NeurIPS 2020 | 清华大学提出:通用、高效的神经网络自适应推理框架
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:rainforest wang
https://zhuanlan.zhihu.com/p/266306870
本文已由原作者授权,不得擅自二次转载
本文主要介绍我们被NeurIPS 2020会议录用的一篇文章:Glance and Focus: a Dynamic Approach to Reducing Spatial Redundancy in Image Classification。

论文:https://arxiv.org/abs/2010.05300
代码和预训练模型已经在Github上面放出:
https://github.com/blackfeather-wang/GFNet-Pytorch
这项工作提出了一个通用于绝大多数CNN的自适应推理框架,其效果比较明显,在同等精度的条件下,将MobileNetV3的平均推理速度加快了30%,将ResNet/DenseNet加速了3倍以上,且在iPhone XS Max上的实际测速和理论结果高度吻合。此外,它的计算开销可以简单地动态在线调整,无需额外训练。
(太长不看版)下面一张图可以概括我们做的事情:将图像识别建模为序列决策过程,先将缩略图输入神经网络(Glance),再不断选择最关键的图像区域进行处理(Focus,利用强化学习实现),直至网络产生一个足够可信的预测结果时停止;对于简单和困难的样本分配不同的计算资源,以提升整体效率。
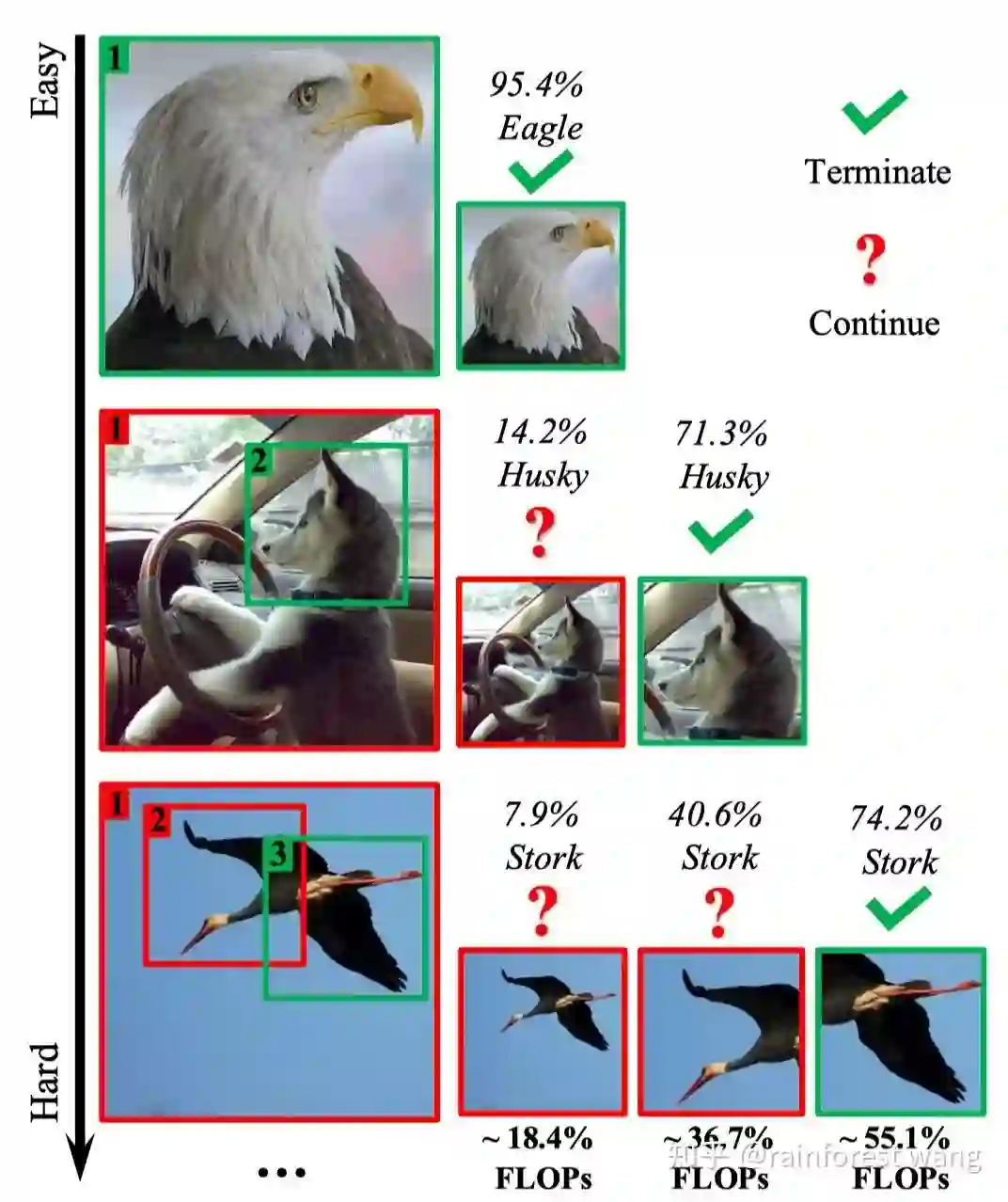
下面,我将详细介绍这一工作的具体内容。
1. Introduction (研究动机及简介)
在基于卷积神经网络(CNN)的图像任务中,提升网络效果的一个有效方法是使用高分辨率的输入,例如,在ImageNet分类[1]任务上,近年来的最新网络(DenseNet[2], SENet[3], EfficientNet[4])往往需要使用224x224或更大的输入图片以取得最佳性能:
| Model | Input Size | Accuracy |
|---|---|---|
| DenseNet-265 | 224x224 | 77.85 % |
| SENet-154 | 320x320 | 82.72 % |
| EfficientNet-B7 | 600x600 | 84.40 % |
然而,这种方式会带来较大的计算开销,因为推理CNN所需的计算量(FLOPs)基本与像素数目成正比[5],即与图形的长、宽成二次关系,如下图所示:
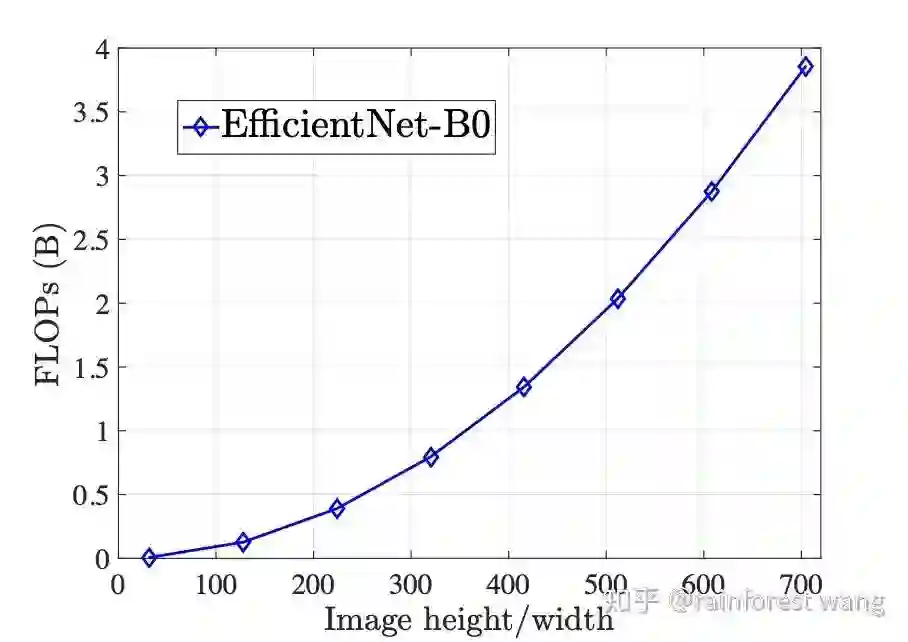
在实际应用(例如手机APP、自动驾驶系统、图片搜索引擎)中,计算量往往正比于能耗或者时间开销,显然,无论出于成本因素还是从安全性和用户体验的角度考虑,网络的计算开销都应当尽可能小。那么,如何在保留高分辨率输入所带来的好处的同时,减小其计算开销呢?
