不看全图看局部,CNN性能竟然更强了
鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
不给全图,只投喂CNN一些看上去毫无信息量的图像碎片,就能让模型学会图像分类。
更重要的是,性能完全不差,甚至还能反超用完整图像训练的模型。

这么一项来自加州大学圣塔芭芭拉分校的新研究,这两天引发不少讨论。
咋地,这就是说,CNN根本无需理解图像全局结构,一样也能SOTA?
具体是怎么一回事,咱们还是直接上论文。
实验证据
研究人员设计了这样一个实验:
他们在CIFAR-10、CIFAR-100、STL-10、Tiny-ImageNet-200以及Imagenet-1K等数据集上训练ResNet。
特别的是,用于训练的图像是通过随机裁剪得到的。
这个“随机裁剪”,可不是往常我们会在数据增强方法中见到的那一种,而是完全不做任何填充。
举个例子,就是对图片做PyTorch的RandomCrop变换时,padding的参数填0。
得到的训练图像就是下面这个样式的。即使你是阅图无数的老司机,恐怕也分辨不出到底是个啥玩意儿。

训练图像如此碎片化,模型的识图能力又能达到几成?
来看实验结果:
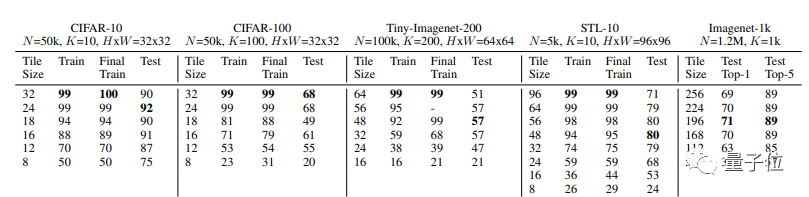
好家伙,在CIFAR-10上,用16×16的图像碎片训练出来的模型,测试准确率能达到91%,而用完整的32×32尺寸图像训练出来的模型,测试准确率也不过90%。
这一波,“残缺版”CNN竟然完全不落下风,甚至还反超了“完整版”CNN。
要知道,被喂了碎片的CNN模型,看到的图像甚至可能跟标签显示的物体毫无关系,只是原图中背景的部分……
在STL-10、Tiny-Imagenet-200等数据集上,研究人员也得到了类似的结果。
不过,在CIFAR-100上,还是完整图像训练出来的模型略胜一筹。16×16图像碎片训练出的模型测试准确率为61%,而32×32完整图像训练出的模型准确率为68%。
所以,CNN为何会有如此表现?莫非它本来就是个“近视眼”?
研究人员推测,CNN能有如此优秀的泛化表现,是因为在这个实验中,维度诅咒的影响被削弱了。
所谓维度诅咒(curse of dimensionality),是指当维数提高时,空间体积提高太快,导致可用数据变得稀疏。
而在这项研究中,由于CNN学习到的不是整个图像的标签,而是图像碎片的标签,这就在两个方面降低了维度诅咒的影响:
图像碎片的像素比完整图像小得多,这减少了输入维度
训练期间可用的样本数量增加了
生成热图
基于以上实验观察结果,研究人员还提出以热图的形式,来理解CNN的预测行为,由此进一步对模型的错误做出“诊断”。
就像这样:

这些图像来自于STL-10数据集。热图显示,对于CNN而言,飞机图像中最能“刺激”到模型的,不是飞机本身,而是天空。
同样,在汽车图像中,车轮才是CNN用来识别图像的主要属性。
研究团队
最后,介绍一下论文作者。
论文一作Vamshi Madala小哥,目前是加州大学圣塔芭芭拉分校的一年级博士生。主要研究兴趣是深度学习理论框架,以及用计算机视觉来对理论研究进行测试。

论文的另一位作者是小哥的导师Shivkumar Chandrasekaran,他是加州大学圣塔芭芭拉分校电气与计算机工程教授,博士毕业于耶鲁大学数值分析专业。

论文地址:
https://arxiv.org/abs/2205.10760
— 完 —
直播报名 | 自动驾驶的量产之路:
为什么“渐进式”路径先看到了无人驾驶量产的曙光?
自动驾驶领域一直以来就有“渐进式”和“跨越式”两种路径之争,前者以特斯拉为代表,后者以Waymo为领头羊。
特斯拉宣布2024年实现新型“Robotaxi”的量产,而另一边是Waymo CEO离职,商业化落地裹足不前。在此背后,为什么“渐进式”路径被越来越多的机构看好?“渐进式”技术发展路径是什么?自动驾驶量产离我们的生活还有多远?

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~

