【学生论坛】详解记忆增强神经网络


记忆增强神经网络(Memory Augmented Neural Network,MANN)是在传统的神经网络模型基础上增加存储模块以及相应的读写机制的一类模型。
背景1:为什么需要MANNs
•当前的机器学习往往忽略了逻辑流控制(logical flow control)以及外部记忆
•以往的模型无法高效的利用可训练参数来获得较强记忆能力
背景2:模型应用场景
模型可应用于:
•模拟工作记忆(working memory),
•超越训练集分布的泛化,zero-shot,
•复杂的结构信息的捕捉:
•长距离信息依赖建模。
背景3:预备知识介绍--自动机理论与MANNs
MANNs中的一大类是建立在循环神经网络(Recurrent Neural Network,RNN)模型的基础上的,而RNN本身在结构上可以类比有限状态自动机(Definite Finite Automata,DFA)
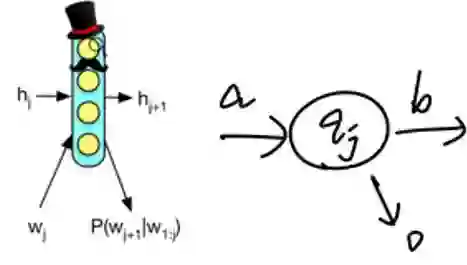
如果这样的类比成立,则进一步的,在普通的RNN模型上加入不同的存储模块则可以类比下推自动机(Pushdown Automata,PDA)、图灵机(Turing Machine,TM)等。
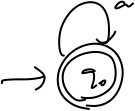
DFA
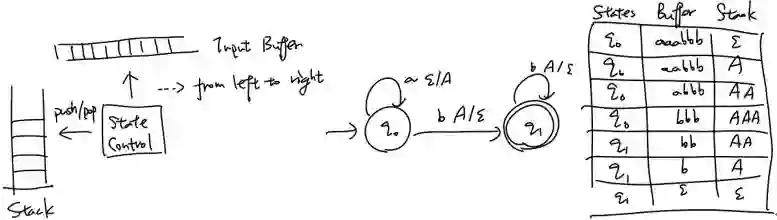
PDA

LBA
从形式语言的角度来说,上下文无关文法(CFG)以及其对应的PDA可以建模程序语言,能够处理递归文法结构,下图简单的以计算表达式的解析(parsing)来举例:

使用栈分析算术表达式语法结构
背景4: 工作记忆机制
本文的主要内容主要围绕短时记忆中的工作记忆展开。工作记忆主要是指个体在执行认知任务中, 对信息暂时储存与操作的能力,强调临时存储以及对存储的信息进行加工处理的能力。
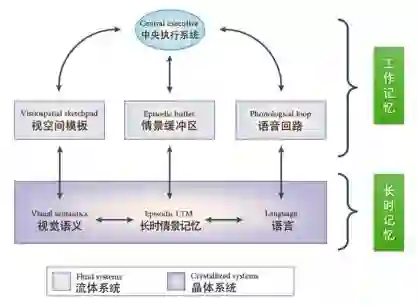
工作记忆模型结构图
与现代计算机(图灵机)相类比,二者都是具有进行临时存储以及调用长match期记忆的match机制,这两个系统也都具有中央控制单元。所以从这一角度来match说,计算机从某种程度上来说可以看作多工作记忆的模仿,而本文涉及到是在模拟工作记忆机制。
分类体系
从分类层次的角度来说,可以如下图进行划分:
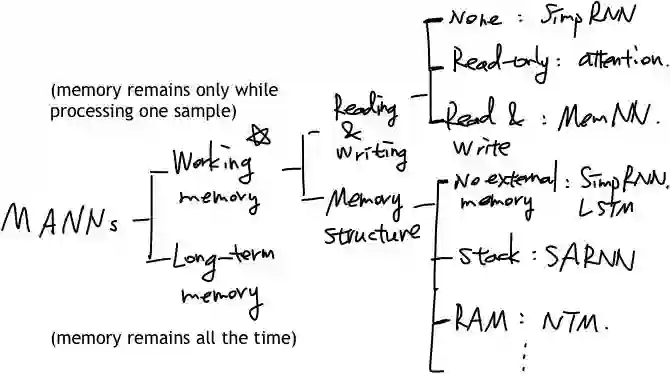
MANNs分类体系
工作记忆相关模型可以按照两个分类方式进行划分,一个是简单的读写match机制的有无,可以分为无读写、只读(如注意力机制,attentmatchion)和既读又写;另一个分类方式是按照存储的结构或者说是按照类比于自动机理论体系的分类方式,分无外部存储、栈式外部存储以及无限制的随机存储。
模型介绍
模型:一般框架
这里列出了两种框架,第一种是MemNN提出的文章中介绍的框架:
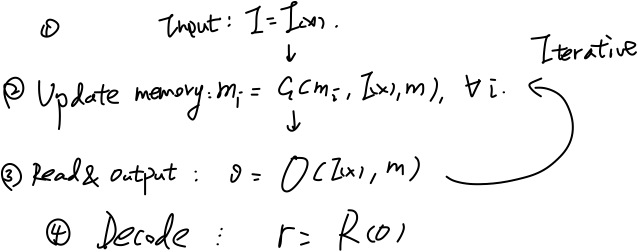
MANN框架一
另一个更加具体的框架适用于下文提到的诸多模型,特别是类比于自动机理论设计的MANNs,框架如图:
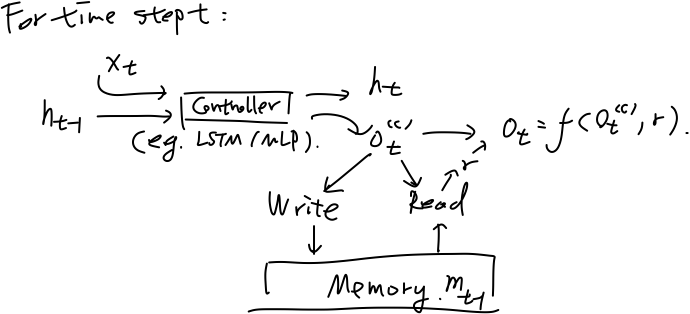
MANN框架二
模型:栈增强的RNN
栈增强的RNN模型(Stack Augmented RNN,SARNN)是在第二种MANN框架的基础上,将存储模块实现为栈式存储,令写可采取动作为压栈(push,压入当前状态的一个转换)、弹栈(pop)以及保持(stay),令读为简单的读取栈。
SARNN结构

