云原生数仓如何破解大规模集群的关联查询性能问题?

前言
ADB PG架构简介
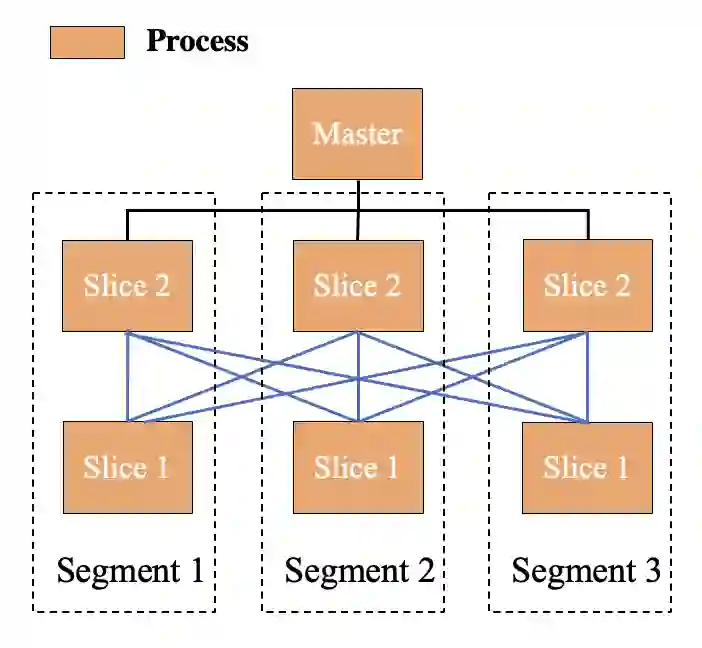

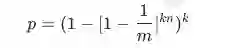

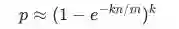
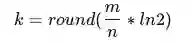
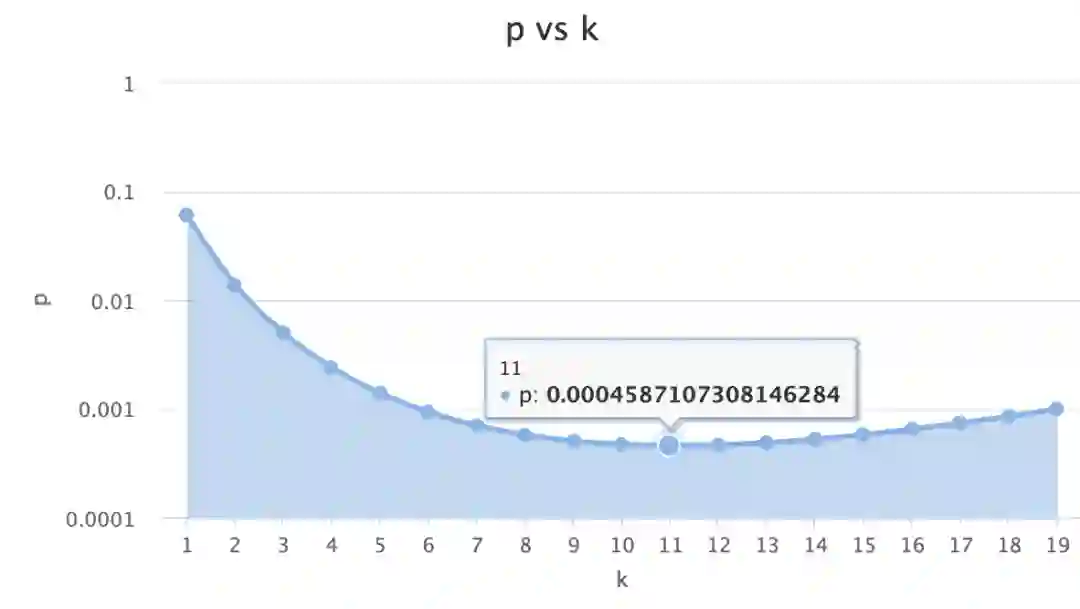
Bloom Filter的参数设计
