CVPR 2022|解耦知识蒸馏,让Hinton在7年前提出的方法重回SOTA行列

极市导读
与主流的feature蒸馏方法不同,本研究将重心放回到logits蒸馏上,提出了一种新的方法「解耦知识蒸馏」,重新达到了SOTA结果,为保证复现该研究还提供了开源的蒸馏代码库:MDistiller。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
1 研究摘要
近年来顶会的 SOTA 蒸馏方法多基于 CNN 的中间层特征,而基于输出 logits 的方法被严重忽视了。饮水思源,本文中来自旷视科技 (Megvii)、早稻田大学、清华大学的研究者将研究重心放回到 logits 蒸馏上,对 7 年前 Hinton 提出的知识蒸馏方法(Knowledge Distillation,下文简称 KD)[1] 进行了解耦和分析,发现了一些限制 KD 性能的重要因素,进而提出了一种新的方法「解耦知识蒸馏」(Decoupled Knowledge Distillation,下文简称 DKD)[2],使得 logits 蒸馏重回 SOTA 行列。
同时,为了保证复现和支持进一步研究,该研究提供了一个全新的开源代码库 MDistiller,该库涵盖了 DKD 和大部分的 SOTA 方法,并不断进行更新维护,欢迎大家试用并提供宝贵的反馈意见。

论文链接:https://arxiv.org/abs/2203.08679
代码链接:https://github.com/megvii-research/mdistiller
2 研究动机
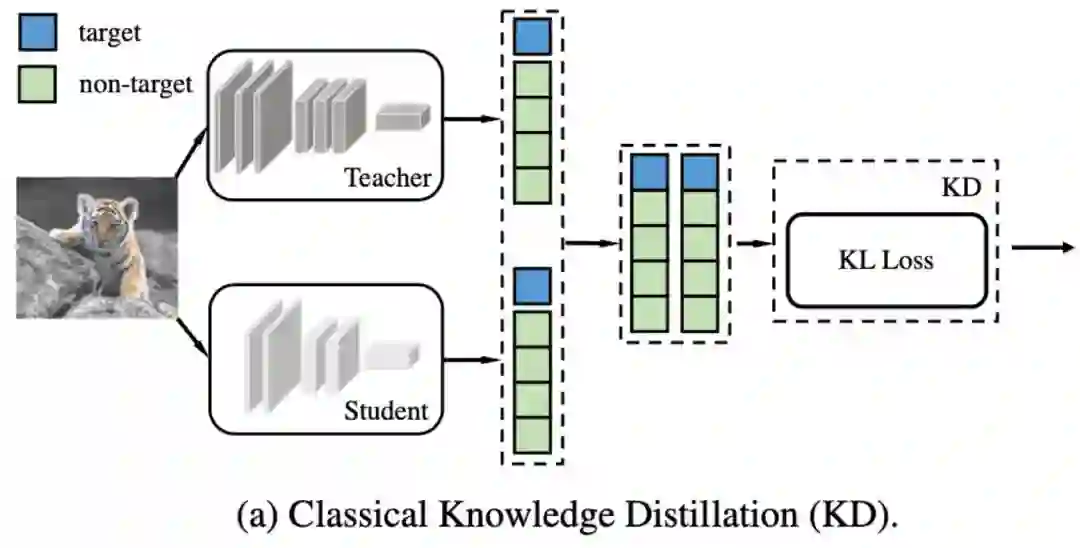
上图是大家熟知的 KD 方法,KD 用 Teacher 网络和 Student 网络的输出 logits 来计算 KL Loss,从而实现 dark knowledge 的传递,利用 Teacher 已经学到的知识帮助 Student 收敛得更好。在 KD 之后,更多的基于中间特征的蒸馏方法不断涌现,不断刷新知识蒸馏的 SOTA。但该研究认为,KD 这样的 logits 蒸馏方法具备两点好处:
-
