【论文推荐】最新七篇行人再识别相关论文—多级高斯模型、密度自适应、注意力感知组成网络、图像-图像域适应、自适应采样
【导读】专知内容组既昨天推荐8篇行人再识别论文,又整理了最近七篇行人再识别(Person Re-Identification)相关文章,为大家进行介绍,欢迎查看!
9.Homocentric Hypersphere Feature Embedding for Person Re-identification(同心超球面特征嵌入的行人再识别)
作者:Wangmeng Xiang,Jianqiang Huang,Xianbiao Qi,Xiansheng Hua,Lei Zhang
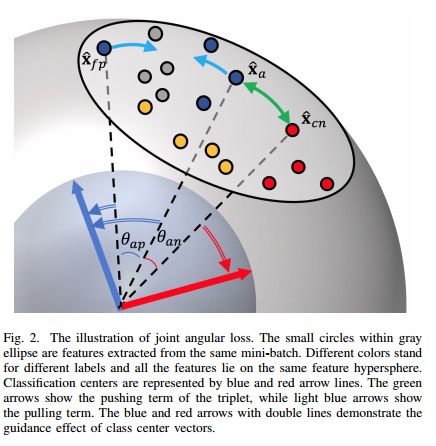
摘要:Person re-identification (Person ReID) is a challenging task due to the large variations in camera viewpoint, lighting, resolution, and human pose. Recently, with the advancement of deep learning technologies, the performance of Person ReID has been improved swiftly. Feature extraction and feature matching are two crucial components in the training and deployment stages of Person ReID. However, many existing Person ReID methods have measure inconsistency between the training stage and the deployment stage, and they couple magnitude and orientation information of feature vectors in feature representation. Meanwhile, traditional triplet loss methods focus on samples within a mini-batch and lack knowledge of global feature distribution. To address these issues, we propose a novel homocentric hypersphere embedding scheme to decouple magnitude and orientation information for both feature and weight vectors, and reformulate classification loss and triplet loss to their angular versions and combine them into an angular discriminative loss. We evaluate our proposed method extensively on the widely used Person ReID benchmarks, including Market1501, CUHK03 and DukeMTMC-ReID. Our method demonstrates leading performance on all datasets.
期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/aa1074bb67e4275d73427986f5174534
10.Weighted Bilinear Coding over Salient Body Parts for Person Re-identification(在显著的身体部位进行加权的双线性编码的行人再识别)
作者:Qin Zhou,Heng Fan,Hang Su,Hua Yang,Shibao Zheng,Haibin Ling
This manuscript is under consideration at Pattern Recognition Letters
机构:Tsinghua University,South China University of Technology
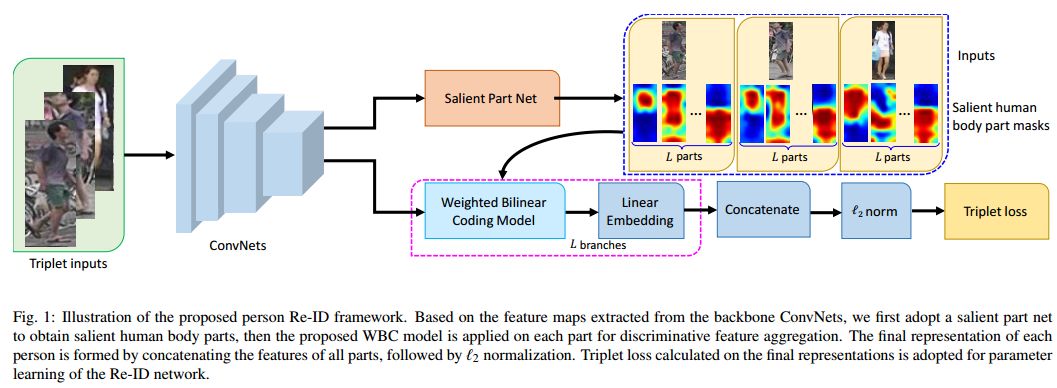
摘要:Deep convolutional neural networks (CNNs) have demonstrated dominant performance in person re-identification (Re-ID). Existing CNN based methods utilize global average pooling (GAP) to aggregate intermediate convolutional features for Re-ID. However, this strategy only considers the first-order statistics of local features and treats local features at different locations equally important, leading to sub-optimal feature representation. To deal with these issues, we propose a novel \emph{weighted bilinear coding} (WBC) model