SFFAI 分享 | 王克欣 : 详解记忆增强神经网络

关注文章公众号
回复"记忆增强神经网络"获取PPT与视频资料
目录
记忆增强神经网络
1. 报告主题简介
1.介绍
1.1 背景1:为什么需要MANNs
1.2 背景2:模型应用场景
1.3 背景3:预备知识介绍--自动机理论与MANNs
1.4 背景4:预备知识介绍--工作记忆机制
1.5 背景5:小结
2. 推文内容
1. 分类体系
2. 模型介绍
2.1 一般框架
2.2 模型:栈增强的RNN
模型简介
实验一:形式文法语言模型任务
实验二:谓语动词数形式预测的句法依存任务
2.3 模型:神经图灵机
类比:状态机 v.s. RNNs
表达能力 v.s. 学习能力
神经图灵机模型的结构
实验一:序列转换拷贝任务
实验二:更多的神经科学中关于记忆的序列转换任务
2.4 模型:情景记忆
情景记忆简介:与其他MANNs的区别
实现细节
实验一:阅读理解式问答
任务二:逻辑推理
2.5 模型:一个长期记忆的例子
长期记忆简介
神经主题模型
实验结果
3. 总结
4. 参考文献
1.报告主题简介
1. 介绍
记忆增强神经网络(Memory Augmented NeuralNetwork,MANN)是在传统的神经网络模型基础上增加存储模块以及相应的读写机制的一类模型。
1.1 背景1:为什么需要MANNs
• 当前的机器学习往往忽略了逻辑流控制(logical flowcontrol)以及外部记忆目前的机器学习模型一般不会建模复杂的逻辑流控制,也一般没有外部记忆(相对于使用内部隐层节点进行记忆),从而难以像MANN一样学习到解决问题的显式策略。
• 以往的模型无法高效的利用可训练参数来获得较强记忆能力目前的模型,如GRU、LSTM等在处理任务时是有一定的记忆能力的,但是这种记忆能力是受可训练参数数目影响的;而记忆增强神经网络则是要摆脱可训练参数与模型的记忆能力之间的联系,高效的利用可训练参数。
1.2 背景2:模型应用场景
• 模拟工作记忆(working memory):MANN能够模拟人脑的工作记忆机制,如阅读理解问答中的反向链式推理(backward chaining),以及一些运算过程、算法等。
• 超越训练集分布的泛化,zero-shot:MANN在一些任务上可以学习到显示的策略、规则,可以在非同分布但同规则的测试场景下泛化;这里的泛化相比一般的zero-shot、one-shot、领域自适应算法来说不必重新训练。
• 复杂的结构信息的捕捉:一些MANN模型可以建模复杂的(递归)结构,如使用栈(stack)增强的神经网络可以递归的处理短语结构文法。
• 长距离信息依赖建模:由于记忆增强神经网络的相对记忆能力更强,更容易建模长距离依赖关系。
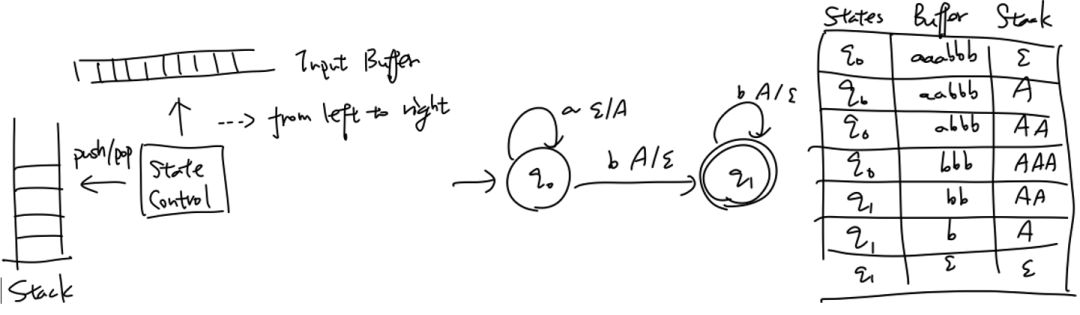
1.3 背景3:预备知识介绍--自动机理论与MANNs
MANNs中的一大类是建立在循环神经网络(Recurrent Neural Network,RNN)模型的基础上的,而RNN本身在结构上可以类比有限状态自动机(Definite FiniteAutomata,DFA),如下图:
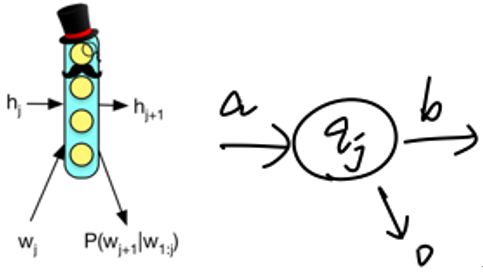
图一:RNN v.s. 状态机
RNN模型一般是在当前时刻读入一个输入
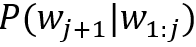
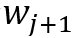
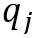
如果这样的类比成立,则进一步的,在普通的RNN模型上加入不同的存储模块则可以类比下推自动机(Pushdown Automata,PDA)、图灵机(Turing Machine,TM)等。
这里先回顾一下形式语言与自动机理论,下图和表格分别为乔姆斯基文法体系以及自动机与文法间的对照关系:
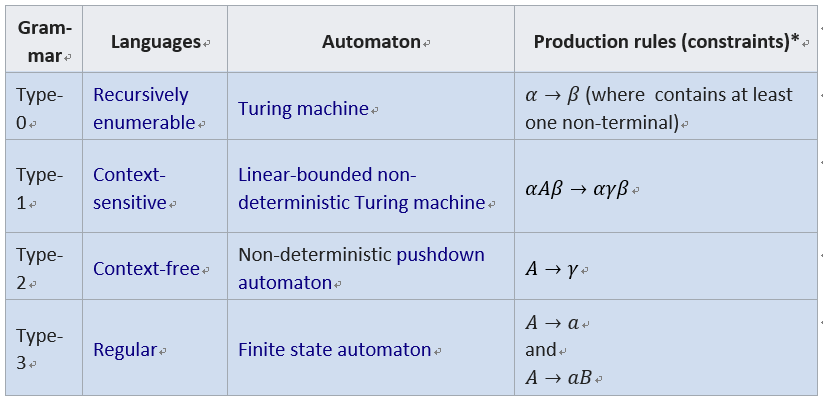
表一:形式文法与自动机对照
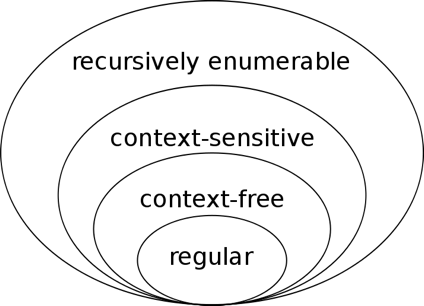
图二:乔姆斯基文法体系