基于 feature 的蒸馏方法需要更多复杂的结构来拉齐特征的尺度和网络的表示能力,而 logits 蒸馏方法更简单高效;
-
相比中间 feature,logits 的语义信息是更 high-level 且更明确的,基于 logits 信号的蒸馏方法也应该具备更高的性能上限,因此,对 logits 蒸馏进行更多的探索是有意义的。
该研究尝试一种拆解的方法来更深入地分析 KD:将 logits 分成两个部分(如图),蓝色部分代表目标类别(target class)的 score,绿色部分代表非目标类别(Non-target class)的 score。这样的拆解使得我们可以重新推导 KD 的 Loss 公式,得到一个新的等价表达式,进而做更多的实验和分析。
2.1 符号定义
这里只写出关键符号定义,更具体的定义请参考论文正文。
首先, 该研究将第 类的分类概率表示为(其中 表示网络输出的 logits):
为了拆解分类网络输出的 logits, 该研究接下来定义了两种新的概率分布 :
1.目标类 vs 非目标类的二分类分布,该概率分布和分类监督信号高度耦合。该分布包含两个元素:目标类概率和全部非目标类概率,分别表示为:
2.非目标类内部竞争的多分类分布 ,也就是在预测样本为非目标类的前提下每个类各自的概率(总和为 1)。这个概率分布和分类的监督信号是不相关的,换句话说,从这个概率分布中无法得知目标类上的预测置信度,其表达式为:
根据上述定义, 可以得到一个显然的数学关系: 。这些定义和数学关系将帮助我们得 到 KD Loss 的一个新的表达形式。
2.2 重新推导 KD Loss
首先,KD 的 Loss 定义如下:
然后根据公式(1)和(2),我们可以将其改写为:
可以观察到, 式中的第一项 只牵涉到了目标类别 vs 非目标类别的二分类概率分布 研究将第一项命名为目标类别知识蒸馏 Target Class Knowledge Distillation (下文简称 TCKD), 将第二项中的 KL 散度命名为非目标类别知识蒸馏 Non-target Class Knowledge Distillation(下文简称 NCKD)。至此, 该研究完成了对 KD Loss 的拆分, 将其分成了两个可单独 使用的部分, 并可以分析其各自的作用:
3 启发式探索
首先,该研究对 TCKD 和 NCKD 做了消融实验,观察它们对蒸馏性能的影响;接着,他们分别探索 TCKD 和 NCKD 的作用;最后,研究者做了一些启发式的讨论。
3.1 单独使用 TCKD/NCKD 训练
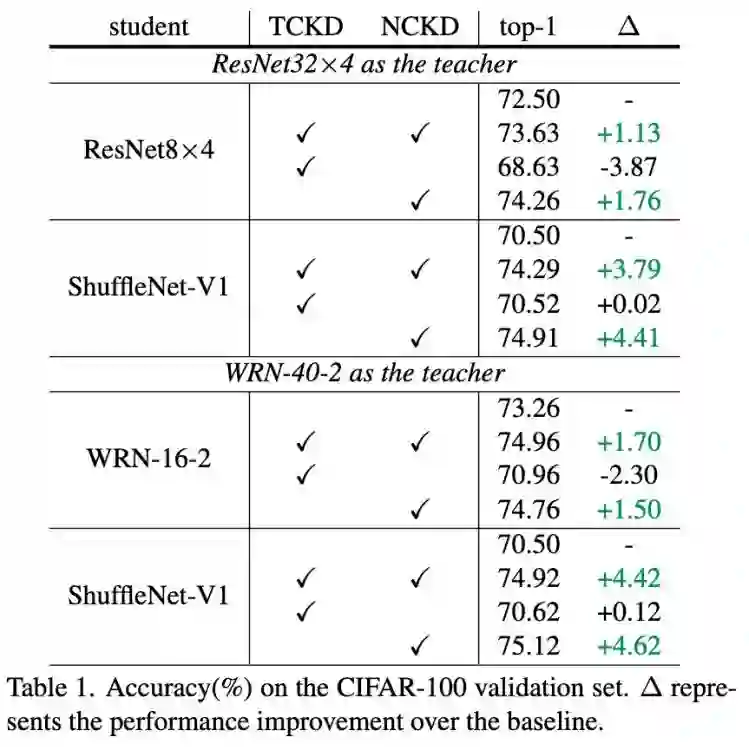
如表 1 所示,我们可以观察到:
1. 同时使用 TCKD 和 NCKD(等同于 KD),有不错的性能提升;
2. 单独使用 TCKD 进行蒸馏,会对蒸馏效果产生较大的损害(这一点在补充材料中有详细讨论,主要和蒸馏温度 T 相关);
3. 单独使用 NCKD 进行蒸馏,和 KD 的效果是差不多的,甚至有时会更好;
基于这些观察可以推出两个初步结论:
1.TCKD 是没用的,甚至在单独使用时可能是有害的;
2.NCKD 可能是 KD 生效的主要原因;
接下来该研究就这两个初步的结论进行了进一步的分析。
3.2 TCKD:传递样本难度相关的知识
TCKD 作用于目标类的二分类概率分布上,这个概率的物理含义是「网络对样本的置信度」。比如:如果一个样本被 Teacher 学会了,会产生类似[0.99, 0.01] 的 binary 概率,而如果一个样本比较难拟合,则会产生类似 [0.6, 0.4] 的 binary 概率。所以该研究猜测:TCKD 传递了和样本拟合难度相关的知识,当训练集拟合难度高时才会起到作用。为了证明这一点,该研究设计了三组实验来增加 CIFAR-100 的训练难度,观察 TCKD 是否有效:
更强的数据增广:
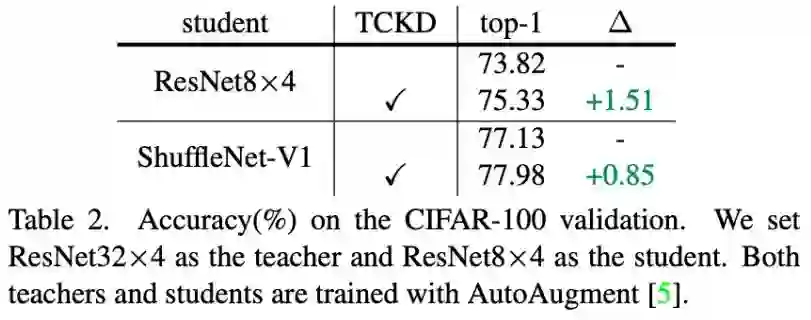
以表 2 中的 ShuffleNet-V1 为例,在使用 AutoAugment 的情况下,训练集难度有了明显提升,此时仅仅使用 NCKD 只能达到 73.8% 的 student 准确率,而同时使用 TCKD 和 NCKD 可以将 student 准确率提升至 75.3%。
更 Noisy 的标签:
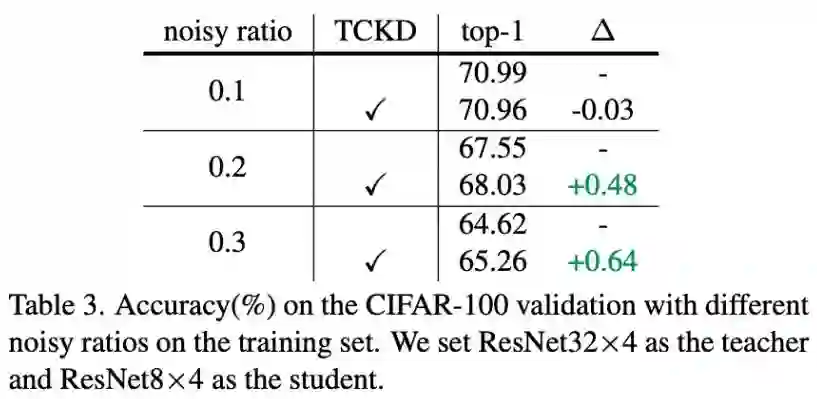
