Gartner 预测,到 2023 年,超过 33% 的大型机构将采用智能决策的实践。无论公共服务、企业经营还是个人生活,智能决策已经渗透越来越多的行业,赋能越来越多的场景,改变我们生产生活的方方面面。但以 AlphaGo 为代表的 AI 智能决策技术,在现实世界落地过程中仍面临着诸多挑战,也是学术界、工业界最为关心和关注的领域之一。
人是如何做决策的?科学研究表明人在决策之前往往会预演一遍可能发生的情况。以下围棋为例,我们通常会说高手算的很快,这里的 “算” 其实就是对可能发生情况的预演。同样地,模拟也是让计算机学会如何决策最为重要的前提。2016 年 AlphaGo 能击败李世石的基石其实有两个,一方面是基于强化学习的智能决策算法,另一方面是对围棋行棋局面的高效推演。
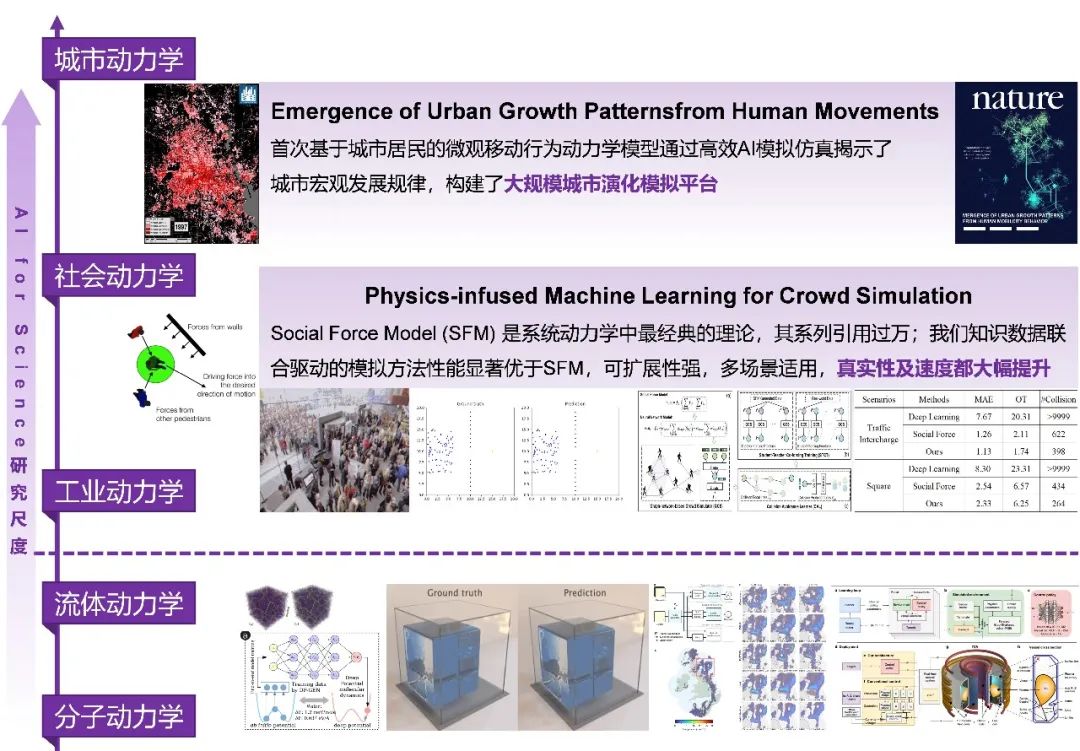
继 AlphaGo 之后,智能模拟(AI Simulation)或模拟智能(Simulation Intelligence)已经成为当今学术界和工业界共同关注的最为火热的方向之一。DeepMind 在分子结构模拟、核聚变控制等领域在 Nature 上频频发表重磅级文章;世界上最顶尖的十大超级计算机中,九台都在运行模拟相关的任务。来自图灵研究院、牛津大学、纽约大学、英伟达、英特尔等行业专家在其联合发表的最新大作中总结到,模拟智能已经成为促进科学和社会发展的新一代方法。
与游戏原生于数字世界不同的是,在现实世界中落地决策智能面临诸多难题,其核心是模拟的效率和真实性问题。传统的模拟方法主要依赖于既定公式的计算和推演,效率低,真实性差,模拟少量水分子的运动就会耗费巨量的计算资源,更不用谈模拟人、城市和社会。
为了解决这些问题,智能模拟应运而生。智能模拟,即充分发挥人工智能的优势来解决现有模拟方法的痛点。譬如,DeepMind 提出用神经网络替代解方程的模拟过程,直接预测得到模拟结果,极大加速了模拟过程。清华大学电子系城市科学与计算中心进一步提出知识数据协同驱动的模拟方法,即让 AI 模型学习已有的公式等专家知识的同时,也让其从海量数据中提取模拟对象的信息,二者结合,优势互补,实现高效而逼真的模拟,突破工业落地的红线。
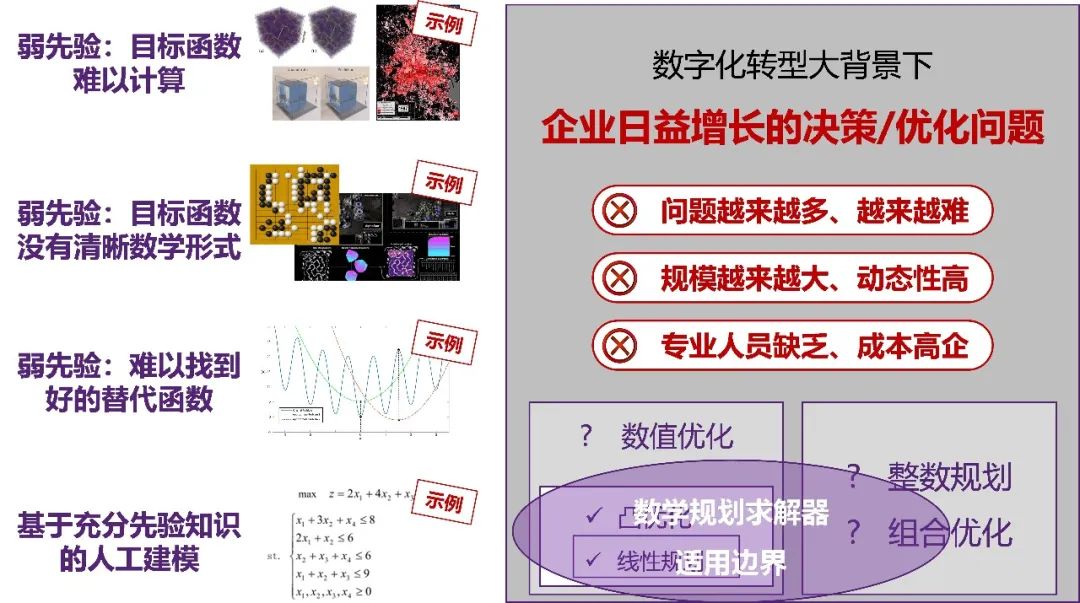
智能决策与智能模拟并驾齐驱,其相关技术在近几年内得到了前所未有的发展。决策是我们日常生产生活中所面对的最为普遍的问题,从公共服务、企业经营到个人生活,决策渗透各行各业,很多场景的本质都可以归纳为优化问题。传统的决策优化算法研究成果多来自于运筹学、应用数学等多个学科,采用数学建模、启发式搜索等方法,构造特定的解搜索策略,从而在庞大的解空间当中不断搜索出较优者,以此做到优化求解。然而,这一类方法往往依赖于具体问题或者具体场景中的信息,因此只能 “具体问题具体分析” 无法通用,导致研发成本较高,质量与效率也无法得到保证。
为解决这些问题,前沿研究提出了一个新兴的研究方向 —— 学习优化(Learn to Optimize),亦即智能决策。其核心思想是从数据出发,让深度(强化)学习模型从数据中学习决策的经验规律,并利用模拟器不断验证当前所学的正确性和完备性,实现数据 - 模型的优化闭环,最终输出优化决策的结果。相较传统方法,基于数据的模型往往能大幅加速甚至替代传统的搜索过程。除了速度提升外,为进一步提升模型的求解质量,有学者进一步提出将深度学习与传统运筹学、数学建模等方法相融合。这类方法得到了广泛关注,譬如,Google 用机器学习设计芯片,DeepMind 融合监督学习与分支界定法加速求解混合整数规划问题,Meta AI 融合强化学习与启发式方法求解组合优化问题等。
当然,智能决策的进一步发展仍然面临着许多开放的学术问题,包括求解过程的安全性和鲁棒性、针对不同决策问题的通用性和泛化性、大规模、高动态、多目标、以及多智能体决策场景的适应性等。针对这些问题的进一步研究也将帮助决策智能在更多实际场景落地迈出关键一步。
第二届 AI 模拟与智能决策论坛将于 7 月 2 日上午举行
,诠释决策智能新范式。为什么 AI 能让决策更智能?如何让 AI 帮助我们实现更智能的决策?这不仅是现代科技发展的前沿,更是当下社会现代化治理和企业数智化转型过程的关键举措和必由之路。
![]()
为此,清华大学电子工程系主办,清华大学电子工程系城市科学与计算研究中心承办、北京清鹏智能科技有限公司协办,多家科技前沿媒体支持的第二届 “AI 模拟与智能决策” 论坛将于 7 月 2 日上午举行。论坛汇聚全球顶尖专家学者、知名企业与创业公司负责人,共同探讨如何推动智能模拟与决策领域的前沿问题,推动科学与技术的快速发展,促进相关领域的创新与实践落地。
![]()