事实上,我们可以借助神经网络的一个有趣的性质。与人类视觉相似,神经网络往往可以通过仅仅处理图像中与任务相关的一小部分区域而得到正确的结果,例如在下图中,遮挡住屋顶、飞鸟或花朵之外的部分,神经网络仍然可以得到正确的分类结果[6]:

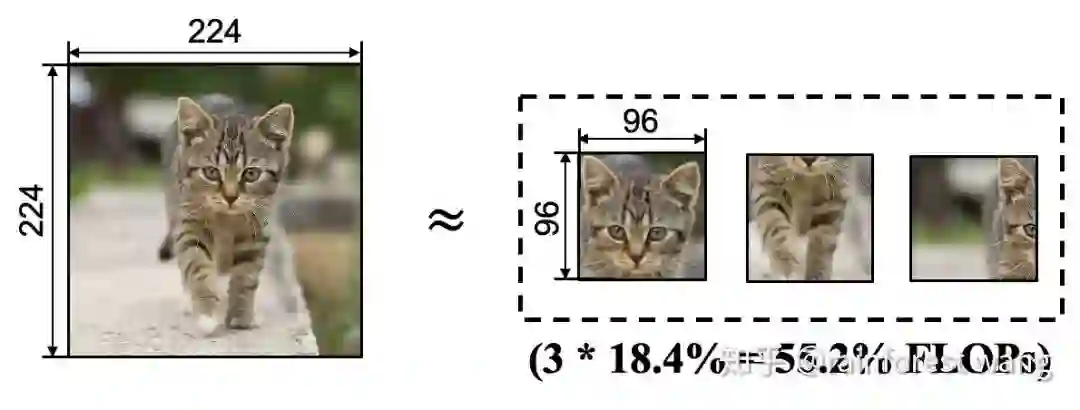
这便是本文所提出方法的出发点,我们的目标是,对于输入图片,自适应地找到其与任务最相关的区域,进而通过使神经网络只处理这些区域,以尽可能小的计算量得到可信的结果。具体而言,我们采用的方法是,将一张分辨率较高的图片表征为若干个包含其关键部分的“小块”(Patch),而后仅将这些小块输入神经网络。以下面的示意图为例,将一张224x224的图片分解为3个96x96的Patch进行处理所需的计算量仅为原图的55.2%。
2. Method (方法详述)
为了实现上述目的,事实上,有两个显然的困难:
(a) 任意给定一张输入图片,如何判断其与任务最相关的区域在哪里呢?
(b) 考虑到我们的最终目的是使神经网络得到正确的预测结果,不同输入所需的计算量是不一样的,例如对于下面所示的两个输入图片,神经网络可能仅需要处理一个patch就能识别出特征非常突出的月亮,但是需要处理更多的patch才能分辨出猫咪的具体品种。

为了解决这两个问题,我们设计了一个Glance and Focus的框架,将这一思路建模为了一个序列决策过程,如下图所示。
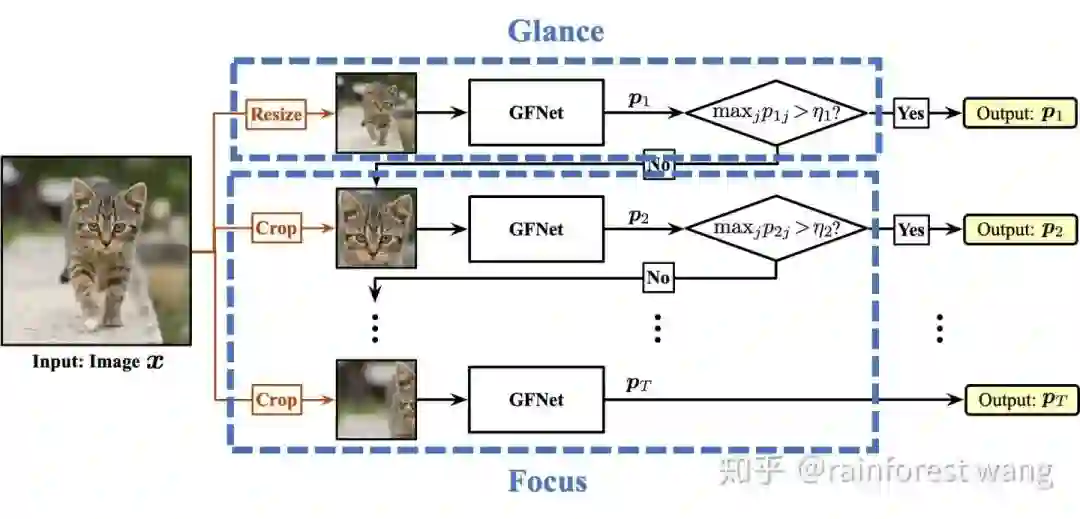
其具体执行流程为:
首先,对于一张任意给定的输入图片,由于我们没有任何关于它的先验知识,我们直接将其放缩为一个patch的大小,输入网络,这一方面产生了一个初步的判断结果,另一方面也提供了原始输入图片的空间分布信息;这一阶段称为扫视(Glance)。
而后,我们再以这些基本的空间分布信息为基础,逐步从原图上取得高分辨率的patch,将其不断输入网络,以此逐步更新预测结果和空间分布信息,得到更为准确的判断,并逐步寻找神经网络尚未见到过的关键区域;这一阶段称为关注(Focus)。
值得注意的是,在上述序列过程的每一步结束之后,我们会将神经网络的预测自信度(confidence)与一个预先定义的阈值进行比较,一旦confidence超过阈值,我们便视为网络已经得到了可信的结果,这一过程立即终止。此机制称为自适应推理(Adaptive Inference)。通过这种机制,我们一方面可以使不同难易度的样本具有不同的序列长度,从而动态分配计算量、提高整体效率;另一方面可以简单地通过改变阈值调整网络的整体计算开销,而不需要重新训练网络,这使得我们的模型可以动态地以最小的计算开销达到所需的性能,或者实时最大化地利用所有可用的计算资源以提升模型表现。