表 3 中,该研究通过控制 noisy ratio 对数据集的标签引入不同程度噪声,ratio 越大表示噪声越大。可以看到,随着数据集的噪声变大,单独使用 NCKD 的效果变得越来越差,同时引入 TCKD 的增益也越来越大。说明在越难学的数据上,TCKD 的作用就会越明显。
更难的数据集:

ImageNet 是一个比 CIFAR-100 更困难的数据集,所以该研究在 ImageNet 上也进行了尝试。从表 4 可以看出,在 ImageNet 上只使用 NCKD 的效果也是没有同时使用 TCKD 和 NCKD 要好的。
总结:
三组实验都反映出,当训练数据拟合难度变高时(无论是数据本身难度、还是噪声和增广带来的难度),TCKD 能提供更有效的知识,对蒸馏性能的提升也越高,这些实验在一定程度上说明了 TCKD 确实是在传递有关样本拟合难度的知识,印证了该研究的想法。
3.3 NCKD:被抑制的重要成分
表 1 中反映出的另一个有趣的现象是:只使用 NCKD 也能取得令人满意的蒸馏效果,甚至可能比 KD 更好。这样的现象反映出:非目标类别上的 logits 中蕴含的信息,才是最主要的 dark knowledge 成分。
然而当回顾 KD 的新表达式时, 发现 NCKD 对应的 loss 是和权重 )耦合在一起的。换言 之, 如果 teacher 网络的预测越置信, NCKD 的 loss 权重就更低, 其作用就会越小。而该研究认 为, teacher 更置信的样本能够提供更有益的 dark knowledge, 和 NCKD 耦合的 权重会 严重抑制高置信度样本的知识迁移, 使得知识蒸馏的效率大幅降低。为了证明这一点, 该研究做了 如下实验:
1. 依据 teacher 模型的置信度,该研究对训练集上的样本做了排序,并将排序后的样本分成置信(置信度 top-50%)和非置信 (剩余) 两个批次;
2. 训练时,对全部样本使用分类 Loss,并只对置信批次 / 非置信批次使用 NCKD Loss;

实验结果如表 5 所示,0-50% 表示置信批次,50-100% 表示非置信批次。第一行是在整个训练集上做 NCKD 的结果,第二行表示只对置信批次做 NCKD,第三行表示只对非置信批次做 NCKD。显然,置信批次上使用 NCKD 带来了更主要的涨点,说明置信度更高的样本对蒸馏的训练过程是更有益的,因此是不应该被抑制的。
