,我们又需要在 bRPC 中开发,由于 Envoy 和 bRPC 的策略架构差异很大,这些代码很难复用,就意味着每一个需求都得重复开发两遍。
因此,到了 2021 年,我们设计并实现了一套 Proxyless/Proxy 统一架构的 Service Mesh:
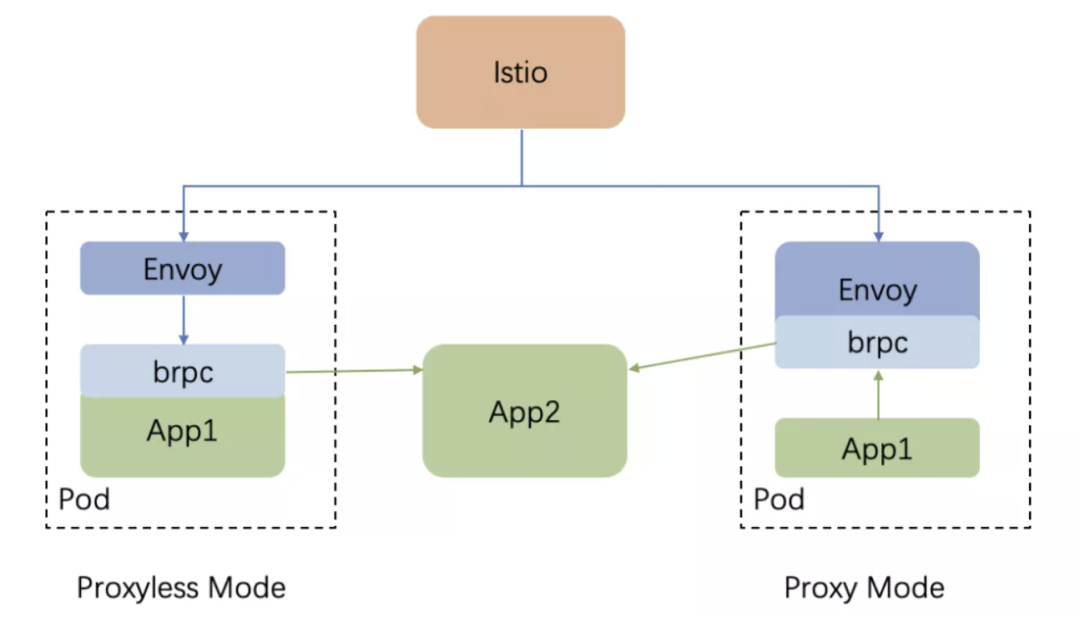
左边是 Proxyless 模式,Envoy 负责把 xds 配置转换成 bRPC 能识别的配置,bRPC 联编到业务进程,从 Envoy 获取配置并按配置转发请求。
右边是 Proxy 模式,Envoy 仍负责把 xds 配置转换成 bRPC 能识别的配置,bRPC 联编到 Envoy 进程,从 Envoy 获取配置并按配置转发请求。
无论是哪种模式,Envoy 都负责转换配置,bRPC 负责配置执行,因此,所有的代码都可以在 Proxy 和 Proxyless 模式下复用。
从业务场景上:
C++ 服务,可以联编 bRPC,使用 Proxyless 模式;
延迟不敏感的非 C++ 服务(如 Go/Python/PHP/Java 等),可以无侵入使用 Proxy 模式;
延迟敏感的非 C++ 服务:什么,既然延迟敏感了,为啥不用 C++ 开发?(这里的延迟敏感指的是一毫秒必争的这种敏感程度)
服务治理能力提升:
在这个架构的基础上,我们丰富了 bRPC 的服务治理能力,基本覆盖了我们用到的所有 Istio 的能力,如权重路由、基于请求内容的路由、实例子集路由、流量复制、错误注入、异常实例驱逐、自定义错误码重试等。
由于采用了 bRPC 架构,我们可以将先前公司内基于 bRPC 架构实现的优秀服务治理策略都集成到 Service Mesh,包括延迟感知的负载均衡、基于错误码的动态实例调权、基于请求优先级的分级调度、基于分位值的动态超时和 Backup request、重试比例熔断,这些能力是原生 Envoy 所缺失的,但是对于降低延迟、提升服务稳定性至关重要。
得益于 bRPC 多协议架构,上述所有的 Istio 服务治理能力、公司内部优秀服务治理策略,都可以支持 bRPC 中的所有协议。相比之下,在 Envoy 中只有 HTTP 协议是一等公民,其它协议的治理能力都相当薄弱。另外由于 bRPC 支持协议自动嗅探,我们无须扩展 Istio 下发协议类型,所有协议都按 HTTP 方式配置即可。
