新加坡科技设计大学杨杰博士莅临我校,并做了报告:Recent Advances in Sequence Labeling

之前了解杨杰博士是从导师那里得知的,模模糊糊,当时也只是知道这个名字而已,谁知道几个月后自己竟然还能作为迎宾亲自去迎接。O(∩_∩)O哈哈~ 路上交流了很多,发现大牛都是这么谦虚,平易近人的吗?
好啦 步入正题,以下内容为事实和自己的部分理解。
Introduction(简单介绍序列标注任务)
Neural Sequence Labeling Models(回顾往年的序列标注模型)
Chinese Sequence Labeling Models(提出自己的模型)
Toolkits for Data Annotation and Neural Models(提出自己的两个工具包)

比如上述的例子,给一句话中的每个词进行标注,标注内容为X-Y。其中X为B(begin)或者I(insert),B表示开始,I表示跟前面的是一起的,这样表示一个完整的序列,单个词用B,多个词用B I I...。Y可以为ORG(organization),PER(person),当然也可以由LOC(local)等。
序列标注运用十分广泛!比如
Word Segmentation 分词
Part-of-speech(POS)tagging词性标注
Named Entity Recognition (NER)命名实体识别
Chunking, CCG Supertagging, etc





对于这方面的论文,做了一下总结:
`
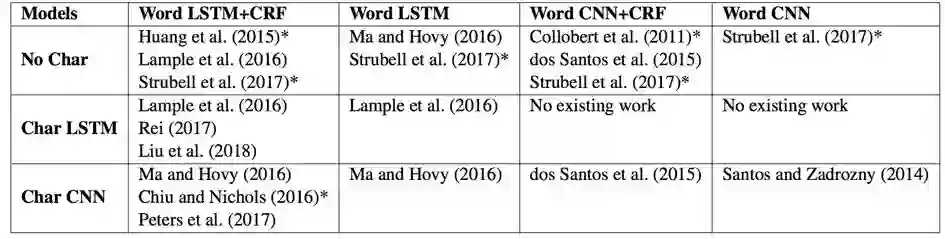
Training Improvement 训练的改进
Joint training with language model 联合训练
Training the sequence labeling with joint training the language model,Marek Rei, ACL 2017. Liyuan Liu, et, al. AAAI 2018
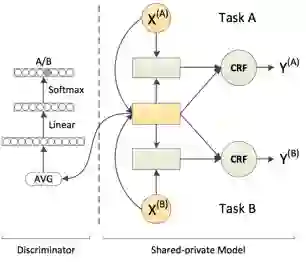
Adversarial training 对抗训练
Joint training models in multi-criteria datasets, using adversarial learning to integrate shared knowledge,Xinchi Chen et,al. ACL 2017.
Pre-training Improvement 预训练改进
Pretrain Word/Char Embeddings 预训练词 / 字 Embedding
Pretrain word/char embeddings using external information,Jie Yang et,al ACL 2017, Hao Zhou et, al EMNLP 2017.
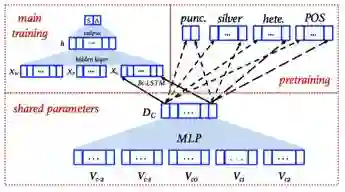
Pretrain LSTM (ELMo) 预训练LSTM
Pretrain bidirectional LSTM representation in a large-scale language model data. Peters, et, al NAACL 2018 (best paper)
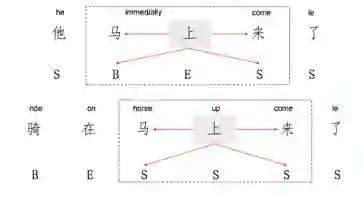
歧义



