微软亚洲研究院发布业界最全面的语义分析数据集MSParS

编者按:语义分析引擎是诸多人工智能产品的核心模块,但由于标注成本高、难度大,学术界现有的语义分析数据集存在数据规模小、问题种类少、问题模板结构过于单一等缺陷。为此,微软亚洲研究院自然语言计算组与微软必应(Bing)搜索引擎团队合作构建并发布了大规模、高质量、多类型的语义分析数据集 MSParS(Multi-perspective Semantic ParSing Dataset),希望供科研人员和工业界同行研究和使用。欢迎通过GitHub下载和使用V1.0版本!
自然语言处理(Natural Language Processing, NLP)是人工智能领域中最重要的分支之一,而语义分析(Semantic Parsing) 则是NLP诸多任务中最核心、也最具挑战的一项。
语义分析旨在将自然语言转换为机器能够理解的结构化语义表示(例如Lambda表达式、SQL语句和SPARQL语句等)。基于语义表示,下游NLP任务(例如智能问答和对话系统等)能够从对应的结构化知识图谱中进行相关信息的精准查询,并将其用于输出结果的生成。下图就是语义分析在多轮问答中的一个应用示例。
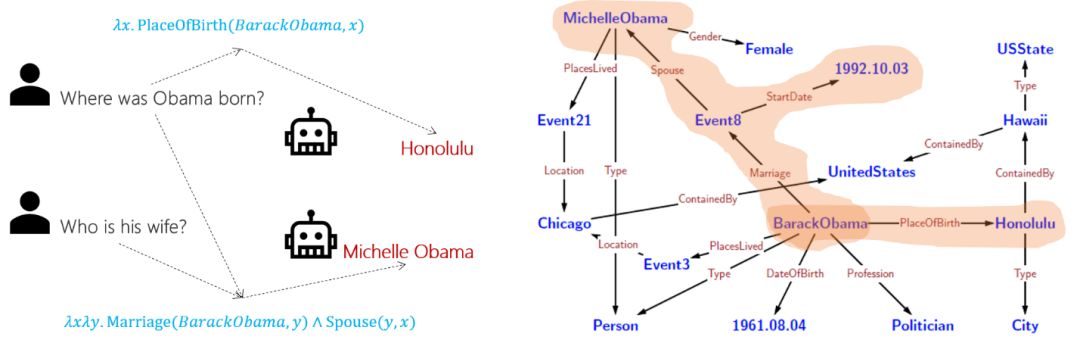
语义分析引擎是目前诸多人工智能产品的核心模块,例如微软必应(Bing)搜索引擎、微软小冰、微软小娜等。然而,由于对自然语言进行语义分析标注的成本非常高、难度非常大,因此,学术界现有的语义分析数据集存在数据规模小、问题种类少、问题模板结构过于单一等缺陷。
针对这些问题,微软亚洲研究院自然语言计算组与微软必应(Bing)搜索引擎团队合作构建并发布了一个大规模、高质量、多类型的语义分析数据集:MSParS (Multi-perspective Semantic ParSing Dataset),希望供科研人员和工业界同行进行研究和使用。该数据集(V1.0版本)包含了81,826个自然语言问题及其对应的结构化语义表示,覆盖12种不同的问题类型和2,071个知识图谱谓词,是学术界目前最全面的语义分析数据集。现在,MSParS V1.0版本已经可以通过GitHub进行下载。
MSParS 下载
下载地址:https://github.com/msra-nlc/MSParS