Proxyless 第三阶段
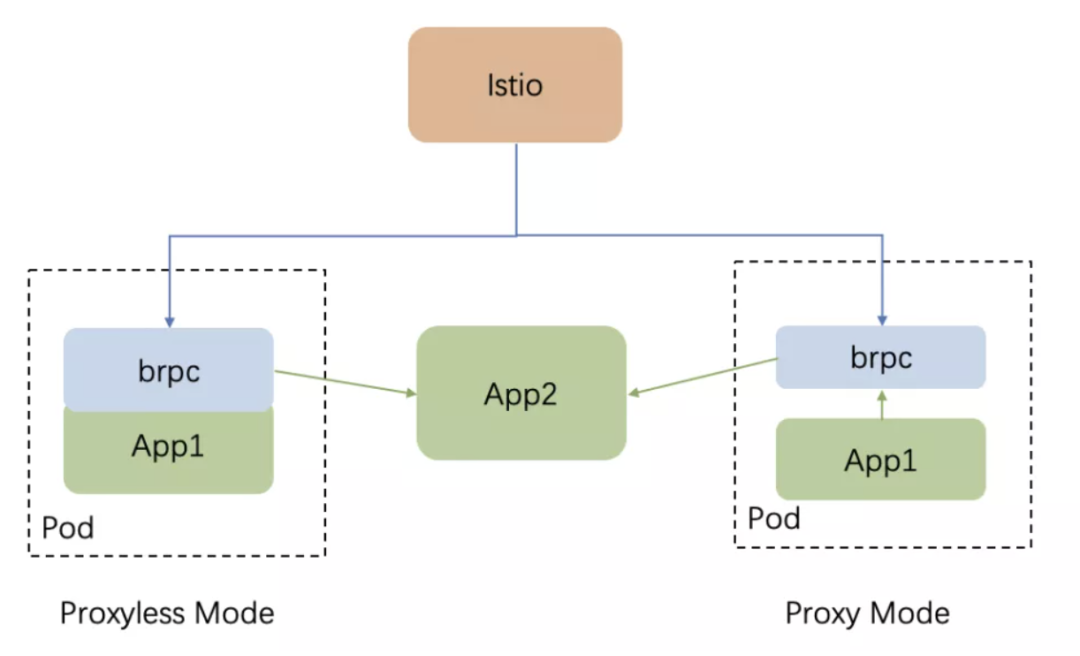
bRPC 直接支持和 istio 通信,获取 xds 配置并进行转换;
Proxyless 模式,bRPC 联编到业务进程中进行请求转发;
Proxy 模式,bRPC 作为一个独立的 sidecar 进程进行请求转发。
这个架构彻底解决了 Envoy 这个历史包袱,让 Service Mesh 轻装上阵。
让我们回过头看一下前面说的 Proxyless 模式的两个缺点是怎么被解决的:
开发效率:我们仍然只需要开发一套策略,适用于所有语言(C++ 用 Proxyless,其它语言用 Proxy),不需要为每个语言开发 SDK。
升级效率:由于百度内部 C++ 有 depend on stable 机制(类似于 Google 的 depend on HEAD),基础库有一个 stable 发布分支,而其它模块都依赖于基础库的 stable 分支。这样,当我们升级了 bRPC 中的 Service Mesh 功能时,只要将代码合并到 stable 分支,所有的上游模块都会自动更新,不需要再一个一个推动业务升级。至于非 C++ 语言,使用 Proxy 方式来保证升级效率。
似乎这两个缺点在我们的场景里都没有了:)
Proxyless 模式的真正优势是性能吗?一开始我们都是这么认为的,但是随着我们落地 Proxyless 模式的过程,我们才逐渐发现 Proxyless 模式的更多优势。让我们来看看一些场景吧:
比如我们要在 Service Mesh 中实现一致性哈希负载均衡,原来没有 Service Mesh 的时候,用户通过 RPC 框架提供的一个 set_request_code() 方法来设置请求级别哈希码,RPC 框架可以确保同一个 request_code 的请求被调度到同一个后端实例。
在 Service Mesh 中如何实现这个需求呢?如果是 Proxy 模式,负载均衡是在 Sidecar 做的,Sidecar 需要获取到这个 request_code。总不能让用户改代码吧?那么只能修改 RPC 框架,让框架把 request_code 传给 Sidecar。如图所示:
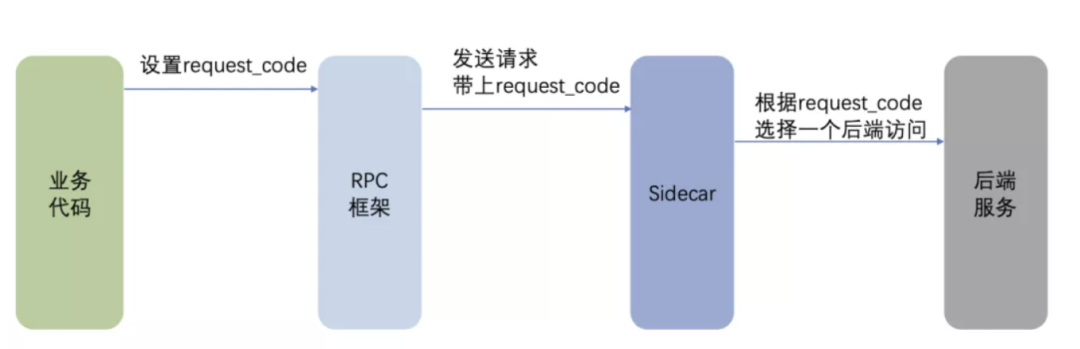
怎么传给 Sidecar 呢?得在协议里的某个字段中传过去,比如 HTTP 协议可以在 header 中传过去,那么其它协议呢?每个协议都得找一个地方来传这个字段,每个协议都得实现一遍这个逻辑。
所以在 Proxy 模式下,传参这个事的实现成本 =(RPC 框架发送参数 +Sidecar 接收参数)* 协议数量。
那么在 Proxyless 模式下呢?这个参数本来 RPC 框架就能拿到,所以传参的实现成本 =0。
除了一致性哈希,类似的场景还有很多,比如请求级别超时控制、请求级别路由参数等,在这些场景下,Proxyless 模式完胜。
比如用户想实现一个自定义重试策略,RPC 框架在访问一次后端服务之后,调用用户代码来判断是否需要重试。一个典型的流程如下所求:
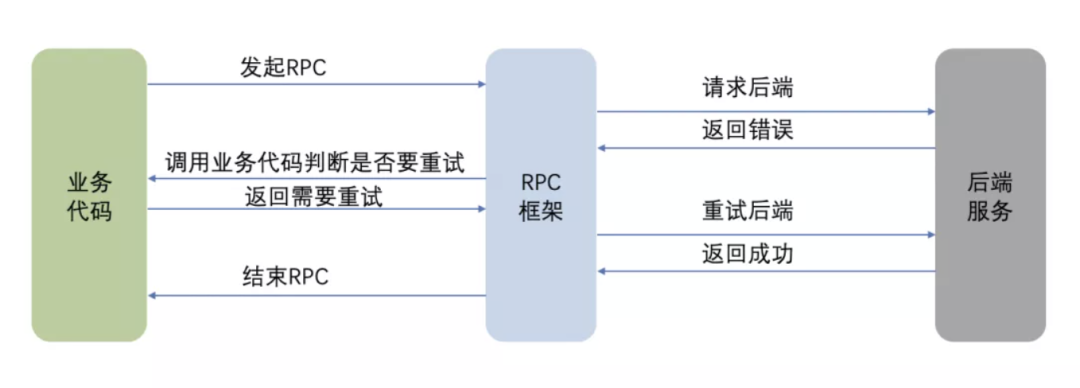
现在业务想要接入 Service Mesh,如果用 Proxy 模式,该如何实现用户自定义重试策略呢?考虑以下方案:
方案一:将业务代码中的自定义重试策略实现到 Sidecar 代码里。问题是,业务的自定义重试策略可能不具有通用性,放在 Sidecar 这种通用基础设施的代码里显然不合适。
方案二:Sidecar 提供一种扩展机制,比如 WASM,用户将自定义重试策略实现为 WASM,以配置方式下发给 Sidecar 去执行。问题是,将原有代码改造成 WASM 的成本可能较高,这会明显降低业务接入 Mesh 的意愿。而且 WASM 的性能也不高。
方案三:业务进程暴露一个服务接口,Sidecar 调用这个接口来决定是否要重试。问题是,这样增加了业务进程和 Sidecar 之间的交互次数,增加了延迟,也增加了问题出现的概率。
在 Proxy 模式下,无论采用哪种方案,问题都很大。在 Proxyless 模式下呢?由于该功能 RPC 框架本来就支持,成本 =0。除了自定义重试策略,类似的场景还很多,比如自定义负载均衡策略、自定义 NamingService 等,在这些场景下,Proxyless 模式完胜。
