学界 | 如何有效预测未来的多种可能?LeCun的误差编码网络给你带来答案
AI 科技评论按:许多自然问题都有一定的不确定性,比如一个杯子从桌上掉地,它可能躺在桌角、立在凳子下面,甚至直接摔碎。这种具有多种可能结果的未来预测一直是一个难题。深度学习三驾马车之一的 Yann LeCun 近日就发布了一篇论文介绍他对这类问题的最新研究成果:误差编码网络 ENN。AI 科技评论把这篇论文的主要内容介绍如下。

多模态时间序列预测
学习关于时间序列的前馈预测模型是人工智能中的一个重要问题,它可以应用于无监督学习、规划以及压缩。这类任务中的一个主要难点是,如何处理许多时间序列中都会展现出的多模态本质。如果一个时间序列有多种可能的演变方式,用经典的l1或者l2范数损失训练的模型做出的预测就会是各个发展方向中不同结果的平均值或者中位数,那么这个结果本身就是一个不会发生的结果、是一个无效的预测。
近年来,Ian Goodfellow 等人发明并发扬光大的生成式对抗性网络GANs就是一种通用的框架,它把预测问题转换为了预测函数和可训练的鉴别器网络(代表着损失)之间的极大极小值游戏。通过这个可训练的损失函数,理论上它可以处理多种输出模式,因为如果生成器能生成每一种模式的样本的话就肯定可以骗过鉴别器,从而走向收敛。然而,只能生成某一个模式的样本的生成器其实也能骗过生成器走向收敛,实际中研究人员们也广泛观察到了这种现象。围绕这种问题,大家开发出了一些解决或者缓解模式崩溃问题的方法,比如minibatch鉴别、增加参数化噪声、通过展开的鉴别器做反向传播以及用多个GANs覆盖不同的模式等等。然而,其中的很多方法还是带来了额外的麻烦,比如增加了实现的复杂度以及增加了计算量消耗。类似视频预测这种输出高度依赖输入的条件生成任务中,模式崩溃的问题显得更为严重。
误差编码网络 ENN
在这篇论文中,作者们介绍了一种新的架构,它让时间序列数据的条件预测也可以是多模态且健壮的。它的构建基于一个简单的直觉,就是把未来状态分成确定部分和随机部分的组合;确定部分可以根据当前状态直接做出预测,随机的(或者说难以预测)的部分就代表了关于未来的不确定性。训练这个确定性的网络就能够以网络预测的形式获得确定性因子,同时也得到了与真实状态相比得到的预测误差。这个误差可以用低维隐含变量的形式编码,然后送入第二个网络中;这第二个网络经过训练后就可以利用这些额外的信息准确地更正前一个确定性网络的预测结果。这就是论文中提出的误差编码网络(Error Encoding Network,ENN)。
简单来说,这个框架在三个时间步骤中分别含有三个函数映射:
第一个函数映射把当前状态映射到未来状态,它也就把未来状态分成了确定性和不确定性的两个部分
第二个函数映射是从不确定部分映射到低维隐含向量‘
第三个函数映射是基于隐含向量的条件,把当前状态映射到未来状态,这个过程中也就编码了未来状态的模式信息。
模型的训练过程中会用到全部的三个映射,推理部分只需要最后一个映射。