举例来说,DFA可以接受语言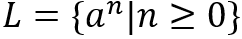
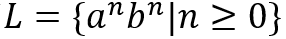
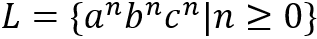
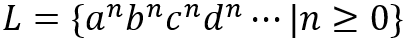
图三:DFA
图四:PDA
图五:LBA
从形式语言的角度来说,上下文无关文法(CFG)以及其对应的PDA可以建模程序语言,能够处理递归文法结构,下图简单的以计算表达式的解析(parsing)来举例:

图六:使用栈分析算术表达式语法结构
一般认为上下文有关文法(CSG)可以建模自然语言,而更复杂的无限制文法对应的图灵机则可建模所有的可计算问题(简单理解也即可以处理所有算法)。另一个相关的概念是图灵完备(turing complete),是说可以模拟任何一个图灵机的模型,也就是说可以处理任何一个算法,如我们现有的冯诺伊曼体系结构下的现代计算机。这个概念下文中会再次提及。
1.4 背景4:预备知识介绍--工作记忆机制
从认知神经科学角度,记忆按照维持时间长短可以分为短时记忆(感觉记忆的毫秒级至短时记忆的分钟级)与长时记忆(常为天级及以上),分类体系如下图:
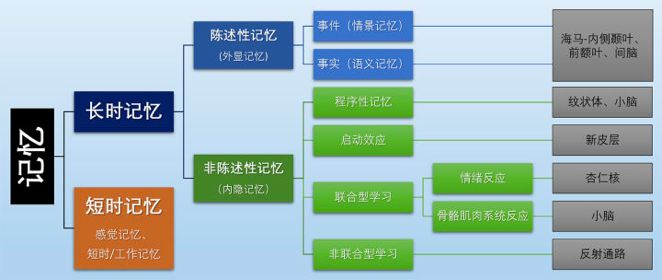
图七:记忆分类体系
这次介绍的主要内容也主要围绕着短时记忆中的工作记忆展开,长时记忆也略有涉及。工作记忆主要是指个体在执行认知任务中, 对信息暂时储存与操作的能力。工作记忆的概念强调临时存储以及对存储的信息进行加工处理的能力,如下图所示:
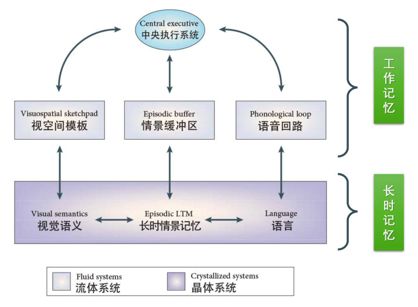
图七:工作记忆模型结构图
可以将工作记忆与现代计算机(图灵机)相类比,二者都是具有进行临时存储(计算机的内存)以及调用长期记忆(计算机的外存)的机制,这两个系统也都具有中央控制单元(计算机的CPU)。所以从这一角度来说,计算机从某种程度上来说可以看作多工作记忆的模仿,而本文涉及到的记忆增强神经网络中的一大类也是有着相似的结构组成,可以说是在模拟工作记忆机制。
1.5 背景5:小结
• 有着越复杂的存储的状态机模型可以确定/处理越复杂的文法/问题
• 配备栈的状态机可以处理一些递归文法
• 图灵机可以处理可计算问题,也即处理所有算法
• 计算机(图灵机)可以看作对工作记忆机制的类比
2.记忆增强网络
1. 分类体系
从分类层次的角度来说,可以如下图进行划分:
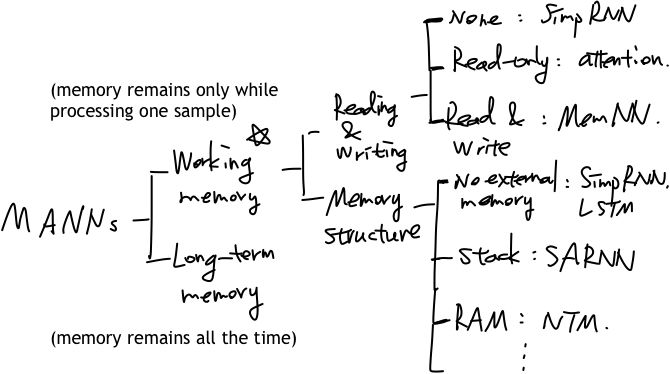
图八:MANNs分类体系
在机器学习模型中,工作记忆指的是记忆仅存在于处理一个样本的过程中,而长期记忆指的是记忆一直存在,本文主要关注工作记忆相关的模型。工作记忆相关模型可以按照两个分类方式进行划分,一个是简单的读写机制的有无,可以分为无读写(如普通的RNN模型,这里简写为SimpRNN)、只读(如注意力机制,attention)和既读又写(如MemNN模型等);另一个分类方式是按照存储的结构或者说是按照类比于自动机理论体系的分类方式,分为无外部存储(如普通RNN、LSTM模型等)、栈式外部存储(如栈增强的神经网络模型,SARNN)以及无限制的随机存储(如神经图灵机)等。
2. 模型介绍
2.1 一般框架
这里列出了两种框架,第一种是MemNN提出的文章中介绍的框架:
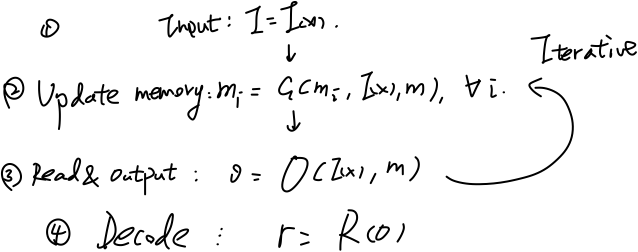
图九:MANN框架一
在第一种框架中,模型(1)先对输入x进行特征映射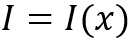
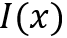
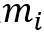
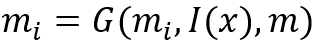
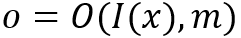
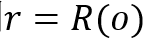
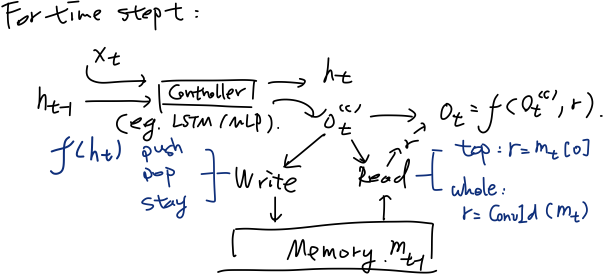
