学界 | 要让GAN生成想要的样本,可控生成对抗网络可能会成为你的好帮手

AI 科技评论按:如何让GAN生成带有指定特征的图像?这是一个极有潜力、极有应用前景的问题,然而目前都没有理想的方法。韩国大学电子工程学院Minhyeok Lee和Junhee Seok近期发表论文,就生成对抗网络的控制问题给出了自己的办法,AI 科技评论根据原文进行如下编辑。
简介
生成对抗网络(GANs)是最近几年提出的新方法,在其问世之后的短短时间内,生成对抗网络已经在生成真实的样本上表现出很多有前途的结果了。然而, 在生成对抗网络的使用上,目前还有未能解决的问题:由于发生器(Generator)的输入变量是随机的,控制GANs产生的样本非常困难。业界了已经有了一些解决方案,但是这些方案普遍没有办法很好地应用在复杂问题上。除此之外,难以将发生器集中在产生真实的图像和产生有差异的图像的任务上,也一直亟待解决。比如,沿用已知的模型,用于脸部图像生成的发生器就无法专注于两个目标中的某一个,即根据标签产生人脸的真实图像,或是产生有差异的人脸图像。这篇文章则介绍了一种新的方法,即可控生成对抗网络(Controllable GAN, CGAN)。CGAN在控制生成样本上有很强的表现,同时,它还能控制发生器专注于单个目标(生成真实的图像或产生不同的图像)。文章最后使用CelebA的数据库对CGAN进行评估。CGAN实现了对GAN的控制,相信可以加速和助益GAN的研究。
背景
生成对抗网络(GAN)是一种神经网络架构,被引用来生成真实的样本。尽管这个架构是近几年才提出的,GAN的大量成果不仅表现于生成真实样本上,还体现于机器翻译和图像超分别率的应用中。
但是,由于样本发生器的输入是随机分布的,在生成真实样本的时候,很难控制GAN。比如,生产的vanilla GAN样本是现实的,也具备多样性,但是随机输入和生成样本的特征之间的关系却不明显。
在过去的几年中,尝试控制由GAN产生的样本的研究从未停止。其中,最为著名的控制方法就是有条件的GAN(Conditional GAN)。有条件的GAN将标签分别输入发生器(Generator)和鉴别器(Discriminator),由此他们可在训练时有条件的工作。但是,这种有条件的GAN不能解决控制发生器专注于一个任务的问题,如生成真实样本和根据输入标签在样本之间产生差异的任务。例如:CelebA数据库包含202559张名人的脸部图片,有40中不同的特征标记,如戴帽子或者年轻人等。当有条件的GAN生成真实样本时,预训练的只有一些简单的标签,比如笑、帽子之类的。为了让发生器具备处理复杂标签的能力,如尖尖的鼻子或者拱形的眉毛,需要控制发生器更注重根据标签生成不同的样本。
可控生成对抗网络 CGAN
在这篇论文中,作者介绍了一种新颖的生成对抗网络架构来控制生成的样本,称为可控生成对抗网络(CGAN)。CGAN由三个部分构成,发生器/解码器,鉴别器和分类器/编码器。在CGAN中,发生器和鉴别器、分类器同时工作;发生器旨在欺骗鉴别器并同时需要被分类器正确的进行分类。
与现有的模型相比,CGAN具有两个主要的优势。首先,CGAN可以通过参数化损失函数专注于条件GAN的两个主要目标中的一个目标,即真实样本或者表现差异。因此,如果要牺牲真实实现差异性,CGAN可以根据复杂标签生成面部图像。其次,当鉴别器使用条件GAN时,CGAN使用一个独立的网络进行相应输入标签的特征映射。因此,鉴别器可以更多的专注进行假样本和原始样本之间的甄别,从而提高生成样本的真实性。 在这篇论文中,使用CelebA进行CGAN的实验。通过实验,证实了CGAN可以有效地根据输入标签生成人脸图像样本。
材料和方法
CGAN由三种神经网络结构组成,发生器/解码器,鉴别器和分类器/编码器。图1中描述了这种CGAN的架构。这三种结构相互协作,发生器尝试欺骗鉴别器,这与vanilla GAN相同,并且旨在正确的被分类器进行分类。发生器和分类器也可以理解为解码器-编译器的结构,原因是标签是发生器的输入同时是分类器的输出。
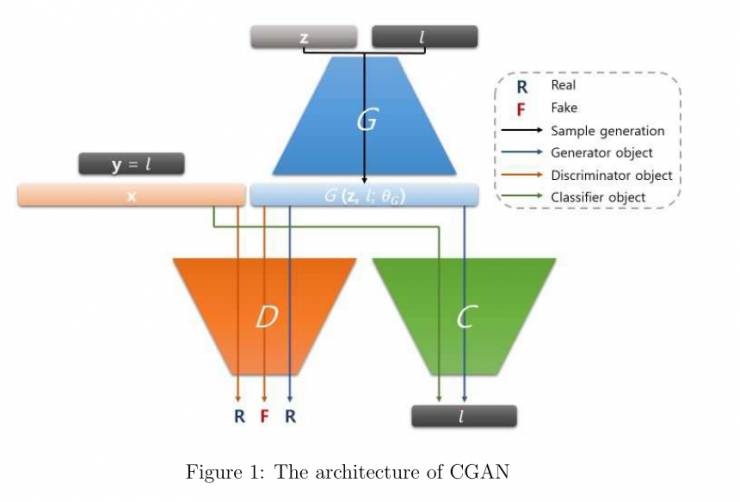
CGAN对如下的方程进行最小化:
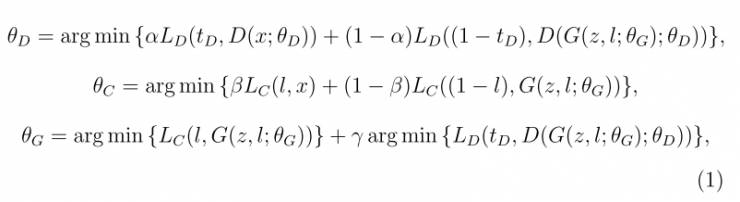
CGAN强制将特征映射到相应输入发生器的l。这个参数决定了发生器专注于样本真实性的程度。这篇论文中应用了Boundary Equilbrium GAN(BEGAN)架构,即目前最新的生成图像样本的GAN架构。发生器由四个反卷积层组成。每层使用5*5的过滤器。鉴别器由四个卷积层和4个反卷积层构成。分类器由4个卷积层和一个全连接层构成。为了验证方法的效率,并没有使用dropout和max-pooling。我们将α设置为0.5,β设置为1并将γ设置为5。
结果和讨论
使用CelebA数据库生成多标签的名人人脸图片样本
通过想发生器输入多个标签,CGAN可以生成多标签样本。CelebA数据库由多个标签的图片构成。例如,一个样本图片可以有“Attractive”,“Blond Hair”,“Mouth Slightly Open”和“Smiling”的标签。
首先,使用一个标签生成图片。生成的样本见图2。

