谷歌实习生新算法提速惊人!BERT训练从三天三夜,缩短到一个小时
郭一璞 安妮 发自 凹非寺
量子位 报道 | 公众号 QbitAI

从头开始训练一遍当今最强的语言AI需要多久?现在,这个时间从三天三夜,一下缩短到一个多小时!
带来这个进步的,是Google Brain实习生,尤洋。这位小哥来自中国河南,曾经的清华计算机硕士第一,目前在加州大学伯克利分校读博。
他最近完成的一项研究,让BERT的预训练速度,足足提高了64倍。从4860分钟,变成了76分钟11秒。
而且训练完成后,在机器问答数据集SQuAD-v1上测试一下,F1得分比原来的三天三夜版还要高一点点。
别人家的实习生,究竟又使出了什么神技?
费时到省时
要缩短神经网络的训练时间,本来有成熟的方法可用:
双管齐下,一是堆上大量CPU、GPU或者TPU增加算力,二是增加批大小减少迭代次数。
在计算机视觉研究中,这种方法就很常用。前两天,富士通的研究人员还用这种方法,74.7秒在ImageNet上训练完ResNet-50。

但是,视觉领域的这些训练方法,搬到BERT上是行不通的。BERT是目前工业界训练起来最耗时的应用,计算量远高于ImageNet。
此外,大批量训练还有个“通病”,就是会产生泛化误差(Generalization Gap),导致网络泛化能力下降,如此直接优化往往会导致测试集上准确度下降。
怎么办?
为了能用大批量训练BERT,尤洋和他的同事们提出了LAMB优化器。这是一个通用的神经网络优化器,无论是大批量还是小批量的网络都可以使用,也无需在学习率之外调试超参数。
靠超大批量也适用的LAMB,他们将批大小由512扩展到了65536。
65536是什么概念呢?这已经达到了TPU内存的极限,也是第一次有研究用2000以上的超大批量来训练BERT。
于是,迭代次数大大降低。此前,BERT-Large模型需要1000000次迭代才能完成预训练过程,耗时81.4小时。有了LAMB加持用上大批量,只需要进行8599次迭代,预训练时间直接缩短到76分钟。
这样看来,加速64倍!
因吹斯听,这LAMB到底是何方神器?
LAMB优化器
它的全称是Layer-wise Adaptive Moments optimizer for Batch training,和大家熟悉的SGD、Adam属于同类,都是机器学习模型的优化器(optimizer)。