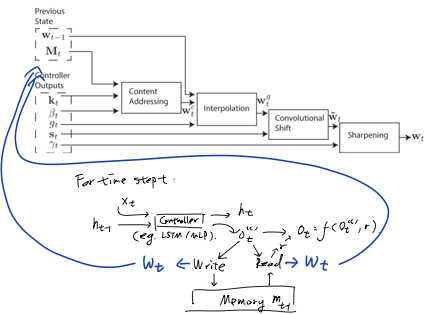
另一个更加具体的框架适用于下文提到的诸多模型,特别是类比于自动机理论设计的MANNs,框架如图:
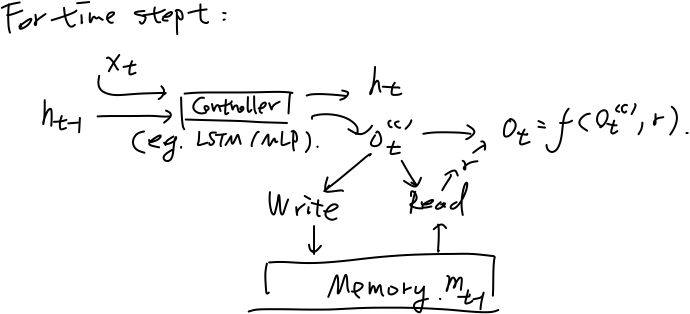
该框架由控制器、存储模块和读写机制构成。控制器一般用LSTM/MLP(多层前馈神经网络)实现,对于t时刻,类似于一般的RNN结构,控制器读入上一时刻的(控制器)状态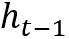
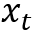
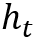
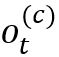
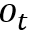
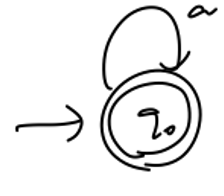
2.2 模型:栈增强的RNN
模型简介
栈增强的RNN模型(StackAugmented RNN,SARNN)是在第二种MANN框架的基础上,将存储模块实现为栈式存储,令写可采取动作为压栈(push,压入当前状态的一个转换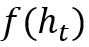
图十一:SARNN结构
这里需要注意的是,正常的压栈弹栈操作是不可微的,所以这里可以使用期望近似(分别为对栈内部元素更新操作和栈顶元素更新操作):
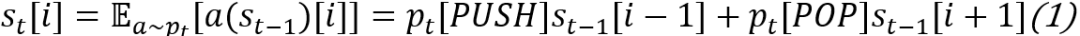
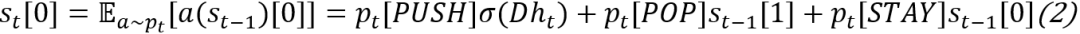
,从而使反向传播可以进行。这一技巧在MANNs中很常见,下文会再次提及。
实验一:形式文法语言模型任务
任务的目标是预测出某(形式文法)语言的句子的关键部分,与语言模型类似,是给定句子的前一部分的输入,预测下面的字符,具体任务如下图所示:
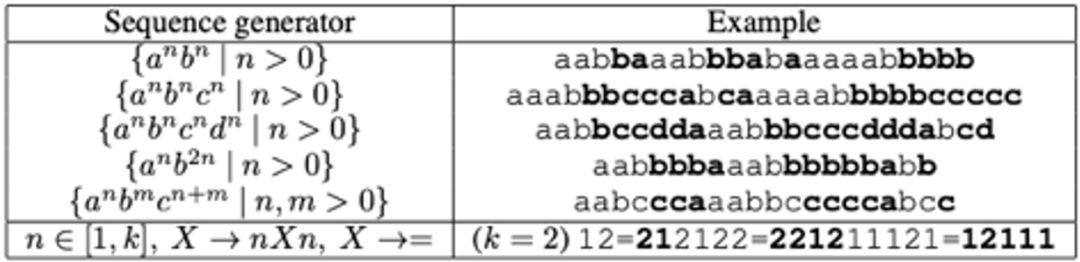
表二:形似文法语言模型任务
其中标黑的为关键部分,评价时以关键部分的预测准确率作为指标。
实验结果如下图:

表三:形似文法语言模型任务实验结果
通过分析训练好的SARNN模型的读写模式(下图),可以看出模型学习到了类似于背景知识介绍中提及的自顶向下规约(bottom-up reduction)的策略,不过这里使用了两个栈。
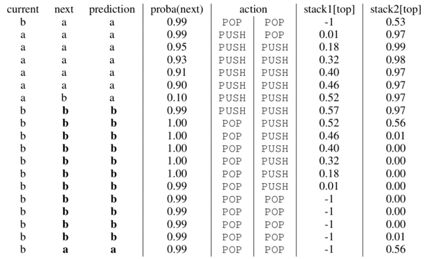
表四:SARNN更新栈动作规律
实验二:谓语动词数形式预测的句法依存任务
这个任务也是用语言模型的形式来进行的,给定自然语言一句话的一部分(截止到谓语动词之前),预测谓语动词的具体单复数形式,如下图例子,给定“this robot”,需要预测下一个接的动词是“is”还是“are”。另外任务(样本)的难度可以依据主语与代判定谓语动词之间所隔名词个数(干扰词,attractors)来划分,如下图的第三个句子包含了个名词的干扰,应当来说比第一个句子更难处理。

图十二:谓语动词单复数预测任务
实验结果如下图:
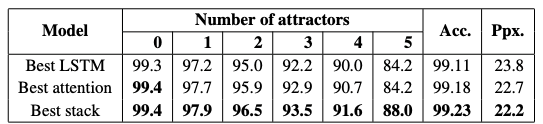
表五:谓语动词单复数预测任务实验结果
SARNN模型在干扰词较多时能够与普通的LSTM模型、注意力机制模型拉开较大指标差距。
分析控制器预测动作的分布(如下图),并且同时观测下一预测词的分布的熵(下图中的绿色点大小表示),可以发现当下一预测词的熵较大时,模型会倾向于将其如栈,可以理解为将信息量较大的(名词等)保存下来,从而一定程度上解决长距离依赖问题。
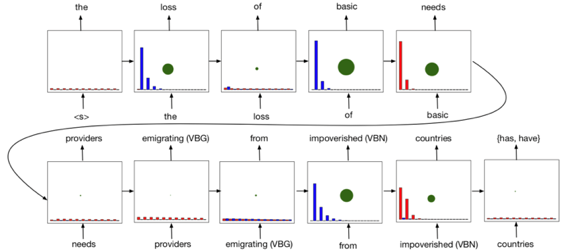
图十三:SARNN学习到的策略
2.3 模型:神经图灵机
类比:状态机 v.s. RNNs
如同背景知识介绍里提到的一样,各种状态机可以与配备不同存储模块的RNN模型相类比,则结合目前已经提到的模型,可以有下列总结:
• DFA 类比 simpRNN
• PDA 类比 stack augmentedRNN
• ...
