演讲实录丨李磊:机器写作与AI辅助创作
本文大概:4246字 读完共需:20分钟
12月22日-24日,由中国人工智能学会主办的第七届吴文俊人工智能科学技术奖颁奖典礼暨2017中国人工智能产业年会在苏州隆重举行。今日头条与北京大学共同完成的“互联网信息摘要与机器写稿关键技术及应用”项目荣获吴文俊人工智能技术发明奖。本年度获得该奖项的机构还包括清华大学、中科院以及北京航空航天大学等国内顶尖高校。
“吴文俊人工智能科学技术奖(以下简称‘吴文俊奖’)”被外界誉为“中国智能科学科技最高奖”,代表中国人工智能学界的重大突破与最高荣誉。今日头条是今年“吴文俊奖”获奖项目中唯一以企业载体获得专业类奖项的机构,过去该奖通常只授予顶尖高校、重点实验室和科研机构。

今日头条人工智能实验室技术总监李磊作为获奖团队代表在大会现场做了题为“机器写作与AI辅助创作”的报告。报告全文如下:

大家好,非常高兴有机会在冬天来到苏州,和大家在此分享今日头条今人工智实验室近期在人工智能机器写稿与AI辅助创作方面做的一些工作。我是李磊,在今日头条人工智能实验室做自然语言理解方面的研究。。
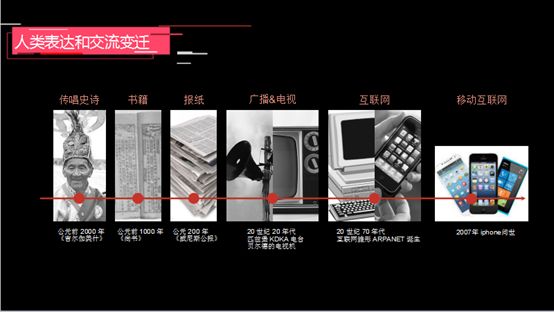
信息被认为是人类的重大需求。在过去3000年,每一次技术的发展都为信息的交流以及人类表达和交互的方式带来了巨大变化,并促进了交流的效率和质量。最早没有科技的情况下,大家只能通过口口相传获得信息,所以传播范围很有限;后来印刷术的出现,让文字可以用纸张来承载保存并且广泛传播;再到上个世纪电子、通讯、无线电、网络的出现,让全世界各个角落的人都可以很方便接收到最新的信息。
过去10年信息的传播方式又发生了重大变化,移动互联网技术的革新,让每个人随时随地都可以接收到最新的信息,并且可以随时随地创作内容。
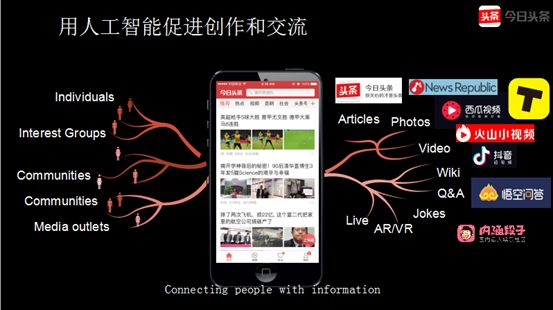
我们认为,在未来的10年,新的技术尤其是人工智能技术将更多促进创作和交流,会去连接内容的创造者与内容的消费者。这些创作者可以是专业的媒体,也可以个人。内容的形式也更为多样,图文、小视频甚至围绕音乐做一些表演...,每个人都可以拍身边的故事,利用计算机视觉的技术去创作更漂亮、更有趣的内容,然后通过我们的平台很方便的分享出去。
同时,像问答,让专家来回答问题,也会成为内容的一种形式。当然,我们要把内容创作和交流的效果提高,为每个人推荐他最喜欢的内容,涉及到三个最核心的技术:

第一,理解人。我们要用机器学习技术去理解这个人的兴趣爱好,他的年龄、性别,他过去读了哪些文章等等,这些组合起来会刻画出他兴趣方面完整的画像。
第二,理解内容。内容不单单是图文,也可以是视频,内容的主题是什么?关键词是什么?热度是什么?这些会决定推荐质量的好坏。
第三,环境特征。在北京还是在上海还是在苏州,要因地制宜推荐不同的内容。
将这三方面结合,再利用机器学习的算法,就可以给每一位用户推荐他真正喜欢的内容。今日头条拥有海量的用户群体,为每个人都推荐他真正喜欢的内容,这离不开强大的计算能力。每天,我们的服务器会收到百亿次的请求,我们有6万余台服务器每时每刻都在计算每一位用户的每一次点击,我们每天处理的数据量超过7.8PB,这些帮助我们更好的理解用户真正喜欢什么。
做好内容引擎有四个环节,包括内容的创作,内容的推荐以及围绕内容讨论还有内容的审核。今天我会重点介绍内容的创作,我们如何应用AI的技术帮助作者用户创作更好的内容。
首先是机器写作。为什么要写作机器人呢?这里有一幅图表,它画的是在我们的平台上发文章被阅读的频次,以及不同频次所对应的文章数量。可以看到它是一条直线,有大部分的文章,是阅读次数都比较少,有少量的文章被阅读的次数非常非常多。这是在很多领域都非常常见的一个现象。

为什么要说这张图呢?我们发现有很多每一篇文章的创作都需要投入不小的精力,但很多内容,阅读量非常小可能不会超过1000次,这样的内容投入产出效率可能比较低。我们认为如果这部分内容可以用机器创作的话,成本就会小很多。
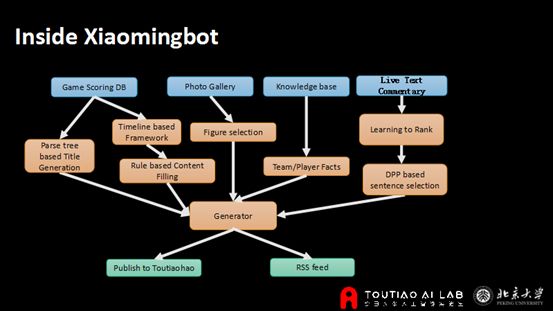
我们从去年6月开始做了一个机器人Xiaomingbot。一开始是做奥运会的赛事文章撰写。它包涵三方面的输入——实时比分,实时图片数据,以及热门比赛的文字直播。我们的机器人将这三方面融合起来,最后生成对应的文章。
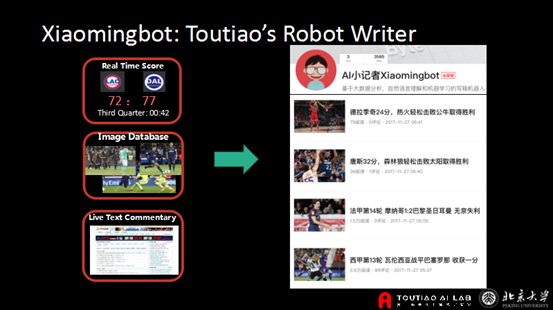
奥运会之后Xiaomingbot陆续创作了一系列体育方面的文章,包括NBA、CBA等等。所有文章从协作到配图,再到分发推荐给读者全部都是自动完成,中间不需要任何人工参与,这个效率就大大提高了。
现在Xiaomingbot不仅能写体育文章,还有财经、房产等等。财经新闻有“小明看财经”这个头条号,房产是房产情报站,世界各领域热点有“小明看世界”,一系列内容都由这些头条号自动放出。
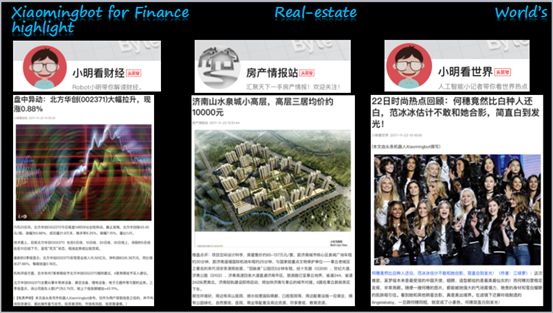
写作机器人的优势明显。首先速度快,其次篇幅长短灵活,另外从质量上看,从去年8月份开始到现在,xiaomingbot一共写了2万多篇文章,读者的阅读率是16%。我们对比了一下记者撰写文章的阅读率,也是16%左右。也就是说机器人写的文章质量和人是接近的。这四个头条号现在也积累了非常多的粉丝,这项技术是我们和北京大学合作,也得到了今年的吴文俊奖。
xiaomingbot所主要涉及的技术包括以下方面:
一是有关于比赛的实时比分的数据。第二,关于图片,我们通过计算机视觉分析图片内容,将它和文字结合。第三方面是知识库的建立,像比赛球队的历史,球员信息。第四,是网上有一些直播文字抓取过来的信息,我通过机器学习技术去挑选最重要的内容,融合进文章中。网上的直播文字信息其实非常复杂,有不重要的信息,甚至会夹杂网友的评论。我们在生成新闻的时候希望把比赛最重要的环节,像进球、判罚等等给找出来。
人工另外,需要考虑挑选出来的句子相互之间相似度要尽量小,但涵盖信息量又尽量大。通过这个算法可以实现将直播文字中的信息挑选出来。
人工我们还利用神经网络来做摘要。在“小明看世界”这个头条号中,会通过摘要的方法把不同领域中一天最核心的信息摘出来,最后合成一篇文章。