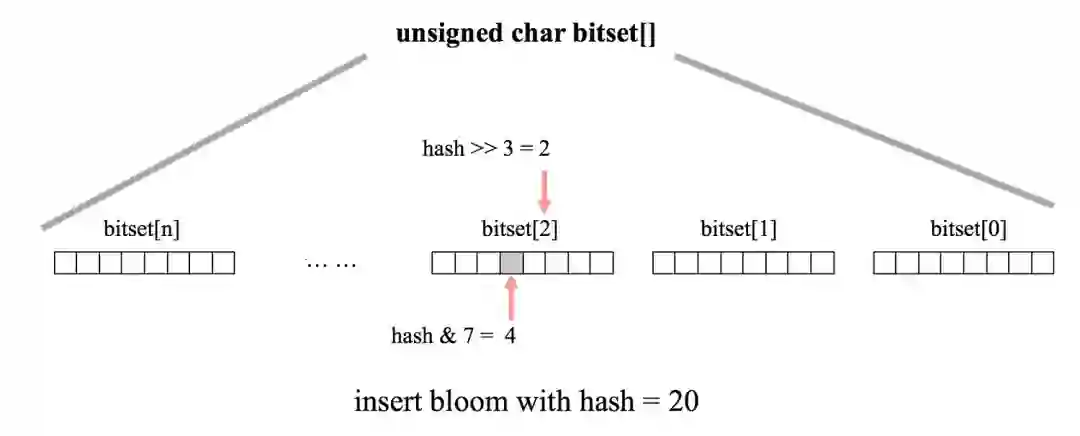
Dynamic Join Filter in ADB PG
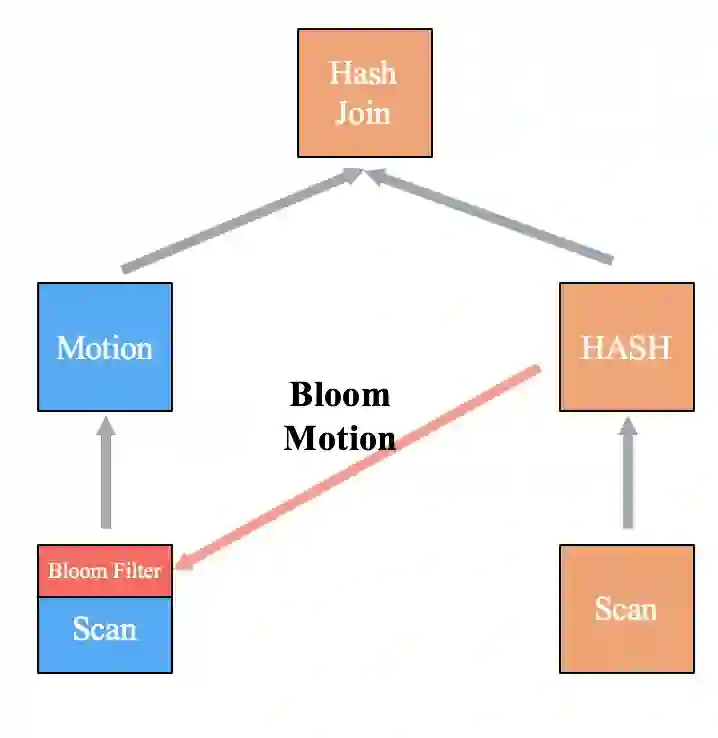
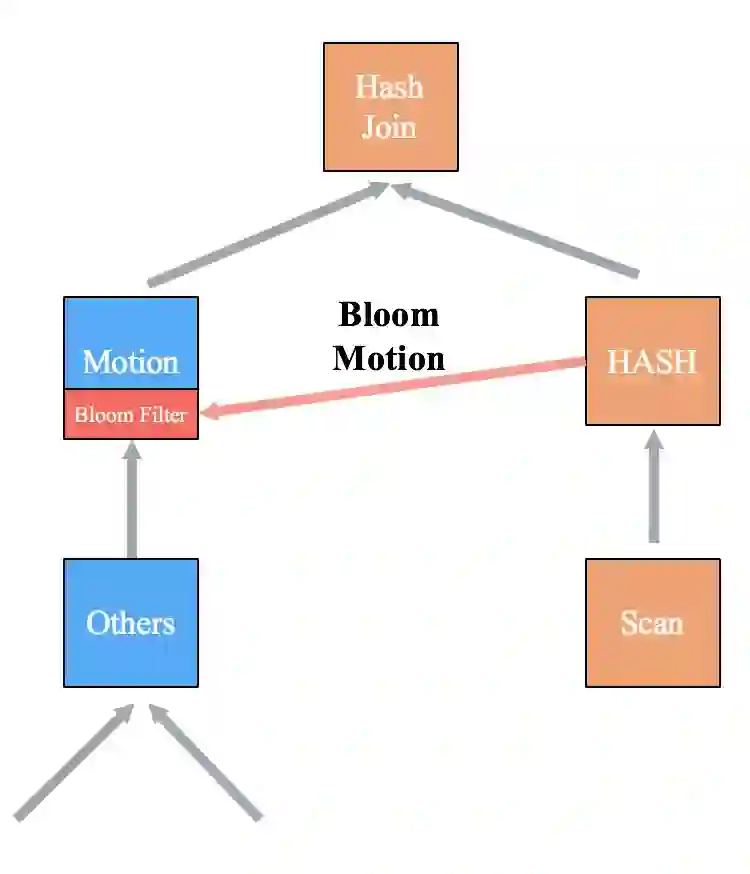
1 Dynamic Join Filter的实现方式
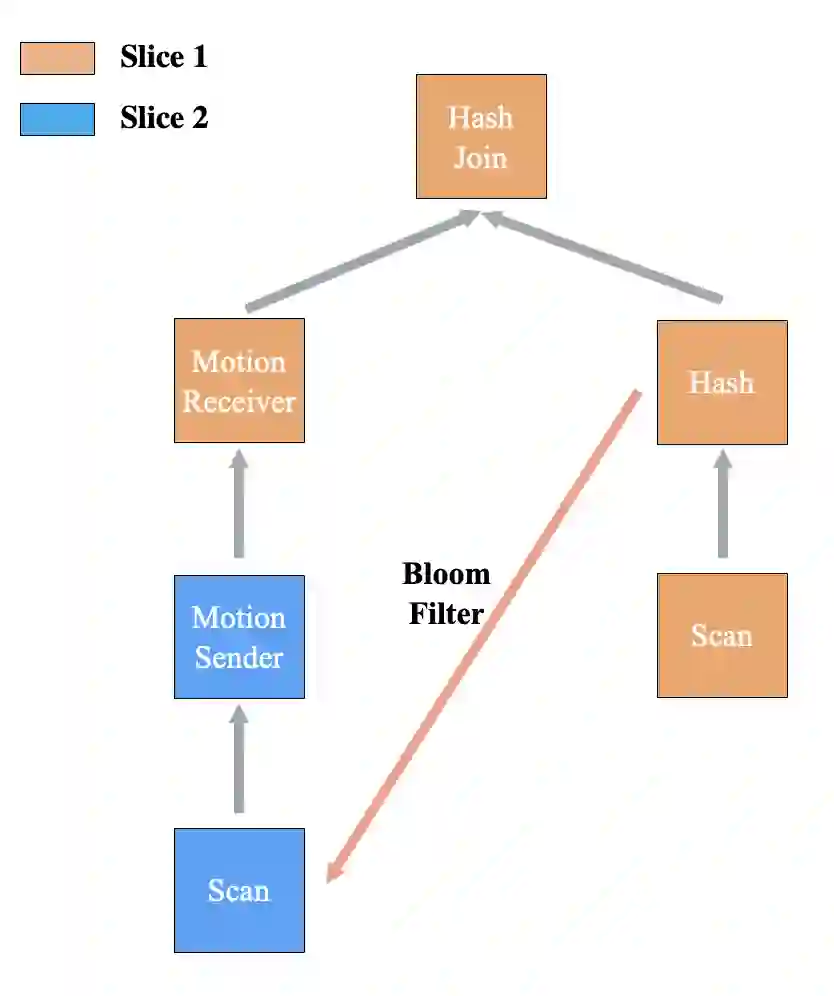
Local Join
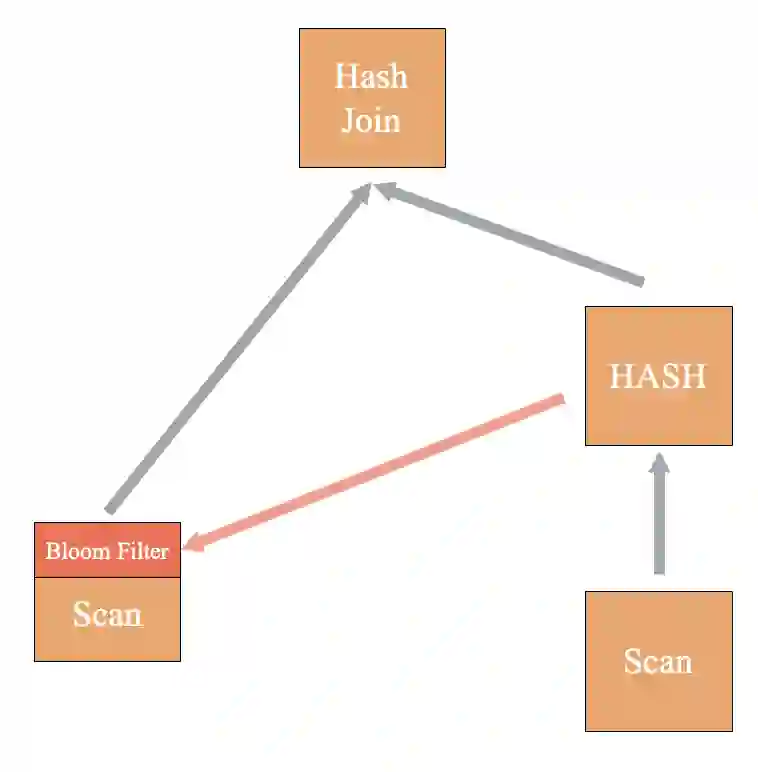