关于这些阈值的具体整定方法,由于比较繁杂,不在这里赘述,可以参阅我们的paper~
3. Network Architecture (网络结构)
下面我们具体介绍Glance and Focus Network (GFNet) 的具体结构,如下图所示
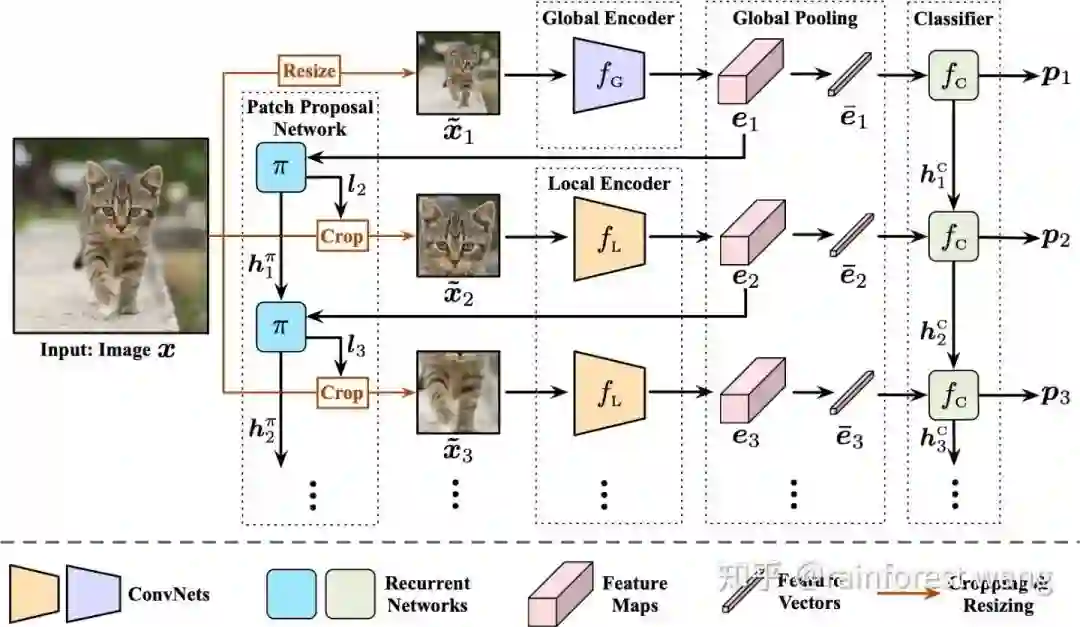
GFNet共有四个组件,分别为:
全局编码器
和局部编码器
(Global Encoder and Local Encoder)为两个CNN,分别用于从放缩后的原图和局部patch中提取信息,之所以用两个CNN,是因为我们发现一个CNN很难同时适应缩略图和局部patch两种尺度(scale)的输入。几乎所有现有的网络结构均可以作为这两个编码器以提升其推理效率(如MobileNet-V3、EfficientNet、RegNet等)。
分类器
(Classifier)为一个循环神经网络(RNN),输入为全局池化后的特征向量,用于整合过去所有输入的信息,以得到目前最优的分类结果。
图像块选择网络
(Patch Proposal Network)是另一个循环神经网络(RNN),输入为全局池化前的特征图(不做池化是为了避免损失空间信息),用于整合目前为止所有的空间分布信息,并决定下一个patch的位置。值得注意的是由于取得patch的crop操作不可求导,
是使用强化学习中的策略梯度方法(policy gradient)训练的。
 和局部编码器
和局部编码器 (Global Encoder and Local Encoder)为两个CNN,分别用于从放缩后的原图和局部patch中提取信息,之所以用两个CNN,是因为我们发现一个CNN很难同时适应缩略图和局部patch两种尺度(scale)的输入。几乎所有现有的网络结构均可以作为这两个编码器以提升其推理效率(如MobileNet-V3、EfficientNet、RegNet等)。