3.4 启发
至此,该研究完成了对 KD Loss 的解耦,并且分析了两个部分各自的作用。所有结果都表明,TCKD 和 NCKD 都有自己的重要作用,然而,研究注意到了在原始的 KD Loss 中,TCKD 和 NCKD 是存在不合理的耦合的:
1. 一方面,NCKD 和 耦合,会导致高置信度样本的蒸馏效果大打折扣;
2. 另一方面,TCKD 和 NCKD 是耦合的。然而这两个部分传递的知识是不同的,这样的耦合导致了他们各自的重要性没有办法灵活调整。
4 Decoupled Knowledge Distillation
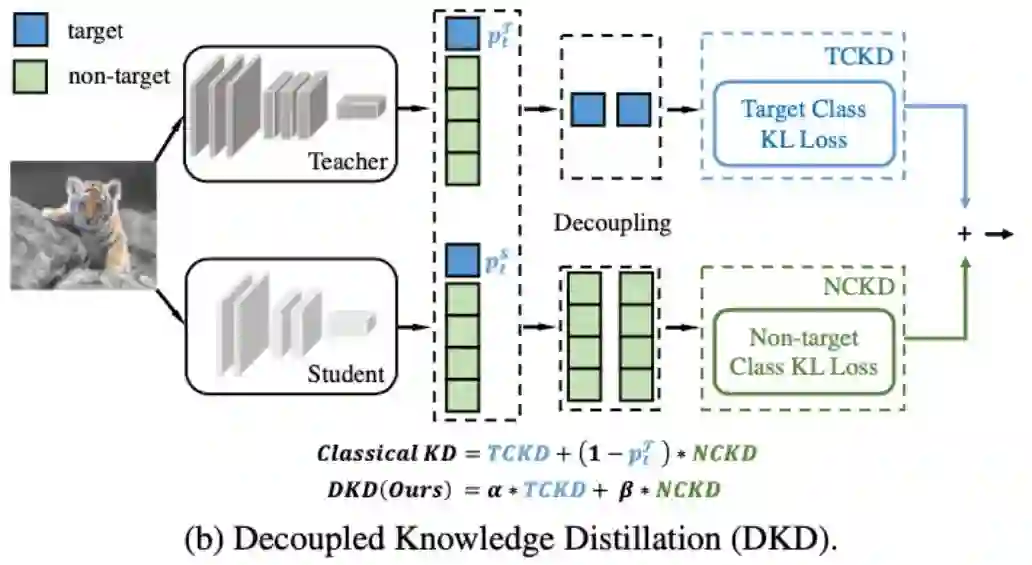
根据推导和启发式探索,该研究提出了一种新的 logits 蒸馏方法“解耦知识蒸馏(DKD)”,来解决上一章提出的两个问题,如上图所示。DKD 的 Loss 表达式如下:
和 KD Loss 相比, 该研究将限制 NCKD 的权重 替换为了 , 并给 TCKD 设置了一个权重 。DKD 可以很好地解决刚才提到的两个问题:一方面, TCKD 和 NCKD 被解耦, 它们各自的重 要性可以独立调节; 另一方面, 对于蒸馏更重要的 NCKD 也不会再被 Teacher 产生的高置信度抑 制, 大大提高了蒸馏的灵活性和有效性。DKD 的伪代码如下:
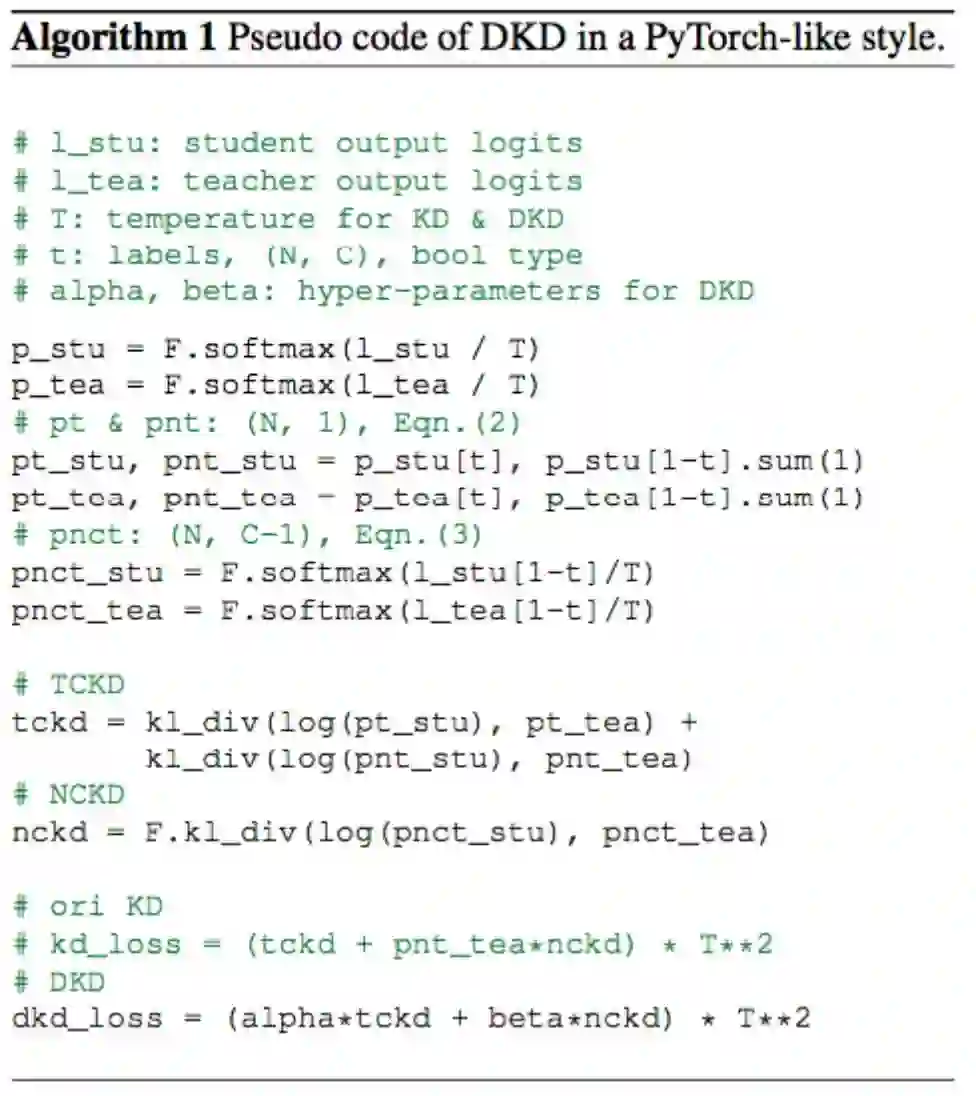
5 实验结果
5.1 Decoupling 带来的好处

首先该研究通过 ablation study 验证了 DKD 的有效性,上面的表格表明:
-
解耦 和 NCKD, 也就是把 设置为 , 可以将 top-1 accuracy 从 提升至 ; -
解藕 NCKD 和 TCKD 的权重, 即进一步调节 的数值, 可以将 top-1 accuracy 从 进一 步提升至 76.3%;
