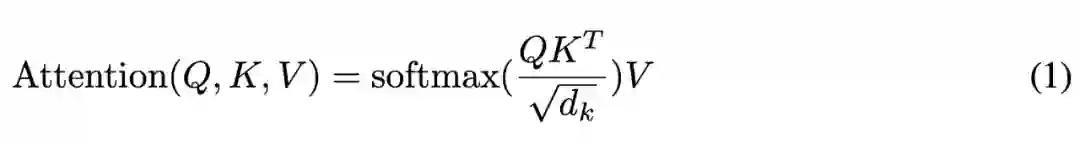在 Transformer 完全采用注意力机制之后,注意力机制有有了哪些改变?哈希算法、Head 之间的信息交流都需要考虑,显存占用、表征能力都不能忽视。
![]()
注意力机制是非常优美而神奇的机制,在神经网络「信息过载」的今天,让 NN 学会只关注特定的部分,无疑会大幅度提升任务的效果与效率。借助注意力机制,神经机器翻译、预训练语言模型等任务获得了前所未有的提升。
但与此同时,注意力机制也面临着重重问题,首先就是参数量太大,这有点类似于全连接层,注意力机制需要考虑两两之间的所有连接。我们可以看到,完全用注意力机制的模型,参数量轻轻松松破个亿,而卷积这类参数共享的运算,参数量一般也就几百万。
如果只是参数量大也就算了,能完整利用这些参数,正是说明模型的表征能力非常强。但问题在于,Transformer 采用的 Multi-head Attention 并没有充分利用参数的表征能力。举个例子,Transformer 中每一个注意力 Head 都是相互独立的,它们之间没有信息交流,因此谷歌最近提出的 Talking-Head 就旨在解决这个问题。
本文从原 Multi-head Attention 出发,探索 Reformer 如何用哈希算法大量降低显存需求,探索 Talking-Head 如何强化全注意力机制的表征能力
。
Transformer 因在大型预训练语言模型中的优秀性能而被世人所熟知。这一类模型已广泛应用于多种预训练语言模型中,如 BERT、GPT-2 等。当然,在广泛应用之余,人们也在思考 Transformer 存在的缺陷,并进行弥补。
提到 Transformer,人们总会想到这类模型最突出的几个特征:点乘注意力、多头注意力、残差连接、Mask 机制等。在最初介绍 Transformer 的论文中,Waswani 等引入了这些优秀的特性,使 Transformer 独树一帜。
在 Transformer 中,首先引入的是注意力点乘机制。它将输入分为查询(Query)、键(Key)和值(Value),通过以下公式计算。其相当于根据序列元素之间的相似性,确定每一个元素都应该关注哪些信息。
![]()
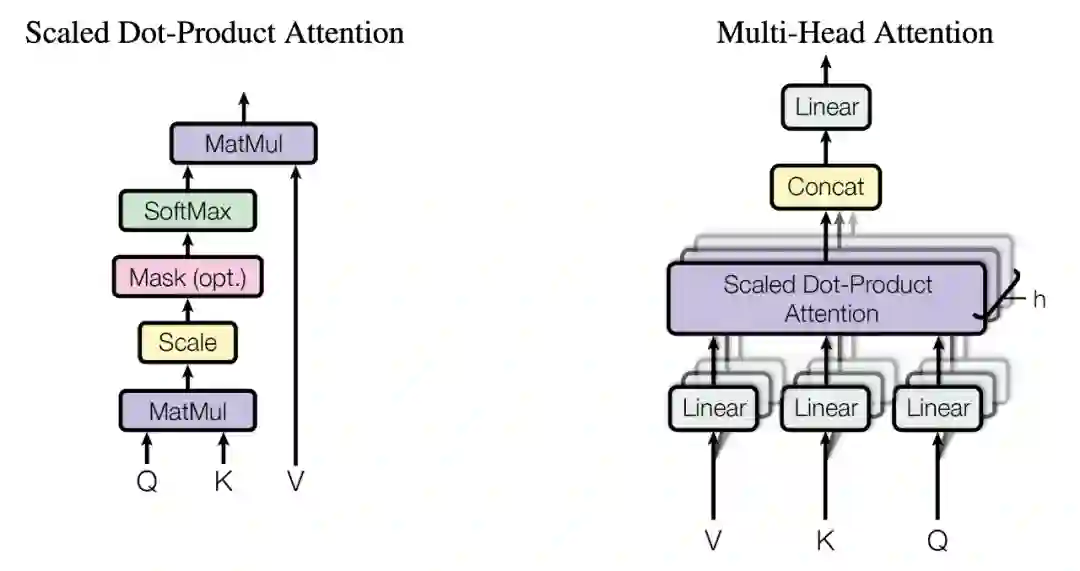
而另一方面,仅计算一次注意力,不足以捕捉所有的文本结构特征。因此,Transformer 的提出者想到类似于 CNN 中的 multi-channel 的方法:让点乘注意力机制「重复」多次。这样一来,Transformer 的模型复杂度显著上升,捕捉了更多的语义和语言特征,这种方法便是我们熟悉的多头注意力。
![]()
图 2:(左)点乘注意力;(右)多头注意力,有多个注意力层并行。
多头注意力的公式如下所示,每一个 Head 都是一个注意力层。为了提高差异性,每一个 Head 的输入张量都会先经过它特有的线性变换,相当于希望该 Head 注意特定的某个方面。
![]()
尽管 Transformer 因为这些特性而产生了很好的性能,但其固有的缺陷也随之而生。特别需要注意的就是多头注意力机制了。在设计之初,为了让不同的注意力头能够捕捉语言模型中的不同特征,不论是 BERT 还是 GPT-2 的设计者都将增加了注意力头的数量。
但是,由于 Query、Key 和 Value 在训练中会进行多次线性变换,且每个头的注意力单独计算,因此产生了大量的冗余参数,也需要极大地显存。
怎样才能降低计算复杂度呢?研究者们在这个问题上思考了很多方法,本文中可以看到采用哈希算法、参数压缩等的方法。这些方法有的是强化多头注意力机制。有的则是利用哈希算法的高效性,替换掉原本的架构,使模型性能更加优秀。