(Global Encoder and Local Encoder)为两个CNN,分别用于从放缩后的原图和局部patch中提取信息,之所以用两个CNN,是因为我们发现一个CNN很难同时适应缩略图和局部patch两种尺度(scale)的输入。几乎所有现有的网络结构均可以作为这两个编码器以提升其推理效率(如MobileNet-V3、EfficientNet、RegNet等)。 (Classifier)为一个循环神经网络(RNN),输入为全局池化后的特征向量,用于整合过去所有输入的信息,以得到目前最优的分类结果。
(Classifier)为一个循环神经网络(RNN),输入为全局池化后的特征向量,用于整合过去所有输入的信息,以得到目前最优的分类结果。 (Patch Proposal Network)是另一个循环神经网络(RNN),输入为全局池化前的特征图(不做池化是为了避免损失空间信息),用于整合目前为止所有的空间分布信息,并决定下一个patch的位置。值得注意的是由于取得patch的crop操作不可求导,
(Patch Proposal Network)是另一个循环神经网络(RNN),输入为全局池化前的特征图(不做池化是为了避免损失空间信息),用于整合目前为止所有的空间分布信息,并决定下一个patch的位置。值得注意的是由于取得patch的crop操作不可求导,4. Training (训练方法)
为了确保GFNet的四个组件按照我们预期的方式工作,我们提出了一个三阶段的训练策略,在这里简要概述,更多细节可以参见我们的paper~
首先,我们从GFNet中移除
,在每一步均以均匀分布随机选择patch的位置,以下面所示的损失函数训练
,
和
,使其达到最佳的分类性能,其中
代表交叉熵损失,
和
分别代表
在第
步的预测结果和原始输入图片
对应的标签,
表示训练集,
表示序列的最大可能长度。
 代表交叉熵损失,
代表交叉熵损失,  和
和  分别代表
分别代表 步的预测结果和原始输入图片
步的预测结果和原始输入图片  对应的标签,
对应的标签,  表示训练集,
表示训练集,  表示序列的最大可能长度。
表示序列的最大可能长度。
而后,我们固定第一步得到的
,
和
,在网络中插入一个随机初始化的
,以强化学习算法(policy gradient)优化以下形式的折扣奖励函数。其中
为一个预先定义折扣因子,
为每次选择patch位置的奖励(reward),我们将其定义为所选择的patch所造成的在正确标签上的confidence的增量,换言之,我们总是希望
选择目前的网络没有处理过的、对产生正确的预测结果最有帮助的patch。
 为一个预先定义折扣因子,
