OpenAI Baselines: ACKTR & A2C
原文地址:https://blog.openai.com/baselines-acktr-a2c/
code链接:https://github.com/openai/baselines
论文链接:https://arxiv.org/abs/1708.05144
我们发布了两个新的OpenAI Baselines实现: ACKTR和A2C。 A2C是Asynchronous Advantage Actor Critic (A3C)的同步确定性变体,我们发现它们具有相同的性能。 与TRPO和A2C相比,ACKTR是一个比样本高效的强化学习算法,每次更新只需要比A2C稍微更多的计算。

ACKTR(发音为「actor」,Actor Critic using Kronecker-factored Trust Region)是由多伦多大学和纽约大学的研究者联合开发的新算法。OpenAI与他们合作发布了Baselines implementation。作者在论文中展示 ACKTR 算法可以学习模拟机器人(以像素作为输入,连续的动作空间)和 Atari 游戏(以像素作为输入,离散的动作空间)的控制策略。
ACKTR 融合了三种不同的技术:以 actor-critic 算法为基础,加上 TRPO 来保证稳定性,同时融入了提升样本效率和可扩展性的分布式 Kronecker 因子分解(Kronecker factorization)。
样本和计算效率
对于机器学习算法,考虑两个代价很重要:样本复杂度和计算复杂度。 样本复杂度是指代理与其环境之间的交互时间的次数,计算复杂度是指必须执行的数值操作量。
ACKTR比一般方法(如A2C)具有更好的样本复杂度,因为它在自然梯度方向上而不是梯度方向(或像ADAM中的重新缩放版本)中步进(take a step)。 自然梯度给出了参数空间中的方向,其使用KL-散度测量来实现网络的输出分布中每单位变化的目标中的最大(瞬时)改善。 通过限制KL分歧,我们确保新政策的行为与旧的不同,这可能导致业绩的崩溃。
对于 ACKTR 的计算复杂度,因为其使用计算非常高效的 K-FAC 算法来估算自然梯度,所以 ACKTR 的每个更新步仅比标准梯度算法慢 10% 到 25%。之前的自然梯度算法,例如 TRPO(Hessian-free optimization)则需要非常昂贵的共轭梯度计算,致使其每步计算所需时间非常长。
在下面的视频中,您可以看到使用ACKTR训练的代理之间的不同时间步长的比较,以解决游戏Q-Bert和用A2C训练的游戏。 ACKTR试剂得分高于用A2C培养的成分。
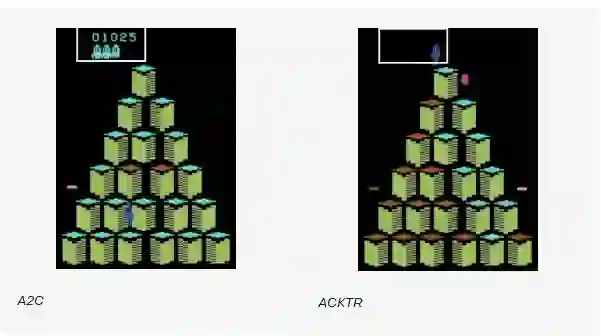
用ACKTR训练的代理(右)在比其他算法(如A2C(左))训练的时间短的时间内获得更高的分数。
Baseline and Benchmarks
OpenAI Baselines 发布包含了 ACKTR 和 A2C 的代码实现。
我们还评估了 ACKTR 在一系列任务的表现。下文中,我们展示了 ACKTR 在 49 个 Atari 游戏中与 A2C、PPO、ACER 表现的对比。注:ACKTR 的作者只用了 Breakout 游戏对 ACKTR 的进行了超参数的调整。
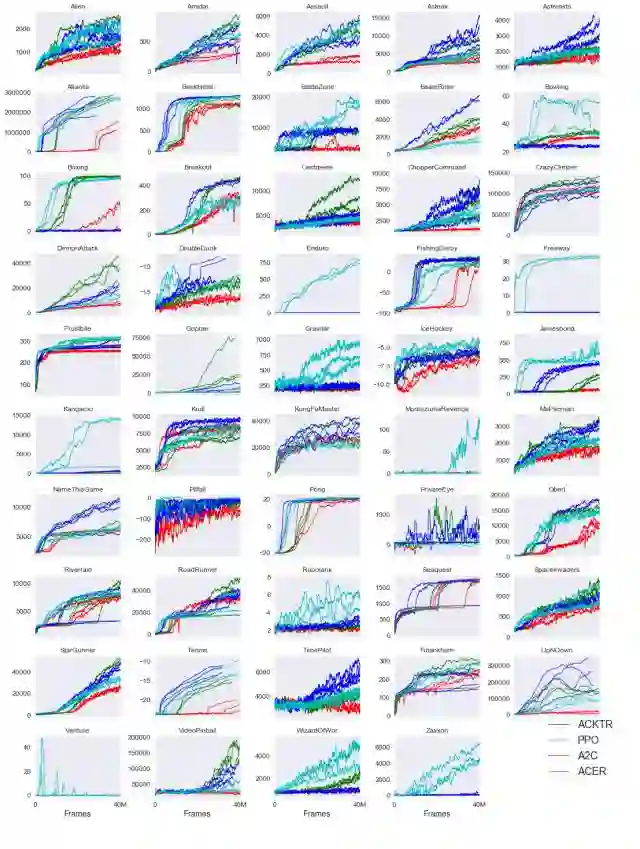
ACKTR性能也可以随batch大小而变化,因为它不仅从每个batch中的信息中导出梯度估计,而且还使用该信息来近似参数空间中的局部曲率。 该特征对于使用大批量尺寸的大规模分布式训练是特别有利的。
A2C和A3C
自从Asynchronous Advantage Actor Critic发表以来,A3C一直非常有影响力。 该算法结合了几个关键思想:
一种更新方案,其操作在固定长度的经验段(例如20个时间步长)上,并使用这些段来计算返回和优势函数的估计。
在策略和价值功能之间共享层次的体系结构。
异步更新。
阅读本文后,AI研究人员想知道不同步是否导致性能提高(例如“可能增加的噪声是否会提供一些正规化或探索?”),或者只是一个实现细节,允许使用基于CPU的更快的训练实现。
作为异步实现的替代方法,研究人员发现,您可以编写一个同步的确定性实现,等待每个演员在执行更新之前完成其经验,并对所有演员进行平均。 该方法的一个优点是可以更有效地使用GPU,这些GPU在批量大的情况下表现最好。该算法叫作 A2C(advantage actor critic 的缩写)。
我们的同步A2C实现表现优于我们的异步实现 - 我们没有看到任何证据表明异步引入的噪声提供了任何性能优势。 当使用单GPU机器时,这种A2C实现比A3C更具成本效益,并且在使用较大策略时比仅限CPU的A3C实现要快。
我们的代码包含了用 A2C 来训练的 CNNs,LSTM 的实现。