人工这部分工作我们通过层次化的LSTM模型对文章做建模。第一个维度是句子层面,通过循环神经网络对句子建模,学句子里面的语义信息,并且结合传统的模本特征,把它组合其他,最后组合成一个向量,用它来代表每一个句子。每天有很多句子,把这些代表句子含义的向量连起来,就变成一个向量的串。
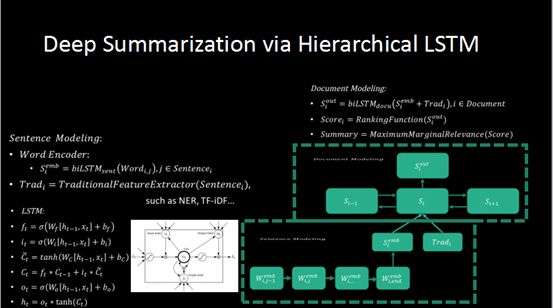
最后的问题就转化成挑选出代表文章中心思想的重要句子,把它作为最后的摘要,我们仍然可以通过LSTM来进行求解。在头条每天有200万篇的文章,可以通过我们摘要的服务自动生成摘要。
除了上述的模板生成,机器学习以及摘要方法的生成。我们最后想探索的是自由语言的生成。通过做一个模型,这个模型可以学习头条上面所有创作者写的文章,去学习他们的写作风格,并且给定一个风格可以很好的模仿,把文章自由的写出来。
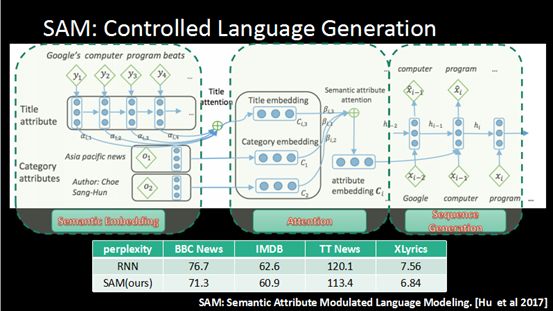
这里用到一个技术,Free Style Language Generatino,我们在Generatino过程中,还希望去控制写作风格,当然有很多方面我们可以去控制。比如说我们可以给定一个题目,做命题作文;或者指定模型写某一类的文章,比如说是财经类、科技等不同品类的文章,有不同写作的风格。
举个例子,左边是头条号作者王晓天写的《你的样子》,右边是我们模仿好妹妹乐队的风格写了同样一个标题的词《你的样子》,可以看到读上去还是比较通的。