则可以自然联想到LBA和图灵机是否也有相应的MANN模型与之对应的模拟呢?
• LBA v.s. ?
• NTM v.s. ?
表达能力 v.s. 学习能力
虽然配备了各种存储模块的RNN相比普通的RNN模型来说模型复杂度更高,但根据Sieglemann & Sontag(1995) 的理论,任何一个图灵机模型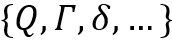
• 使用维度为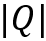
• 对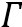
• 使用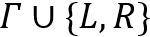
• 使用单位矩阵作为reccurence矩阵,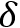
这也就是说,理论上任何一个图灵机模型都可以通过参数设置来表达为一个RNN模型,也即普通RNN模型的表达能力足以处理任何一个可计算问题。这样就引发了一个问题,为什么还需要更复杂的MANN模型,仅仅使用普通RNN模型不就够了吗?问题的关键在于表达能力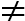
神经图灵机模型的结构
如下图所示,神经图灵机模型(Neural Turing Machine,NTM)与上文介绍的SARNN模型一样,NTM模型也可以归为第二类框架,与别的模型的不同也仅在于存储模块是一个可随机访问的数组结构、特别设计的读写方式。
图十四:NTM结构
NTM模型的读写都涉及到同样的寻址方式,即由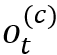
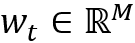
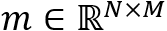
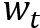
• 首先将控制器输出
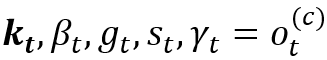
• 内容寻址(contentaddressing):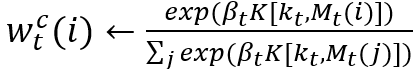
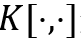
• 差值运算: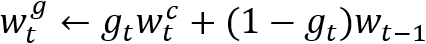
• 卷积(循环)移位: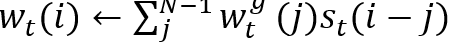
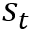
• 锐化操作: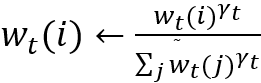
总的来说,NTM的寻址过程就是先全局范围的寻址(内容寻址),再参考上一时刻寻址信息(差值运算)以及进行局部微调(卷积循环移位),再经读写位置锐化得到最终寻址位置。
得到了寻址位置
• 读操作: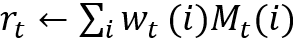
• 写操作: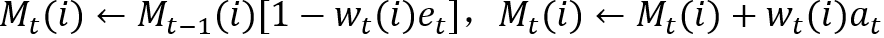
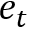
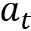
实验一:序列转换拷贝任务
这个任务要求模型读入一个(随机采样的)向量序列,输出同样的向量序列,使用均方误差来评价模型的预测准确性。在该任务上各个模型的训练曲线如下图:
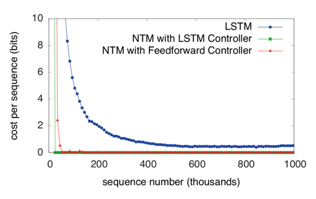