for local feature aggregation in CNN networks to pursue more representative and discriminative feature representations. In specific, bilinear coding is used to encode the channel-wise feature correlations to capture richer feature interactions. Meanwhile, a weighting scheme is applied on the bilinear coding to adaptively adjust the weights of local features at different locations based on their importance in recognition, further improving the discriminability of feature aggregation. To handle the spatial misalignment issue, we use a salient part net to derive salient body parts, and apply the WBC model on each part. The final representation, formed by concatenating the WBC eoncoded features of each part, is both discriminative and resistant to spatial misalignment. Experiments on three benchmarks including Market-1501, DukeMTMC-reID and CUHK03 evidence the favorable performance of our method against other state-of-the-art methods.
期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/c2d493f464cb5ced209703ddf1802eef
11.Horizontal Pyramid Matching for Person Re-identification(水平金字塔匹配的行人再识别)
作者:Yang Fu,Yunchao Wei,Yuqian Zhou,Honghui Shi,Gao Huang,Xinchao Wang,Zhiqiang Yao,Thomas Huang
机构:Cornell University
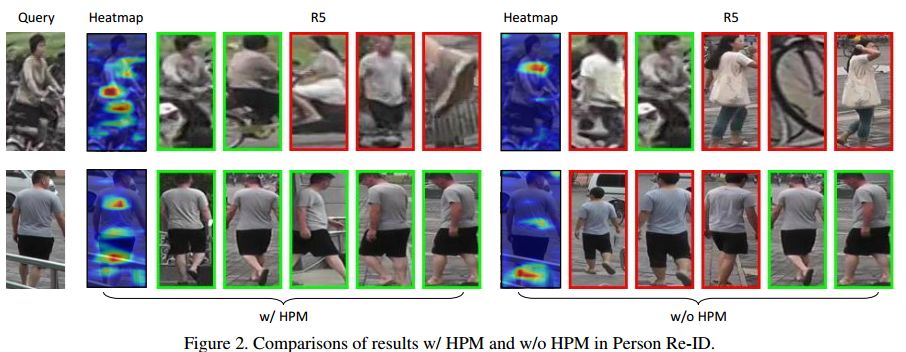
摘要:Despite the remarkable recent progress, person Re-identification (Re-ID) approaches are still suffering from the failure cases where the discriminative body parts are missing. To mitigate such cases, we propose a simple yet effective Horizontal Pyramid Matching (HPM) approach to fully exploit various partial information of a given person, so that correct person candidates can be still identified even if some key parts are missing. Within the HPM, we make the following contributions to produce a more robust feature representation for the Re-ID task: 1) we learn to classify using partial feature representations at different horizontal pyramid scales, which successfully enhance the discriminative capabilities of various person parts; 2) we exploit average and max pooling strategies to account for person-specific discriminative information in a global-local manner; 3) we introduce a novel horizontal erasing operation during training to further resist the problem of missing parts and boost the robustness of feature representations. Extensive experiments are conducted on three popular benchmarks including Market-1501, DukeMTMC-reID and CUHK03. We achieve mAP scores of 83.1%, 74.5% and 59.7% on these benchmarks, which are the new state-of-the-arts.
