微软亚研院副院长周明:从语言智能到代码智能

本文来源:智源社区
整理:罗丽
1
NLP预训练模型到代码智能预训练模型
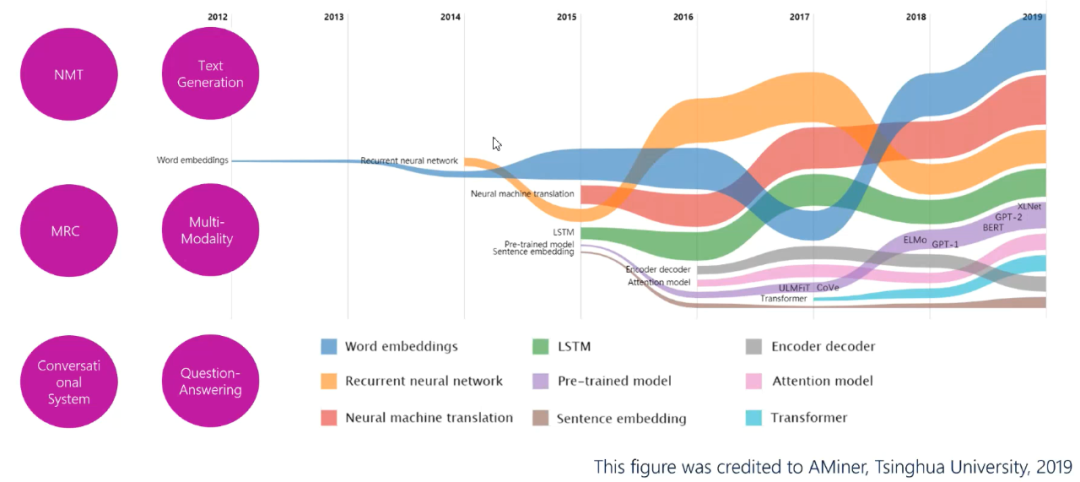
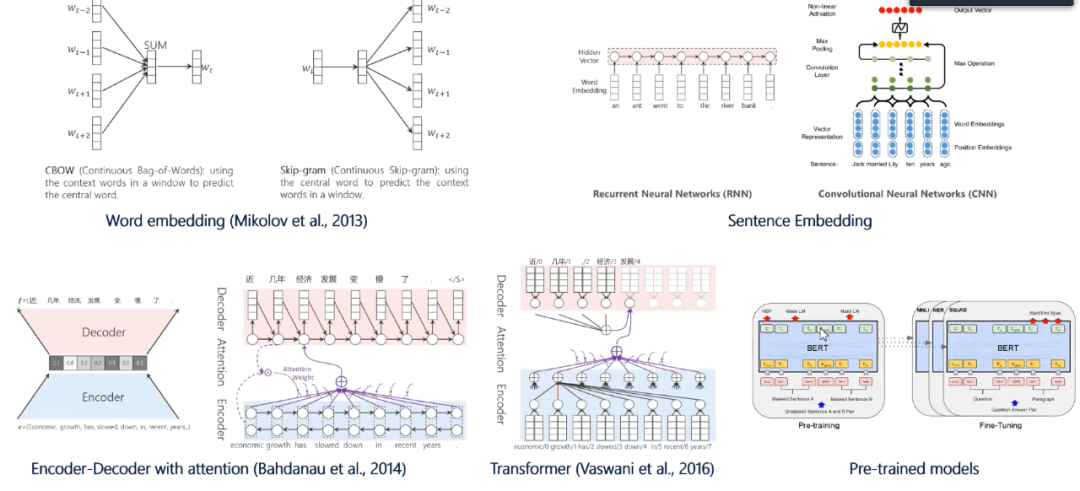 图2:NN-NLP的技术演进
图2:NN-NLP的技术演进
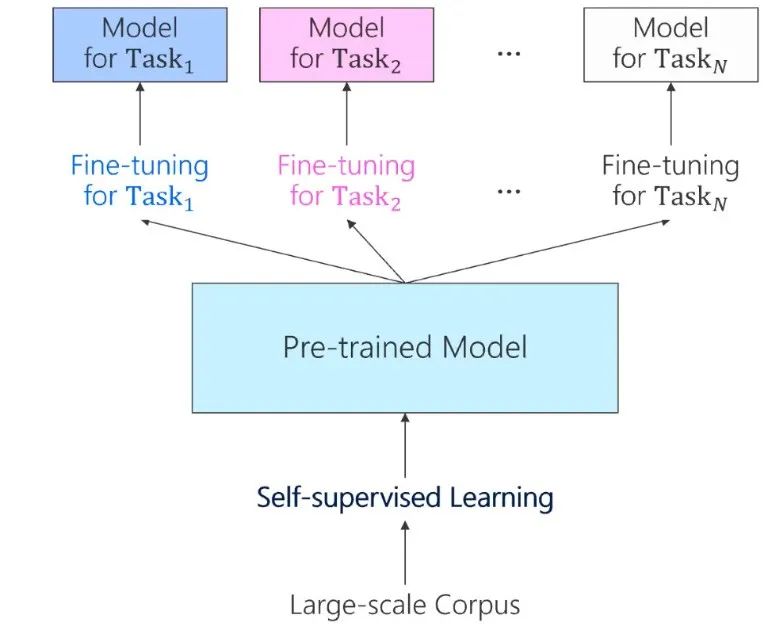
 图4:自监督学习的预训练
图4:自监督学习的预训练