Dr. Zhiguang Cao is currently a Scientist at Singapore Institute of Manufacturing Technology (SIMTech), Agency for Science Technology and Research (A*STAR). Previously he was a Research Assistant Processor in Department of Industrial Systems Engineering and Management, National University of Singapore (NUS). In recent years, his research interests focus on Learning to Optimize, where he exploited deep (reinforcement) learning to solve Combinatorial Optimization Problems, such as Vehicle Routing Problem, Job Shop Scheduling Problem, Bin Packing Problem and Integer Programs. It is a hot yet challenging topic in both AI and OR. His works under this topic are published in NeurIPS, ICLR, AAAI, IJCAI and IEEE Trans, and the code is available at:
相关链接:https://zhiguangcaosg.github.io/publications/
分享主题:Learning to Solve Vehicle Routing Problems
Vehicle routing problem (VRP) is the most widely studied problem in operations research (OR), which is always solved using heuristics with hand-crafted rules. In recent years, there is a growing trend towards exploiting deep (reinforcement) learning to automatically discover a heuristic or rule for solving VRPs. In this talk, I will first briefly introduce the construction type of neural methods, followed by the elaboration of improvement type. Then, I will present the challenges in this area and my personal thoughts on them.
Dr. Zhenhui (Jessie) Li is the chief scientist at Yunqi Academy of Engineering, a non-profit organization for technological innovation. Her research has been dedicated to innovating spatial-temporal data mining techniques to address real-world problems in cities, environment, and society. Dr. Li obtained her PhD in computer science from University of Illinois at Urbana-Champaign and was a tenured associate professor at the Pennsylvania State University.
分享主题:Open data research toward a science of cities
Research paradigm is shifting. We are now at the exciting beginning of data-driven research paradigm. However, we often over-emphasize the methodologies and theories but data itself is understated. In this talk, I revisit some classical city science theories with open data. I would like to elaborate how open data play a critical role in defining science.
