AI Challenger_2018英中文本机器翻译_参赛小结
作者:Canon(目前研究生在读,研究方向OCR)
原文链接:
https://zhuanlan.zhihu.com/p/50153808
本文已获授权转载,点击文末"阅读原文"可直达链接。
从九月底开始准备这个赛事,花了很多精力做比赛,最终跑分不算理想,但是排名还是挺意外的,测试集B有许多排名靠前的大佬放弃提交(听说有的人可能是因为不合符参赛规则而放弃提交)。
最终自己排到第10。
0 感受
这是第一次参加AI相关的比赛,自己本来是做OCR的,但是由于平时看的论文很多是机器翻译方向的,所以打算试一下水。总的来说,感觉做比赛最重要的是经验积累,其次是比赛期间投入的总时间,top的几个队伍应该是公司或者专门做机翻的实验室,得分甩后面队伍几条街。所以新手参加看到前面大佬的分数不要慌,无视就好。
另外,收获呢,学习是谈不上的了,基本都是跑开源代码调参的苦力活,但是可以拓展知识面,了解这个领域有什么方法。教训也是有的,其一,尽量不要一个人做,容易犯错而不自知;其二,在尝试新方法的时候,要快速走完训练、验证、测试这些环节,这样可以确保这套代码可行,并且对其性能有个估计。
1 数据处理
使用官方提供的数据处理脚本,英文做了lowercase和简单的tokenize,中文jieba分词。
2 tensor2tensor库
第一阶段的实验基于tensor2tensor库(t2t),它是google基于tensorflow开发的高级库,内置了许多经典模型,做实验相当方便。transformer模型已经成为当前机器翻译比赛的标配,大家都用,我也用。
先后尝试了transformer_base, transformer_big, transformer_middle(自己定义的参数,num_layer, num_head, num_filter值取base和big的平均),universal_transformer_base, universal_transformer_middle, universal_transformer_big这些模型。简单汇总如下:
实验参数(未列出的使用默认参数):
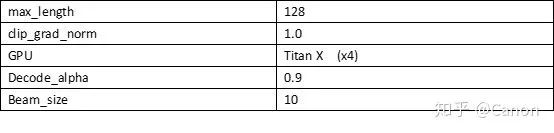
实验结果

上述实验结果不是很精确,大概这么多,做实验的时候没有严格记录。universal_transformer的结果不比transformer好,就不列出了,而且decode耗费的时间巨多。
调参方面可以看这个参考文档Training Tips for the Transformer Model,有很周祥的实验记录。我的经验是batch_size调大会有提升,但是超过一定值之后就不会再提高了,如果想增大batch_size,可以将参数sync设置为True(有多张卡的前提下),这个参数决定了模型参数更新是否为同步更新,如果是同步更新,真实的batch_size扩大了n倍(n张卡)。此外,学习率在训练loss不降的时候调小,能进一步降低训练loss,dev集上的表现相应提升。
有一个trick是,训练集上训出来的模型拿到dev集上finetune可以提高test集的得分,因为dev与test的分布比较相近。我的实验中会有0.5左右的提升。
最后就是多去github上的issue看看,会有很多收获。
至此,tensor2tensor调参工作告一段落了,接下来就是考虑提升的思路。因为在dev集上finetune提升明显,所以首先想到的是在数据上动手。
3 数据筛选
(很伤心的是这方面的尝试全部失败,大家可以跳过这部分)。在dev集上finetune尝到甜头,所以很自然地想从训练集中选出与test集相似的一些样本来。
这个相似性如何度量呢,一个超级naive的想法是统计test集中的词频,去掉高频词,得到一个能表示test集特点的词库,然后遍历训练集中的每个句子每个词,如果该词在test集中出现过,则选中当前句。但是这个时间复杂度太大了,放弃。
接着想到用bleu值来度量句子相似度,直接用python的nltk库算bleu值,其实这个时间复杂度比前一个想法更大,但想着毕竟是开源库,应该优化的好,于是测了一下耗费时间,能接受,最后遍历了大概800w训练集,选出14w数据(多台服务器100多个核上跑了6小时,还是挺耗时的)。用这14w数据finetune发现性能下降了,观察了一下这14w数据,数据多样性很低,很多句子都有相同的短语,例如 i don't know .... , and if you don't....., it doesn't have to....., what's going on....., do you want me.......。这种片段开头的句子非常多,考虑到这语料是电影里的,也很正常。想不到解决办法,放弃。
然后在网上搜到有专门计算句子相似度的算法,主要有基于word-embedding的方法和预训练编码器的方法,我就采取最简单的方法,两个句子做了词嵌入后的WMD距离(词移距离)。介绍见四种计算文本相似度的方法对比,代码见Simple Sentence Similarity。小规模测试发现这个计算太耗时了,而选出来的句子并不理想,放弃。
最后在后期想到一个骚操作,那就是在test和dev集上训一个语言模型,用这个语言模型给训练集中的句子打分,选出一些高分句子。然而这个方法选出的句子特点是,得分靠前的都是一些非常简单的句子(句子中的词汇都是一些高频词),加之时间不多了,也就没有进一步想解决办法。想到这个操作起因是听说去年冠军队伍用语言模型给训练集打分,剔除了低分数据。但是我的实验并不奏效,我是用训练语料训出一个语言模型,先去掉训练集中重复的句子(蛮多的),然后剔除了100W低分语料,但是结果并没有提升。训语言模型用的工具是kenlm, 需要注意的是score这个函数算出来的分数没考虑句长,所以用perplexity更合适。这之前尝试过另一个工具mitlm,文档比较隐蔽,见MIT Language Modeling Toolkit Tutorial,mitlm/tree/wiki。