中文的基于字的效果要比词的效果好,这样不会因为词金标原本的错误导致最终训练效果的不佳,而如果基于字的话,就不会有这样的顾虑。
比如

会有歧义。
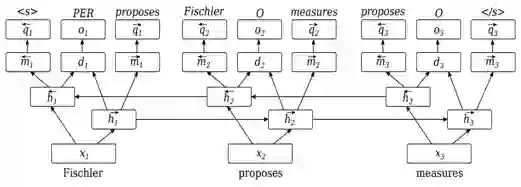
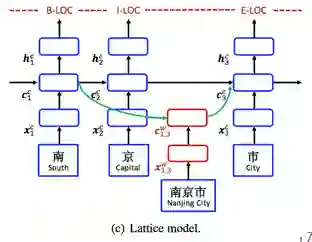
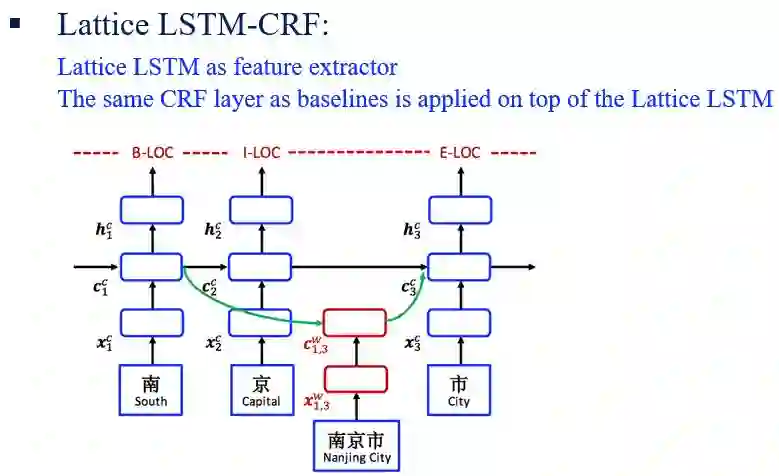
这样,引出了自己提出的新的模型 Lattice LSTM :
每一个路径连接一个可能性词的首尾
用之前的传统模型和自己的模型对对比
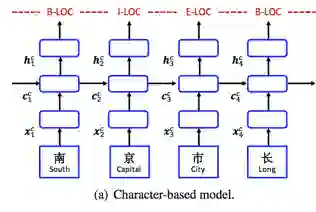
Character-based model
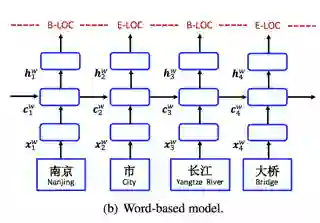
Word-based model
Lattice model
该模型是在Standard LSTM上改进的,先看看标准的模型们:
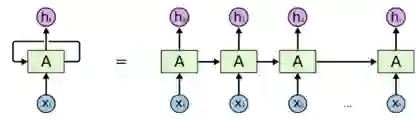
RNN
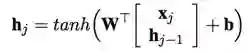
LSTM
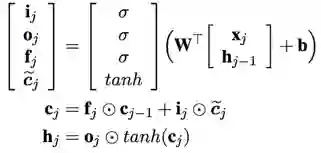

Coupled LSTM
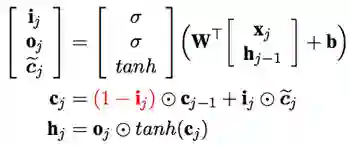

而该模型就是在Coupled LSTM上进行了稍微的修改

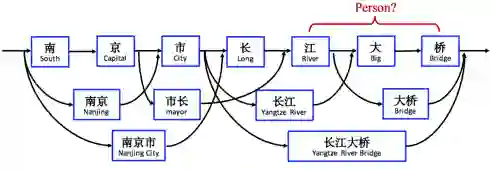
其中X^w_{b, e}是匹配词(比如这里的市长等)的embeddings
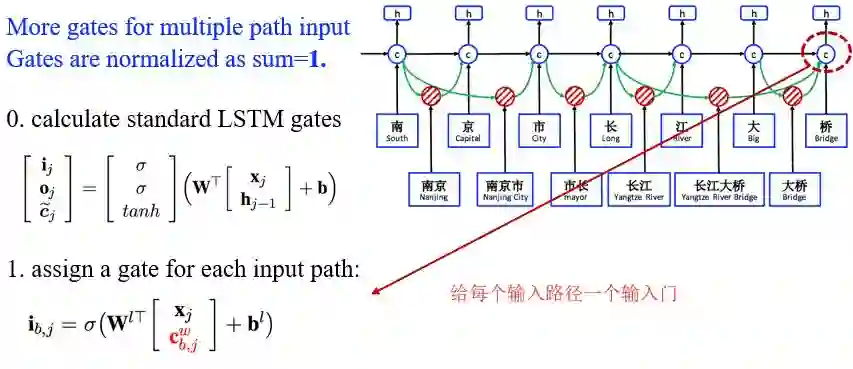
正则化所有的门
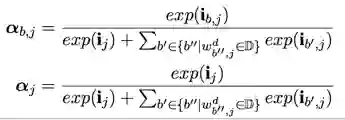
对所有路径加权和
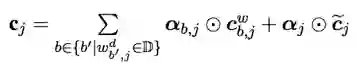
Standard LSTM 和 Lattice LSTM 对比

Lattice LSTM是coupled LSTM 的一种扩展,可以用于多路径输入。
Lattice LSTM 的优势
在句子中有很多信息的路径
有门控制多个路径的输入
字词序列之间建立关联
相似的词可以通过word embedding被利用起来
对于上述第四条,举个例子

比如左边是train语料,右边是test,我们都知道江泽民和胡锦涛是同一类型的词,其他的模型识别不出来右边的,但是Lattice LSTM可以。可以说有一定的泛化能力。
baselines:
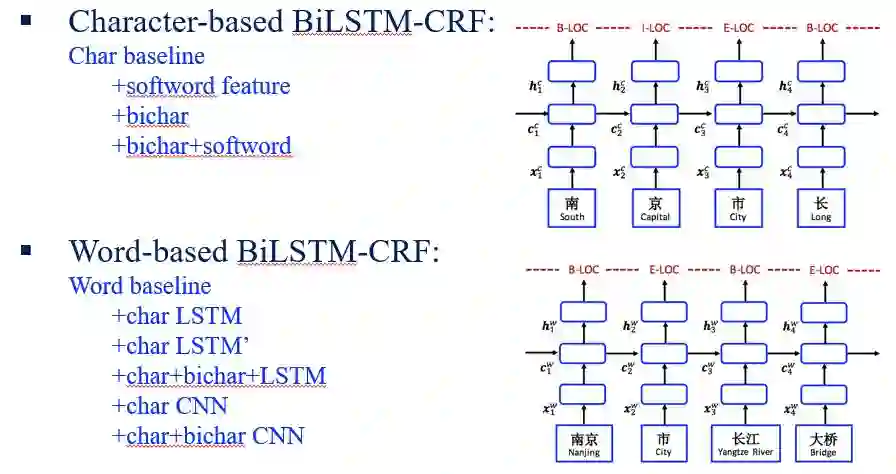
而Lattice LSTM CRF:
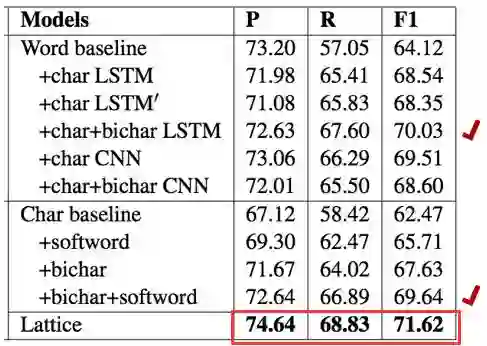
在最终的baseline对比数据中,发现Lattice LSTM模型是遥遥领先的
还做了进一步的一些实验
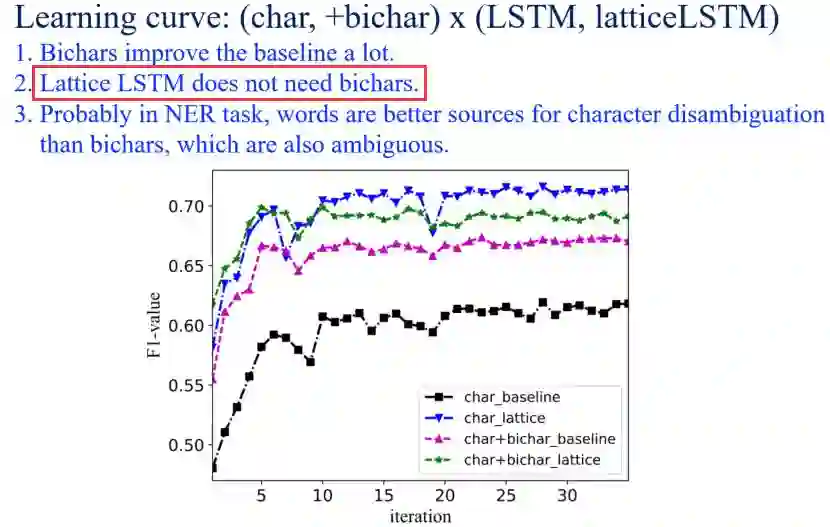
OneNotes NER 与金标分词做对比

MSRA NER 测试集中没有金标分词

微博或个人简历 NER 没有金标分词且数据小

具体案例分析
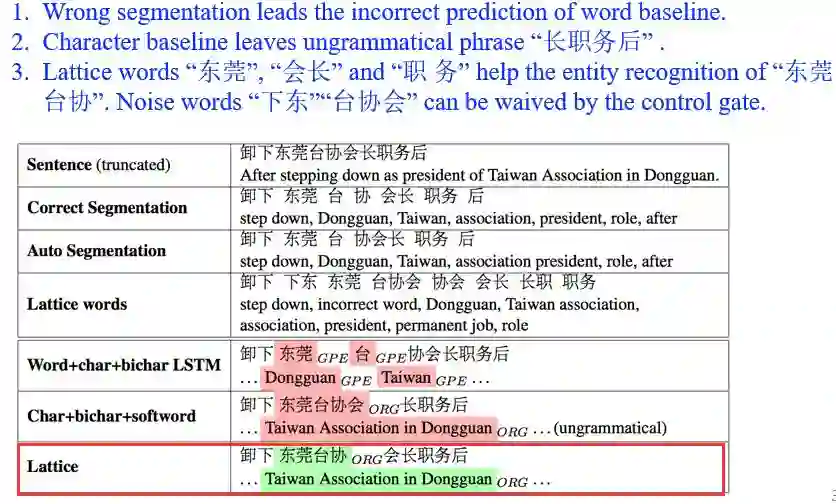
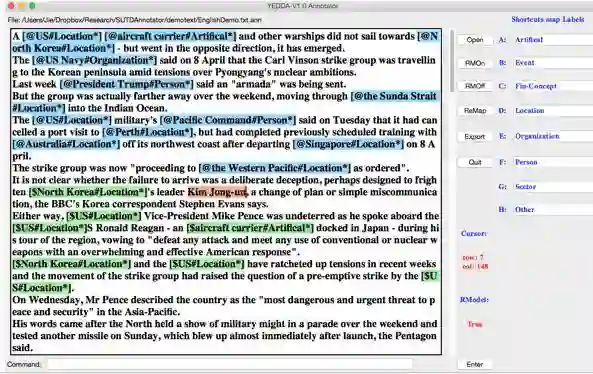
效率:在shortcut key上 比SOTA快2倍
智能:系统可以根据历史标注推荐注释
强大分析能力:从不同的标注pairs上生成一份diff 报告
ACL best demo nomination

github链接:https://github.com/jiesutd/YEDDA
2. NCRF++:神经网络序列标注(github 699 stars)
基本信息:
神经网络版本的CRF++,支持n-best 输出
不需要额外的code,只需要用config文件即可。
支持12个SOTA神经网络模型,支持任何神经网络特征
并行计算,在CoNLL NER 解码能达到大于2000句每秒

github 地址:https://github.com/jiesutd/NCRFpp



推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Attention Modeling for Targeted Sentiment
 欢迎关注交流
欢迎关注交流