期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/42ec600e6030cab7cdd59b3ec6c848ab
12.Long-term Tracking in the Wild: A Benchmark(自然环境下的长时跟踪:一个基准库)
作者:Lin Wu,Yang Wang,Junbin Gao,Dacheng Tao
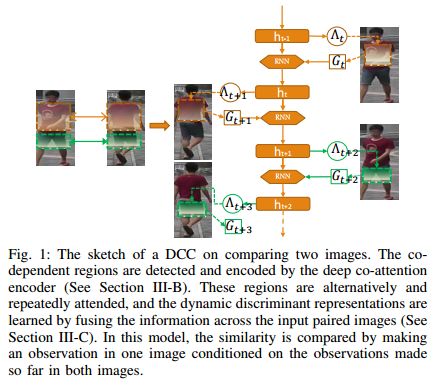
摘要:Person re-identification (re-ID) requires rapid, flexible yet discriminant representations to quickly generalize to unseen observations on-the-fly and recognize the same identity across disjoint camera views. Recent effective methods are developed in a pair-wise similarity learning system to detect a fixed set of features from distinct regions which are mapped to their vector embeddings for the distance measuring. However, the most relevant and crucial parts of each image are detected independently without referring to the dependency conditioned on one and another. Also, these region based methods rely on spatial manipulation to position the local features in comparable similarity measuring. To combat these limitations, in this paper we introduce the Deep Co-attention based Comparators (DCCs) that fuse the co-dependent representations of the paired images so as to focus on the relevant parts of both images and produce their \textit{relative representations}. Given a pair of pedestrian images to be compared, the proposed model mimics the foveation of human eyes to detect distinct regions concurrent on both images, namely co-dependent features, and alternatively attend to relevant regions to fuse them into the similarity learning. Our comparator is capable of producing dynamic representations relative to a particular sample every time, and thus well-suited to the case of re-identifying pedestrians on-the-fly. We perform extensive experiments to provide the insights and demonstrate the effectiveness of the proposed DCCs in person re-ID. Moreover, our approach has achieved the state-of-the-art performance on three benchmark data sets: DukeMTMC-reID \cite{DukeMTMC}, CUHK03 \cite{FPNN}, and Market-1501 \cite{Market1501}.
期刊:arXiv, 2018年4月30日
网址:
http://www.zhuanzhi.ai/document/e9cd7bf5f4e7652decdab32e5ec98dae
13.Domain Adaptation through Synthesis for Unsupervised Person Re-identification(通过合成的领域自适应进行无监督行人再识别)
作者:Slawomir Bak,Peter Carr,Jean-Francois Lalonde
机构:Université Laval
摘要:Drastic variations in illumination across surveillance cameras make the person re-identification problem extremely challenging. Current large scale re-identification datasets have a significant number of training subjects, but lack diversity in lighting conditions. As a result, a trained model requires fine-tuning to become effective under an unseen illumination condition. To alleviate this problem, we introduce a new synthetic dataset that contains hundreds of illumination conditions. Specifically, we use 100 virtual humans illuminated with multiple HDR environment maps which accurately model realistic indoor and outdoor lighting. To achieve better accuracy in unseen illumination conditions we propose a novel domain adaptation technique that takes advantage of our synthetic data and performs fine-tuning in a completely unsupervised way. Our approach yields significantly higher accuracy than semi-supervised and unsupervised state-of-the-art methods, and is very competitive with supervised techniques.