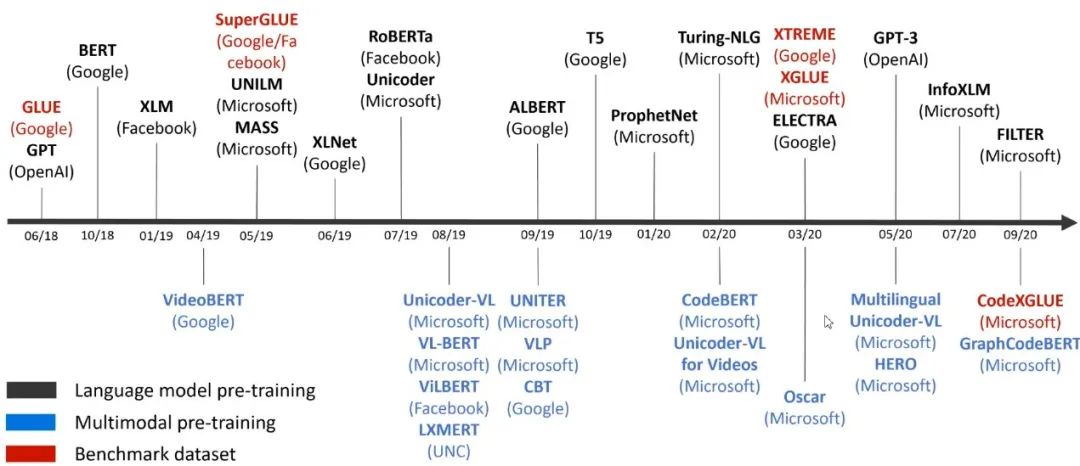
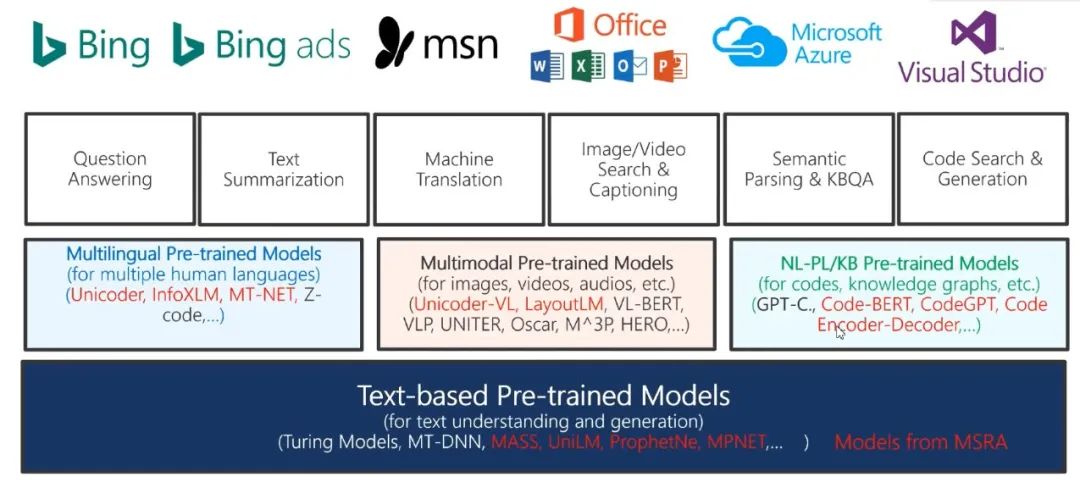 图6:微软预训练模型的主要应用
图6:微软预训练模型的主要应用
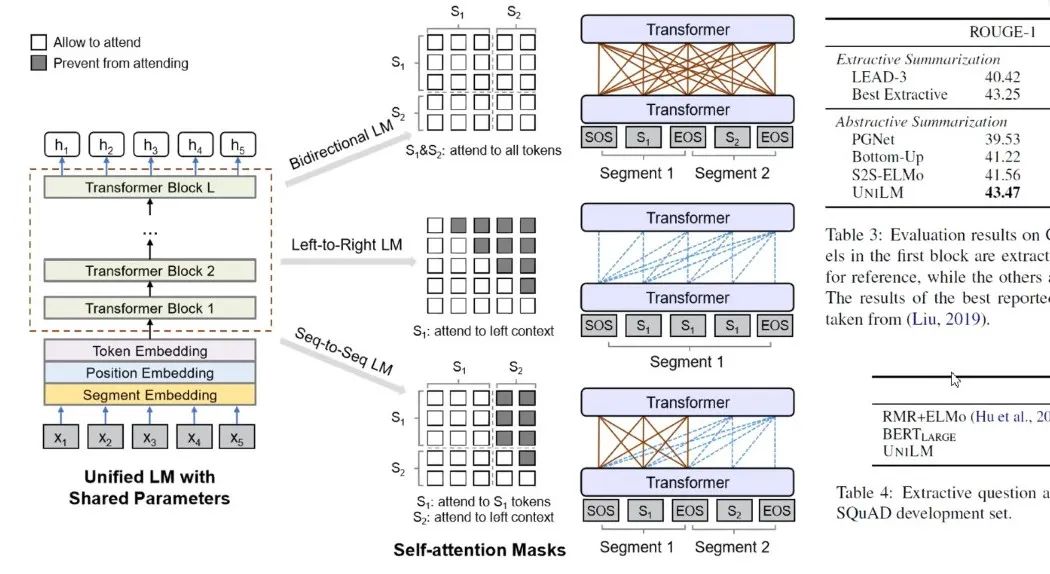 图7:UniLM
图7:UniLM
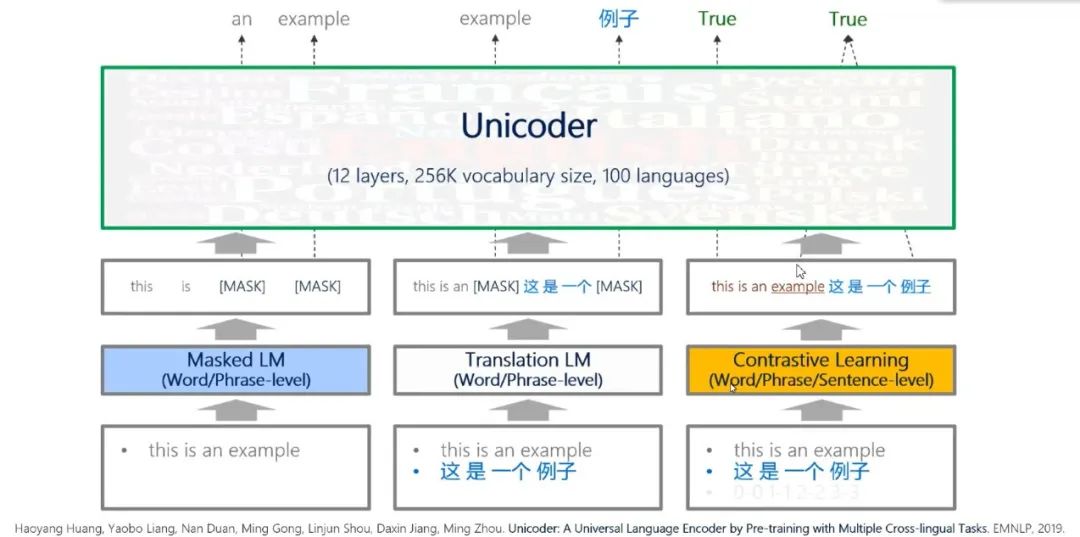 图8:Unicoder
图8:Unicoder
