CVPR2020 Oral | 动态多尺度图表达3D人体骨架运动,实现精准预测效果超SOTA

新智元推荐
编辑:白峰
【新智元导读】上海交大、三菱电机实验室联合提出将人体骨架建模为一个可学习的多尺度图,并且对不同层次的特征,多尺度图呈现动态变化。通过学习综合的多尺度特征表达,DMGNN实现了更准确的未来运动预测,超越SOTA。

动态多尺度图建模3D人体骨架
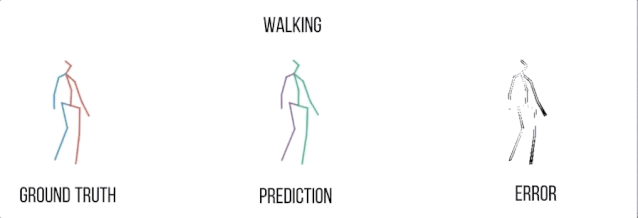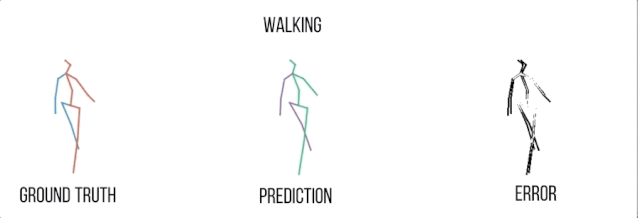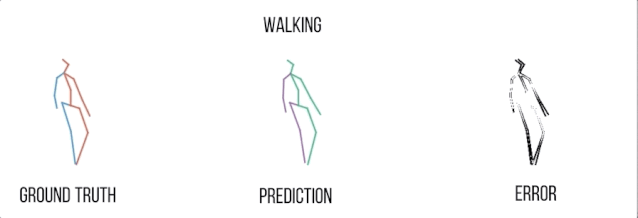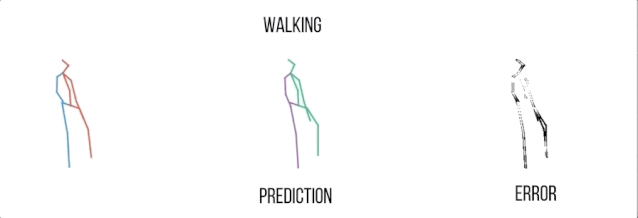
行走