图十五:训练曲线
可以发现NTM模型拟合数据集收敛速度更快,一定程度上反映其学习能力较强。对输入输出向量序列进行可视化,可以得到下图:
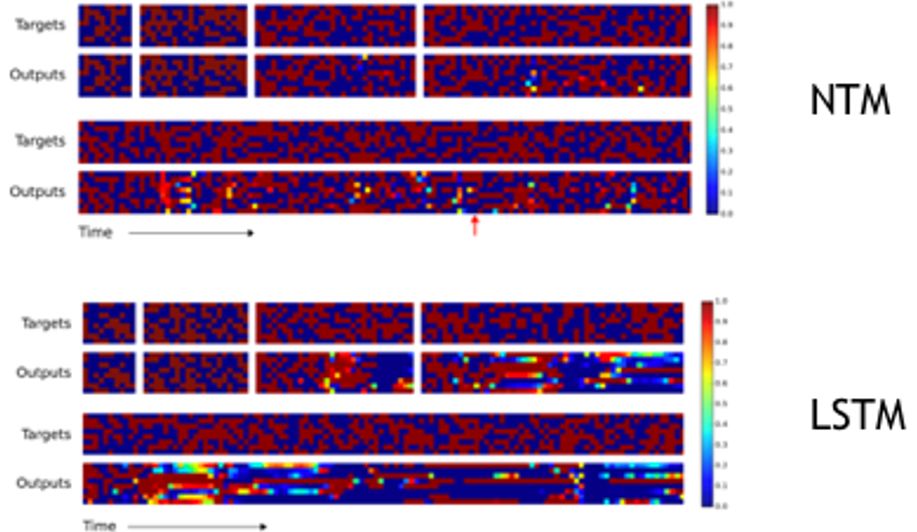
图十六:测试可视化结果
这两张图分别为NTM和LSTM的样例测试结果,这里每一个模型都分别在同训练集分布的测试集上(序列长度较短)和非同分布测试集上(序列长度较长)测试,可以发现NTM在这两种情形下均可实现较准确的拷贝,而LSTM仅局限于同分布测试集上的泛化。
究其原因,可以将NTM模型进行样本处理时的读写位置可视化,探究其学习到的策略:
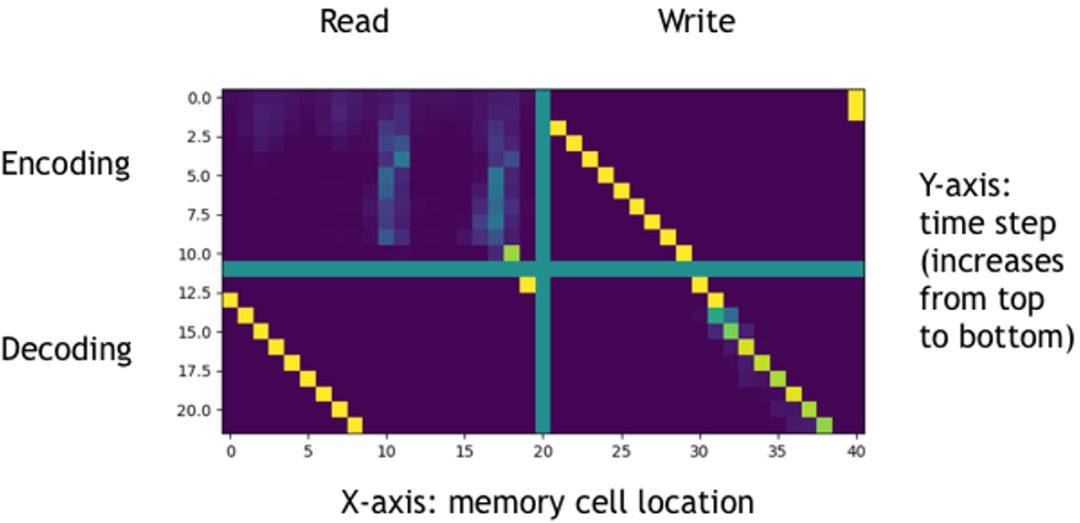
图十七:NTM读写策略
上图中横坐标为存储单元的位置,纵坐标为时刻(从上至下时刻递增),使用绿色线分隔得到的四张图的上边两张对应编码阶段,下边两张对应解码阶段,左边两张和右边两张分别对应读和写,图中像素点约接近黄色代表强度越大。进过分析,可知NTM在拷贝任务上学习到的策略为:
• 编码阶段,将读入的数据向量依次相邻的写入内存的连续位置(若越界溢出则循环写入)
• 解码阶段,将编码阶段写入的数据向量按写入的位置依次连续循环的读出
可以推测,模型在非同分布但同规则的数据集上,仍可以保持这一策略,则可以完成同规则数据集上的泛化。
实验二:更多的神经科学中关于记忆的序列转换任务
这个实验是关于改进的NTM模型进行的。下面的表格展现的是神经科学中常用的测试记忆能力的实验示意,以接下来要说明的任务“Ignore”为例,表格中这一行中标识的代表在不同时刻的输入,O代表在不同时刻的输出,输入是一串序列
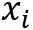
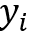

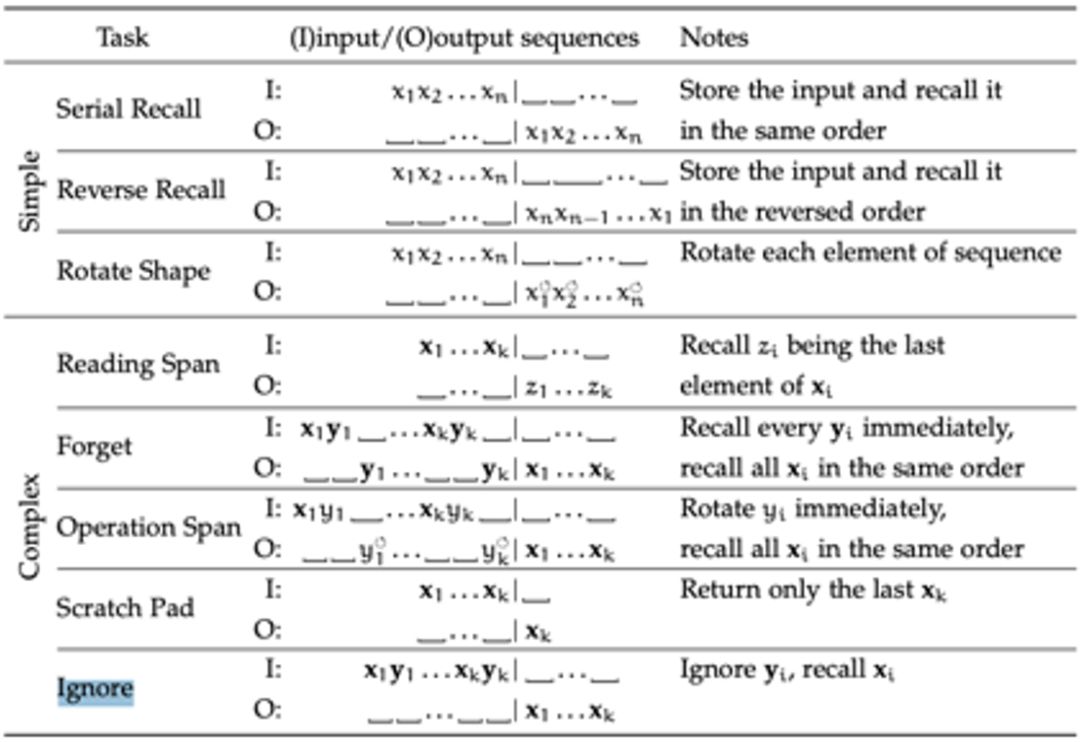
表五:记忆相关任务
使用类似于任务一中的学习到的策略可视化方式可以得到下图:
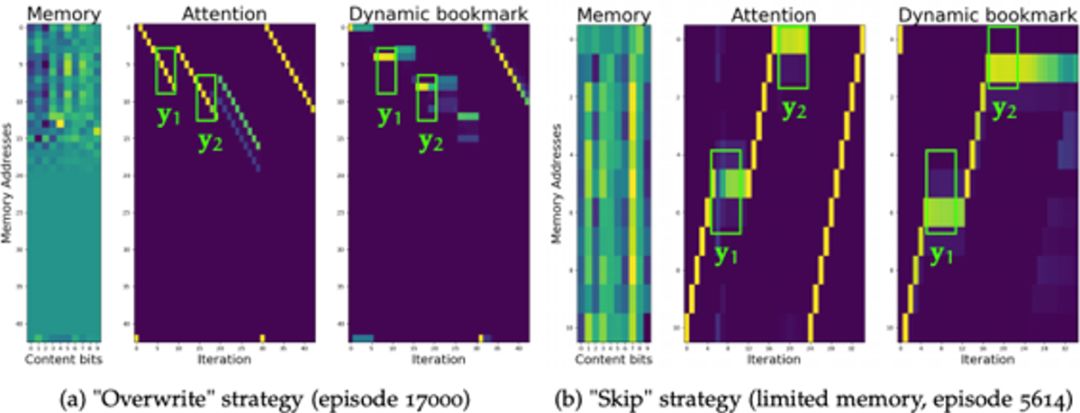
图十八:两种可能策略
在这一任务于之前的任务不同,理论分析可知应有两个策略能够完成这一任务,即覆盖策略(overwrite)和略过(skip)策略:
• 覆盖策略:模型依次存入子序列
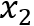
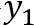
• 略过策略:模型依次存入子序列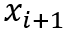
而实际实验中发现这两种策略都是可以学习到的。从而一个自然产生的问题就是如何让模型学到特定规则,而实验发现,模型在训练初期往往会学习到覆盖策略(由于这样的策略较简单,容易学习到),在训练的后期会逐渐转为略过策略(由于这种策略能更佳高效的利用存储空间),两个阶段(episode 1757与episode 17685)的策略可视化如下图所示:
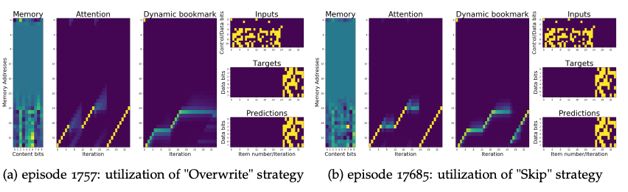
图十九:训练的两个阶段学到的策略
而这个问题的进一步分析有待于未来工作。
2.4 模型:情景记忆
情景记忆简介:与其他MANNs的区别
情景记忆(episodic memory)在认知神经科学中指以时间和空间为坐标对个人亲身经历的、发生在一定时间和地点的事件(event)的记忆,强调时空与事件发生的绑定的记忆,隶属于长期记忆;而在机器学习中情景记忆往往强调迭代式的对存储模块处理的模型,在本文的分类体系里被归为工作记忆/短时记忆(可能有一些概念上的混淆)。从模型设计的角度来说,一般的情景记忆模型的信息处理是在编码之后进行的,而之前讲到的模型均是在编码期间相伴进行的信息处理。