总的来说,数据筛选尝试失败的原因可能是:选出的数据多样性较低。
4 数据增强
NMT中用回译的方法扩充语料是常用的数据增强方法,见Improving Neural Machine Translation Models with Monolingual Data[1], Investigating Backtranslation in Neural Machine Translation[2],Explaining and Generalizing Back-Translation throughWake-Sleep[3]。
[1]中实验有个非常有意思的尝试是,仅用额外的target端单语数据(不做回译)就能提高性能。具体做法是,将source端句子填充为<null>,得到这样的句对,与真实句对按1:1的比例组成全部训练集,训练的时候每个batch中的句对要么全是填充的,要么全是真实的句对,如果是填充的句对,要固定encoder部分的参数,只更新decoder的参数。相当于用额外数据训了一个语言模型,需要注意的是,单语数据不能用太多,超过1:1的话可能导致decode的时候更依赖于用单语语料训出来的参数,而学不到利用encoder端的信息。[3]中也探究了回译生成的伪句对与真实句对的比例如何影响性能。
由于比赛规则不能用额外的数据,所以我只能尝试用现有的target端数据再做一遍回译,生成了大概600w伪平行句对,加入原训练语料。性能下降了。观察了一下数据,发现噪声还是有点大了。最关键的还是要有额外的target端数据啊。但是也有些论文会用加噪声的方法(随机替换、mask、打乱语序),扩充语料预训练模型参数。这个尝试失败的原因难以确定,不过回译出来的数据相比加噪声的方法变动更大是可以确定的。
5 Document Level Context
本次比赛的数据是有篇章上下文的,前期的实验没有考虑利用这个信息。Improving the Transformer Translation Model with Document-Level Context[4] 提出一个利用上文信息提升翻译质量的方法,是在Transformer模块之外引入一个表征上文信息的模块,将上文信息传到encoder和decoder中,实验提升非常明显。但是代码是基于清华的机器翻译库THUMT,所以在这个库上面又跑了一些Transformer模型,用默认参数跑出来的baseline在dev集上大概是31.2bleu,test集上30.2bleu,相比于t2t,这个库训出来的模型泛化性能差一些,不过也可能是因为用了Bpe编码。引入Context后dev集上最高能到32.6bleu,提升还是挺高的,但是不同步数的checkpoint结果波动很大,在32.0~32.6区间。
接下来就是调参,其中有提升的trick是,batchsize扩大到2.4w(设置update_cycle=4),学习率后期调小,最后Base模型在dev上能到32.0。用dropout没有提升,很奇怪。尝试增大模型深度和宽度,用big,middle没有提升。然后在dev集上finetune, dev能到32.4bleu,加入context模块dev集能到33.2bleu。
THUMT提供了ensemble的代码,时间关系我只ensemble了不同阶段的checkpoint,ensemble的方法可参考面向神经机器翻译的集成学习方法。另外,提升性能的思路这个文档里的Refine部分总结的很全面Neural Machine Translation[5]。
Context模块应该还有提升空间,它的波动较大,可以在观测到的最优结果附近再搜索一下,因为快到截止时间时训出一个dev集上33.4的结果,来不及提交。
6 Unsupervised Neural Machine Translation
这部分只是一个探索,没有训出好的结果,也没有时间把它与有监督的模型进行融合。但是最感兴趣的还是这部分。论文见Phrase-Based & Neural Unsupervised Machine Translation[6]。相关文章的解读见Notes on Unsupervised Neural Machine Translation。
[6]的方法对于距离较远的语言之间,需要先用一个质量较好的双语词典做初始化。所以我先用MUSE在训练语料上训了一个词典,然后用两个语言的词向量空间初始化[6]中的模型。英中bleu训到8.x。
因为考虑到无监督的方法会用对偶学习的套路生成一些额外的数据训练模型,所以感觉结合有标注的训练语料可能会得到更好的结果。虽然基础模型都是用的Transformer, 但是总体结构还是有区别,目前还不知道如何把有监督得到的模型与无监督训出的模型进行融合。
7 GAN/RL in NMT
这部分也挺有意思,不过没时间尝试。我们在评估翻译质量的时候是看预测结果与标准句子之间的单词匹配程度,但是有很多同义词存在,即使单词匹配程度不好,意思也可能非常相近,所以现在的训练目标函数并不是很好。而用一个判别器来给预测结果打分可能会改善这个问题。一个比较好的解读见:Where GAN/RL meets NMT
还有一个基于Transformer,结合RL做机器翻译的论文A Study of Reinforcement Learning for Neural Machine Translation代码RL4NMT。