这是通过一个SAM模型,叫做Controlled Language Generation。这个模型有三方面,第一方面,是通过对标题建模,对语意属性建模,把所有这些都变成语义的向量,对标题建模用了SAM。第二方面,这些语义信息重要程度不同,我们通过一个机制区分这里面哪个语义标签是重要的。最后是生成,生成我们通过循环神经网。但在这个循环神经网里面,我们加入了前两步学到的语义信息去控制风格。这个方法我们在数量级上做测试发现越小越好,优于传统方法。如果大家可以感兴趣可以看这篇文章。
接下来我和大家分享一些我们在辅助创作者生产上做的一些工作。
首先是机器翻译,我们认为很多内容不需要凭空生成,可以借助翻译的技术将英文翻译成中文,或者将中文翻译成英文获得更多信息。
翻译以前是通过统计的方法做,2014年开始,一个新的方法是把原句用序列的方法—循环神经网络来建模,去解码。在生成的过程中仍然用一个序列的模型,比如说STM。中间还会加上一些生成的过程当中目标语言的一句话里面每一个词,针对原句每一个词有对应的不同权重,通过这个机制可以学到这个权重并且很好的对应起来。

我的一位同事最近做了一个工作叫Modeling Psat Future,在翻译的过程中生成目标语言的句子,比如说生成到第五个字的时候,未来还有哪些信息在原句当中没有翻译出来的,我们把这把它称为未来的信息,将没有翻译出来的信息直接建模。我们发现把这两部分信息,也就是已翻译的信息和将要翻译的信息结合,可以做一个更好的翻译。
比如说原语言这里给了两句英语以及对应的翻译,我们也对比了业界做的比较好的公司,可以发现还是有一些case通过这个方法可以做的更好。
刚才提到我们还有图文匹配技术为文章自动配图。我们2016年收购了一家图片社——东方IC。作者在写文章的时候,起一个标题或者写一句话,机器就可以通过自然语言理解技术去分析,这句话的语意,自动地从东方IC图库里面挑选出比较匹配的图片,配到这个文章中。

有些作者有固定的原文配图,我们可以帮助作者挑选文章的封面图。原文图片可能大小不一,为了配合封面固定大小,机器会利用人脸识别等技术去识别图片中最关键的区域,设置为封面。比如含有人脸的图片,将人脸的技术抠出来,还有一些动物,可以将它最关键的部分抠出来放在封面中。
目前,今日头条识别技术检测时间只需要10毫秒,可以对视频图片进行实时检测。
最后我将分计算机视觉方面的技术如何帮助创作更好的视频。
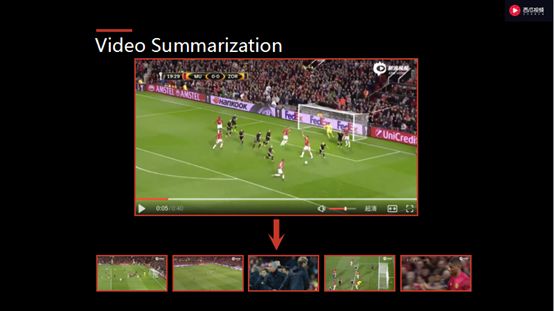
首先,可以自动做视频剪辑,比如说足球比赛最关键的片段通常只有3-5分钟,我们可以利用自动分析的技术做视频的摘要,把里面最关键的信息摘出来组合成一个片断自动播放。
另外,通过单一图像分析,我们可以仅凭视频里面的一桢就分析出这个视频中最主要的人体部位,以及各部位的位置。依赖这一技术,我们可以实现人体分割以及背景变换。这一技术目前已经应用到抖音小视频。
这里的难点不在于身体分割,而是头发的分割。因为头发非常细,边缘部分的识别和分割非常难。我们专门针对头发做了识别优化。识别后能针对头发的颜色做一个替换。这个技术也用到了抖音小视频,成为了排名前三的特效。
最近也在研发人体姿态以及人体关键部位比如手肘、脚踝、膝盖等位置的实时识别。依靠这一技术,抖音近期上线了一个新的功能叫尬舞机。这一功能让抖音在App Store排行榜上到了第一。

以上就是我介绍主要内容。最后我将提出机器写作方面我们面临的一些技术挑战。
一是深度的内容很难自动生成的。
二是计算机的推理能力以及自然语言理解方面仍有更多的挑战。
三是目前写作还不能针对不同读者做到个性化。

如果大家对机器写作感兴趣,可以关注“AI小记者Xiaomingbot”,”小明看世界”,“小明看财经”等头条号。
CAAI原创 丨 作者李磊
未经授权严禁转载及翻译
如需转载合作请向学会或本人申请
转发请注明转自中国人工智能学会






