ACL2019最佳长论文阅读笔记,降低机器翻译中的exposure bias
文章知乎链接 https://zhuanlan.zhihu.com/p/92654122
今天开组会的时候一个师兄说到了这篇文章,之前就有一定的印象,现在补看完后赶紧写一篇阅读笔记记录一下。论文的题目为《Bridging the Gap between Training and Inference for Neural Machine Translation》
文章简介
文章发表于ACL2019,是 ACL2019的最佳长论文。作者在论文中提出了一种方法来解决文本生成当中的exposure bias问题,并应用到了机器翻译当中。

背景知识
没做机器翻译的同学可能不知道为什么机器翻译中存在exposure bias的问题(后面我也会整理一下机器翻译的一些资料,虽然我也不知道什么时候有空填坑T-T),这里先解释一下exposure bias产生的原因。
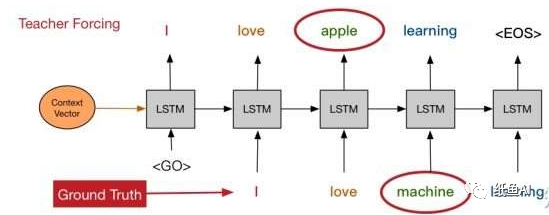
在机器翻译的模型中通常使用的是seq2seq模型。在seq2seq模型的解码端中,当前词是根据前一个词来生成的,但是在训练时使用的是Teacher Forcing,前一个词是从ground truth中得到的,而在测试时,前一个词是模型自己生成的,这就使得在训练和测试时预测出的单词实际上从不同的分布中得到的,这就是exposure bias。由于exposure bias的存在,在测试时,如果某一步出现错误,那么错误就会一直累积(因为训练时前一个单词总是正确的),最终导致生成不正确的文本。
除此之外作者认为在机器翻译的过程中还有另一个问题:overcorrection。即在机器翻译中,损失函数通常是交叉熵,交叉熵函数会严格匹配预测的输出和ground truth是否一致,如果预测的词和 ground truth中的词不同,尽管这个翻译是合理的,但也会被交叉熵纠正,这降低了翻译结果的多样性。
论文的方法
总的来说,作者取消了训练中仅使用ground truth单词的做法,而使用一种概率采样,以一定的概率从模型预测的结果Oracle Word和ground truth中选择一个单词作为当前步的输入,从而一定程度上消除这种偏差带来的影响,下面是具体的选择方法。
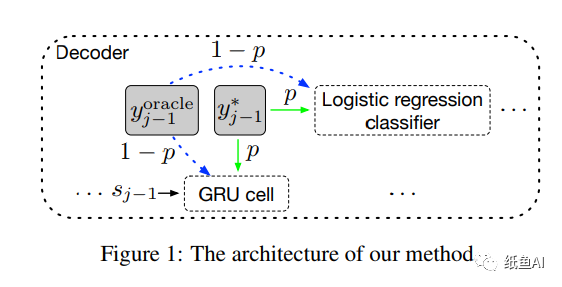
首先作者提出了Oracle Word Selection的概念,即从模型生成的单词中选择当前步的输入,而模型生成单词也有两种方式,一种是词级别的Word-level oracle,另一种是句子级别的输出sentence-level oracle。
Word-level oracle
Word-level oracle旨从模型在 j-1 时刻的备选输出选出单词做为在模型在第 j 步中训练时的输入,而j-1时刻的单词的选择,作者并没有简单地使用概率最大的单词作为输出,而是使用了Gumbel-Max 方法,它是一种简单有效的从类别分布中进行采样的方法。
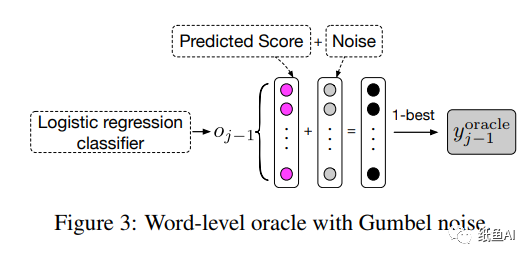
假设oj-1为上一步的备选输出。则作者通过他们的概率加噪后(方式如下)取softmax,然后选择Word-level oracle的单词
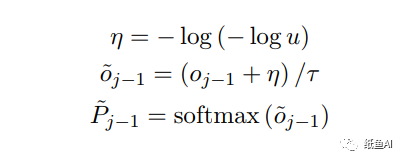
Sentence-Level Oracle
Sentence-Level Oracle是从句子层面来选择 j-1 时刻的单词,在该过程中需要先对每个句子进行 beam search(这个我后面也会更一篇文章详解)。给每个句子选择 k 个候选翻译,然后选择 BLEU 得分最高 的那个句子作为 sentence-level oracle。
但是 Sentence-level oracle 的长度需要和 ground truth 句子的长度相等,而普通的 beam search 不能保 证这一点。为了解决这个问题,作者对 beam search 进行改动,提出了 force decoding:假设 ground truth 句子包含 n 个单词。(1) 如果模型在时间步 n 之前的第 t 步就预测除了终止符,那么选择第 t 步概率第二高的单词作为输出;(2) 如果模型在第 n 步还没有预测出终止符,那么将第 n 步的输出替换为终止符 。
衰减概率采样
上面介绍结束后就是如何采样的问题了。作者在训练的过程中在每个时间步以概率 p 从 ground truth 中采样,以概率 1-p 从 oracle 中采样。但是如果模型在训练刚开始时就从 oracle 中采样过于频繁 (p 较小),将会导致收敛缓慢。如果在模型训练快结束时从 groud 2truth 中采样过于频繁 (p 较大),那么将不能对训练和测试时数据分布的差异进行模拟。所以一个较为合理的方法是:训练初期将 p 设的较大,随着训练的进行逐渐对 p 进行衰减。
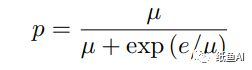
其中e为epoches,u为超参数。
损失函数
前文提到作者认为交叉熵容易over correcton,所以这里作者使用最大似然作为损失函数。
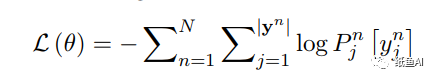
实验结果
作者在机器翻译的 2 个数据集上做了实验,两个数据集分别是NIST ChineseEnglish和 WMT' 14 EnglishGerman。实验结果如下 :
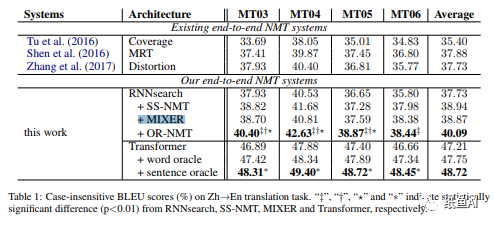
实验结果也证明了该方法在RNN和transformer的nmt模型中都对exposure bias 问题都能起到一定的改善作用,从而提高翻译模型的性能。
本文转载在公众号:纸鱼AI,作者:linhw
推荐阅读
Transformer详解《attention is all your need》论文笔记
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