实验一:形式文法语言模型任务
任务的目标是预测出某(形式文法)语言的句子的关键部分,与语言模型类似,是给定句子的前一部分的输入,预测下面的字符,具体任务如下图所示:
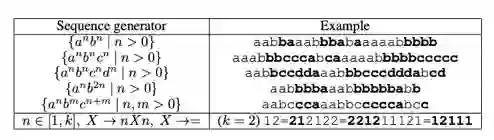
形似文法语言模型任务
其中标黑的为关键部分,评价时以关键部分的预测准确率作为指标。
实验结果如下图:
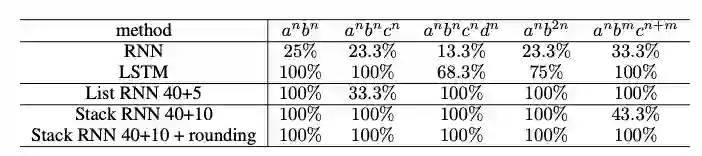
形似文法语言模型任务实验结果
通过分析训练好的SARNN模型的读写模式(下图),可以看出模型学习到了类似于背景知识介绍中提及的自顶向下规约(bottom-up reduction)的策略,不过这里使用了两个栈。
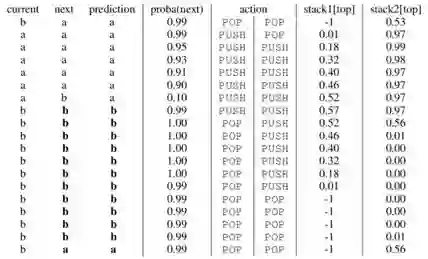
SARNN更新栈动作规律
实验二:位于动词数形式预测的语法依存任务
任务用语言模型的形式来进行,给定自然语言一句话的一部分,预测谓语动词的具体单复数形式。另外任务(样本)的难度也可以依据主语与代判定谓语动词之间所隔名词个数(干扰词,attractors)来划分。

谓语动词单复数预测任务
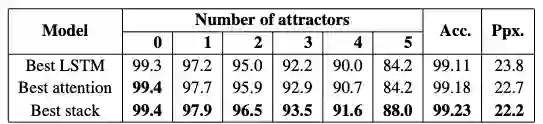
谓语动词单复数预测任务实验结果
模型:神经图灵机
类比:状态机 v.s. RNNs
各种状态机可以与配备不同存储模块的RNN模型相类比,则结合目前已经提到的模型,可以有下列总结:
• DFA 类比 simpRNN
•PDA 类比 stack augmented RNN
•...
则可以自然联想到LBA和图灵机是否也有相应的MANN模型与之对应的模拟呢?
•LBA v.s. ?
•NTM v.s. ?
表达能力 v.s. 学习能力
虽然配备了各种存储模块的RNN相比普通的RNN模型来说模型复杂度更高,但根据Sieglemann & Sontag (1995) 的理论,任何一个图灵机模型
神经图灵机模型的结构
如下图所示,神经图灵机模型(Neural Turing Machine,NTM)模型也可以归为第二类框架,与别的模型的不同也仅在于存储模块是一个可随机访问的数组结构、特别设计的读写方式。