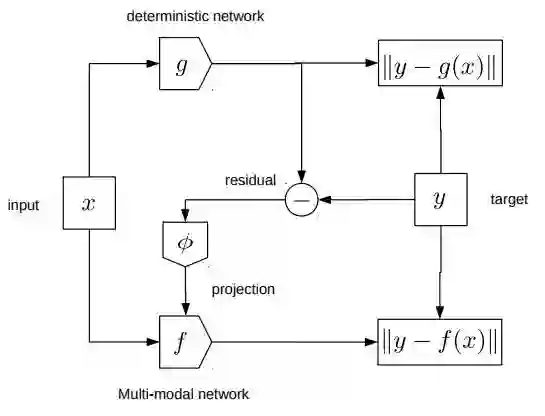
模型架构
前述的两个网络都是根据监督学习的目标函数端到端训练的,隐含变量是通过学到的参数化函数计算的,这样一来训练过程就可以简单、快速。
相关研究
以往的视频预测模型中,有的做法只关注了确定性,忽略了时间序列预测的多模态性本质;也有的做法里需要训练数据带有额外的标签,才能以不同的动作为条件生成不同的预测。与这些方法相比,论文中提出的方法是以隐含变量为条件生成的,而这些隐含变量是以无监督的方式从视频中学到的。
有一些研究在视频预测中使用了对抗性损失,比如使用多尺度架构和多种不同的损失组合进行预测。增加的对抗性损失和梯度差异损失能够提升图像质量,尤其可以降低使用l2损失时经常出现的模糊现象。然而,当时研究者们也指出生成器学会了忽略噪声,生成的结果和不带噪声训练的确定性模型的结果相似。
也有其它的视频预测模型中用交替最小化的方式推测隐含变量。一种做法里包含了一个离散的隐含变量,它的作用是在几个用来预测未来视频的隐藏状态的不同模型间切换。这要比一个纯粹的确定性模型灵活得多,然而一个离散的隐含变量仍然会把可能的未来模式显示在一个离散的集合中。这篇论文中的模型则是通过一个学到的参数化函数推测连续的隐含变量。
近期也有研究表明,好的生成式模型可以通过在隐含空间联合学习表征和解码器的参数得到。这样做的要比训练对抗式网络简单。生成式模型当然也可以通过交替最小化隐含变量和解码器的参数得到,但每个样本的隐含变量都可以在每次更新后存储下来,当对应的样本再次从训练集中拿出时优化过程也还可以继续。这种做法和论文中的方法有所关联,不过区别是,这次没有为每个样本存储隐含变量,而是通过确定性网络的预测误差学习一个函数。
实验结果 - 定性部分
在游戏(Atari Breakout,Atari Seaquest,Flappy Bird)、机器人操控、模拟驾驶的视频数据集上的测试结果都表明,这种方法可以持续地产生未来帧内容的多模态预测。它们都具有完善定义的多模态结构,其中的环境可以根据智能体的动作而改变,又或者是随机地改变,同时还能足够多样化的视觉环境。作者们训练模型根据已知的4帧画面,预测接下来的1到4帧。
比如下方打砖块游戏的预测结果,基准线的确定性模型预测的反弹板越来越模糊,这表明了模型对它的未来位置越来越不确定,不过同时静态的背景一直非常清晰。残差,也就是ground truth和基准模型之间的差别,值预测了确定性模型无法预测的小球和反弹板的运动。把残差作为输入,网络学到的函数就可以把它编码为隐含变量z。在训练集内采样不同的z值,就得到了以同一组帧为条件的三种不同生成结果。


打砖块游戏的生成结果。左侧4帧是给定的,右侧4帧是模型生成的。
在另一个游戏Flappy Bird中,除了玩家的动作和新出现的管子的高度之外都是确定的。在第一个例子中可以看到,通过改变隐含变量可以得到两种不同的结果,新的管子在不同的时间进入画面、有不同的高度,或者干脆没有新的管子出现。