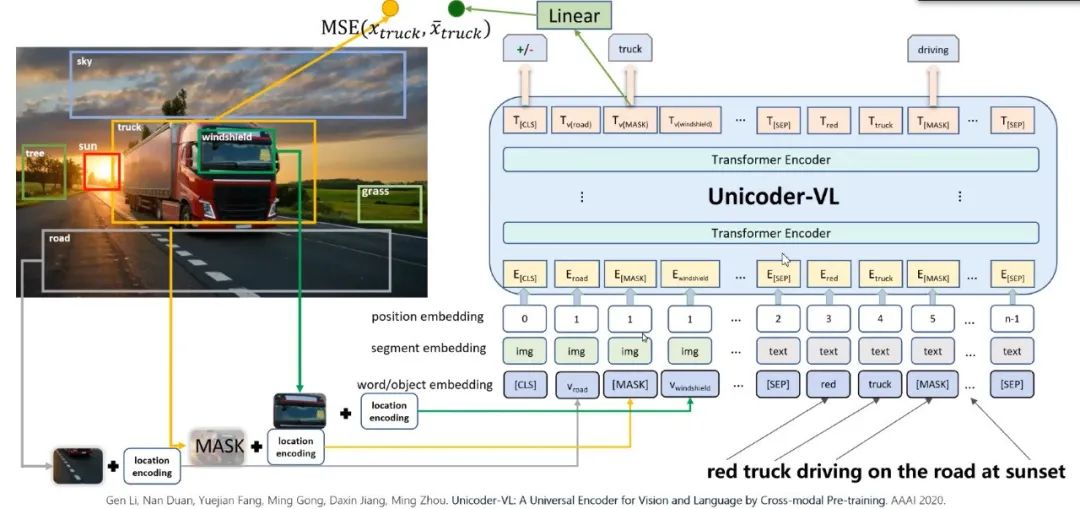 图9:Unicoder-VL for Images
图9:Unicoder-VL for Images
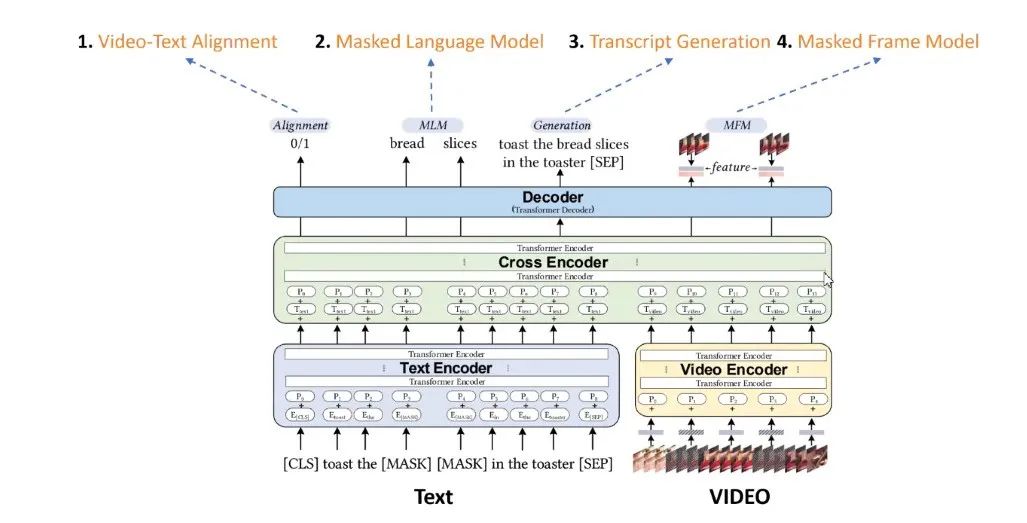 图10:Unicoder-VL for Videos
图10:Unicoder-VL for Videos
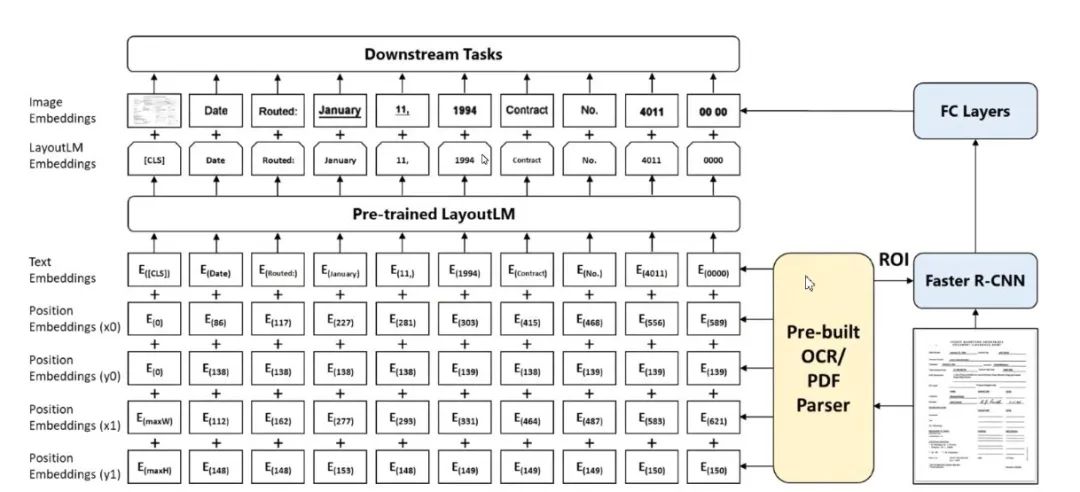 图11:LayoutLM: Text Layout Pre-training