NTM结构
实验一:序列转换拷贝任务
这个任务要求模型读入一个(随机采样的)向量序列,输出同样的向量序列,使用均方误差来评价模型的预测准确性。在该任务上各个模型的训练曲线。
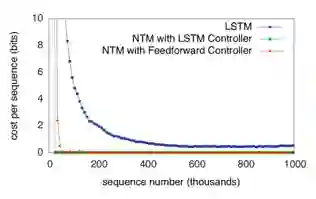
训练曲线
可以发现NTM模型拟合数据集收敛速度更快,一定程度上反映其学习能力较强。对输入输出向量序列进行可视化,可以得到下图:
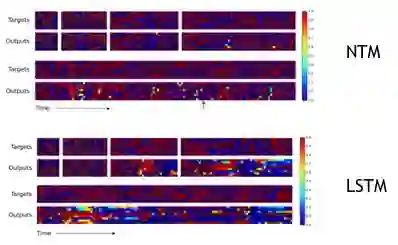
测试可视化结果
实验二:更多的神经科学中关于记忆的序列转换任务
这个实验是关于改进的NTM模型进行的。下面的表格展现的是神经科学中常用的测试记忆能力的实验示意,以接下来要说明的任务“Ignore”为例,表格中这一行中标识代表在不同时刻的输入,
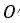



记忆相关任务
使用类似于任务一中的学习到的策略可视化方式可以得到下图:
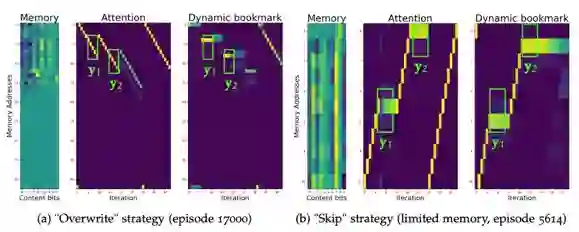
两种可能策略
在这一任务于之前的任务不同,理论分析可知应有两个策略能够完成这一任务,即覆盖策略(overwrite)和略过(skip)策略:
•覆盖策略:模型依次存入子序列


• 略过策略:模型依次存入子序列

模型:情景记忆
情景记忆简介:与其他MANNs的区别
本文的分类体系里归为工作记忆/短时记忆(可能有一些概念上的混淆)。从模型设计的角度来说,一般的情景记忆模型的信息处理是在编码之后进行的。
实现细节
回顾MANN框架介绍中的第一类框架,
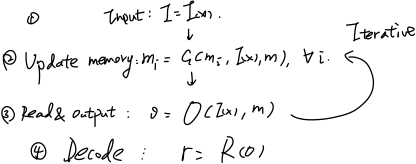
MANN第一类框架
在这一框架中的第(2)步与第(3)步中,信息处理可以表达为:

其中

与其他MANNs模型的寻址面临的问题一样,这一寻址操作并不可微,也可以采用访问内存单元的期望近似:

一组句子{Xi}使用两组embedding(A和C)表示,这里句子向量的表示采用简单的词向量加权求和的方式表达:


其中Lj和TA(i)用于表达位置信息。模型每次寻址读取内存内容的方式为:


也即用期望近似寻址读取内存。

所采用的embedding,可以简单的采取如下方式:


使用表示当前推理时刻的状态表示,对其更新方式为:

其中

实验一:阅读理解式回答
该任务是给定一些已知事实(若干个句子,往往时序相关),给一个问题,在词表中选出一个单词作为答案。如下表所示:

阅读理解式问答样例
每一列代表一个样本,黑色字体的句子为已知事实,蓝色字体的句子为问题,红色字体标出的是答案。解决这类问题的一般策略为根据答案在已知事实中逆向回溯寻找答案(backward chaining,回退式链式推理)。下表给出各个模型的准确率对比:
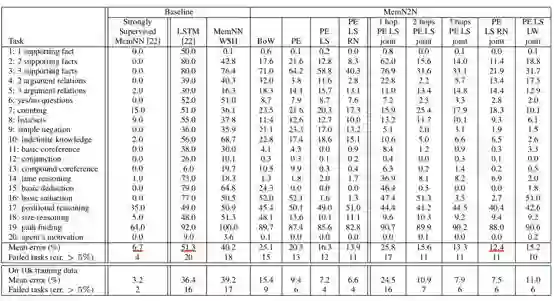
阅读理解式问答实验结果
其中,第二列标出的“Strongly Supervised MemNN”为在这节提到的模型的基础上训练阶段给出强监督信息(即被指示每个推理阶段应关注哪个词)训练得到的模型。可以看出使用情景记忆的模型MemN2N可以在不使用强监督信息的情况下取得相对较好的性能。
该模型在这个任务上学习到的策略为上文提及的backward chaining,将每一个推理时刻模型关注到不同句子的强度可视化,可以得到下图:
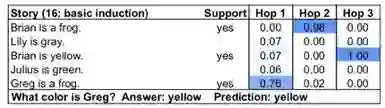
backward chaining策略
任务二:逻辑推理
这里的逻辑推理任务是用prolog程序表达的。样例如下表所示:

prolog逻辑推理任务样例
实验结果如下表(IMA为针对任务设计的模型,DMN为较通用的情景记忆模型):
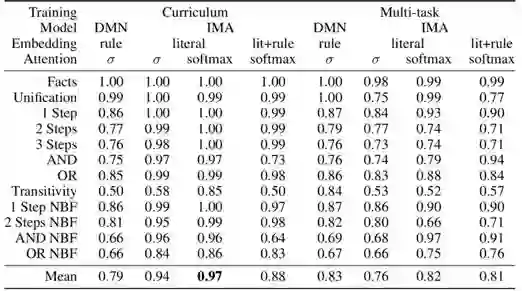
prolog逻辑推理任务实验结果
其学习到的策略与之前任务中展示的类似:
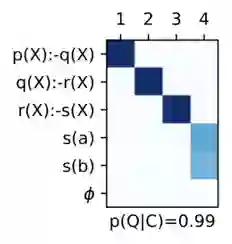
逻辑推理中的backward chaining策略
模型:一个长期记忆的例子
长期记忆简介
与工作记忆不同,长期记忆主要关注样本之间的相关性(适用于样本稀疏情形)或是充分利用某些样本信息来辅助学习过程。
神经主题模型
神经主题模型(Neural Topic Model)关注解决短文本分类任务,即待分类的文本长度较短。这类样本常常由于文本蕴含信息不全难以完成分类任务,一个简单的例子:

短文本分类任务样例
实验结果
这个模型在多个短文本数据集(新闻、Twitter数据、微博数据)上进行了实验,与其他模型可以拉开较大差距。

实验结果
分析其信息处理机制,对测试样本处理过程中,处理单词“wristband”时模型对给个主题词关注强度进行可视化,得到下图:
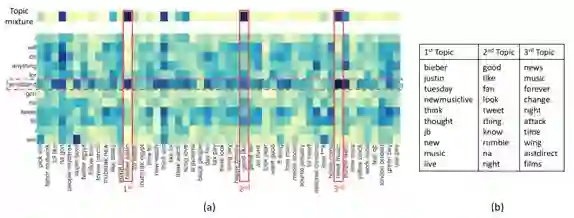
神经主题模型对主题词关注强度可视化
可以看出,模型对最相关的主题词“biber justin”关注强度最大,与之前分析一致。
总结
提炼本文的总结的重要观点如下:
•自动机模型与记忆增强RNNs之间的类比关系
•工作记忆与计算机/图灵机的类比关系
•配备栈的模型能够处理一些递归结构
•可以使用回退式链式推理来处理逻辑推理
•表达能力与学习能力的关系:任何图灵机模型都可以使用RNN模型来表达
参考文献及原文献请点击阅读原文!
Story of Convolution Network – 卷积网络的故事(Part 4):从深度学习的角度分析David Hubel和Torsten Wiesel的成果,研究者们得到了简化的大脑功能分区图。在这个简化的图中,研究者们着重关注了被称为 V1区的脑区——也称初级视觉皮层(primary visual cortex)。
AI爱新词

文章为作者独立观点,不代表自动化所立场。
更多精彩内容,欢迎关注
中科院自动化所官方网站:
http://www.ia.ac.cn
欢迎后台留言、推荐您感兴趣的话题、内容或资讯,小编恭候您的意见和建议!如需转载或投稿,请后台私信。
作者:王克欣
审稿:周玉
文稿:SFFAI(人工智能前沿学术论坛)
来源:人工智能前沿讲习班
排版:康扬名
编辑:鲁宁


中科院自动化研究所
微信:casia1956
欢迎搭乘自动化所AI旗舰号!