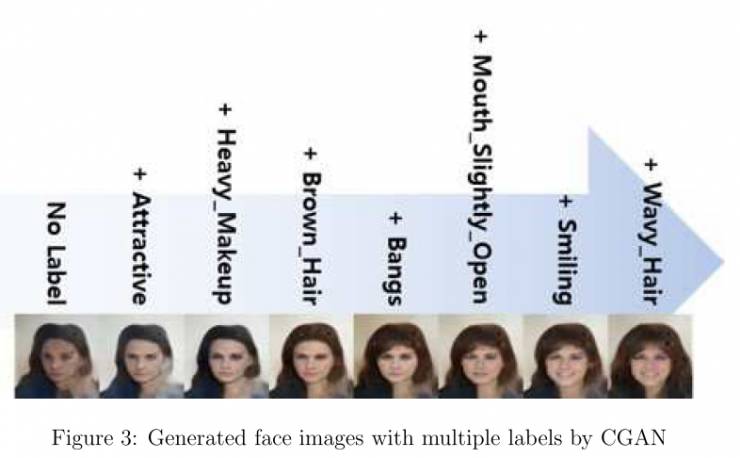
像之前讨论的,CGAN可以通过向发生器输入多个标签生成多标签的样本。图3是通过CelebA生成的多标签图片。其中“No Label”的图片只通过随机分布z~N(0,1)生成,并且输入标签设置成一个0矩阵,长度为40,l=【0,0,...,0】。“+ Attractive”的图片由同样的z和“Attractive”标签的二进制生成。类似的,最后一组图片是由z和多个标签生成的。
CGAN还具有另一优势:相较于条件GAN,CGAN可以生成label-focused样本。通过选择γ的低值,可以讲发生器更多的专注于输入标签。图4是CGAN,γ=5和条件GAN的对比。从图中可以看出CGAN生成的人脸图片比条件GAN更契合输入标签。例如,使用“Arched Eyebrow”标签时,CGAN生成的图片全部符合这个标签的特征,而条件GAN则有偏差。

结论
这篇论文提出了一种新的生成网络模型,即CGAN,这种模型可以控制生成的图片样本。CGAN包含三个模块,发生器/解码器,鉴别器和分类器/编码器。通过将相应的特征映射到输入标签上,生成的样本可以被有效地控制。
其实CGAN是一个简单的架构,即为vanilla GAN和解码-编码结构的组合。通过实验,作者证实了CGAN可以生成具有多个标签的人脸图片。同时,这种控制有效性也可以对生成对抗网络的研究带来一些重要的提升。
论文地址:https://arxiv.org/abs/1708.00598
AI 科技评论编译
————— AI 科技评论招人啦! —————
我们诚招学术编辑 1 名(全职,坐标北京)
你即将从事的工作内容:
报道海内外人工智能相关学术会议,形成具有影响力的报道内容;
采访高校学术青年领袖,输出人工智能领域的深度观点;
跟进国内外学术热点,深入剖析学术动态;
我们希望你是这样的小伙伴:
英语好,有阅读英文科技网站的习惯;
兴趣广,对人工智能有关注及了解;
态度佳,有求知欲,善于学习;
欢迎发送简历到 guoyixin@leiphone.com
————— 给爱学习的你的福利 —————
随着大众互联网理财观念的逐步普及,理财规模随之扩大,应运而生的智能投顾,成本低、风险分散、无情绪化,越来越多的中产阶层、大众富裕阶层已然在慢慢接受。王蓁博士将以真实项目带你走上智能投顾之路,详情请识别下图二维码或点击文末阅读原文

————————————————————