为一个预先定义折扣因子, 为每次选择patch位置的奖励(reward),我们将其定义为所选择的patch所造成的在正确标签上的confidence的增量,换言之,我们总是希望
为每次选择patch位置的奖励(reward),我们将其定义为所选择的patch所造成的在正确标签上的confidence的增量,换言之,我们总是希望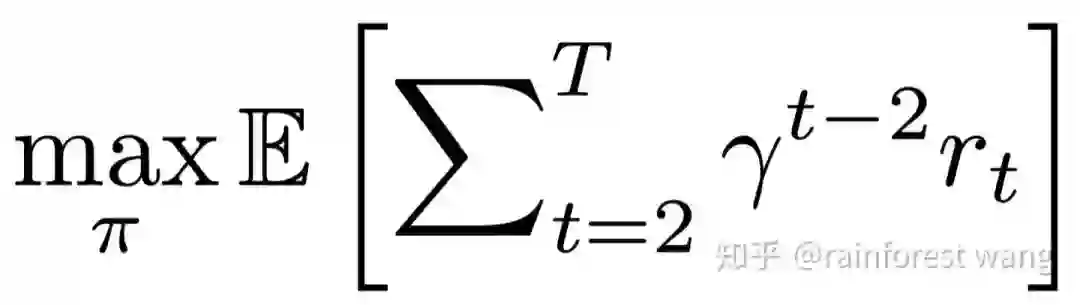
最后,我们固定第二步得到的
,再以第一步中的损失函数对
,
和
进行最终的微调(Finetune)。
5. Experiments (实验结果)
在实验中我们考虑了两种设置:
budgeted batch classification,测试数据伴随有一个计算开销的预算(budget),网络需要在这个计算预算内进行推理。在此设置下,我们使用前面提到的方法,确定阈值(confidence threshold)并进行自适应推理。
anytime prediction,网络有可能在任何时候被要求立刻输出预测结果。在此设置下,我们不使用自适应推理技术,并假设所有测试样本的序列长度固定。
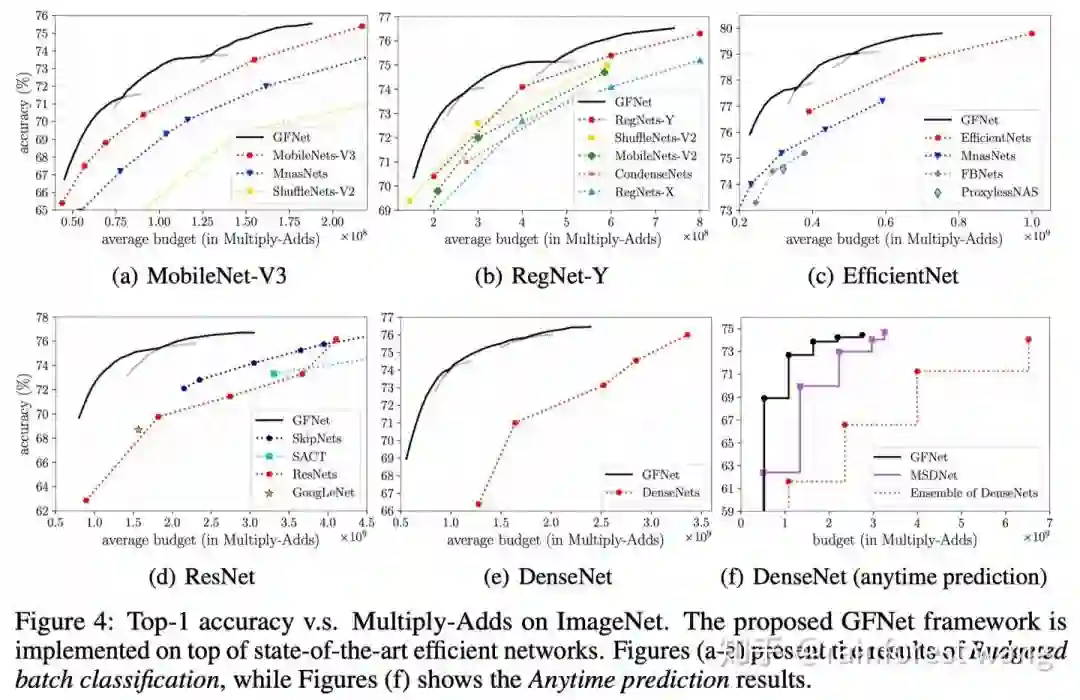
下图为我们在不同网络结构上实现GFNet的实验结果,其中横轴为网络的平均理论计算开销,纵轴为准确率,(a-e)为budgeted batch classification的结果,(f)为anytime prediction的结果。可以看出,GFNet明显地提升了包括MobileNetV3、RegNet和EfficientNet在内的最新网络结构的推理效率,同等精度下,计算开销减小达30-40%以上,对于ResNet/DenseNet的增幅可达3倍甚至更高;同等计算开销下,对MobileNetV3提点2%左右,对ResNet/DenseNet达5-10%以上。
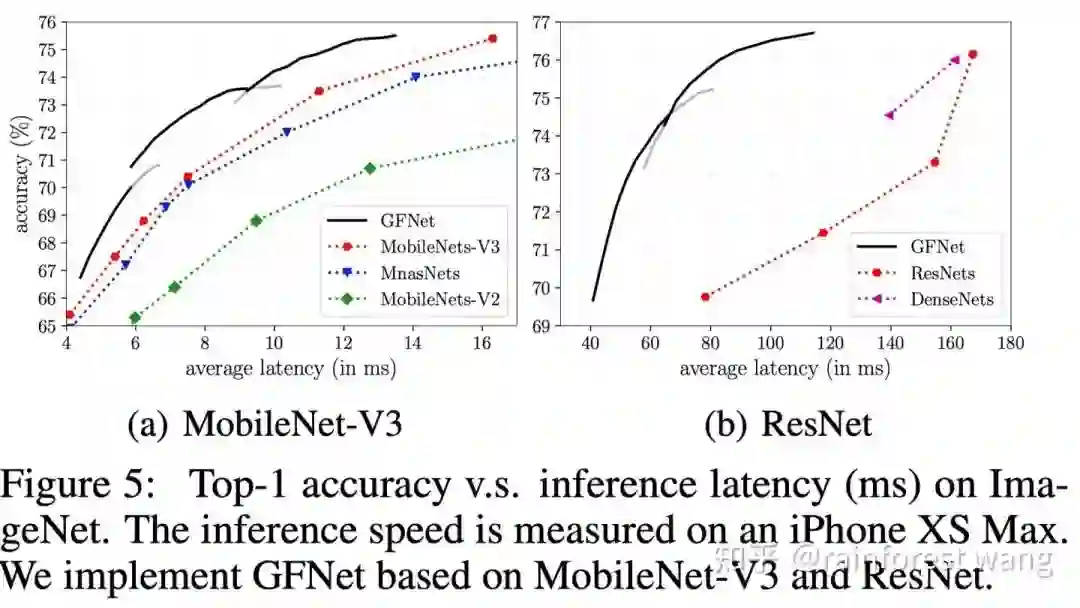
GFNet的另一个显著优势是,由于其没有更改CNN的具体结构,其可以方便地在移动端或边缘设备上使用现有的工具部署,且享有和理论结果几乎等同的实际加速比。下图为我们在一台iPhone XS Max(就是我的手机)上基于TensorFlow Lite的测试结果:
下面是GFNet的一些可视化结果,可以从中看出,对于比较简单的样本,GFNet可以仅在Glance阶段或Focus阶段的第一步以很高的confidence得到正确的结果,对于较为复杂的样本,则实现了以不断关注关键区域的形式逐步提升confidence。

6. Conclusion (结语)
最后总结一下,其实我本人是非常喜欢这项工作的,因为它非常的自然、通用、有效。一方面它很好的模拟了生物(或者说人)识别一张图片的过程,人眼对图像数据的认知事实上也是一个先扫视得出一些直觉信息、再逐渐关注关键区域的过程。另一方面GFNet的实际效果也非常显著,且能在目前最佳的一些模型上进一步提升理论计算效率,并加快实测速度。欢迎大家follow我们的工作~。
@inproceedings{NeurIPS2020_7866,
title = {Glance and Focus: a Dynamic Approach to Reducing Spatial Redundancy in Image Classification},
author = {Wang, Yulin and Lv, Kangchen and Huang, Rui and Song, Shiji and Yang, Le and Huang, Gao},
booktitle = {Advances in Neural Information Processing Systems (NeurIPS)},
year = {2020},
}如有任何问题,欢迎留言或者给我发邮件,附上我的主页链接
参考
^[1] http://www.image-net.org/
^[2] https://arxiv.org/pdf/2001.02394.pdf
^[3] https://arxiv.org/pdf/1709.01507.pdf
^[4] https://arxiv.org/pdf/1905.11946.pdf
^[5] https://papers.nips.cc/paper/5542-recurrent-models-of-visual-attention.pdf
^[6] https://arxiv.org/pdf/1910.08485.pdf
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。

下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2400+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!