图11:LayoutLM: Text Layout Pre-training
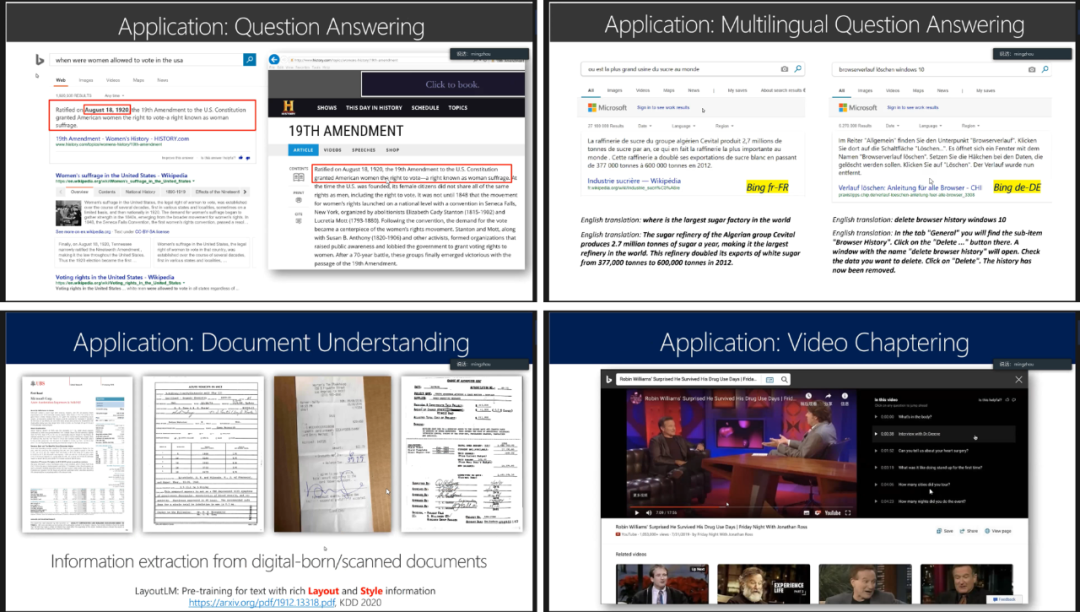 图12:预训练模型的应用
图12:预训练模型的应用
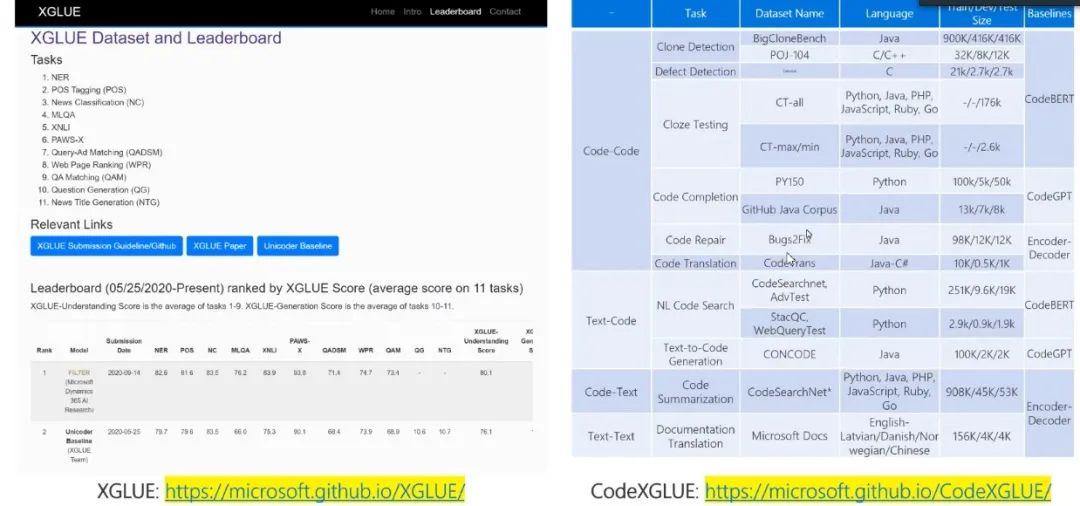 图13:数据集XGLUE
图13:数据集XGLUE
如何用预训练模型做代码智能