实现细节
回顾MANN框架介绍中的第一类框架,
图二十:MANN第一类框架
在这一框架中的第(2)步与第(3)步中,信息处理可以表达为:
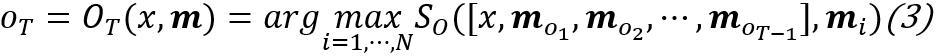
,其中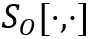
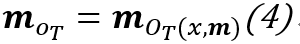
与其他MANNs模型的寻址面临的问题一样,这一寻址操作并不可微,也可以采用访问内存单元的期望近似:
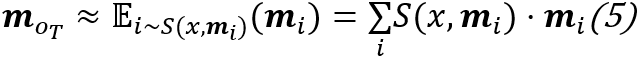
一个经典的模型结构图为:
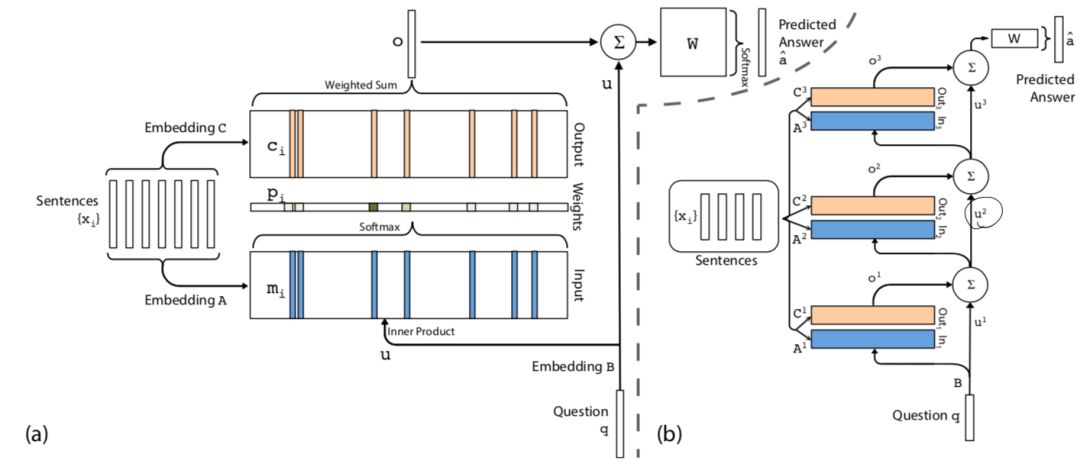
图二十一:情景记忆模型MemN2N结构
一组句子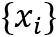
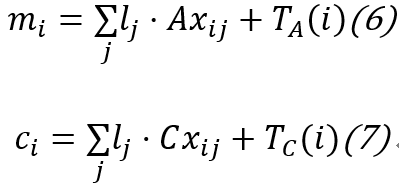
,其中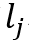
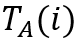
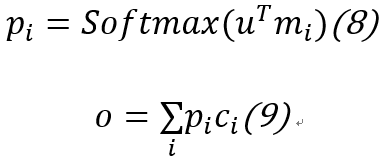
,也即用期望近似寻址读取内存。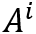
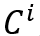
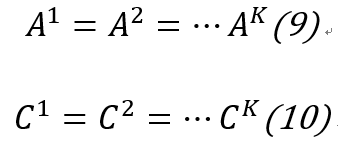
使用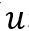
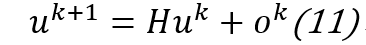
,其中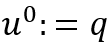
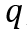
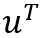
实验一:阅读理解式问答
该任务是给定一些已知事实(若干个句子,往往时序相关),给一个问题,在词表中选出一个单词作为答案。如下表所示:

表六:阅读理解式问答样例
每一列代表一个样本,黑色字体的句子为已知事实,蓝色字体的句子为问题,红色字体标出的是答案。解决这类问题的一般策略为根据答案在已知事实中逆向回溯寻找答案(backward chaining,回退式链式推理)。下表给出各个模型的准确率对比:
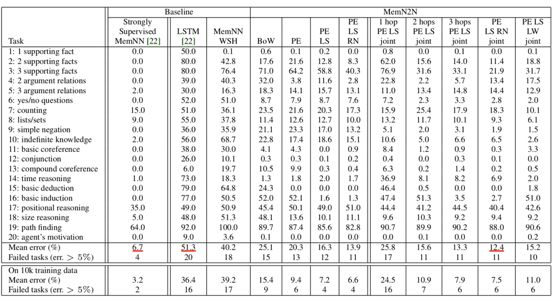
表七:阅读理解式问答实验结果
其中,第二列标出的“Strongly Supervised MemNN”为在这节提到的模型的基础上训练阶段给出强监督信息(即被指示每个推理阶段应关注哪个词)训练得到的模型。可以看出使用情景记忆的模型MemN2N可以在不使用强监督信息的情况下取得相对较好的性能。
该模型在这个任务上学习到的策略为上文提及的backward chaining,将每一个推理时刻模型关注到不同句子的强度可视化,可以得到下图:
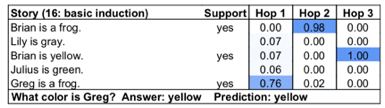
表八:backward chaining策略
可以看出,模型在第一个推理时刻关注到最后一句话,在第二时刻关注到第一句话,在第三时刻关注到第三句话,可以看出与人推理的机制类似。
任务二:逻辑推理