拍照
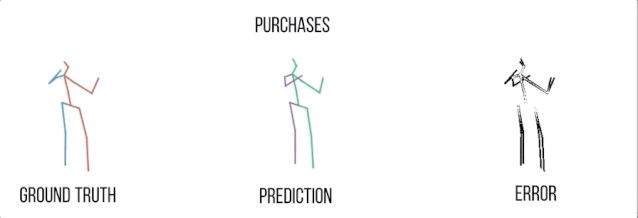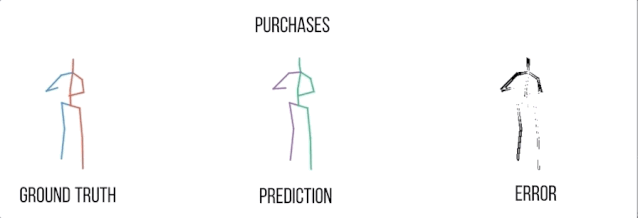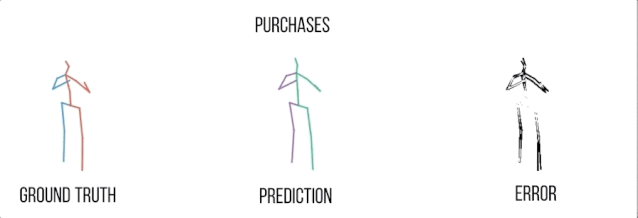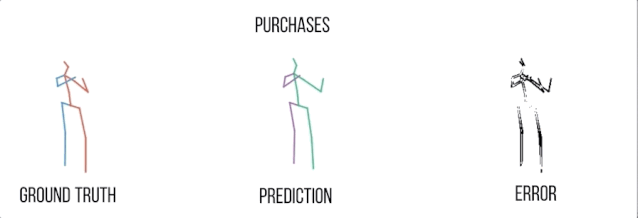
买东西
基于动态多尺度图的运动预测算法
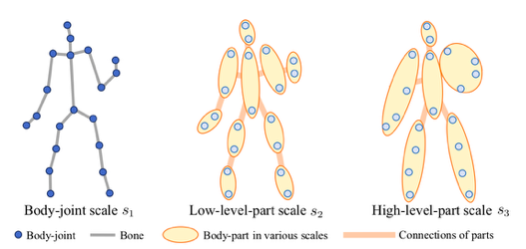
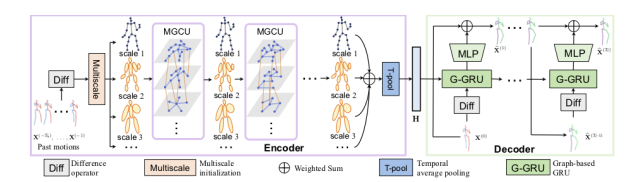
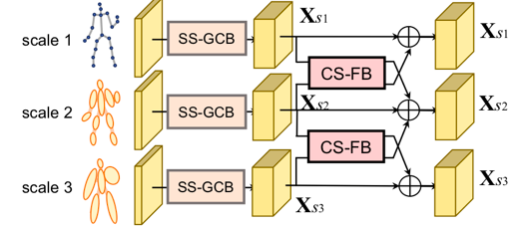
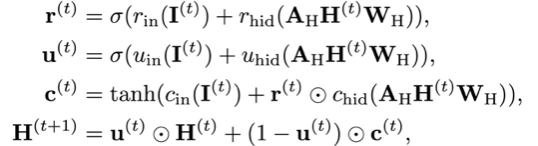
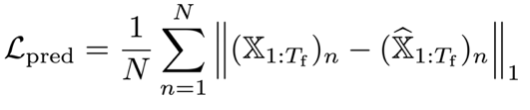
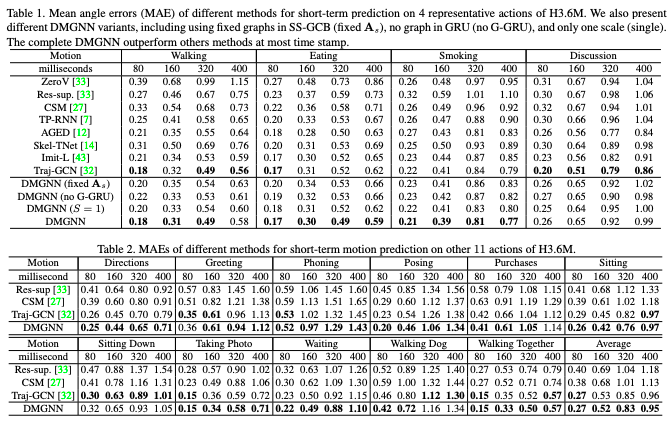
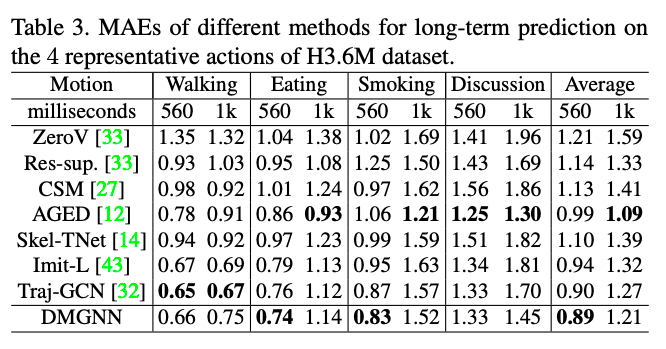
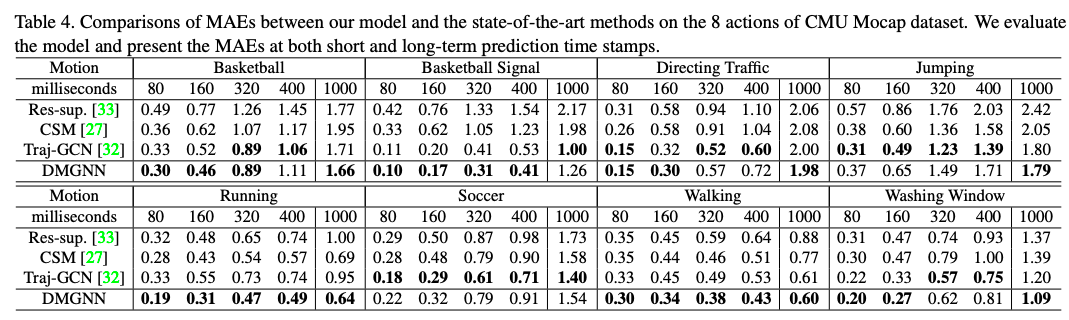
Human3.6M和CMU Mocap数据集验证效果超SOTA
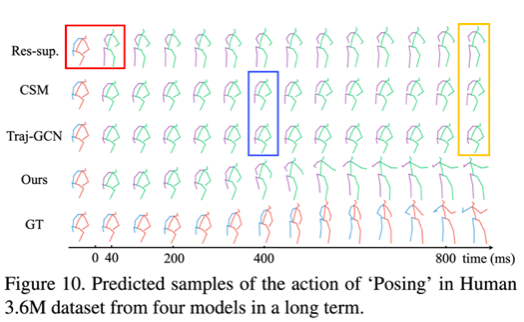
实验结果可视化
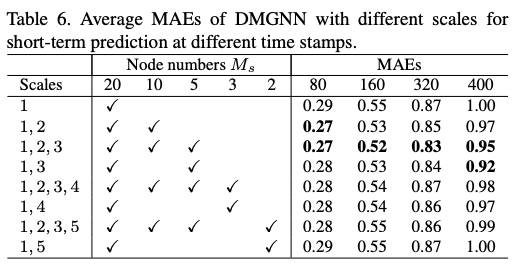
消融实验

登录查看更多
相关内容
专知会员服务
136+阅读 · 2020年3月8日


相关VIP内容
专知会员服务
136+阅读 · 2020年3月8日
相关资讯
相关论文