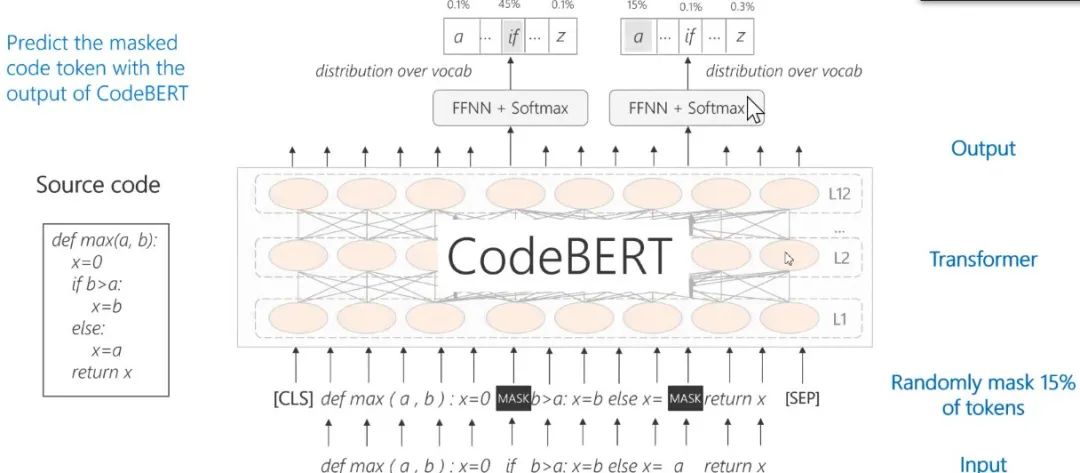 图14:CodeBERT——Pre-Train with Code
图14:CodeBERT——Pre-Train with Code
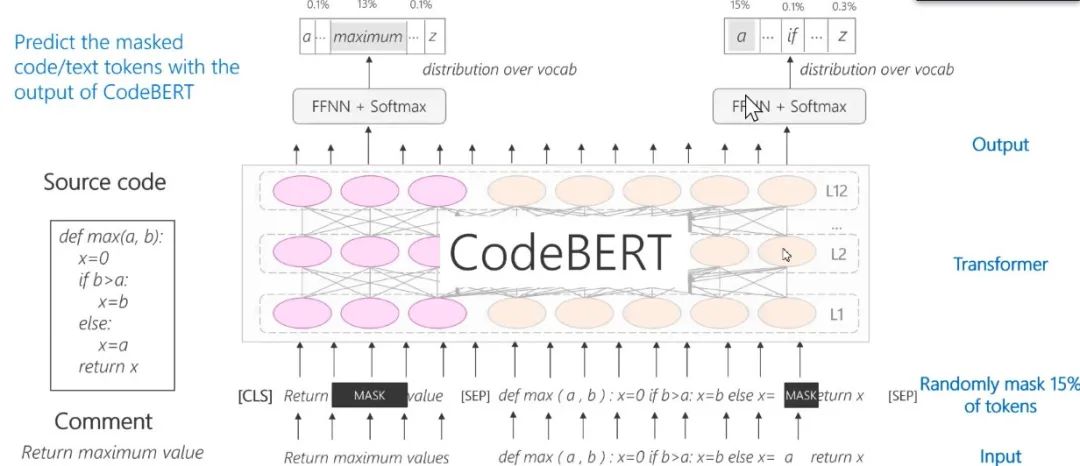 图15:CodeBERT:Pre-Train with code + Text
图15:CodeBERT:Pre-Train with code + Text
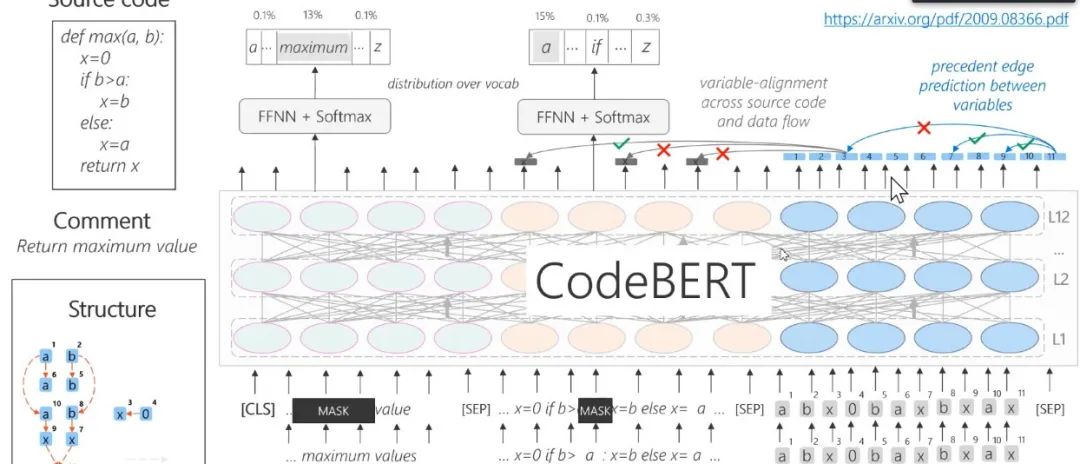 