香港中文大学高一帆博士:会话式机器阅读理解
会话式机器阅读理解是什么?
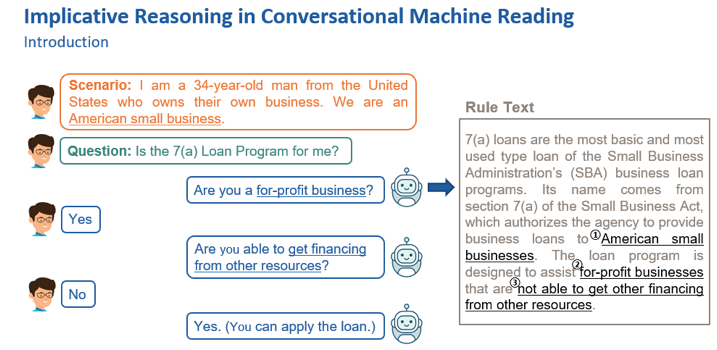
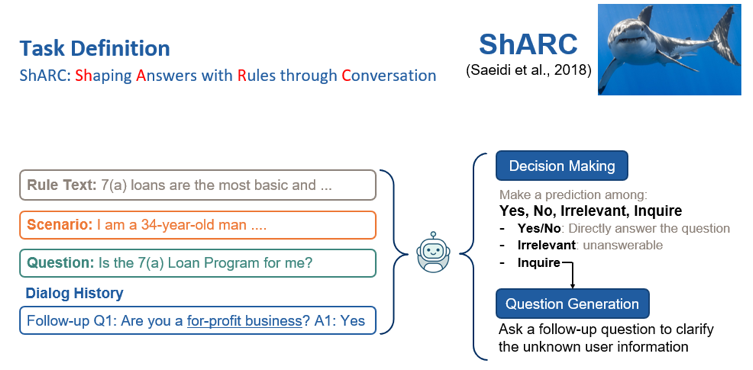
会话式机器阅读理解的初探

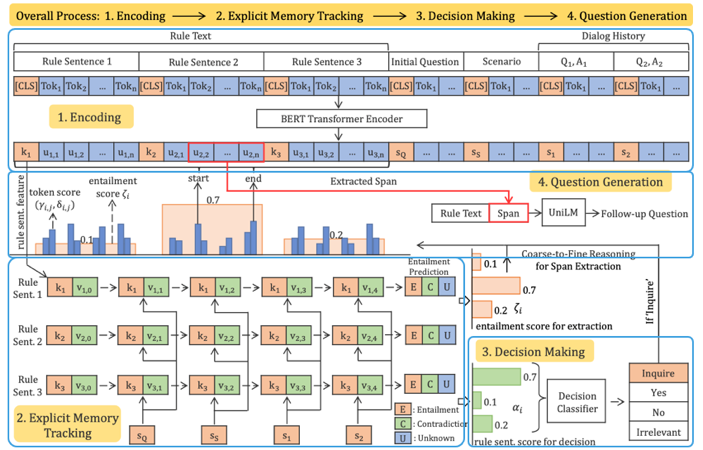
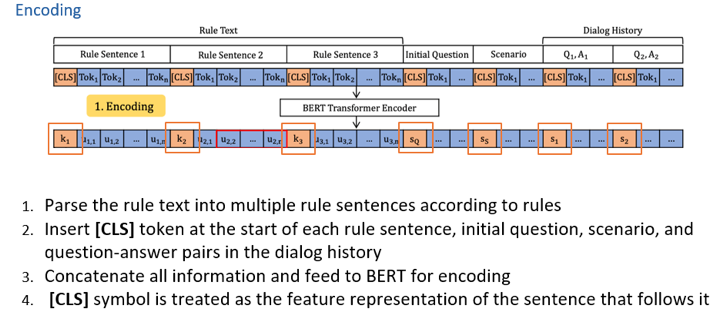
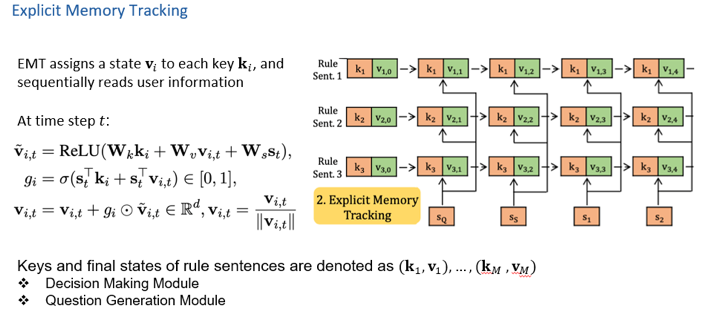
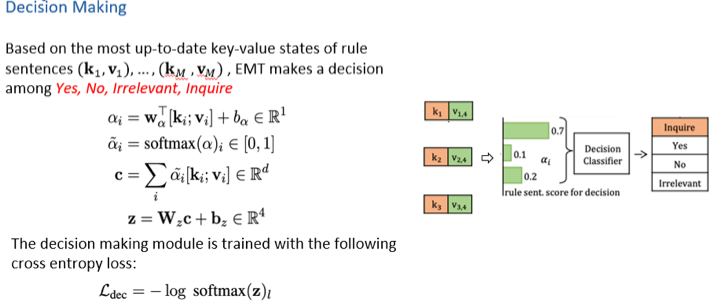