MPP Join
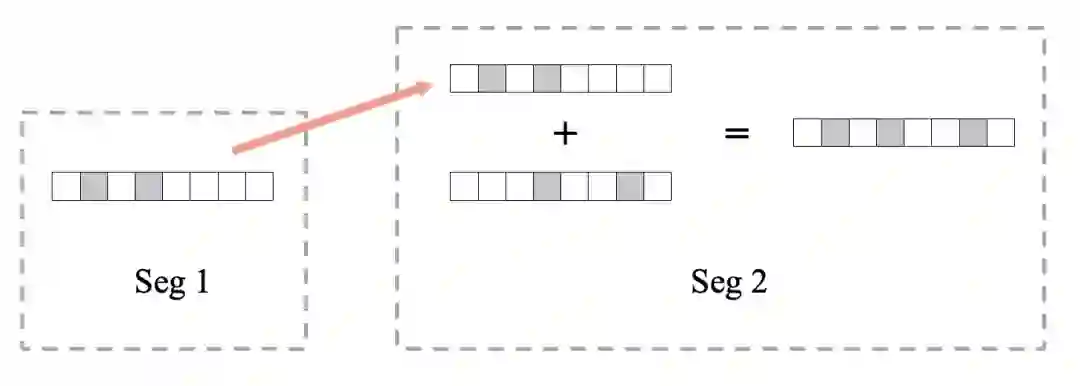
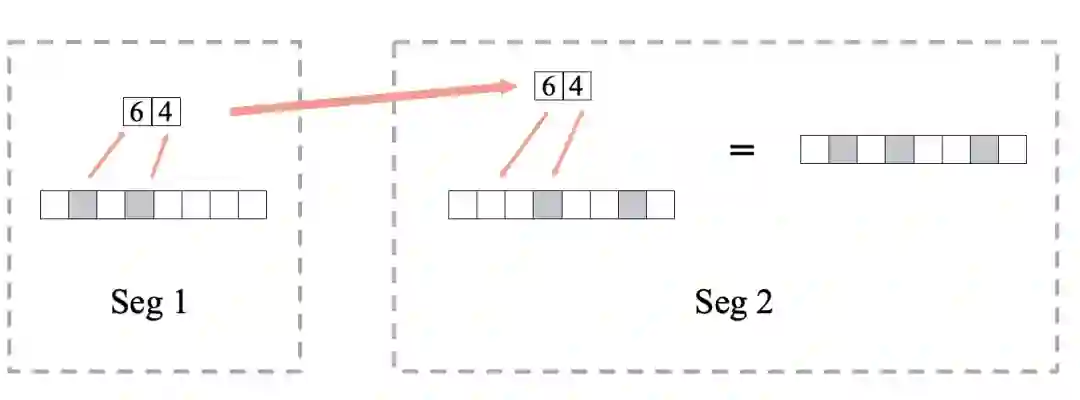
2 Bloom Filter网络传输
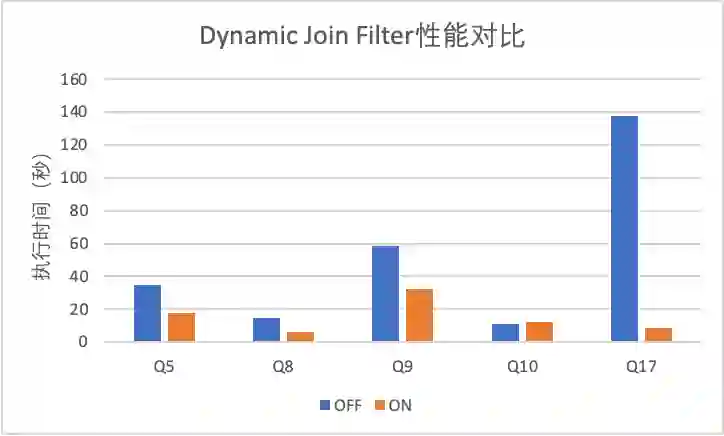
性能测试
总结&未来规划
-
完善Dynamic Join Filter功能,支持各种模式的Hash Join,并进一步推广到Merge Sort Join、NestedLoop Join的优化中;
-
提升优化器的代价估算模型精度,完善优化器下推规则;
-
Runtime Filter自适应调度。
十万亿条消息背后的故事
数次支撑阿里双十一、上线至今处理超过十万亿条消息,开源消息中间件Apache RocketMQ背后是怎样一群人?开源这十年间有哪些不为人知的故事?InfoQ与阿里云开发者社区联合出品的【开源人说】系列视频第一期预告片已上线!

点击阅读原文查看详情!
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年7月26日

相关VIP内容
相关资讯