这些实验结果说明 DKD 的解耦确实能带来显著的性能增益, 这一方面证明了 KD 确实存在刚才提 到的两个问题, 另一方面也证明了 DKD 的有效性。此外, 这个表格也证明了 对超参数是不敏感 的, 把 设置为 就可以取得令人满意的效果, 所以在实际应用中只需要调节 即可。同时, 也不是一个敏感的超参数, 在 4.0-10.0 的范围内, 都可以取得令人满意的蒸馏效果。
5.2 图像分类
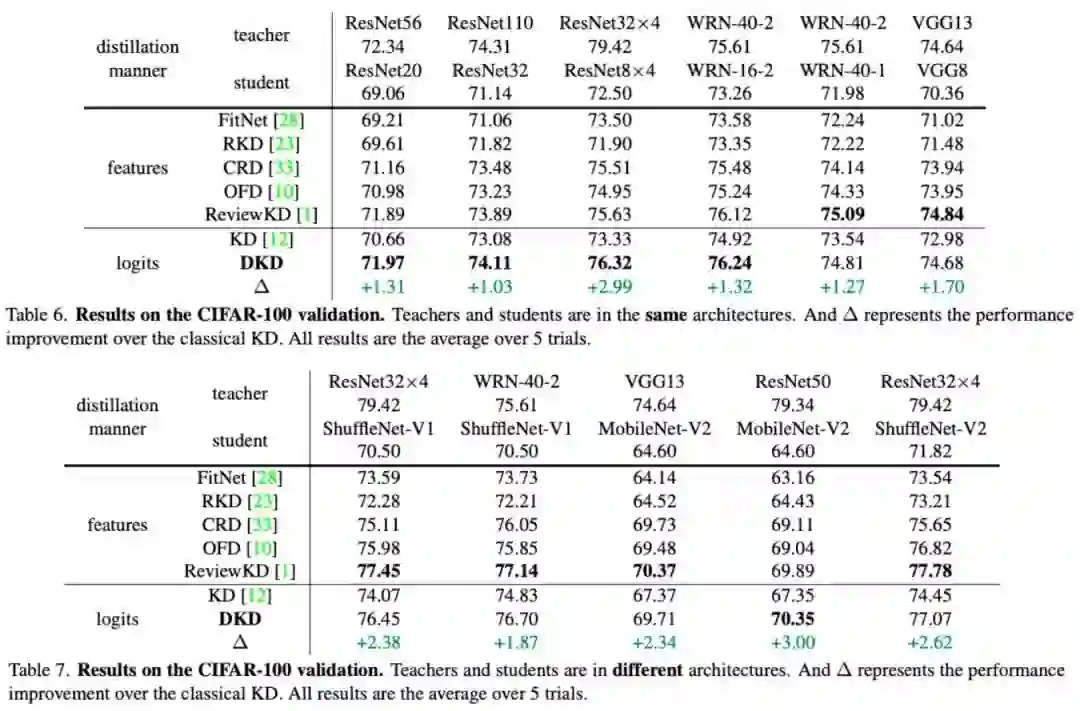
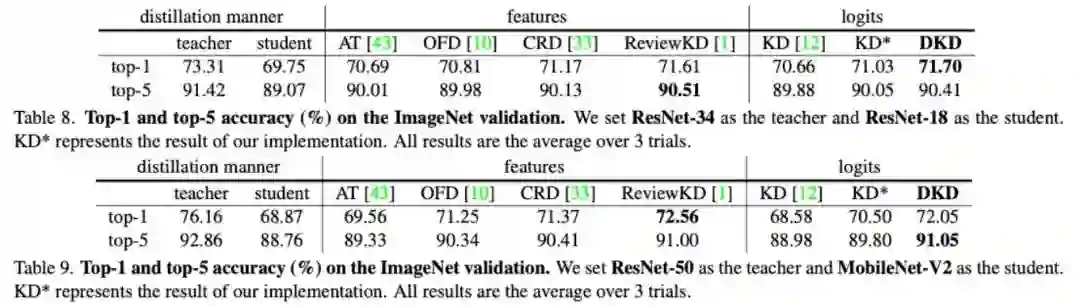
表 6~9 中提供了 DKD 在 CIFAR-100 和 ImageNet-1K 两个分类数据集上的蒸馏效果。和 KD 相比,DKD 在所有数据集和网络结构上都有明显的性能提升。此外,与过去最好的特征蒸馏方法(ReviewKD)相比,DKD 也取得了接近甚至更好的结果。DKD 成功使得 logits 蒸馏方法重新回到了 SOTA 的阵营中。
5.3 目标检测
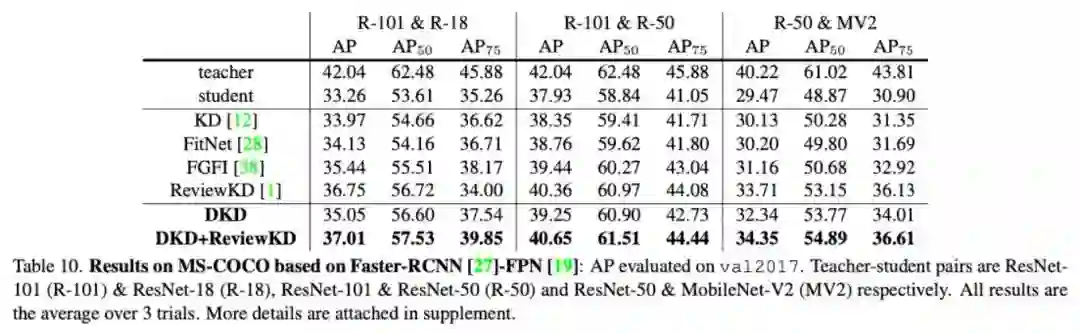
该研究也在目标检测任务(MS-COCO)上验证了 DKD 的性能。如表 10 所示,在 Detector 蒸馏中,DKD 的结果虽不如特征蒸馏的 SOTA 性能,但是依然稳定地超过了 KD 的性能。而将 DKD 和特征蒸馏方法组合起来,也可以进一步提高 SOTA 结果。
关于这一点:过去的一些工作证明了,Detection 任务非常依赖特征的定位能力,这在 Detector 蒸馏中也是成立的(如 [5] 中提到了,feature mimicking 是非常重要的)。而 logits 并不能提供 location 相关的信息,无法对 Student 的定位能力产生帮助,因此在 Detection 任务中,特征蒸馏相比 logits 蒸馏存在机制上的优势,这也是 DKD 无法超过特征蒸馏 SOTA 的原因。
6 扩展性实验和可视化
6.1 训练效率
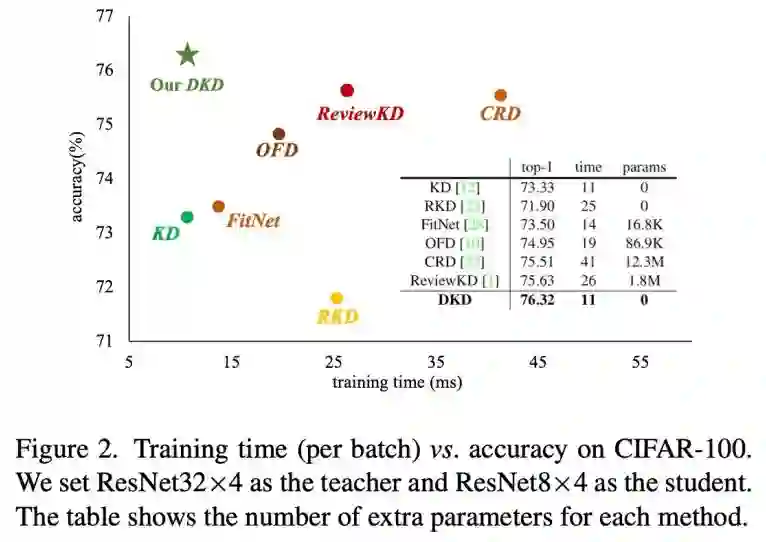