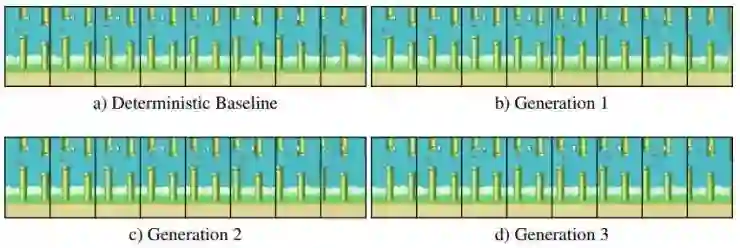
Flappy Bird,例1,最后一帧的管子有不同的高度。
在第二个例子中,改变隐含变量可以改变小鸟飞行的高度。这就说明环境中的两种变量都可以被EEN建模。
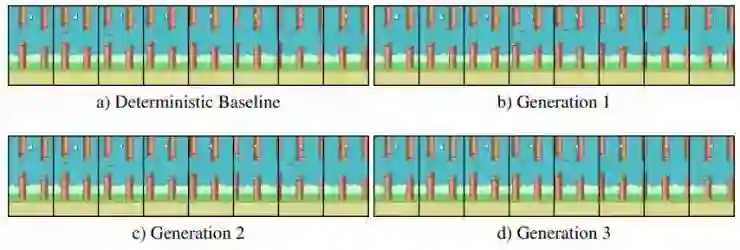
Flappy Bird,例2,最后一帧的小鸟有不同的高度。
实验结果 - 定量部分
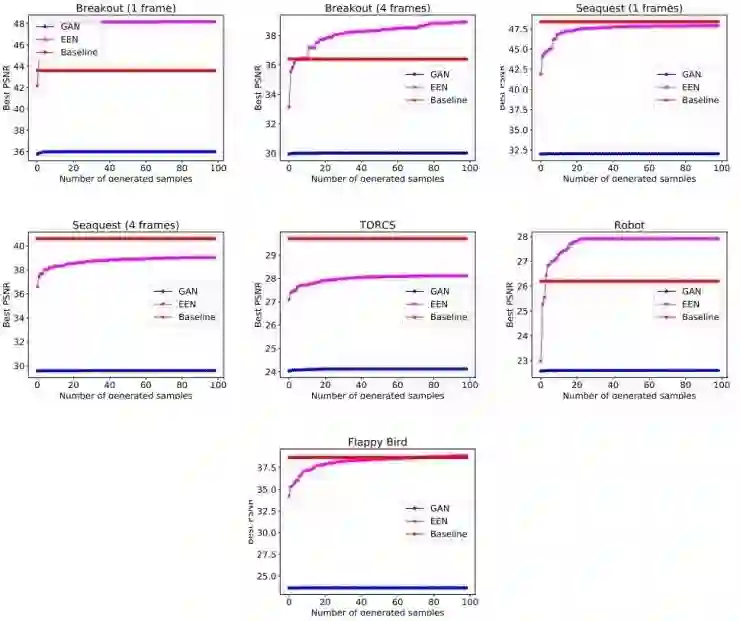
论文中以信噪比为指标对比了一个基准的确定性模型和一个GAN。可以看到,随着生成的样本数量更多,论文中所提模型的表现也跟着提升;这表明它的生成结果足够多样化,起码某些测试集中出现的模式都已经覆盖到了。也可以看到,随着增加生成样本的数目,GAN的表现并没有提升,这说明它的隐含变量对生成的样本几乎没什么影响。这也和其它研究中得到的结果相符。
另外还可以看到,不同模型之间用信噪比为指标对比的话,可比性不是很强,因为基准模型是直接优化l2损失的,ENN是以给定的测试样本为条件进行优化,GAN则是总体优化了另一个loss。这里作者们主要想要表明,随着生成的样本变多,ENN的生成质量也会提高;而GAN就不会这样。
结论
这篇论文提出了一种在带有不确定的情况下进行时间预测的新框架,方法是把未来状态中可预测和不可预测的部分分开。这种方法执行速度快、易于实现且便于训练,不需要对抗性网络或者交替最小化。论文中是在视频数据集上的做的测试,但这也是一种通用化的方法,理论上可以用于任意值连续的时间序列预测问题中。
关于未来研究,这篇论文中采用了一个简单的技巧,采样隐含变量时不考虑是否依赖当前状态;作者们认为可能还能找到更好的办法。另外,这个模型的一个好处是,它可以快速从没有见过的数据中提取隐含变量,因为毕竟它只需要在前馈网络中运行一次。如果关于动作的隐含变量是易于解耦的,这就可以成为一种从大规模无标签数据集中抽取动作、进行模仿学习的好方法。其它有意思的应用方式还包括用模型做预测、用它展开不同的未来可能性。
更多细节请查看原论文:https://arxiv.org/abs/1711.04994
AI 科技评论编译
————— AI 科技评论招人啦! —————
我们诚招学术编辑 N 枚(全职,坐标北京)、新媒体运营 N 枚(全职,坐标深圳)、学术兼职 N 枚。
详情请参见AI科技评论招人啦,新媒体运营、学术编辑、学术兼职虚位以待!
欢迎发送简历到 guoyixin@leiphone.com
————— 给爱学习的你的福利 —————
不要等到算法出现accuracy不好、loss很高、模型overfitting时,
才后悔没有掌握基础数学理论!
线性代数及矩阵论, 概率论与统计, 凸优化
AI慕课学院机器学习之数学基础课程即将上线!
扫码进入课程咨询群,组队享团购优惠!
详细了解点击文末阅读原文

————————————————————