Transformer 因为 Multi-Head Attention 而成功,也因为它而受到重重限制。在 2017 年 Transformer 提出以后,18 年到 19 年已经有很多研究在改进这种注意力机制,这里介绍的是一种「哈希大法」,提出该方法的 Reformer 已经被接收为 ICLR 2020 的 Oral 论文。
ICLR 2020 程序主席评论道:「Reformer 这篇论文提出的新型注意力机制有效减少序列长度的复杂度,同时新机制也减少了存储需求。实验证明它们非常有效,该论文可能对研究社区会产生显著影响。尽管有一些次要的观点,但所有评审者都一致同意接收该论文。」
我们先回到注意力机制,其中非常重要的运算是 Query 与 Key 这两个张量之间的矩阵乘法,其代表着余弦相似性。具体而言,如果 Query 表示翻译领域的中文序列,Key 表示英文序列,那么矩阵乘法则表示在翻译成某个中文词时,需要注意哪些英文词。
但问题在于,Query 与 Key 的张量维度都是 [batch size, length, d_model],乘完后的维度是 [batch size, length, length]。要是序列长度 length 不长也就罢了,但如果上下文跨度很广,需要很长的序列,也就是说 length 远远大于隐藏层大小 d_model。那可就麻烦了,研究者表示要是序列长度达到 64K,注意力机制计算一个样本也需要 16GB 的显存(Float32)。
![]()
你可能会说,我不一次性计算 Query 中的所有序列,而每次只算一步,例如一个中文词,计算它与所有英文词之间的相似性。这样不就没问题了么?这是没问题的,但并没有实质上的改变。
现在,假定序列长度还是 64K,对于 Query 序列中的每一个 q,正常的注意力机制需要计算它和 Key 序列 64K 个元素之间的相似度,并通过 Softmax 将相似度归一化为概率。反正都是要计算概率,且一般只有概率最高的一些元素真正对 q 有很大的贡献,那么为什么不直接找出这些元素?
之前超大的矩阵乘法会计算 Query 序列所有元素与 Key 序列所有元素之间的相似度,现在如果不通过矩阵乘法,只找每个 Query 序列「最相近」的 32 个或 64 个元素,那么显存与计算岂不是成千倍地减少?
这就是 Reformer 最核心的思想,完成查找「最相近」元素的算法即局部敏感哈希算法(Locality sensitive hashing)。
简单而言,局部敏感哈希算法(LSH)在输入数据彼此类似时,它们有很大概率映射后的哈希是一样的;而当输入数据彼此不同,它们映射后的哈希值相等概率极小。
![]()
LSH 算法根据局部敏感哈希函数族将类似的数据映射到相同的桶(Bucket)。
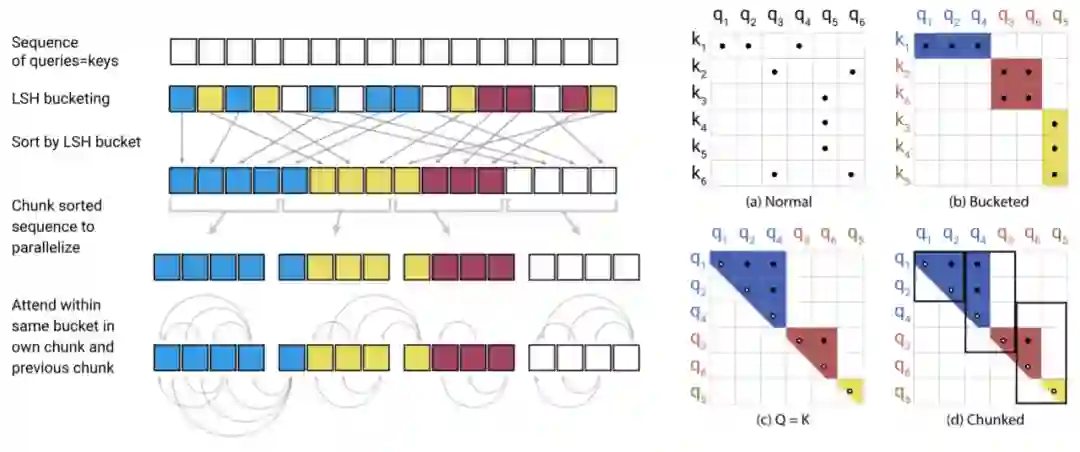
如下图 a 所示,传统注意力机制需要计算 q 与 k 之间的所有相关性,但实际上真正起作用的注意力分配是非常稀疏的。对于图 b 来说,Query 和 Key 会先通过哈希桶排序,相似的 q 与 k 会落在相同的桶内,因此直接在桶内执行注意力计算就能逼近完整的注意力机制。
![]()
然而图 b 只是理想情况,真正用于注意力机制还有很多困难要克服,比如说,一个桶内包含很多 q 而没有一个 k。为此,研究者对 b 执行了一系列转换,并使排序后的注意力权重,来自相同桶的 q 和 v 都集中在对角线上,就如同图 c 一样。注意 c 图中 Q=K,表示 Transformer 中的自注意力机制。
排好序后,d 图就可以分成不同的批量,并完成并行计算。这样不仅计算量与参数量大大减少,还能加速训练。
最后,整个 LSH 注意力机制就如上左图所示。对于自注意力机制,先根据 LSH 分成不同的桶,然后对桶排序并分割为不同的批量,这些批量能够并行处理。最后只要在相同的桶内执行注意力机制就行了,整个过程会节省大量存储与计算资源。