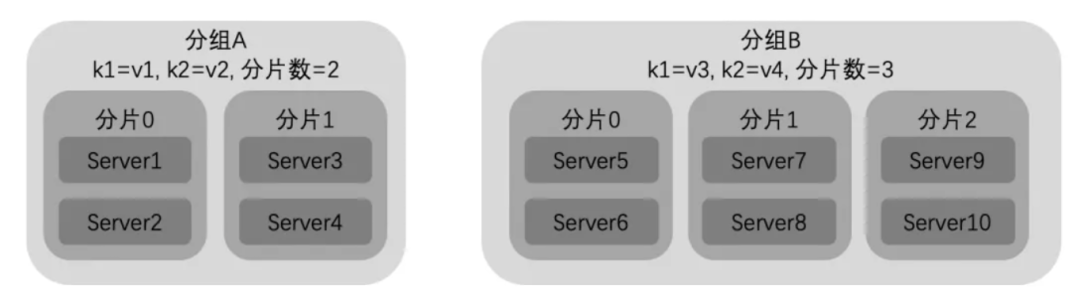
先解释一下什么叫动态多分片。多分片在搜索、推荐类业务是一个典型场景,也就是说一个服务的一个实例并不加载全量的数据,只加载一个分片的数据。客户端调用此类服务时,需要将请求同时发送给不同分片的后端服务实例,获取到每个分片的结果再进行汇总处理。动态多分片是指多个分片的服务组成一个分组,每次请求可以动态地选择一组分片。之所以需要多个分组,一种场景是因为数据发生扩容时,分片数会发生变化,为了保证流量平滑迁移,会同时存在不同分片数量的分组;另一种场景是由于业务需要,不同的分组加载了不同业务属性的数据,需要根据请求来动态确定调用哪个分组的服务。如下图所示,分组 A 有 2 个分片,分组 B 有 3 个分片,而 k1、k2 则代表了不同的业务属性。
在动态多分片场景下,业务代码和 RPC 框架的一个简化的交互流程如下:
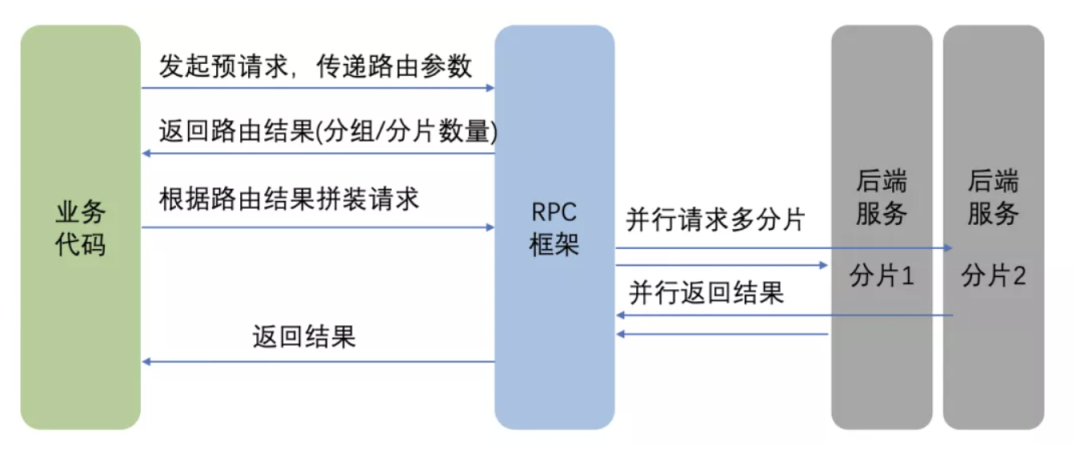
之所以需要分两个阶段调用 RPC 框架,是因为业务需要根据最终选定的分组和分片数量来拼装业务的请求。
现在业务想要接入 Service Mesh,让我们看看在 Proxy 模式下支持动态多分片的方案:
方案一:...(此处省略 300 字),不行,这个方案性能太差;
方案二:...(此处省略 500 字),不行,这个方案成本太高;
方案三:抱歉,我想不出其它方案了……
现在,让我们看看 Proxyless 模式下支持动态多分片的方案:
沿用原来的二阶段流程,在第一阶段,执行 Service Mesh 中的各种路由策略,确定最终的分组,以及决策是否做流量复制、流量复制目的分组。
第二阶段,先按原来 RPC 框架逻辑进行多分片并行调用,具体到单个分片上,使用 Service Mesh 中的负载均衡、超时重试等策略。如需流量复制,则异步执行流量复制到另一个分组。
虽然这个方案也有一定复杂性,但实现成本也不是很高,比 Proxy 模式的实现成本低多了。所以,在动态多分片场景,Proxyless 模式完胜。
服务可观测是 Service Mesh 的重点场景,我们来看一下这个场景下的一些需求吧:
用户想实现分布式 trace,需要将服务的入口流量和出口流量建立关联,比如在处理 trace_id=x, span_id=y 的入口流量过程中,发出的出口流量,其 trace_id=x, parent_span_id=y。Sidecar: 这事我干不了,得靠 RPC 框架。
用户想把业务日志和 RPC 日志进行串联,比如在处理 trace_id=x 的请求过程中,打印的业务日志中都包含 trace_id=x 字段,这样可以进行汇聚计算。Sidecar:这事我干不了,得靠 RPC 框架和日志库打通。
用户想监控请求处理过程的一些细化耗时,比如排队时间、序列化反序列化时间。Sidecar:这事我干不了,得靠 RPC 框架。
用户想实现流量染色,比如将入口请求打上 k=v 标签,然后由该请求触发的整个调用链的请求都会带上 k=v 标签。Sidecar:这事我干不了,得靠 RPC 框架。
用户想针对业务代码的耗时、cpu 使用进行分析,找出瓶颈。Sidecar:这事我干不了……
为什么会出现这些情况呢?实现服务可观测的最好方法就是深入服务内部,对于 Sidecar 来说,服务就是个黑盒,当然不好实现了。
所以,对于服务可观测场景,Proxyless 模式完胜。
诚然,Sidecar 是 Service Mesh 的一大卖点,比如方便支持多语言、和应用解耦,这可以让用户更方便地接入 Service Mesh。但是我们更应该关注 Service Mesh 给用户带来了什么价值,如果用户用了 Service Mesh 没有收益,即使接入成本为 0,用户也会不接入的。
从用户角度看,Service Mesh 带来的是以下价值:
服务可用性提升:比如各种超时重试、限流熔断策略带来的提升;
延迟降低:比如延迟感知的负载均衡策略可以实现服务整体延迟的降低;
服务可观测:比如链路黄金指标、调用链追踪能力可以提升服务可观测性;
流量调度灵活性:比如各种路由策略可以实现灰度发布、跨机房切流等;
安全性:比如 TLS、各种认证鉴权机制可以提升服务间调用的安全性;
管理便利性:上述策略都可以通过控制平面集中管理,动态下发生效。
因此我认为,Service Mesh 就是能让服务间通信更可靠、更快、更透明、更灵活、更安全、更便于管理的基础设施。