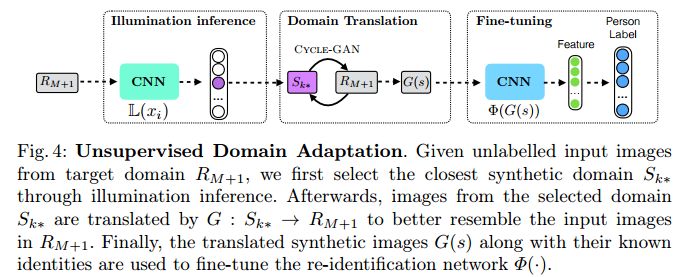
期刊:arXiv, 2018年4月26日
网址:
http://www.zhuanzhi.ai/document/b36ee20fdde83b9b579e10b9a23b6760
14.Adaptation and Re-Identification Network: An Unsupervised Deep Transfer Learning Approach to Person Re-Identification(适应和再识别网络:一种无监督的深度迁移学习方法)
作者:Yu-Jhe Li,Fu-En Yang,Yen-Cheng Liu,Yu-Ying Yeh,Xiaofei Du,Yu-Chiang Frank Wang
CVPR 2018 workshop paper
机构:National Taiwan University,National Taiwan University
摘要:Person re-identification (Re-ID) aims at recognizing the same person from images taken across different cameras. To address this task, one typically requires a large amount labeled data for training an effective Re-ID model, which might not be practical for real-world applications. To alleviate this limitation, we choose to exploit a sufficient amount of pre-existing labeled data from a different (auxiliary) dataset. By jointly considering such an auxiliary dataset and the dataset of interest (but without label information), our proposed adaptation and re-identification network (ARN) performs unsupervised domain adaptation, which leverages information across datasets and derives domain-invariant features for Re-ID purposes. In our experiments, we verify that our network performs favorably against state-of-the-art unsupervised Re-ID approaches, and even outperforms a number of baseline Re-ID methods which require fully supervised data for training.
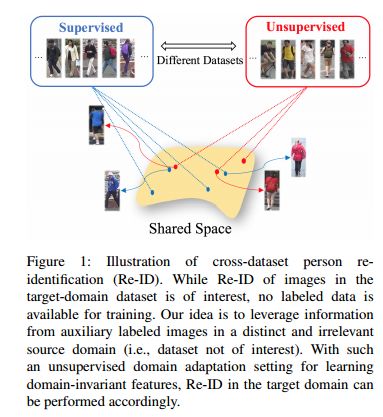
期刊:arXiv, 2018年4月25日
网址:
http://www.zhuanzhi.ai/document/bef4302818dcfa5e868291bd4c33db6a
15.Multi-Level Factorisation Net for Person Re-Identification(多层次的分解网络进行行人再识别)
作者:Xiaobin Chang,Timothy M. Hospedales,Tao Xiang
To Appear at CVPR2018
机构:, The University of Edinburgh,Queen Mary University of London
摘要:Key to effective person re-identification (Re-ID) is modelling discriminative and view-invariant factors of person appearance at both high and low semantic levels. Recently developed deep Re-ID models either learn a holistic single semantic level feature representation and/or require laborious human annotation of these factors as attributes. We propose Multi-Level Factorisation Net (MLFN), a novel network architecture that factorises the visual appearance of a person into latent discriminative factors at multiple semantic levels without manual annotation. MLFN is composed of multiple stacked blocks. Each block contains multiple factor modules to model latent factors at a specific level, and factor selection modules that dynamically select the factor modules to interpret the content of each input image. The outputs of the factor selection modules also provide a compact latent factor descriptor that is complementary to the conventional deeply learned features. MLFN achieves state-of-the-art results on three Re-ID datasets, as well as compelling results on the general object categorisation CIFAR-100 dataset.
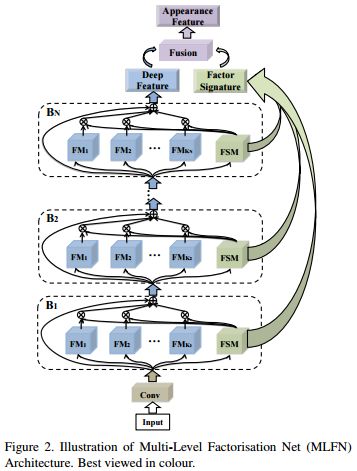
期刊:arXiv, 2018年4月18日
网址:
http://www.zhuanzhi.ai/document/25a28b9b4a7b44b1ef7361d70d5fe79f
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知