这里的逻辑推理任务与之前的阅读理解问答任务类似,均是给定一些事实和问题,给出答案,都需要回退式链式推理,不同的是本任务是用prolog程序表达的。这里不对相关背景知识详细展开介绍。一些样例如下表所示:

表九:prolog逻辑推理任务样例
实验结果如下表(IMA为针对任务设计的模型,DMN为较通用的情景记忆模型):
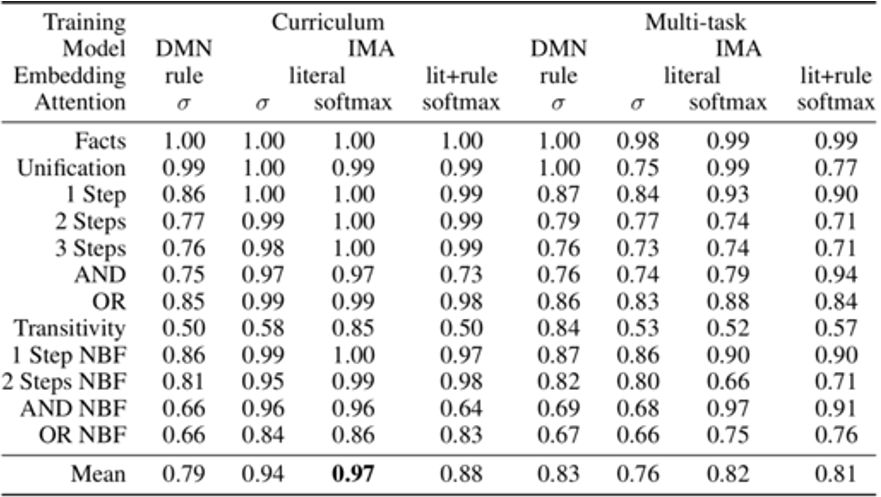
表十:prolog逻辑推理任务实验结果
其学习到的策略与之前任务中展示的类似:
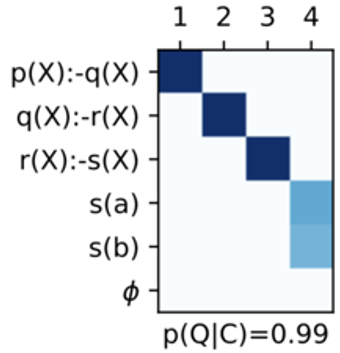
图二十二:逻辑推理中的backward chaining策略
2.5 模型:一个长期记忆的例子
长期记忆简介
如上文所述,长期记忆在机器学习中一般指记忆存留与处理不同样本之间,而不仅仅局限于单个样本的处理过程。与工作记忆不同,长期记忆主要关注样本之间的相关性(适用于样本稀疏情形)或是充分利用某些样本信息来辅助学习过程。简单的例子如强化学习中常使用的经验回放(experience replay),即保存一些回报比较高的样本,多次重新利用其训练来使训练过程更稳定。下文给出一个在样本稀疏的场景下,利用样本间的相关性来进行段文本分类的任务的模型。
神经主题模型
神经主题模型(Neural Topic Model)关注解决短文本分类任务,即待分类的文本长度较短。这类样本常常由于文本蕴含信息不全难以完成分类任务,一个简单的例子:

图二十三:短文本分类任务样例
可以看到测试样例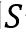
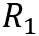
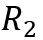
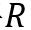
神经主题模型则是基于这一观察,在一般的分类模型处理的同时使用主题模型对训练集中的样本抽取主题保存在存储模块中(作为长期记忆)辅助分类。这里的主题模型使用了变分自编码器进行实现,与分类模型得到的损失函数差值联合优化,模型结构图如下所示,本文不详细展开说明。
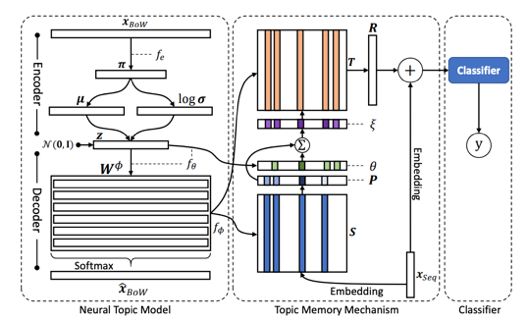
图二十四:神经主题模型结构
实验结果
这个模型在多个短文本数据集(新闻、Twitter数据、微博数据)上进行了实验,与其他模型可以拉开较大差距。
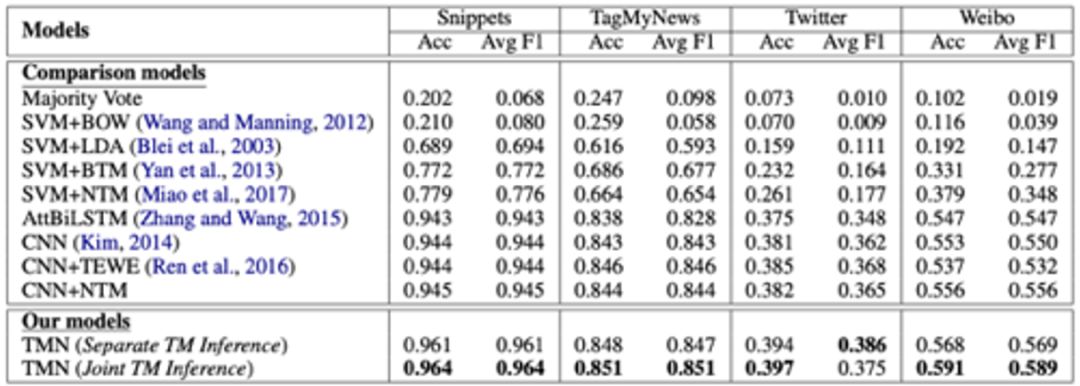
表十一:实验结果
分析其信息处理机制,对测试样本
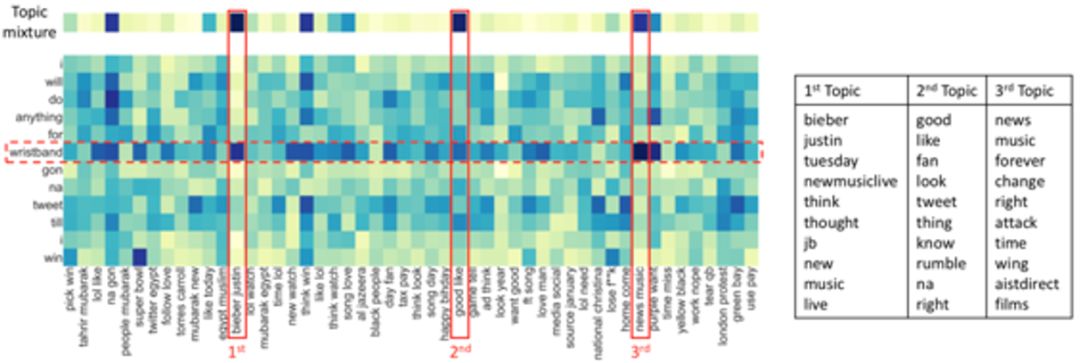
图二十五:神经主题模型对主题词关注强度可视化
可以看出,模型对最相关的主题词“biber justin”关注强度最大,与之前分析一致。
3. 总结
提炼本文的总结的重要观点如下:
• 自动机模型与记忆增强RNNs之间的类比关系
• 工作记忆与计算机/图灵机的类比关系
• 配备栈的模型能够处理一些递归结构
• 可以使用回退式链式推理来处理逻辑推理
• 表达能力与学习能力的关系:任何图灵机模型都可以使用RNN模型来表达
4. 参考文献
[1] Mikolov T, Mikolov T. Inferringalgorithmic patterns with stack-augmented recurrent nets[C]// InternationalConference on Neural Information Processing Systems. MIT Press, 2015:190-198.
[2] Grefenstette E, Hermann K M, SuleymanM, et al. Learning to transduce with unbounded memory[J]. Computer Science,2015.