logits 蒸馏的好处之一是训练效率高。为了证明这一点,该研究可视化了 SOTA 蒸馏方法的训练开销。图 2 的 X 轴是每个 batch 的训练时间,Y 轴是 student 的 top-1 accuracy。显然,logits 蒸馏(KD 和 DKD)所需的训练时间是最少的,并且 DKD 用了最少的时间获得了最好的蒸馏效果。图 2 中的表格也提供了训练时间和训练所需的额外参数量,和 KD 一样,DKD 也并没有额外引入参数量,同时训练时间也几乎没有增加。logits 蒸馏的优越性显而易见。
6.2 提升大 Teacher 模型蒸馏效果
过去的一些蒸馏工作发现了一个有趣的现象: 大模型并不一定是好的 Teacher 网络。对于该现象, 研究者提供了一个可能的解释:大模型的 model capacity 很大, 这会导致大模型产生更高的 , 进而导致的 NCKD 被抑制得更严重。过去的一些工作也可以基于这一点解释, 如 ESKD [4] 引入了 early-stopped teacher 来缓解这一问题, 这可能是因为 early-stopped 模型还没有充分拟合训练 集, 还比较小, 所以对 NCKD 的抑制不是很严重。
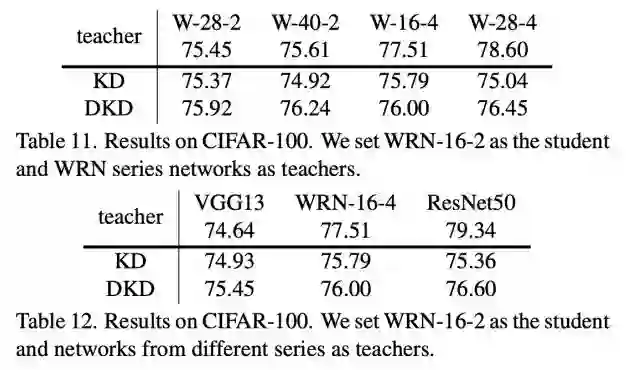
为了证明该观点,研究者也进行了一系列的对比实验。如表 11 和表 12 所示,当使用 DKD 时,大模型蒸馏效果变差的问题被显著改善。该研究希望这一点可以为后续的工作提供一些 insight。
6.3 特征迁移性
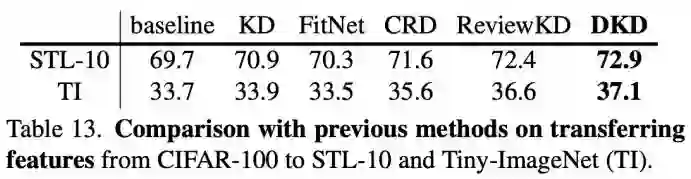
这里该研究尝试将 DKD 训练得到的 student 网络进行特征迁移。如表 13 所示,研究者将在 CIFAR-100 上训练的 student 迁移到了 STL-10 和 TinyImageNet 两个数据集上,在众多的蒸馏方法中,DKD 取得了最好的迁移效果。
6.4 可视化
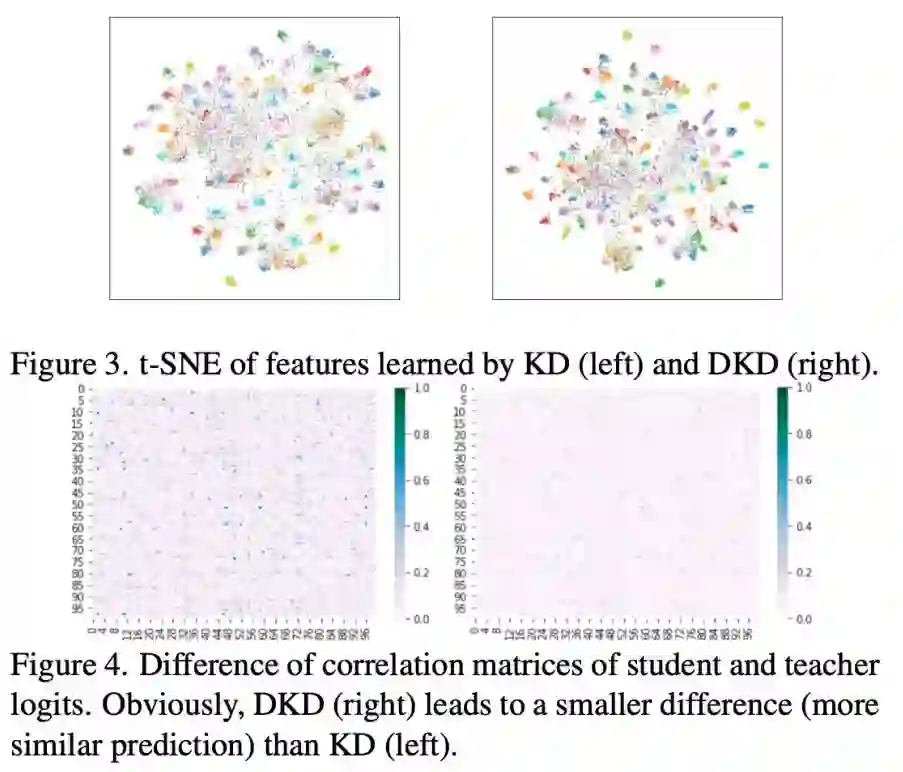
这里研究者提供了两种可视化。图 3 中,与 KD 相比,DKD 的样本聚得更加紧凑,说明 DKD 帮助 student 网络学到了更加可区分的特征。图 4 中,研究者计算了 teacher 网络和 student 网络输出 logits 的相似度,和 KD 相比,DKD 训练后的 student 产生的 logits 会更像 teacher 产生的 logits,说明 teacher 的知识被更好地利用了。
