随机变量 - 统计学核心方法及其应用

理论与数值计算相结合
涵盖理解和运用参数统计方法所需核心知识
为数据分析构建新方法
下文节选自《统计学核心方法及其应用》, 已获人邮图灵授权许可, [遇见数学] 特此表示感谢!
1.1 随机变量概述
统计学的本质是从具有不可预测性的数据中提取信息,随机变量则是为这种可变性建立模型的数学工具. 在每一次观测中,随机变量随机取不同的值. 我们无法提前预测随机变量的精确取值,但是可以对可能的取值做出概率性的刻画. 也就是说,我们可以描述随机变量的取值的分布. 本章简要回顾应用随机变量时所涉及的专业知识,以及一些常用的结果. 详细论述见参考文献 [8]、[19].
1.2 累积分布函数
随机变量(r.v.)

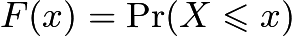
即,
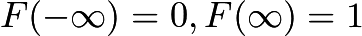


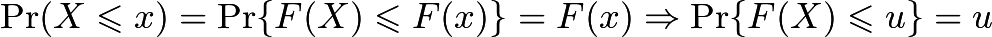
(如果
定义累积分布函数的反函数为 

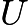

令 



[遇见]小编推荐观看《视频 | QQ分位图的解释及画法》
1.3 概率函数与概率密度函数
在很多统计学方法中,描述随机变量取某个特定值的概率的函数比累积分布函数更有用. 为了探讨这类函数,首先需要区分取离散值(例如非负整数)的随机变量和取值为实数轴上的区间的随机变量.
对于离散型随机变量 
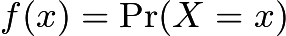
显然,0

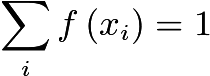
对于连续型随机变量 


显然,




除特别注明外,后续几节主要考虑连续型随机变量,用适当的求和代替积分, 可以得到等价的对离散型随机变量适用的结果. 为了简洁起见,约定当自变量不同时,概率密度函数不同(例如,
1.4 随机向量
从单次观测中很难得到有用的信息. 有效的统计分析需要多重观测和同时处理多元随机变量的能力. 因此,我们需要概率密度函数的多元形式. 二维的情形能够充分阐释所需的概念,因此考虑随机变量 
设 

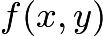

因此,
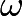



例图1-1 给出了下式中的联合概率密度函数的图像.

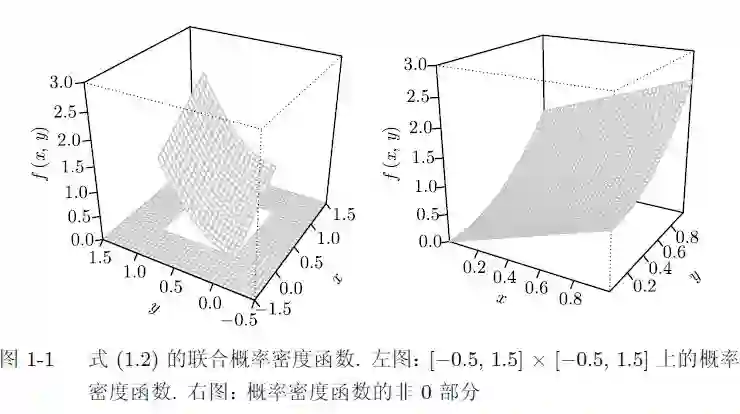
该概率密度函数下的两个概率值的估计如图1-2所示.
1.4.1 边缘分布
继续沿用 
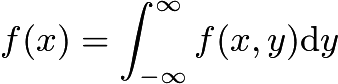
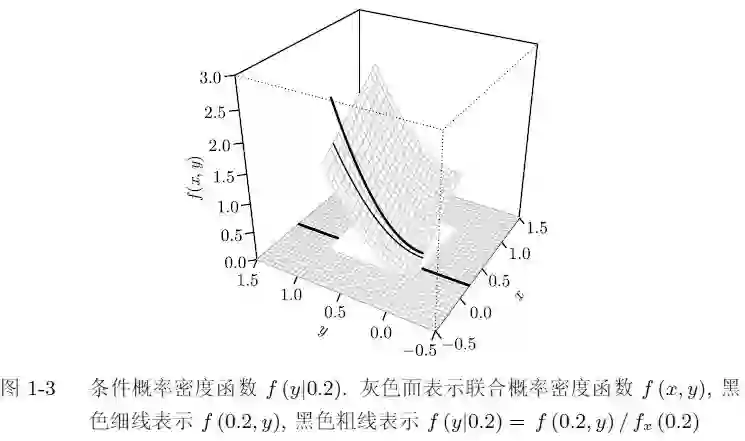
1.4.2条件分布
假设已知 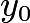


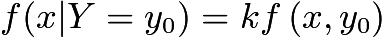
其中 
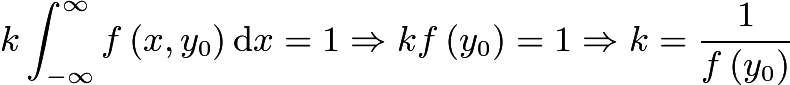
其中 

定义 如果

假设 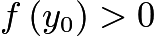
注意,当 

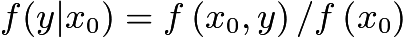
在统计学中,常常利用 
1.4.3 贝叶斯定理
从上一小节可知
重组上式的后两项可以得到
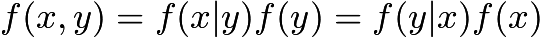
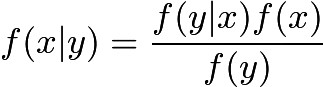
这个重要的结论叫作贝叶斯定理,在该定理的基础上形成了一个完整的统计学模型体系,见第 2 章和第 6 章. (1.1~1.4节完)