图16:CodeBERT——Pre-Train with Code + Text + Structure
图16:CodeBERT——Pre-Train with Code + Text + Structure
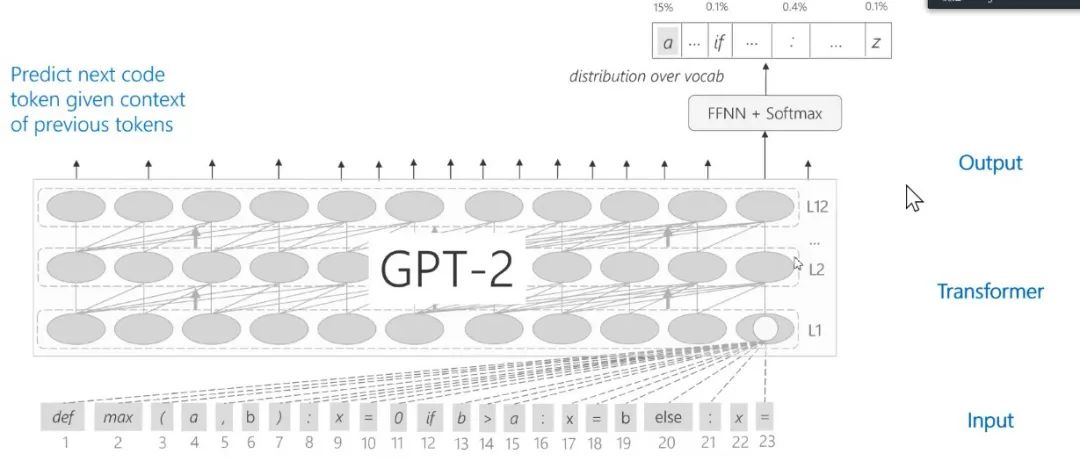 图17:CodeGPT
图17:CodeGPT
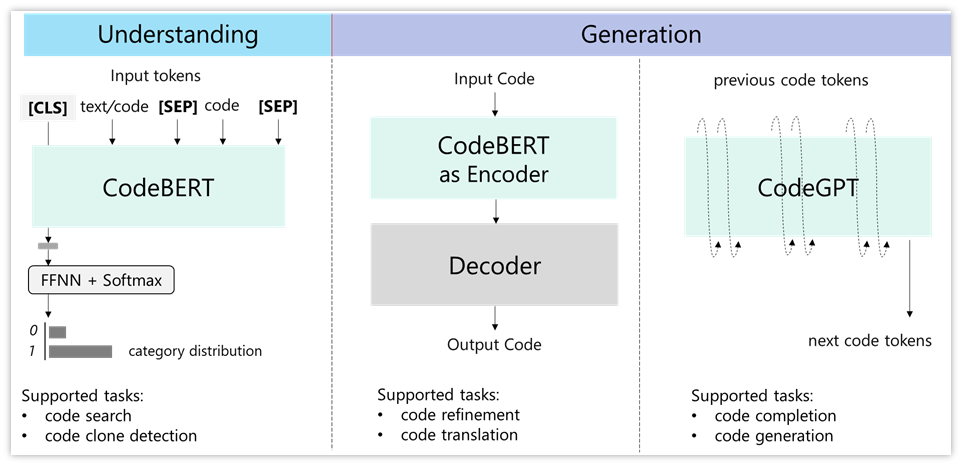 图18:Fine-tuning框架
图18:Fine-tuning框架