Dr. Yin received his Ph.D. in OR from Columbia University in 2006. Before joining Alibaba US and starting to lead the Decision Intelligence Lab in 2019, he was a Professor in the Department of Mathematics at University of California, Los Angeles. Dr. Yin won the NSF CAREER award in 2008, an Alfred P. Sloan Research Fellowship in 2009, a Morningside Gold Medal in 2016, and the Damo Award and Egon Balas Award in 2021. Dr. Yin’s research interests include computational optimization and its applications in signal processing, machine learning, and other data science problems. Since 2018, he has been among the top 1% cited researchers by Clarivate Analytics.
分享主题:Learning to Optimize: Algorithmic Unfolding
Learning to optimize, or L2O, is a method of developing optimization algorithms and improving their performance through offline training. It has achieved significant success in deep learning acceleration, signal processing, inverse problems, and SAT and MIP problems. In this talk, after giving a short introduction to L2O methods, we will focus on Algorithmic Unrolling or AU, an L2O methodology that has evolved quickly over the past 10 years. Early AUs imitate DNNs, so they have a large number of free parameters, which were expensive to train and hard to generalize. Recent AU methods have significantly reduced the number of parameters, in some cases to only a few. By examing the algorithms generated by L2O, we can obtain extremely high-performance, almost universal algorithms that no longer need training. This lecture will overview the sparse coding problem and its LISTA-series methods.
郝建业博士,天津大学智算学部副教授,华为诺亚决策推理实验室主任。主要研究方向为深度强化学习、多智能体系统。发表人工智能领域国际会议和期刊论文 100 余篇。主持参与国家基金委、科技部、天津市人工智能重大等科研项目 10 余项,研究成果荣获 ASE2019、CoRL2020 等最佳论文奖,以及 NeurIPS20-21 黑盒优化比赛 BBO、MineRL、求解器黑盒优化等冠军。相关成果在游戏 AI、广告及推荐、自动驾驶、网络优化、物流调度等领域落地应用。
近年来,强化学习的研究取得了很大进展,但仍存在采样效率和可泛化性等问题,这极大地限制了其在实际应用场景中的广泛应用。强化学习的主要瓶颈在于对环境和策略的表征能力有限。在本次报告中,我将介绍如何利用自监督技术,从状态、策略、动作、环境 / 任务等不同视角提高强化学习的表征能力入手,最终提高学习效率和跨不同场景任务的可扩展性和泛化性,最后介绍基于自监督强化学习的 “决策大模型” 未来演进之路。
直播预约
直播间:关注机动组视频号预约直播,北京时间7月2日9:00开播。