7 改进方向
的自适应调整: DKD 目前还需要手工调整 的值才能达到最佳的蒸馏效果, 该研究希望可以通 过一些训练过程中的统计量实现对 的自适应调节(对于这一点, 该研究已经有了初步的探索, 详 情可见补充材料)。
8 开源代码库 MDistiller
为了保证复现和进一步的探索,该研究还开源了一个知识蒸馏的 codebase MDistiller。该 codebase 涵盖了大部分的 SOTA 方法,同时支持两种蒸馏关注的主要任务,图像分类和目标检测。该研究希望 MDistiller 可以为后续的研究者们提供一套可靠的 baseline,因此会提供长期支持。
参考文献
[1] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. In arXiv:1503.02531, 2015.
[2] Borui Zhao, Quan Cui, Renjie Song, Yiyu Qiu, and Jiajun Liang. Decoupled knowledge distillation. In CVPR, 2022.
[3] Pengguang Chen, Shu Liu, Hengshuang Zhao, and Jiaya Jia. Distilling knowledge via knowledge review. In CVPR, 2021.
[4] Jang Hyun Cho and Bharath Hariharan. On the efficacy of knowledge distillation. In ICCV, 2019.
[5] Tao Wang, Li Yuan, Xiaopeng Zhang, and Jiashi Feng. Distilling object detectors with fine-grained feature imitation. In CVPR, 2019.
公众号后台回复“数据集”获取30+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