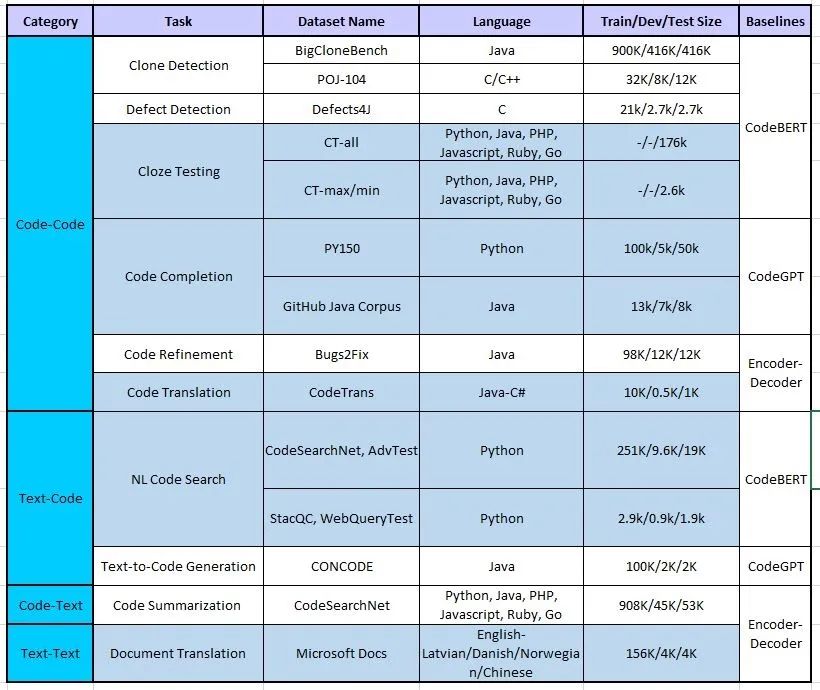 图19:CodeXGLUE
图19:CodeXGLUE
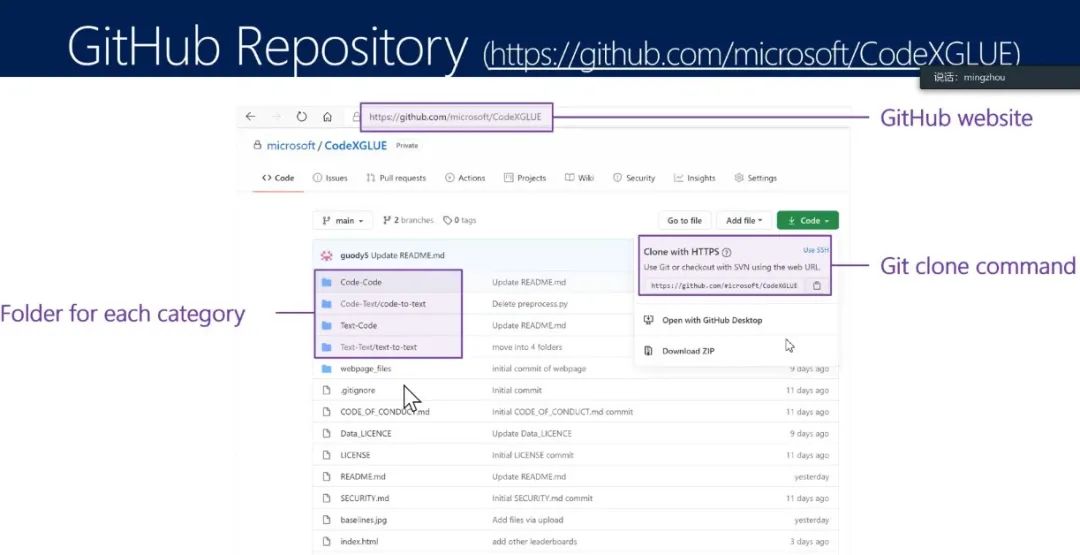 图20:GitHub链接
图20:GitHub链接
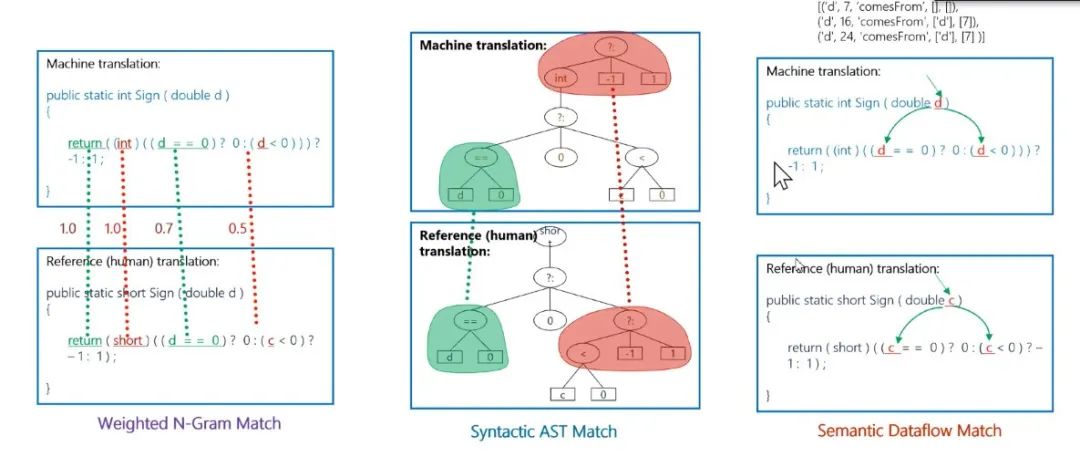 图21:CodeBLEU
图21:CodeBLEU
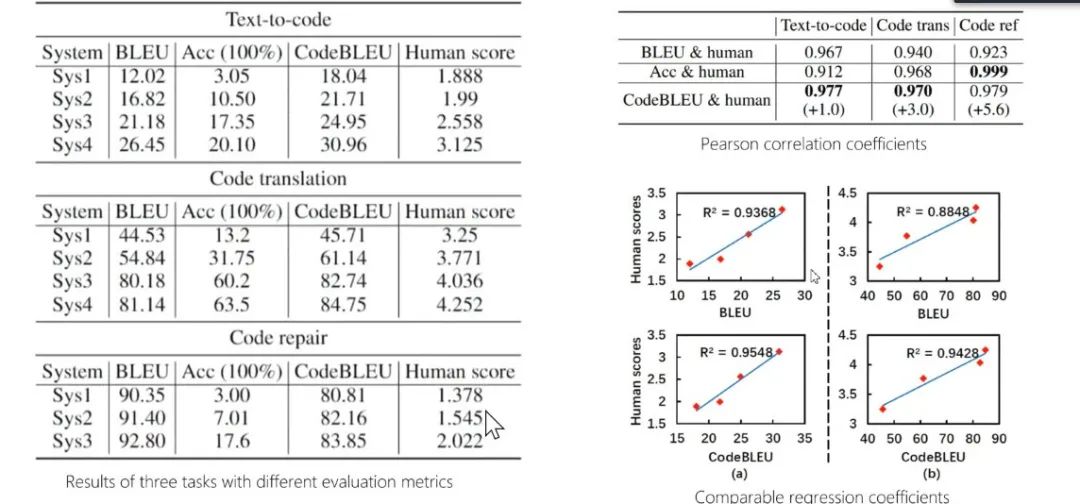 图22:CodeBLEU实验
图22:CodeBLEU实验
问答环节


点击阅读原文,直达AAAI小组!
登录查看更多
相关内容

专知会员服务
32+阅读 · 2020年2月21日
Arxiv
0+阅读 · 2021年1月28日
Arxiv
27+阅读 · 2021年1月21日


相关VIP内容
专知会员服务
32+阅读 · 2020年2月21日
相关资讯
相关论文
Arxiv
0+阅读 · 2021年1月28日
Arxiv
27+阅读 · 2021年1月21日