至于这个基础设施是 Proxyless 还是 Proxy 模式,其实不是很重要。从实际业务场景出发,哪种模式更容易满足业务需求,就用哪种方案。两种模式各有自己的优势场景,结合起来可以提供更好的服务。
有一种观点认为,Proxyless 模式不就是 RPC 框架 + 配置中心吗?Proxy 模式不就是一个 7 层代理 + 配置中心吗?这玩意很多年前就有了。
但是,Service Mesh 的控制平面,不能简单看作配置中心。配置中心仅仅是简单地将配置文件或者配置项进行下发,并不感知配置的实际含义。
而以 Istio 为代表的控制平面,实际上是定义了 Service Mesh 的能力标准,比如各种路由、负载均衡策略等。如果只是做了一个简单的 RPC 框架,暴露了几个超时参数到配置中心来控制,那不叫 Service Mesh,因为没有实现 Service Mesh 的标准能力。即使 RPC 框架把 Service Mesh 的标准能力都实现了,但是没有统一的协议和配置格式,不同的框架的配置方式五花八门,通信协议互相割裂,那也不能算 Service Mesh。
所以说,Service Mesh 是一组服务间通信的能力标准,实现了这些标准,就可以称之为 Service Mesh。
从目前趋势看来,Istio 仍然会作为 Service Mesh 控制平面的首选。尽管 Istio 的 CRD 对用户也不是很友好,但是 Istio 定义的 Service Mesh 标准体系目前仍是最完整的,也获得了最广泛的数据平面的支持。
而数据平面,则可能出现百花齐放的场景,毕竟业务场景非常多样,有的看重灵活性,有的看重性能,有的看重安全,那么就能催生不同的数据平面实现方案。Envoy 仍然会作为 Proxy 模式的主流选择,但各 RPC 框架也不甘于只做瘦客户端,将会继续发展自己的 Proxyless 方案,让 Service Mesh 能落地到更多的业务场景之中。
今日好文推荐
突发!Log4j 爆“核弹级”漏洞,Flink、Kafka等至少十多个项目受影响
离职 Oracle 首席工程师怒喷:MySQL 是“超烂的数据库”,建议考虑 PostgreSQL
计算机架构史上的一次伟大失败,多数人都不知道
滴滴启动美股退市;阿里股价跌回2017年;Linus吐槽桌面版Linux:乱改核心,程序兼容性太糟糕

点个在看少个 bug 👇