长按扫码,下载数据集
传统的语义分析数据集,如ATIS、JOBS、Geoquery等均针对特定领域进行构建,其特点是数据规模小,并且覆盖的领域知识非常有限。近年来,随着包括Freebase等在内的大规模知识图谱的快速发展,很多更具挑战的开放领域语义分析任务被陆续提出,例如SimpleQuestions、WikiSQL、ComplexWebQuestions等。这些语义分析数据集规模较大,但只针对极少数常见问题类型进行语义标注,例如单关系(single-relation)问题、多跳(multi-hop)问题和多约束(multi-constraint)问题。
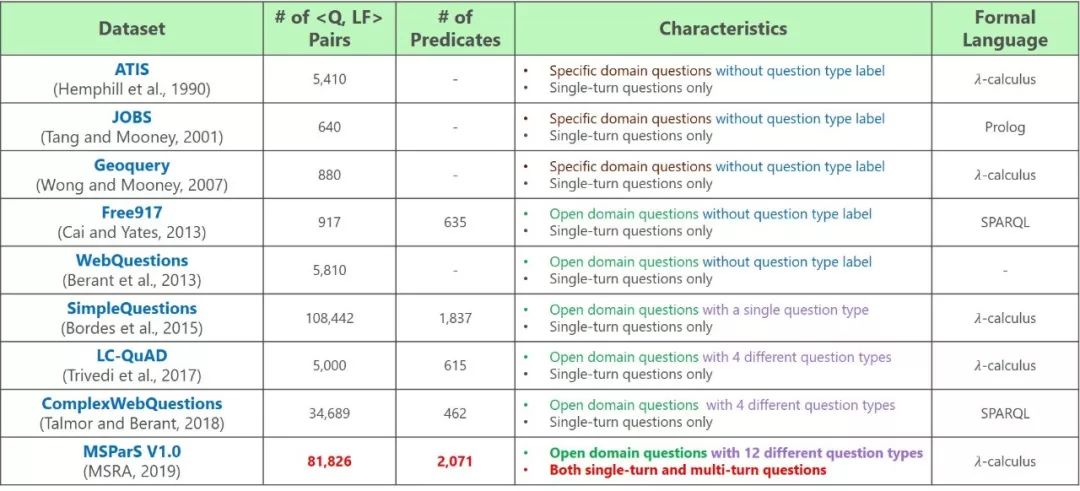
现有的语义分析数据集对比
而MSParS基于微软的开放领域知识图谱Satori进行标注,目前发布的V1.0版本总共包含81,826条人工标注,每条数据由一个四元组构成:问题、语义表示、语义表示参数、问题类型。其中,语义表示参数是指在问题中出现的构成语义表示所需的实体名称、实体类型或数值等。问题类型则由9种单轮问题类型和3种多轮问题类型组成,包括单关系(single-relation)、多跳(multi-hop)、多约束(multi-constraint)、复合事件(CVT)、是非判断(yesno)、选择(multi-choice)、最高级(superlative)、数值比较(comparative)、聚集查询(aggregation)、前一轮问题实体省略(multi-turn-entity),前一轮问题谓词省略(multi-turn-predicate)和前一轮答案省略(multi-turn-answer)。
整个MSParS数据集被划分为训练集(63,826条人工标注)、验证集(9,000条人工标注)和测试集(9,000条人工标注),总共覆盖2,071个知识图谱谓词和121种不同的实体类型。具体统计数字,详见下图。
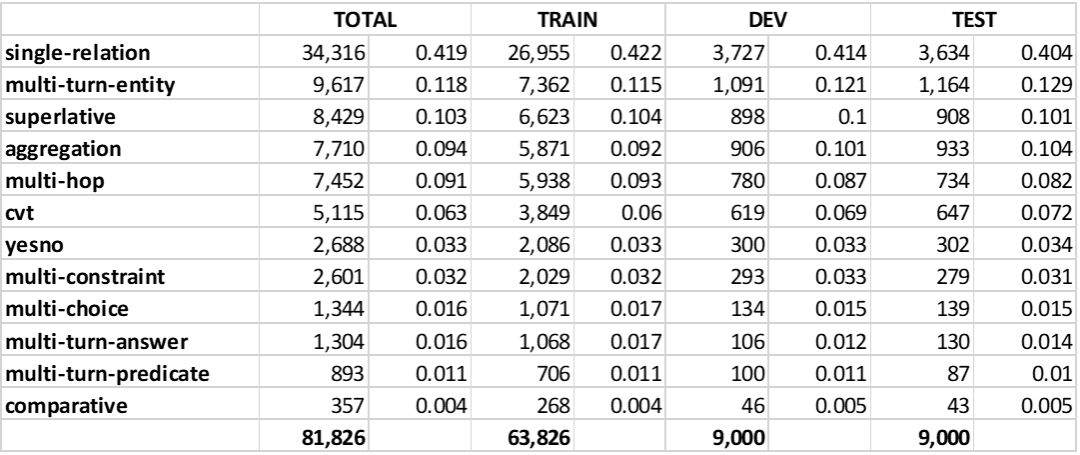
MSParS数据集划分
数据集构建
MSParS数据集采用众包(crowd-sourcing)的方式进行构建。下面以多跳(multi-hop)类型问题进行标注的流程为例:首先,基于语义表示模板,从知识图谱中采样抽取符合条件的语义表示实例;然后,基于规则为每个语义表示实例生成一个伪造的自然语言问题;再采用众包的方式对生成的伪造问题进行改写,形成<问题,语义表示>对;最后,添加语义表示参数和问题类型,生成最终的标注四元组。
数据集应用
目前,MSParS数据集已经成为NLPCC 2019的三大评测任务之一,具体信息可以从NLPCC官网进行查找。
NLPCC官网
http://tcci.ccf.org.cn/conference/2019/cfpt.php

长按扫码,查看链接

除了语义分析任务外,MSParS还能够支持其它若干种NLP任务,例如实体识别、问题分类、问题生成、知识图谱问答等。
当然,微软的科研人员也意识到MSParS中的问题与现实生活中可能遇到的问题相比,在覆盖度、复杂度等方面依旧存在很大的差距。所以,MSParS的后续版本中会引入更多的对抗样本,用来模拟在真实应用中可能遇到的不可解析查询情况。微软会持续对该数据集进行更多的问题标注和扩充,欢迎大家保持关注并下载使用。
你也许还想看:



感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。