原本,三天三夜的BERT训练,用的是权重衰减的Adam优化器。
而这一次的新型优化器LAMB,是在论文一作尤洋2017年的一项研究启发下产生的。当时,他提出了一种用于大批量卷积神经网络的优化器LARS。
LARS使用系数eeta控制信任率(trust ratio),但是这种做法可能会导致一些问题,造成一些差异。
因此,在LAMB里,研究团队删除了eeta,对于0|w|或者0|g|的层,直接把信任率设置成1.0,消除了BERT训练的差异。
另外,LARS里用权重衰减来计算信任率:
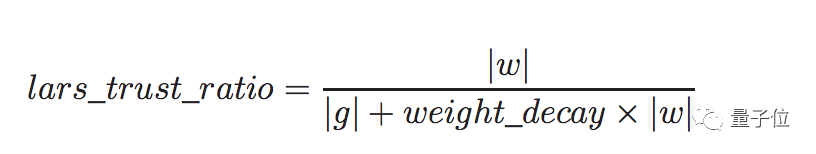
考虑到权重衰减,LAMB里的信任率公式改成了这样:
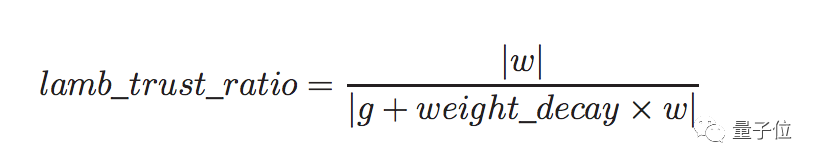
另外,LARS虽然在ImageNet上运行的很好,但是在ImageNet上用的模型参数比BERT少得多,因此,这一次,研究团队把LARS中的
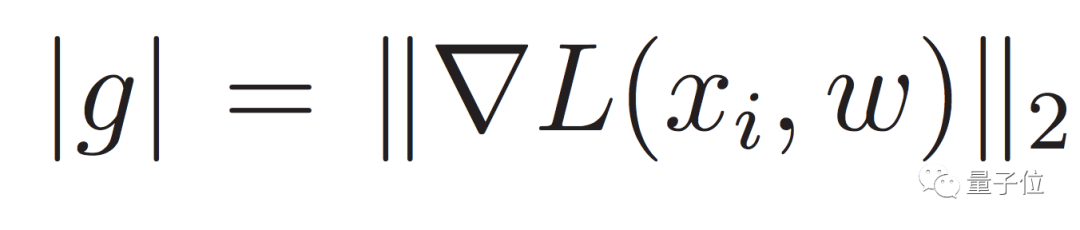
改成了:
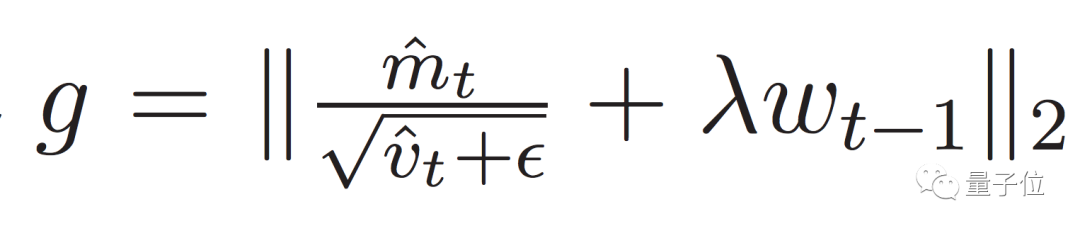
通过一系列改动,LAMB优化器的最大批量被提升到了32K。
真·优化
是骡子是马,也该拉出来溜溜了。
研究人员用常规训练与混合批训练两种方法,测试LAMB优化器的优化成果,实测效果不错。
在测试中,他们大大增加了算力,选择1024核的TPUv3 Pod进行训练,其中的1024个TPU核心,每秒可以提供超过10亿次浮点(100 petaflops)的混合精度运算。
最后研究人员敲定,和原版BERT模型一样,用Wikipedia和ooksCorpus数据集预训练,然后利用斯坦福的SQuAD-v1数据集进行测试,测试得出的F1 Score的值则用来衡量准确度。
结果显示,随着批量的增大,迭代次数逐减少,F1 Score的波动并不显著,F1值维持在90以上,但训练时间明显缩短。
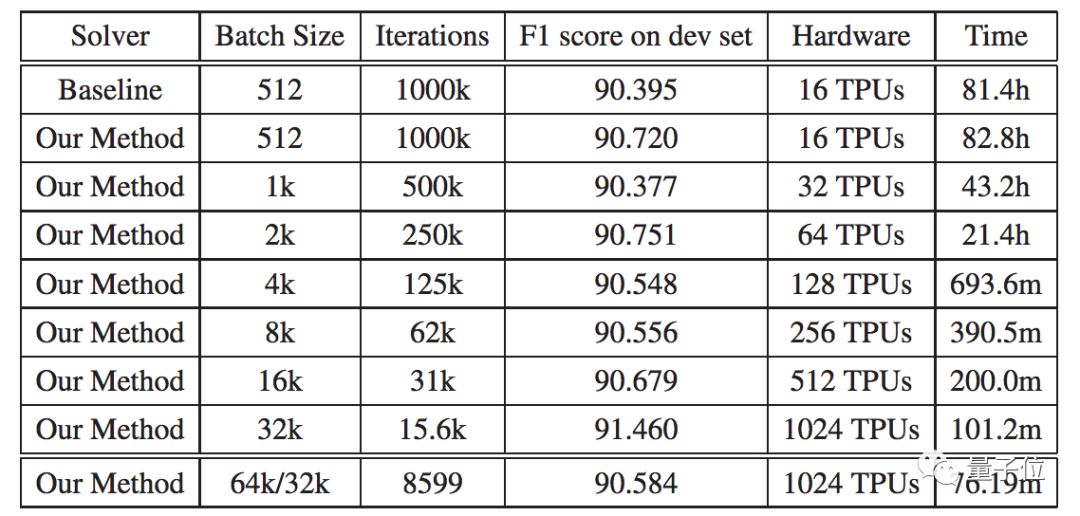
△ 测试结果
当批大小大于65536、序列长度达到128时,训练时间就没有明显的减少了。
当用了1024块TPU,批大小为32768或65536、迭代8599次时,训练时间缩减到最小,预训练过程只需要76.19分钟。
并且,最终达到了101.8%的弱缩放效率(weak scaling efficiency)。
学霸一作:本硕都是第一名
这项研究的作者是UC伯克利计算机科学部的在读博士尤洋,同时他也是Google Brain的实习生。

小哥哥是一位大学霸,他本科就读于中国农业大学计算机专业,是班里的第一名,硕士保送了清华计算机系,在134名入读清华的佼佼者中,他依然是第一名。
作为第一名的学霸,在申请博士的时候,尤洋一下子喜提了UC伯克利、CMU、芝加哥大学、UIUC、佐治亚理工、西北大学六所名校的全奖offer,简直是名校任挑。
于是,他从六所名校里选择了UC伯克利,UC伯克利刚好位于湾区,尤洋也因此有机会游走于Google Brain、英特尔实验室、微软研究院、英伟达、IBM沃森研究中心等知名企业、研究院实习,趁实习的机会为TensorFlow、英伟达GPU上部署caffe、英特尔CPU部署caffe等大型知名开源项目做出了贡献。
甚至,还有机会趁实习去皮衣哥黄仁勋家里开爬梯~真是让人羡慕啊。

△ 今天没穿皮衣
另外,尤洋也是一位论文高产选手,光是一作的顶会论文就有十几篇,其中还包含去年ICPP的最佳论文,还会有IPDPS 2015的最佳论文。而且,他还拿到了2014年的西贝尔学者奖(Siebel Scholar)。
传送门
Reducing BERT Pre-Training Time from 3 Days to 76 Minutes
Yang You, Jing Li, Jonathan Hseu, Xiaodan Song, James Demmel, Cho-Jui Hsieh
https://arxiv.org/abs/1904.00962

— 完 —
量子位AI+系列沙龙--智慧城市

加入社群
量子位AI社群开始招募啦,量子位社群分:AI讨论群、AI+行业群、AI技术群;
欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“微信群”,获取入群方式。(技术群与AI+行业群需经过审核,审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点这里吧 !