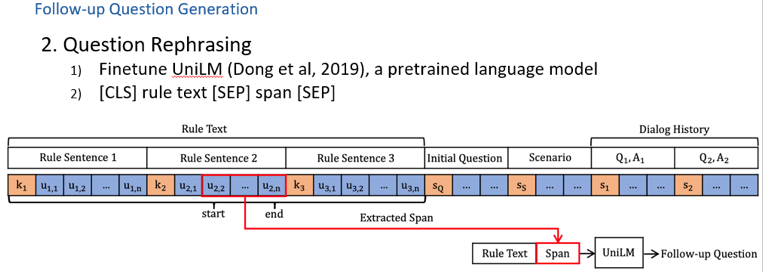
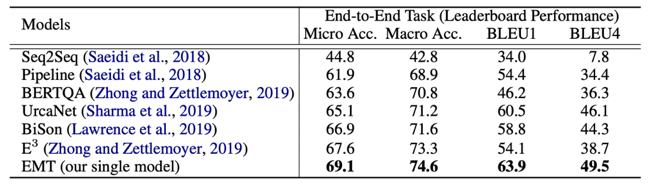
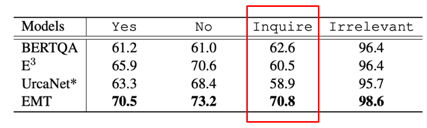
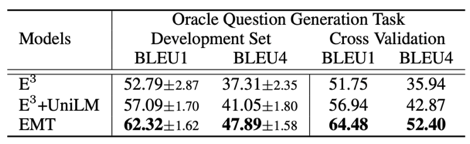
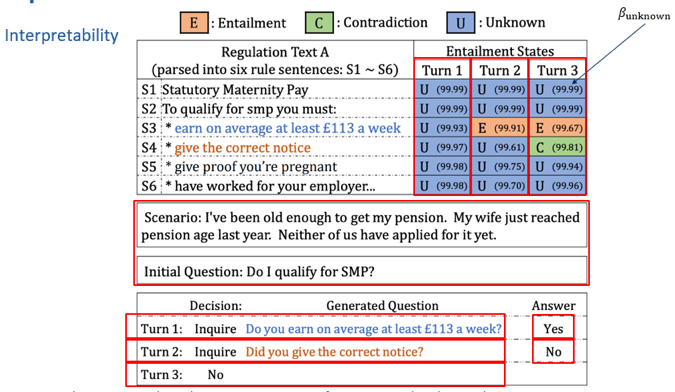
如何更好地进行会话式机器阅读理解

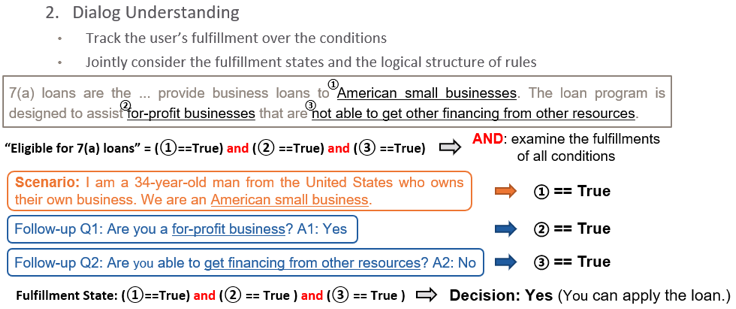
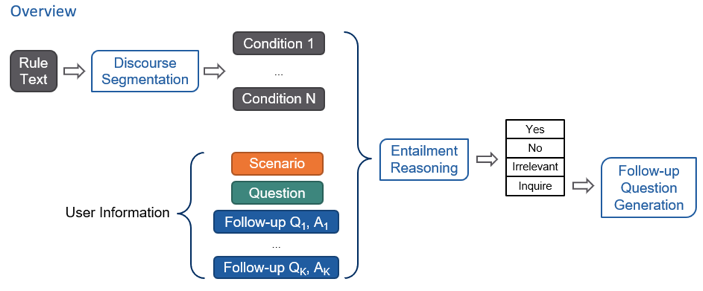

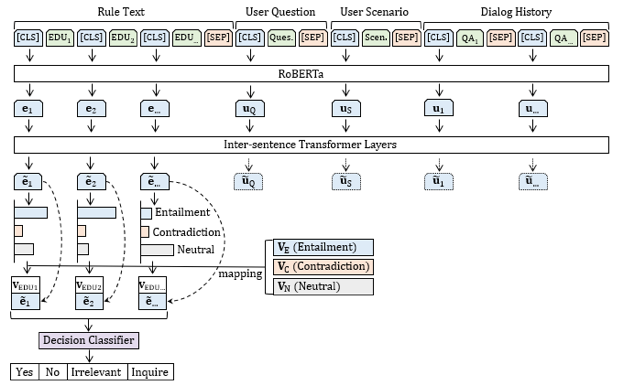
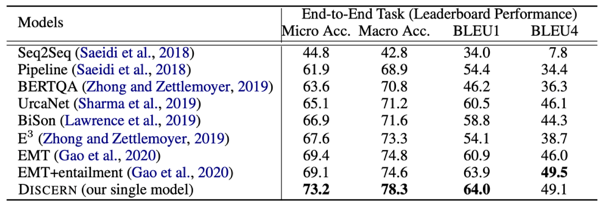
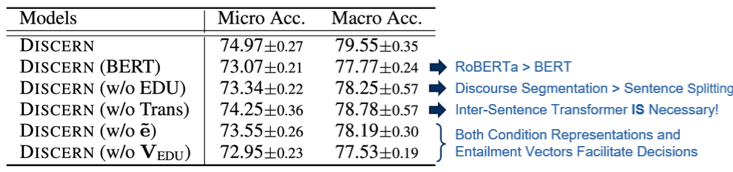

总结



登录查看更多
相关内容

Arxiv
12+阅读 · 2020年12月14日
Arxiv
3+阅读 · 2019年1月31日



相关VIP内容
相关资讯
相关论文
Arxiv
12+阅读 · 2020年12月14日
Arxiv
3+阅读 · 2019年1月31日