近日,来自 Google 的研究团队提出一种「交谈注意力机制」(Talking-Heads Attention),在 softmax 操作前后引入对多头注意力之间的线性映射,以此增加多个注意力机制间的信息交流。这样的操作虽然增加了模型的计算复杂度,却能够在多项语言处理问题上取得更好的效果。
作者在论文的伪代码中使用大写字母表示张量,而小写字母表示其对应维度大小。同时作者在张量的计算中使用了 einsum 表示法,也就是爱因斯坦求和约定。它在 numpy、tensorflow、pytorch 等 Python 扩展库中均有实现。使用 einsum 表示法能够仅使用一个函数,就可以优雅地实现如点积、外积、转置、矩阵-向量乘法、矩阵-矩阵乘法等运算。
einsum 解释:https://rockt.github.io/2018/04/30/einsum
限于本文篇幅,有关 einsum 表示法的概念,感兴趣的小伙伴可参考上面这篇博客。这里举个栗子,两个矩阵的乘法运算使用 einsum 表示法可写为:
Y[a, c] = einsum(X[a, b], W[b, c])
于是,前面介绍的多头注意力机制使用 einsum 表示法可改写为如下形式:
![]()
同时,einsum 表示法还支持大于两个矩阵作为输入的运算。于是,以上伪代码可进一步精简为如下极简模式:
![]()
不同于多头注意力机制,交谈注意力机制在 softmax 运算的前后增加了两个可学习的线性映射 P_l 与 P_w,这使得多个注意力 logit 和注意力 weight 彼此之间能够相互传递信息。
于是,交谈注意力机制出现了三个不同的维度:h_k、h 和 h_v,其中 h_k 表示 Query 和 Key 的注意力头数量,h 表示 logit 和 weight 的注意力头数量,h_v 则表示值的注意力头数量。其对应伪代码表示如下,注释中标出了每个 einsum 运算所对应的计算量。
![]()
Talking-Head 是 Multi-Head 的延伸
当假设注意力机制的输入与输出维度相同时,可得到计算多头注意力机制所需进行的标量乘法运算数目为:
h·(dk +dv)·(n·dX +m·dM +n·m)
(dk ·hk +dv ·hv)·(n·dX +m·dM +n·m)+n·m·h·(hk +hv)
可以看到上式中第一项与多头注意力机制的计算量类似,而第二项是由交谈注意力中的线性映射导致的。假如 h<d_k 且 h<d_v,那么交谈注意力机制的线性映射计算量,将分别小于对应多头注意力机制中的 n·m·dk ·hk 与 n·m·dv ·hv。
作者指出,由于交谈注意力机制引入了额外的小尺寸张量运算,在实际运行过程中很可能导致速度比 Transformer 更慢。
最后,多头注意力机制与交谈注意力机制都可看作一种「通用双线性多头注意力机制」(GBMA, i.e. general bilinear multihead attention)的特殊形式。我们可以从以下伪代码看出,GBMA 具有两个三维的参数张量。
从以下伪代码不难看出,多头注意力机制在数学上等效于,使用两个因子的乘积分别表示 GBMA 中的各参数张量。
![]()
而交谈注意力机制在数学上等效于,使用三个因子的乘积分别表示 GBMA 中的各参数张量。
![]()
这里的 GBMA 仅作为理论研究探讨,由于其计算量较大可能并不具备实用性。
「注意力」这个想法真的非常优雅,所以 2020 年剩下的是,我们如何才能更高效地实现「注意力」?
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com