[3] Yogatama D, Miao Y, Melis G, et al.Memory Architectures in Recurrent Neural Network Language Models[J]. 2018.
[4] Graves A, Wayne G, Danihelka I.Neural turing machines[J]. arXiv preprint arXiv:1410.5401, 2014.
[5] Graves A, Wayne G, Reynolds M, et al.Hybrid computing using a neural network with dynamic external memory[J]. Nature, 2016, 538(7626): 471.
[6] Jayram T S, Bouhadjar Y, McAvoy R L,et al. Learning to Remember, Forget and Ignore using Attention Control inMemory[J]. arXiv preprint arXiv:1809.11087, 2018.
[7] J. Weston, S. Chopra, and A. Bordes.Memory networks. In International Conference on Learning Representations(ICLR), 2015.
[8] Sukhbaatar S, Weston J, Fergus R.End-to-end memory networks[C]//Advances in neural information processingsystems. 2015: 2440-2448.
[9] Kumar A, Irsoy O, Ondruska P, et al.Ask me anything: Dynamic memory networks for natural languageprocessing[C]//International Conference on Machine Learning. 2016: 1378-1387.
[10] Cingillioglu N, Russo A. DeepLogic:End-to-End Logical Reasoning[J]. arXiv preprint arXiv:1805.07433, 2018.
[11] Zeng J, Li J, Song Y, et al. TopicMemory Networks for Short Text Classification[J]. 2018.
SFFAI讲者招募
为了满足人工智能不同领域研究者相互交流、彼此启发的需求,我们发起了SFFAI这个公益活动。SFFAI每周举行一期线下活动,邀请一线科研人员分享、讨论人工智能各个领域的前沿思想和最新成果,使专注于各个细分领域的研究者开拓视野、触类旁通。
SFFAI目前主要关注机器学习、计算机视觉、自然语言处理等各个人工智能垂直领域及交叉领域的前沿进展,将对线下讨论的内容进行线上传播,使后来者少踩坑,也为讲者塑造个人影响力。
SFFAI还将构建人工智能领域的知识树(AI Knowledge Tree),通过汇总各位参与者贡献的领域知识,沉淀线下分享的前沿精华,使AI Knowledge Tree枝繁叶茂,为人工智能社区做出贡献。
这项意义非凡的社区工作正在稳步向前,衷心期待和感谢您的支持与奉献!
有意加入者请与我们联系:wangxl@mustedu.cn

历史文章推荐:

