导读
由北京智源人工智能研究院主办的2019北京智源大会(BAAI2019)在国家会议中心开幕,会期两天(2019年10月31日–11月1日)。
华为诺亚方舟实验室语音语义首席科学家刘群发表《预训练语言模型的研究与应用》主题演讲,分享华为诺亚方舟实验室在预训练语言模型的研究和应用实践。
刘群表示,预训练语言模型本身就是神经网络语言模型,它有个很大的优点是使用大规模无标注纯文本语料进行训练。在预训练语言模型的应用上,华为推出了中文预训练语言模型“哪吒”;将实体知识融入BERT并开发了“ERNIE”;基于GPT模型的中国古诗词生成方法,推出“乐府”作诗机,在场同学立即玩起“乐府”来。
谈及未来,刘群表示他们将会研究更好、更强大的预训练语言模型,融入更多的知识,跟语音和图像结合后,希望能应用到更多领域。另外在模型压缩和优化方面的研究期待能在终端落地。目前他们和华为海思合作,把预训练语言模型在华为自己的芯片上实现。
![]()
https://slides.baai.ac.cn/2019/
刘群,男,华为诺亚方舟实验室,语音语义首席科学家,主导语音和自然语言处理领域的前沿研究和技术创新。1989 年毕业于中国科学技术大学计算机系,1992 年于中国科学院计算技术研究所获得硕士学位。刘群博士是自然语言处理和机器翻译领域的国际著名专家,他的研究方向包括多语言信息处理、机器翻译模型、方法与评价等。
![]()
![]()
预训练语言模型本身就是神经网络语言模型
,
它的特点
包括:
第一
,
可以使用大规模无标注纯文本语料进行训练
;
第二
,
可以用于各类下游NLP任务
,
不是针对某项定制的
,
但以后可用在下游NIP任务上
,
你不需要为下游任务专门设计一种神经网络
,
或者提供一种结构
,
直接在几种给定的固定框架中选择一种进行 fine-tune
,
就可以从而得到很好的结果
,
这是预训练模型特别厉害的一点
。
预训练语言模型有两个大类型
。
一类是Encoder
,
用于自然语言理解
,
输入整个文章
,
用于自然语言理解
;
另一类是Decoder
,
是解码式的
,
用于自然语言生成
,
只能来看到已经生成的内容
,
看不到没有生成的内容
,
这两类模型有所区别。
![]()
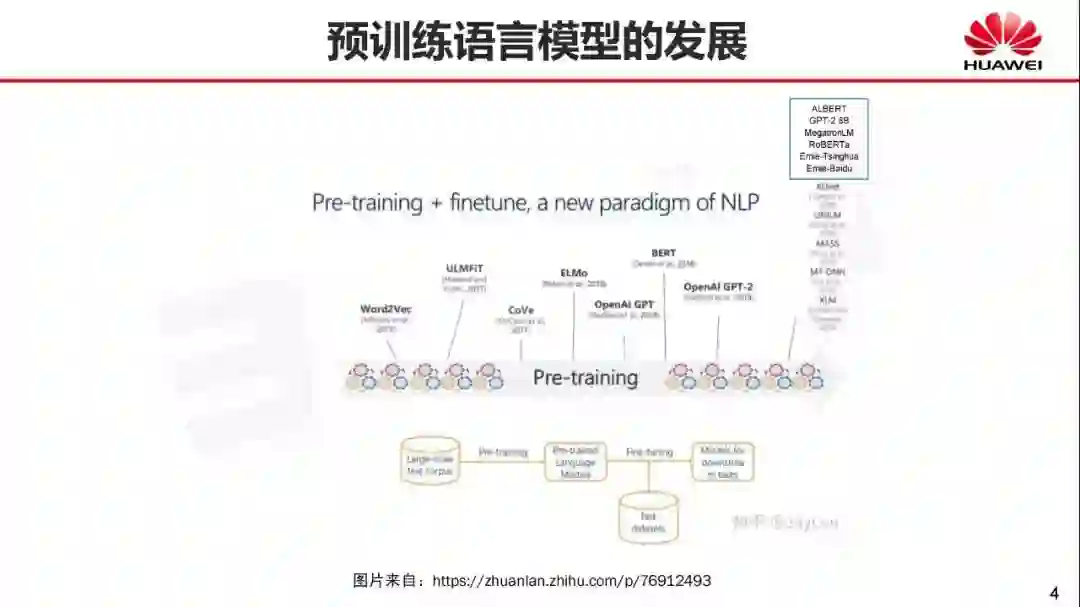
从上面的图中我们可以看出
,
近两年预训练模型的发展非常快
。
从很早的Word2Vec
、
之后ULMFiT
、
CoVe
、
Elmo
、
OpenAI GPT随之出现
,
最后影响最大的是Bert
,
BERT之后有OpenAI Gpt-2
。
后面我又补充了 GPT-2 8B
、
MegatronLM
、
RoBERTa
、
Ernie-Tsinghua
、
Ernie-Baidu
、
XLNet
、
UNILM
、
MASS
、
MT-DNN
、
XLM
,
最近有几个模型非常有意思
,
比如 Ernie
、
Roberta
,
然后是Megatronlm
,
做到了GPT-2 8EB。
![]()
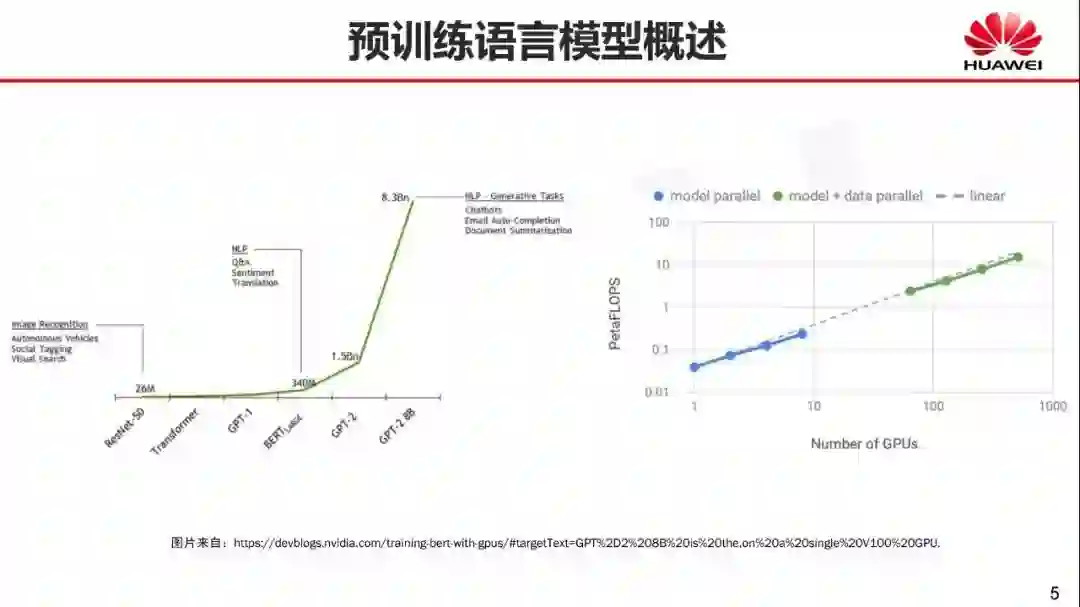
这是模型的参数大小
,
跟早期的 ResNet相比
(
视觉模型
)
,
我们看到GPT1 是 100M
,
BERT large是340M
,
GPT2是 1.5BN
,
GPT-2 8B是 8.3BN
。
再到计算量GPU的使用数量
,
可以看出大家都在拼数据
、
拼算力。
![]()
华为诺亚方舟实验室在预训练语言模型研究方面,内部重现了 Google Bert-base和Bert-large的实验;利用BERT的代码,实现了OpenAI GPT-2模型;实现基于GPU多卡多机并行训练,并且对训练过程进行了优化,提高了训练效率。
其次,对模型细节进行了多方面的改进。
这是尝试很多方法后得到的结果,我们拿出有效的部分。此外,我们还尝试了很多模型压缩优化方案。我们希望这些成果能真正部署在我们的产品上,特别是手机上。虽然华为做手机已经很好了,但是这种GPT模型太大了,想直接用在手机上还是做不到,我们尝试很多压缩的方法,现在还没有完全能够压缩到手机上,但是已经能够压缩比较小了。
![]()
在模型应用方面做了很多有意思的事情,预训练语言模型特别好,有很多应用。
![]()
哪吒,诺亚方舟实验室的中文预训练语言模型在哪吒模型中,我们有两个模型改进的工作,一是函数式相对位置编码,二是实现全词覆盖。
![]()
Ernie:实体表示增强的预训练语言模型,为语言理解注入外部知识
![]()
![]()
![]()
报告便捷下载:
请关注专知公众号(点击上方蓝色专知关注)
参考资料:
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!
请加专知小助手微信(扫一扫如下二维码添加),
获取专知VIP会员码
,加入专知人工智能主题群,咨询技术商务合作~